參考文獻:
Speaker Verification嗶哩嗶哩bilibili
2020 年 3月 新番 李宏毅 人類語言處理 獨家筆記 聲紋識別 - 16 - 知乎 (zhihu.com)
(2) Meta Learning – Metric-based (1/3) - YouTube
如何理解等錯誤率(EER, Equal Error Rate)?請不要只給定義 - 知乎 (zhihu.com)
本次省略所有引用論文
目錄
一、Introduction
模型的簡單介紹
評價指標 Equal Error Rate(EER)
二、Speaker Embedding 講解
模型框架
數據集
Speaker Embedding 制作方法
三、End-to-End 端到端學習
訓練數據準備
模型設計
四、一些補充的問題與回答
一、Introduction
模型的簡單介紹
-
聲音模型有這么一大類,其模型主要需要完成的任務是,輸入一段語音,輸出某一類別。
-
相關的模型或任務有:
-
Emotion Recognition:情緒識別,輸入語音,判斷語者情緒如何。
-
Sound Event Detection:聲音事件偵測,輸入語音,判斷發生了什么事,可以用于安保等行業。
-
Autism Recognition:自閉癥識別,輸入語音,判斷是否患有自閉癥。
-
Keyword Spotting:關鍵詞識別,輸入語音,判斷指定的關鍵詞是否在語音中出現過。

-
-
那么采用這類模型,和語者有關的任務有哪些呢?
-
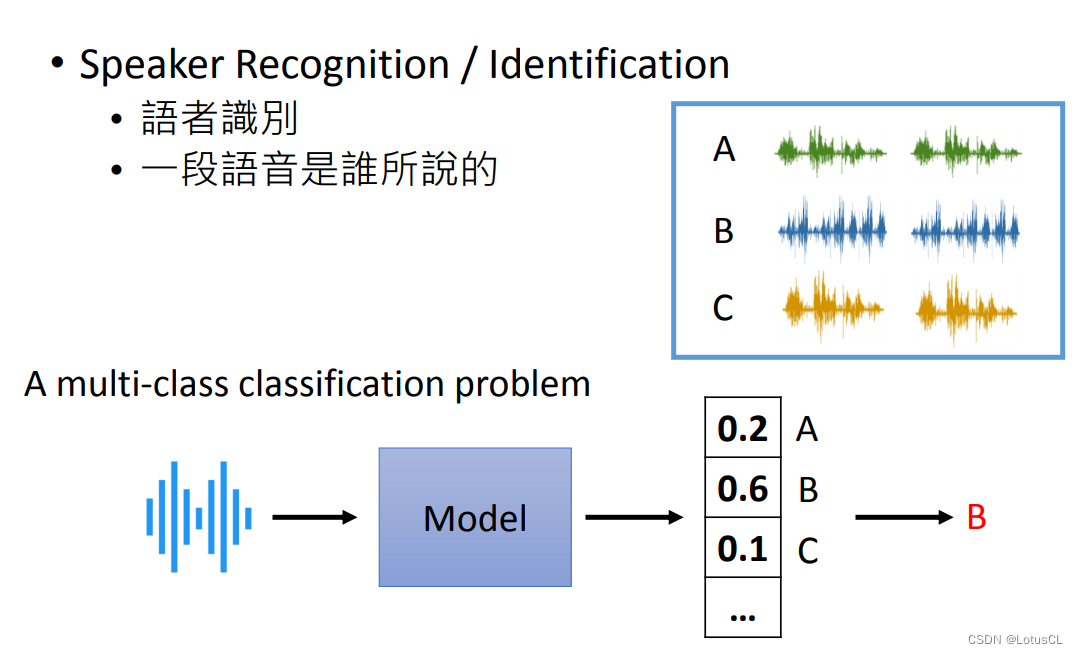
Speaker Recognition / Identification:語者識別,判斷一段語音是誰說的。其本質就是使用多語者的語料庫進行訓練,然后再輸入一段語音,通過模型輸出所有語者的 Confidence(可信度),誰的可信度高就判斷為這段信號是誰說的。這里我們不再過多介紹。
-
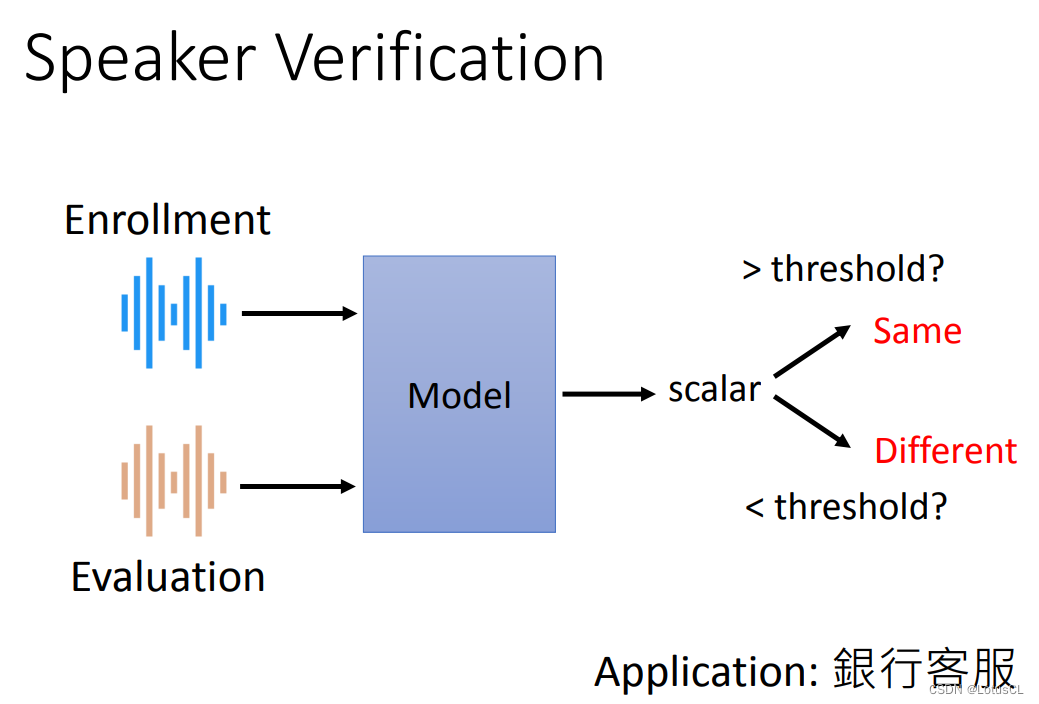
Speaker Verification:語者驗證,輸入兩段語音,判斷這兩段語音是否是同一個人說的。給定之前一段記錄好的聲音和一段新輸入的聲音,模型會判斷二者的相似度,并輸出一個表示相似度的概率(圖中scalar為標量的意思),通過閾值來判斷二者是否是同一個人說的。典型的應用如銀行客服判斷取錢的人是否是存錢者。
-
Speaker Diarization:語者分段標記,輸入一段語音,識別這段語音中,誰在何時說了話。SD 系統先要把聲音信號進行分割(Segmentation)。通常每一段是一句話,或是一個段落。接下來我們再做 聚類(Clustering)來標記哪一段是同一個人聲。如果不同說話人的數量是已知的,那么只需要知道這段話是誰講的就好,比如電話場景通常是兩個人。如果不知道是多少人在說話,比如會議場景,我們就需要把屬于同一個人的聲音聚成一類,并給它一個編號。這里就需要用到一些前兩種技術,也就是語者識別和聲紋識別的技術。

-
評價指標 Equal Error Rate(EER)
-
Equal Error Rate(EER),中文名叫 等錯誤率 。在 Speaker Verification 模型中,我們通常需要人為設置一個閾值,來決定二者是否為同一個人說的。很自然的我們能知道,設置不同的閾值,模型的表現自然也不同。閾值選擇通常會留給用戶。那么我們怎么去評判兩個模型孰優孰劣呢?
-
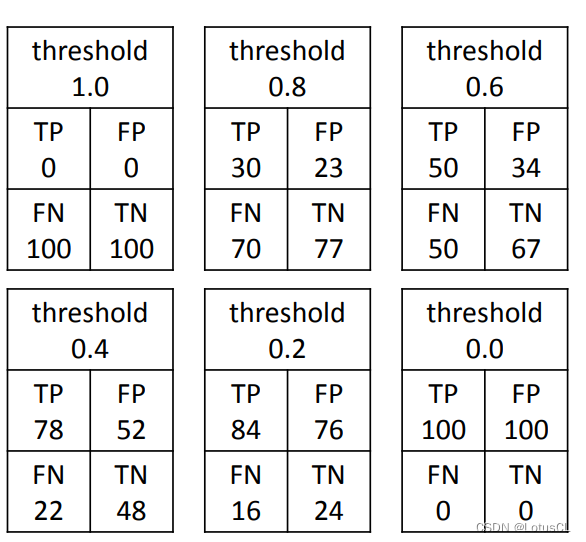
我們會把所有的閾值都窮舉出來,畫成一個圖像,計算 EER。我們先給一些簡單的樣例。
-
如果我直接把閾值設為1.0,那么對于這個模型來說,無論是哪兩段語音輸入進來,模型都會判斷為不是同一個人所說。
-
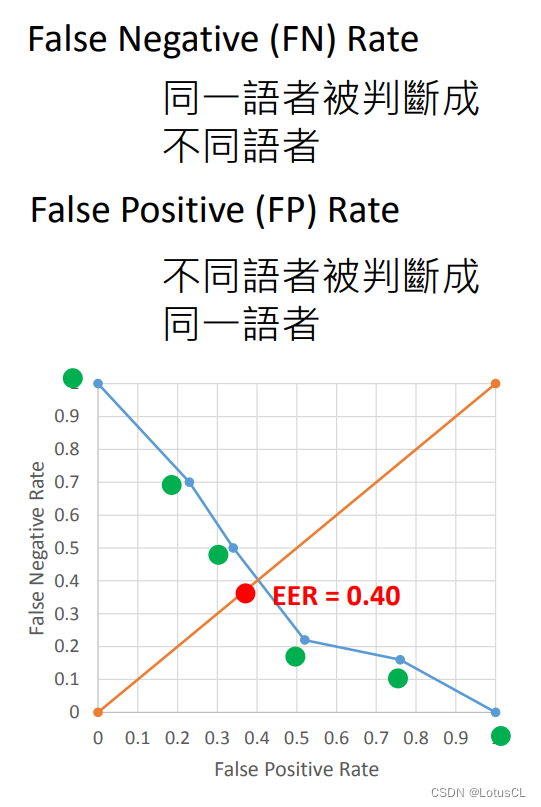
如果我把閾值設的挺高,比如0.8,那么這個模型來說,可能使用同一個語者的兩段音頻,被誤判為不同人說的,這個誤判率【False Negative Rate】會比較高,因為你的標準比較苛刻;不過使用不同語者的兩段音頻,被誤判為同一人說的,這個誤判率【False Positive Rate】就比較低了。
-
如果之后我直接把閾值設為0,那么對于這個模型來說,無論是哪兩段語音輸入進來,模型都會判斷為就是同一個人所說,利用剛剛的概念我們可以說,FNR = 0,FPR = 1。
-
-
最后,以 FPR 數值為 x 軸,以 FNR 數值為 y 軸,我們將圖像畫出,而 EER 就是當 FPR = FNR 時,二者的大小。
二、Speaker Embedding 講解
模型框架
-
那么 SV 模型具體長什么樣子呢?傳統的 SV 模型通常是采用了某些方法,輸入一段聲音訊號,就能輸出一個向量來表示語者特征。這個語者特征也就是我們所說的 Speaker Embedding。有了這個方法,我們就能將兩段聲音訊號都轉為 Speaker Embedding,然后去比較二者的相似度即可。

-
模型使用具體步驟:

-
Stage 1:Development,即模型訓練,使用語料庫對模型進行訓練,從而讓模型學習到 Speaker Embedding 的編碼方式。
-
Stage 2:Enrollment,即聲紋錄入,需要說話者將自己的聲音錄入系統。系統會把這些聲音一個個輸入模型,得到語者嵌入,再取平均,儲存到數據庫。
-
Stage 3:Evaluation,即聲紋評估,也就是驗證階段,系統會把檢測到的人聲輸入模型得到另一個語者嵌入,與之前儲存到的嵌入做比較,得出是否是同一個人的結論。
值得一提的是,剛剛所說的步驟中,訓練模型使用的語料庫的語者并不會在后續模型使用中出現。
-
-
而 SV 模型的這一套思想,其實和 Metric-based meta learning 思想近乎相同。詳情可以參考(2) Meta Learning – Metric-based (1/3) - YouTube。
數據集
-
訓練 SV 抽取 Speaker Embedding 的模型需要一個多大的數據集呢?谷歌用了 18000 個語者,總共 36M 個句子去訓練模。實驗跑不動這種數據。一般我們會用相對小一些的 Benchmark Corpus(基準語料庫),比如 VoxCeleb 數據集來訓練。

Speaker Embedding 制作方法
-
早期采用的方法是 i-vector,不管輸入的語音有多長,最終都會生成一個400維的 i-vector,來表示聲紋信息。i 意思是 identity。i-Vector 是一個非常強的方法。在 16 年之前都沒有被 DL 打敗。

-
而最早采用 deep learning 來抽取 Speaker Embedding 的模型就是 d-vector。它是截取一小段聲音訊號(因為后面使用的 DNN 輸入長度是固定的),送到 DNN中去,經過多層網絡后最終輸出。在訓練過程中,我們一直將這個模型當成 Speaker Recognition 模型來進行訓練,即最后輸出是哪個語者講的話。而模型訓練完后,其最后一個隱藏層的輸出我們將它拿出來,這就是我們要的 d-vector。
我們不用最后一層 output layer 的輸出,就是因為此時它將要決定是聲音來源于哪個語者,所以它的維度是和訓練時語者數目有關的,而我們并不想要這樣的 vector,所以使用的是最后一個隱藏層(hidden layer)的輸出。
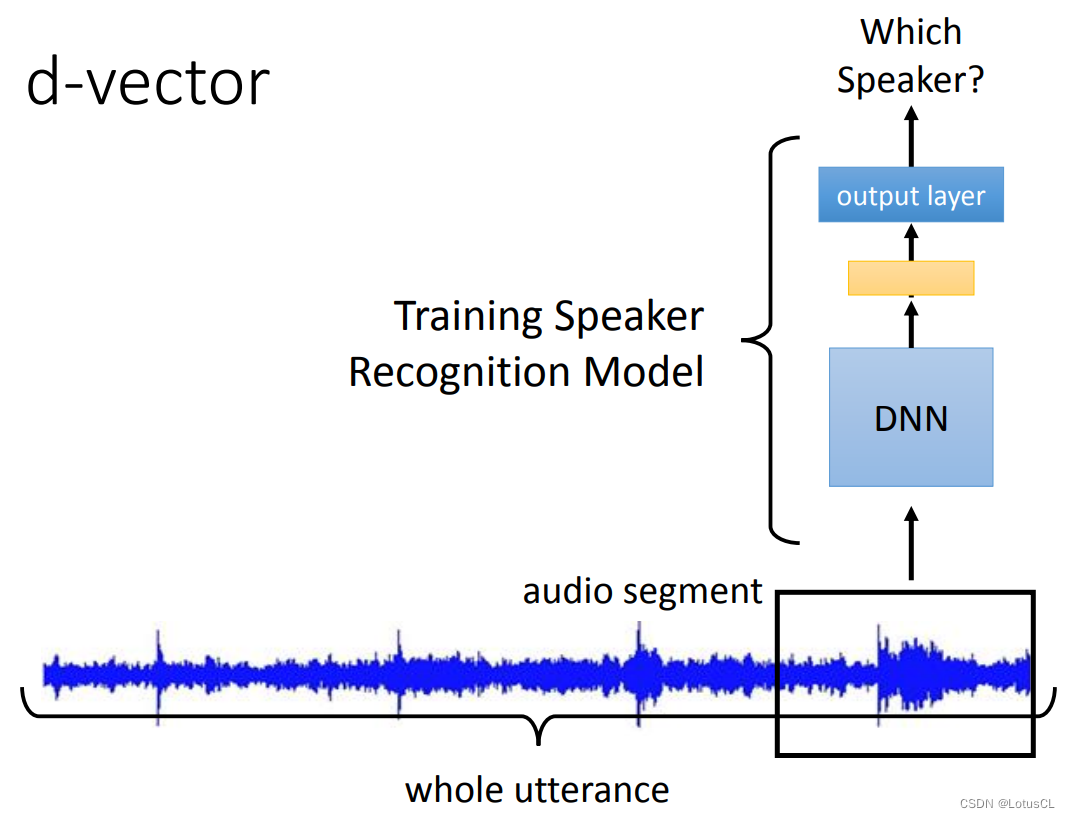
-
當然,剛剛的方法只是看了一小段語音而已。想要看完一整段語音也很簡單,每一個小段都進行上述的操作,最終取平均,就得到最終的 d-vector了。在 2014 年,d-vector 可以做到與 i-vector 相當的效果。不過這也只是讓大家知道,原來深度學習可以做這玩意。

-
到了2018 年,出了 x-vector。它會把每個語音片段通過模型后的輸出用一種方式聚合起來,而不是像 d-vector 那樣簡單的取平均。這種方式是取每個維度的均值和方差向量,拼接起來后,再輸入給一個模型做 Speaker Recognition 任務。到時取這個模型輸出的隱層,作為表征聲紋信息的 x-vector。它與 d-vector 不同在,它考慮的是一整段的語音信息。這里也可以考慮用 LSTM 來做聚合。

-
當然也可以用 Attention 來做啦,算出每一個語音片段的注意力權重,然后再做加權求和。還有從圖像那邊借來的方法 NetVLAD,其主要思想是一段語音中并非所有的片段都是人聲,其中有的是環境噪音。我們可以想辦法從中只取出人聲的部分。具體細節這里不再贅述。
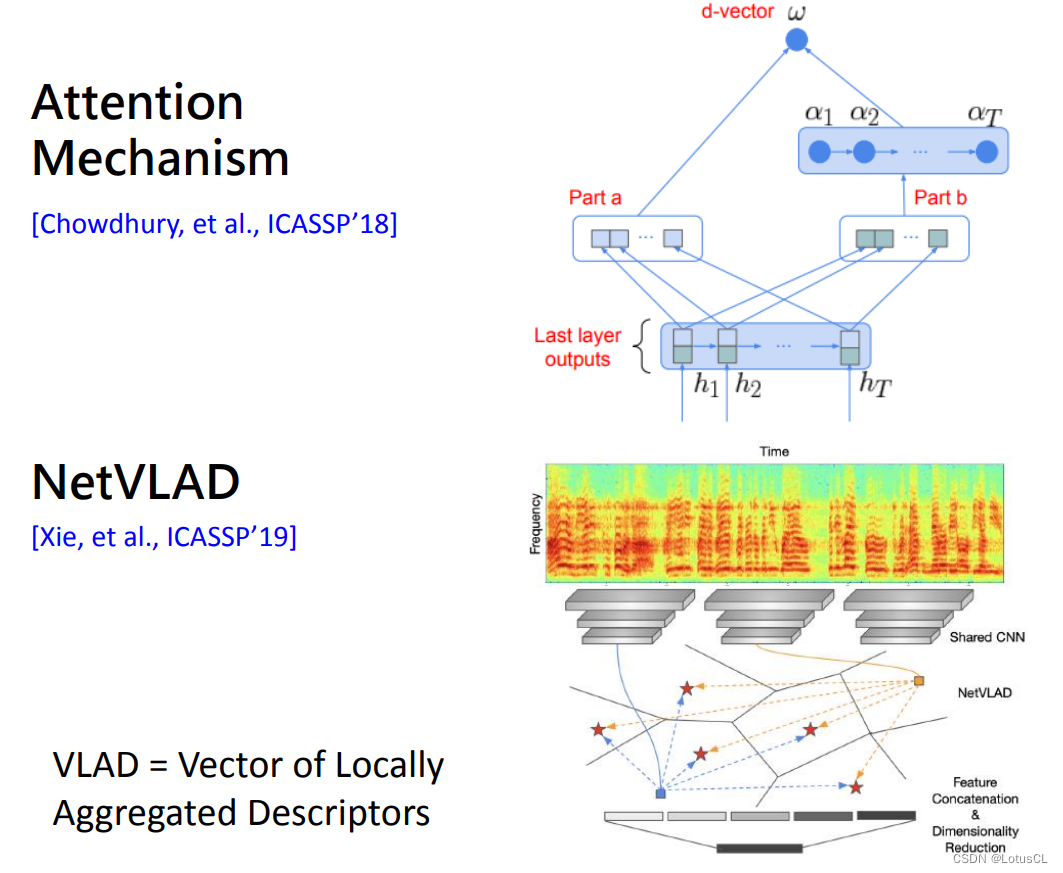
-
綜合這些方法,我們都是先按照 Speaker Recognition 任務來進行模型的訓練,然后再抽取輸出,拿到 Speaker Verification 任務中去用。
三、End-to-End 端到端學習
此前,我們都是想辦法得到 Speaker Embedding,然后計算二者的相似度來完成任務的。這是分離的方法,那我們有沒有什么辦法將“計算 Speaker Embedding”和“計算相似度”二者聯合起來做 joint learning,一起去學習訓練呢?
訓練數據準備
-
首先我們需要準備我們訓練的數據。在以前的任務中,我們手上有的資料是一堆的語者,每個語者說了一堆的話。假設我們的 Enrollment 環節要求語者要說 k 句話,那么我們就這么準備資料:
-
Positive Examples:從某個語者說的話中挑出 k 句話當作注冊的句子輸入進模型中,取同一個語者的另一句話當作測試的句子再輸入進模型中,最終輸出的數值要越大越好。

-
Negative Examples:從某個語者說的話中挑出 k 句話當作注冊的句子輸入進模型中,取另一個語者的一句話當作測試的句子再輸入進模型中,最終輸出的數值要越小越好。

-
-
當然,除了這種準備數據集的方法,我們還有其他各種各樣的方法,比如 Generalized E2E(GE2E,[Wan, et al., ICASSP’18])等等,這里不再贅述。
模型設計
-
端到端模型它內部的構造是完全仿造傳統的 SV 的模型。有 K 個注冊的句子,每一個句子都會進入一個網絡中并產生一個 vector 來充當 Speaker Embedding,用來測試的句子也是一樣,經過一個網絡生成一個 vector。
-
接下來,我們取注冊句子生成的 vector 做個平均,得到一個 vector,然后再將其與剛剛測試句子生成的 vector 計算相似度,這里也可以使用一個網絡來計算相似度,最終得到一個分數。怎樣端對端訓練?不同人講的語音我們就希望分數能小點,同一個人講的聲音我們就希望分數大點。
-
常用的相似度計算是先計算二者的余弦相似度,然后再做一些小變換,如乘上一個權重,然后再加一個偏置。
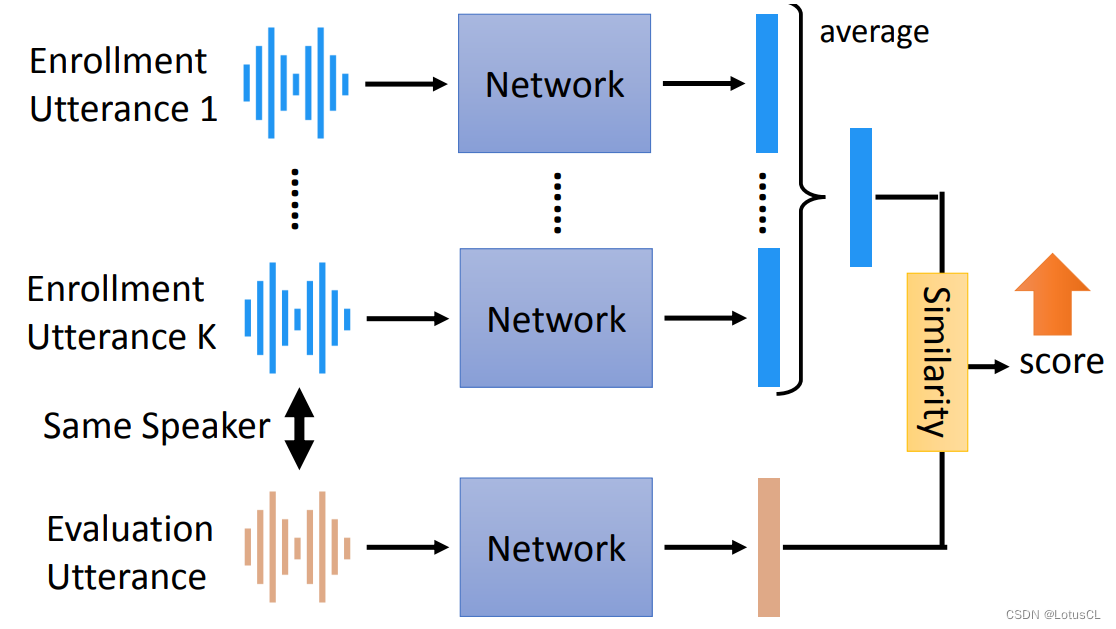
-
這種端對端的模型可以分成 Text-dependent 和 Text-independent。若注冊和評估說的都是相同文字內容,就是 Text-dependent,比如必須要說同樣的暗語“芝麻開門”。若可以是不同的文字內容,就是Text-independent。
-
如果想做 Text-independent,那么我們在抽取 Speaker Embedding 類似物的時候就需要盡可能只抽取語者信息,而不去抽取內容信息。在這里,我們可以引入 GAN 的思想,來對抗訓練。我們可以在 生成的 Speaker Embedding 后面接上一個 Discriminator(判別器),來識別文字內容(有點像 ASR)。而我們訓練的目標又多了一個,輸出 Speaker Embedding 的網絡要想辦法去騙過這個判別器,盡可能讓它無法從聲紋嵌入中識別出文字內容。
四、一些補充的問題與回答
-
EER 的意義是什么:
因為此模型的錯誤有兩種,一種是明明是同一個人說的,你說是不同人;還有一種是話是不同人說的,你卻判斷是同一個人說的。那么這就要涉及到兩種錯誤率的 trade-off(權衡折衷),那么 EER 就是看當這兩種錯誤的錯誤率相同時大小為多少,以此來評判模型優劣。
這里還可以參考知乎上的回答:如何理解等錯誤率(EER, Equal Error Rate)?請不要只給定義 - 知乎 (zhihu.com),其實大差不差啦。













)


)


)