簡介
? ? ? ?作為數據庫管理員(DBA),定期進行數據庫的日常巡檢是非常重要的。以下是一些原因:
? ? ? ? 保證系統的穩定性:通過定期巡檢,DBA可以發現并及時解決可能導致系統不穩定的問題,如性能瓶頸、資源利用率過高或磁盤空間不足等。
? ? ? ? 提高數據的安全性:巡檢可以幫助DBA發現潛在的安全風險,例如未經授權的訪問、數據泄露或其他安全漏洞。及時采取措施,可以防止這些風險演變成實際問題。
? ? ? ? 避免數據丟失:DBA可以通過檢查備份和恢復策略來確保數據的完整性,并確保在發生災難時能夠快速恢復業務運營。
? ? ? ? 確保合規性:許多行業都有特定的數據管理規定和法規要求。通過巡檢,DBA可以確保他們的數據庫管理系統符合這些規定和要求。
? ? ? ? 性能優化:巡檢可以幫助DBA識別性能瓶頸,從而優化數據庫以提高其效率和響應速度。
? ? ? ? 資源規劃:通過巡檢,DBA可以了解當前的資源使用情況,預測未來的資源需求,并根據需要調整資源配置。
? ? ? ? 綜上所述,DBA的日常巡檢是保持數據庫健康運行的關鍵環節之一,也是確保業務連續性和高效運行的重要步驟。
目錄
簡介
17、TOP 10 邏輯讀排序
18、TOP 10 CPU排序
19、查詢等待事件
20、查詢當前正在消耗temp空間的sql語句
21、查詢需要使用綁定變量的sql,10G以后推薦第二種
一、
二、
22、查看數據文件可用百分比
23、查看表空間可用百分比
24、查看臨時表空間使用率
25、查詢undo表空間使用情況
26、查看ASM磁盤組使用率
?27、統計每個用戶使用表空間率
17、TOP 10 邏輯讀排序
select *from (select BUFFER_GETS,username,PARSING_USER_ID,sql_id,ELAPSED_TIME / 1000000,sql_textfrom v$sql, dba_userswhere user_id = PARSING_USER_IDorder by BUFFER_GETS desc)where rownum <= 10;
 ????????BUFFER_GETS:這個字段表示SQL語句在數據庫中獲取了多少次數據,也就是這個SQL被執行了多少次。
????????BUFFER_GETS:這個字段表示SQL語句在數據庫中獲取了多少次數據,也就是這個SQL被執行了多少次。
????????USERNAME:這個字段表示執行SQL語句的用戶名。
????????PARSING_USER_ID:這個字段表示解析SQL的用戶ID。
????????SQL_ID:這個字段表示SQL語句的唯一ID。
????????ELAPSED_TIME / 1000000:這個字段表示SQL語句執行所花費的時間(單位是秒)。
????????SQL_TEXT:這個字段表示SQL語句的內容。
????????"邏輯讀排序":是ORACLE中一種用于優化查詢性能的技術。當ORACLE執行一個查詢時,它需要讀取和解析SQL語句。如果一個表有很多行,或者有很多列,那么讀取和解析這些數據可能會花費很長時間。因此,ORACLE使用了一種叫做"邏輯讀排序"的技術,這種技術可以使得查詢優化器能夠預測哪些行將會被需要,并提前讀取這些行,從而減少了讀取和解析的時間。這種技術對于大數據量的表特別有用,因為它可以顯著提高查詢性能。
注:(不要使用DISK_READS/ EXECUTIONS來排序,因為任何一條語句不管執行幾次都會耗邏輯讀和cpu,可能不會耗物理讀(遇到LRU還會耗物理讀,LRU規則是執行最不頻繁的且最后一次執行時間距離現在最久遠的就會被交互出buffer cache),是因為buffer cache存放的是數據塊,去數據塊里找行一定會消耗cpu和邏輯讀的。Shared pool執行存放sql的解析結果,sql執行的時候只是去share pool中找hash value,如果有匹配的就是軟解析。所以物理讀邏輯讀是在buffer cache中,軟解析硬解析是在shared pool)
18、TOP 10 CPU排序
select *from (select CPU_TIME / 1000000,username,PARSING_USER_ID,sql_id,ELAPSED_TIME / 1000000,sql_textfrom v$sql, dba_userswhere user_id = PARSING_USER_IDorder by CPU_TIME / 1000000 desc)where rownum <= 10;
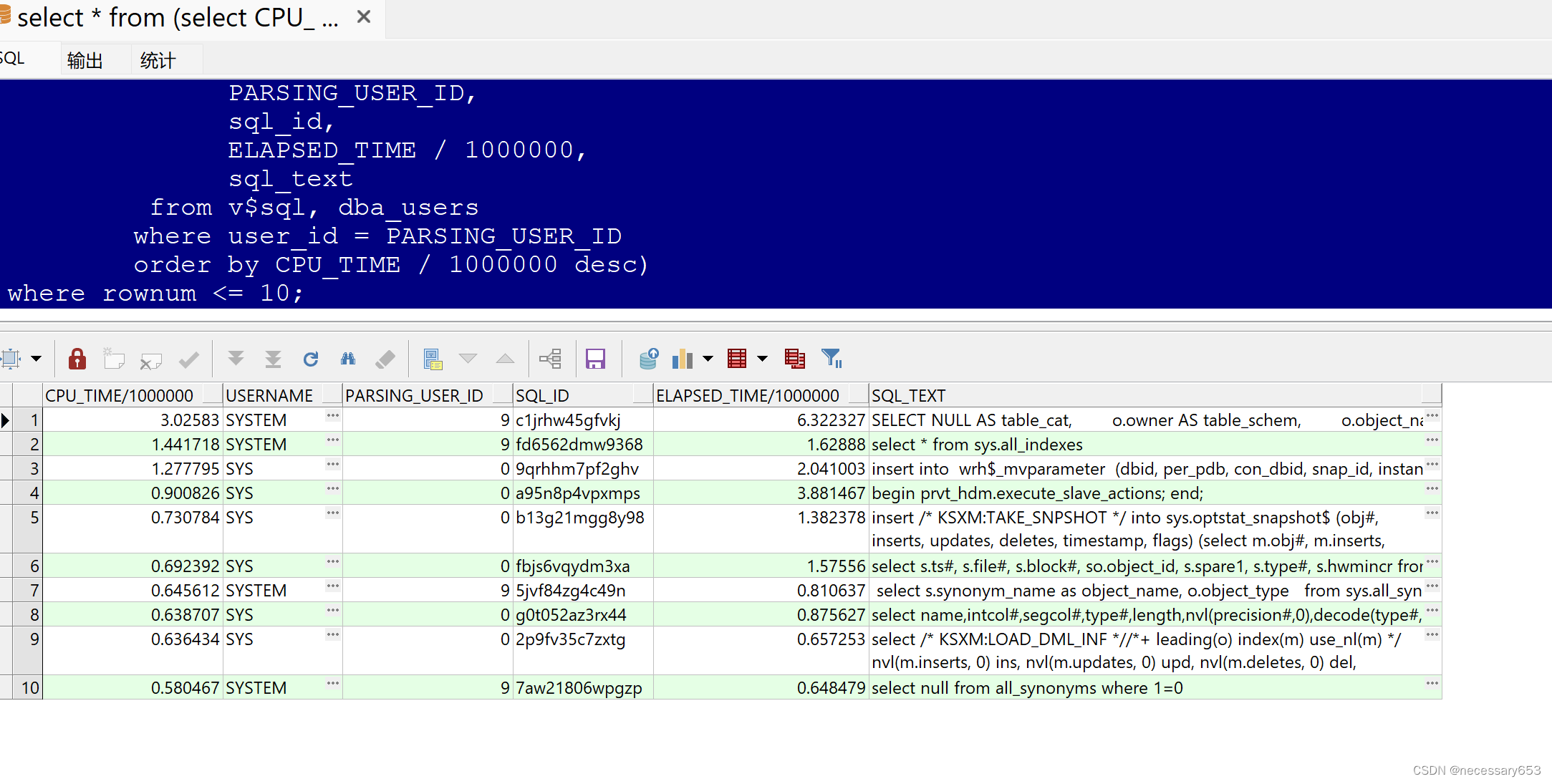 ????????CPU_TIME / 1000000:這個字段表示SQL語句在數據庫中執行時所消耗的CPU時間(單位是秒)。
????????CPU_TIME / 1000000:這個字段表示SQL語句在數據庫中執行時所消耗的CPU時間(單位是秒)。
????????USERNAME:這個字段表示執行SQL語句的用戶名。
????????PARSING_USER_ID:這個字段表示解析SQL的用戶ID。
????????SQL_ID:這個字段表示SQL語句的唯一ID。
????????ELAPSED_TIME / 1000000:這個字段表示SQL語句執行所花費的總時間(單位是秒)。
????????SQL_TEXT:這個字段表示SQL語句的內容。
????????當數據庫執行一個SQL語句時,它會在CPU上運行,消耗一定的CPU時間。通過使用CPU排序,我們可以找出最消耗CPU時間的SQL語句,從而優化它們以提高數據庫的性能。這種技術特別適用于找出那些需要大量計算和處理的SQL語句,因為這些語句通常會對數據庫的性能產生最大的影響。
19、查詢等待事件
select event,sum(decode(wait_time, 0, 0, 1)) "之前等待次數",sum(decode(wait_time, 0, 1, 0)) "正在等待次數",count(*)from v$session_waitgroup by eventorder by 4 desc
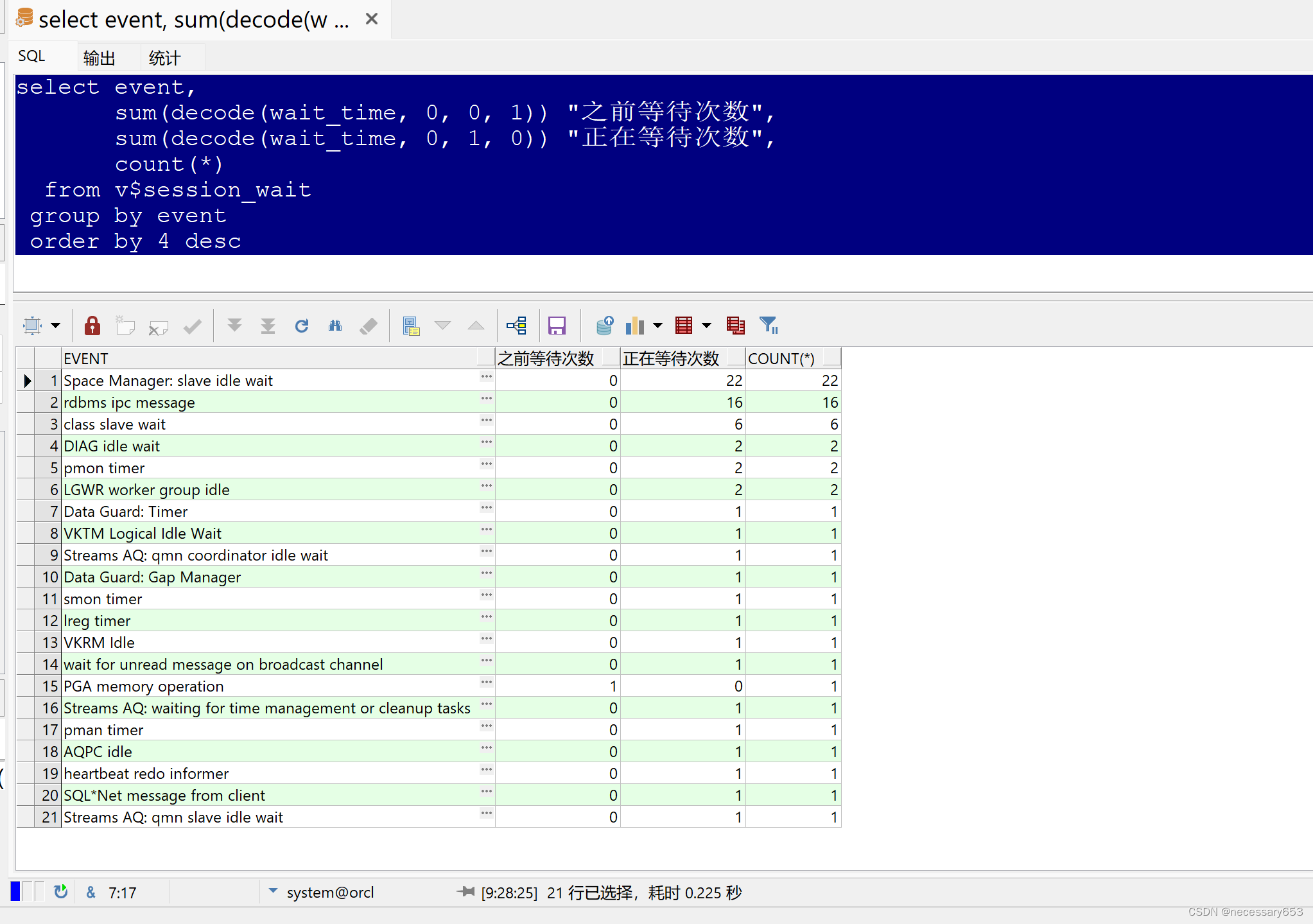
????????EVENT:這個字段表示等待事件的類型。等待事件是指在數據庫操作過程中,用戶需要等待資源釋放的情況。
????????SUM(DECODE(WAIT_TIME, 0, 0, 1)) "之前等待次數":這個字段表示在等待時間(WAIT_TIME)為0的情況下,該事件發生的次數。如果等待時間為0,說明該事件沒有發生過。
????????SUM(DECODE(WAIT_TIME, 0, 1, 0)) "正在等待次數":這個字段表示在等待時間不為0的情況下,該事件發生的次數。如果等待時間不為0,說明該事件正在發生。
????????COUNT(*):這個字段表示該事件發生的總次數。
該查詢從V$SESSION_WAIT視圖中獲取數據,這是一個包含數據庫中所有會話的等待事件信息的視圖。它會根據等待事件的類型(EVENT)進行分組,并按照等待事件的次數進行降序排序。
????????在ORACLE數據庫中,等待事件是常見的性能問題分析工具。通過分析等待事件,我們可以了解數據庫的資源使用情況、會話的活動情況以及可能存在的性能瓶頸。例如,如果"LOG FILE SYNC"事件的等待次數很多,可能意味著磁盤I/O存在問題;如果"ROW LOCK"事件的等待次數很多,可能意味著存在競爭行鎖的情況等。
之前的文章有列舉出關于等待事件名稱對應的數據庫事件情況的列表。
20、查詢當前正在消耗temp空間的sql語句
Select distinct se.username,se.sid,su.blocks * to_number(rtrim(p.value)) / 1024 / 1024 as space_G,su.tablespace,sql_textfrom V$TEMPSEG_USAGE su, v$parameter p, v$session se, v$sql swhere p.name = 'db_block_size'and su.session_addr = se.saddrand su.sqlhash = s.hash_valueand su.sqladdr = s.address
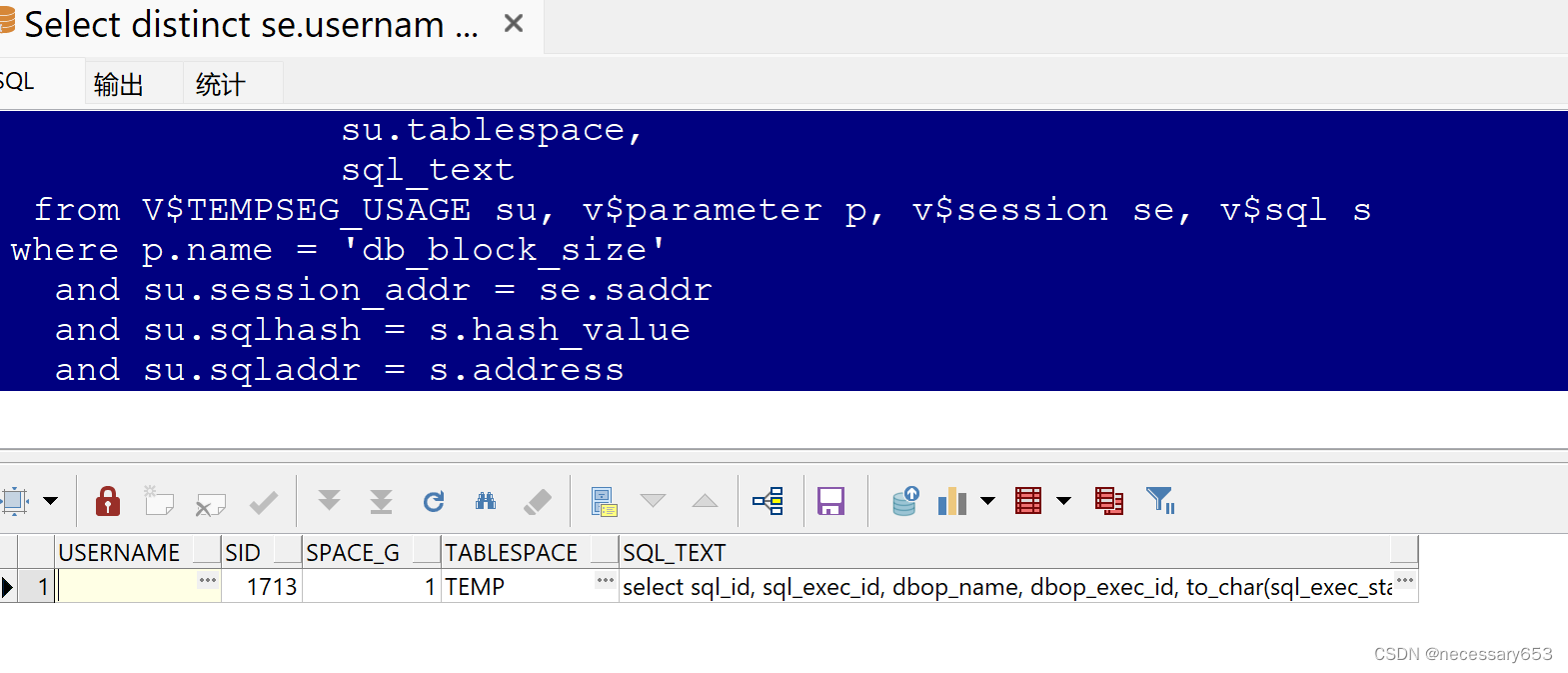
? ? ? ? USERNAME: 用戶名,表示正在使用臨時空間的會話所屬的用戶。
????????SID: 會話ID,表示正在使用臨時空間的會話的唯一標識符。
????????BLOCKS * TO_NUMBER(RTRIM(P.VALUE)) / 1024 / 1024 AS SPACE_G: 這部分計算了臨時空間使用的空間大小,單位是G字節。其中,SU.BLOCKS表示臨時空間使用的塊數,TO_NUMBER(RTRIM(P.VALUE))表示數據庫塊的大小(以字節為單位),然后通過除以1024*1024轉換為兆字節(MB),再除以1024轉換為G字節。
????????TABLESPACE: 臨時表空間,表示臨時空間所在的表空間。
????????SQL_TEXT: SQL文本,表示正在使用臨時空間的SQL語句的文本。
????????查詢當前正在消耗TEMP空間的SQL語句的意義在于:TEMP空間是ORACLE數據庫中的臨時存儲區域,用于存儲臨時數據和中間結果。當一個SQL語句在執行過程中需要創建臨時表、排序數據或執行其他類似操作時,ORACLE會將數據存儲在TEMP空間中。通過查詢正在消耗TEMP空間的SQL語句,可以了解哪些操作正在使用TEMP空間,以及它們的使用情況,從而幫助數據庫管理員進行性能分析和優化。
21、查詢需要使用綁定變量的sql,10G以后推薦第二種
一、
select * from (
select count(*),sql_id, substr(sql_text,1,40)
from v$sql
group by sql_id, substr(sql_text,1,40) having count(*) > 10 order by count(*) desc) where rownum<10
????????從 Oracle 數據庫的 v$sql 視圖中查詢 SQL ID、SQL 語句以及它們的使用次數,需要注意的是,這段代碼只返回了 SQL 語句的前 40 個字符,因為這部分足以表明 SQL 語句的大致含義,同時還可減少數據庫的 I/O 開銷。
二、
select sql_id, FORCE_MATCHING_SIGNATURE, sql_text
from v$SQL
where FORCE_MATCHING_SIGNATURE in
(select /*+ unnest */
FORCE_MATCHING_SIGNATURE
from v$sql
where FORCE_MATCHING_SIGNATURE > 0
and FORCE_MATCHING_SIGNATURE != EXACT_MATCHING_SIGNATURE
group by FORCE_MATCHING_SIGNATURE
having count(1) > 10)????????從 Oracle 數據庫的 v$sql 視圖中查詢一組具有相同 FORCE_MATCHING_SIGNATURE 的 SQL 語句,同時每個 FORCE_MATCHING_SIGNATURE 的使用次數必須大于 10。其中,FORCE_MATCHING_SIGNATURE 是 Oracle 中的一個哈希值,它用于標識一組具有相同執行計劃的 SQL 語句。因此,如果兩個 SQL 語句具有相同的 FORCE_MATCHING_SIGNATURE,它們很可能會共享相同的執行計劃,并且會相互影響。如果 FORCE_MATCHING_SIGNATURE 不同,即使兩個 SQL 語句的文本完全相同,它們也可以擁有不同的執行計劃。
結果集反映了在數據庫中存在一些具有相同 FORCE_MATCHING_SIGNATURE 的 SQL 語句,并且它們的數量超過了 10。這意味著在數據庫中存在一些 SQL 查詢語句,它們具有相同的執行計劃,卻被執行了很多次。這可能是因為它們是經常性的查詢,也可能是因為有許多用戶同時執行了它們。
22、查看數據文件可用百分比
select b.file_id,b.tablespace_name,b.file_name,b.AUTOEXTENSIBLE,
ROUND(b.bytes/1024/1024/1024,2) ||'G' "文件總容量",
ROUND((b.bytes-sum(nvl(a.bytes,0)))/1024/1024/1024,2)||'G' "文件已用容量",
ROUND(sum(nvl(a.bytes,0))/1024/1024/1024,2)||'G' "文件可用容量",
ROUND(sum(nvl(a.bytes,0))/(b.bytes),2)*100||'%' "文件可用百分比"
from dba_free_space a,dba_data_files b
where a.file_id=b.file_id
group by b.tablespace_name,b.file_name,b.file_id,b.bytes,b.AUTOEXTENSIBLE
order by b.tablespace_name;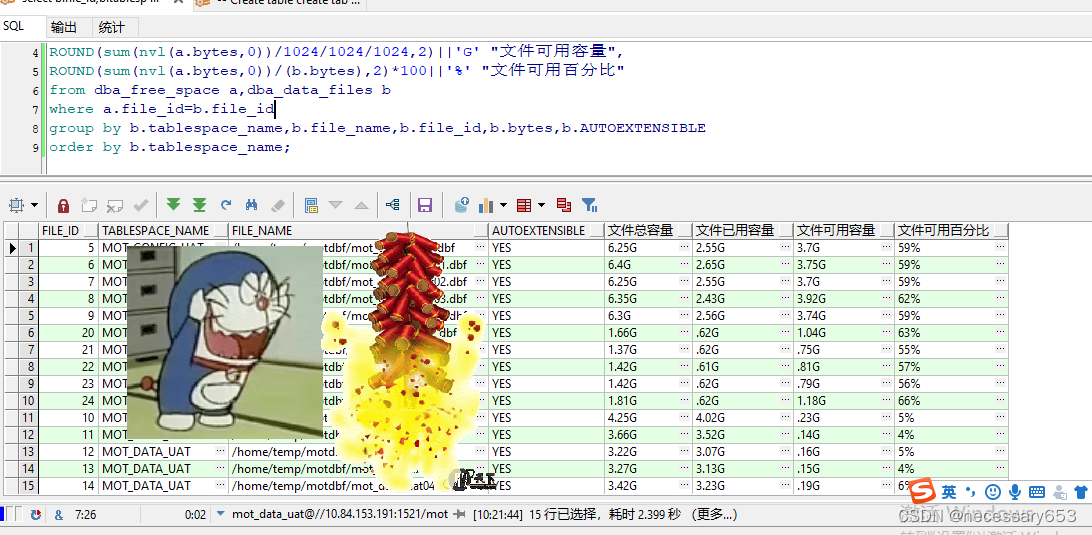
????????file_id: 文件ID,唯一標識數據庫中的文件。
????????tablespace_name: 表空間名稱,表空間是Oracle數據庫中的一個邏輯存儲單位,它包含了數據庫的對象(如表,索引等)。
????????file_name: 文件的名稱,這是在文件系統中的實際文件名。
????????AUTOEXTENSIBLE: 自動擴展標志,如果此字段為TRUE,表示文件是自動擴展的。
????????ROUND(b.bytes/1024/1024/1024,2) ||'G' "文件總容量": 這個字段表示文件的總容量,單位是GB。
????????ROUND((b.bytes-sum(nvl(a.bytes,0)))/1024/1024/1024,2)||'G' "文件已用容量": 這個字段表示文件的已使用容量,單位是GB。如果a.bytes字段為空(即沒有記錄或者沒有數據),則使用0代替。
????????ROUND(sum(nvl(a.bytes,0))/1024/1024/1024,2)||'G' "文件可用容量": 這個字段表示文件的可用容量,單位是GB。如果a.bytes字段為空(即沒有記錄或者沒有數據),則使用0代替。
????????ROUND(sum(nvl(a.bytes,0))/(b.bytes),2)*100||'%' "文件可用百分比": 這個字段表示文件的可用百分比。如果a.bytes字段為空(即沒有記錄或者沒有數據),則使用0代替。
????????查詢的結果集將返回每個表空間的文件的信息,包括文件的ID、名稱、總容量、已使用容量、可用容量和可用百分比。這個查詢有助于管理員了解數據庫的存儲使用情況,以便于進行存儲管理和優化。?
23、查看表空間可用百分比
select b.tablespace_name,a.total,b.free,round((b.free / a.total) * 100) "% Free"from (select tablespace_name, sum(bytes / (1024 * 1024)) totalfrom dba_data_filesgroup by tablespace_name) a,(select tablespace_name, round(sum(bytes / (1024 * 1024))) freefrom dba_free_spacegroup by tablespace_name) bWHERE a.tablespace_name = b.tablespace_nameorder by "% Free";

????????查詢Oracle數據庫中各個表空間的存儲使用情況。下面是各個字段的解釋:
? ? ? ? tablespace_name: 表空間名稱。
? ? ? ? total: a子查詢中計算得到的表空間的總容量,單位是MB。
????????free: b子查詢中計算得到的表空間的剩余容量,單位是MB。
????????round((b.free / a.total) * 100) "% Free": 計算得到的表空間的剩余百分比。
? ? ? ? 查詢的結果集將返回每個表空間的名稱、總容量、剩余容量以及剩余空間的百分比。這個查詢有助于數據庫管理員了解數據庫的存儲使用情況,以便于進行存儲管理和優化。例如,如果發現某些表空間接近其容量限制,那么可能需要增加這些表空間的容量或者優化存儲結構。
?
24、查看臨時表空間使用率
SELECT temp_used.tablespace_name,total,used,total - used as "Free",round(nvl(total-used, 0) * 100/total,3) "Free percent"FROM (SELECT tablespace_name, SUM(bytes_used)/1024/1024 usedFROM GV_$TEMP_SPACE_HEADERGROUP BY tablespace_name) temp_used,(SELECT tablespace_name, SUM(bytes)/1024/1024 totalFROM dba_temp_filesGROUP BY tablespace_name) temp_totalWHERE temp_used.tablespace_name = temp_total.tablespace_name?? ? 獲取Oracle數據庫中各個表空間的臨時空間使用情況。
????????temp_used.tablespace_name: 這是一個表空間名稱,它來自于子查詢temp_used。該子查詢從GV_$TEMP_SPACE_HEADER視圖中獲取了臨時空間使用的總字節數,并按表空間名稱進行了分組。
????????total: 這是另一個來自子查詢temp_total的字段,表示特定表空間的臨時文件總字節數。它從dba_temp_files視圖中獲取數據,并按表空間名稱進行了匯總。
????????used: 這是從GV_$TEMP_SPACE_HEADER視圖中獲取的已使用的臨時空間字節數。它按表空間名稱進行了匯總。
????????total - used as "Free": 這個字段表示表空間的剩余臨時空間,計算方法是總臨時空間減去已使用的臨時空間。
????????round(nvl(total-used, 0) * 100/total,3) "Free percent": 這個字段表示剩余臨時空間占總臨時空間的百分比。如果總臨時空間或已使用的臨時空間中的任何一個為空(即未定義),則使用NVL函數將其替換為0,并計算剩余臨時空間所占的百分比。
????????查詢的結果集將顯示每個表空間的名稱、總臨時空間、已使用的臨時空間、剩余臨時空間以及剩余臨時空間所占的百分比。如果發現某個表空間的臨時空間使用率很高,那么可能需要增加該表空間的存儲容量,或者優化該表空間的存儲結構。
25、查詢undo表空間使用情況
select tablespace_name, status, sum(bytes) / 1024 / 1024 Mfrom dba_undo_extentsgroup by tablespace_name, status

?
從dba_undo_extents視圖中獲取數據。這個視圖存儲了數據庫中撤銷空間的信息。
????????tablespace_name: 這個字段表示撤銷空間所在的表空間的名稱。表空間是Oracle數據庫中的一個邏輯存儲單位,它包含了數據庫的對象(如表,索引等)和撤銷空間。
????????status: 這個字段表示撤銷空間的當前狀態。狀態可能包括例如"ACTIVE"、"INACTIVE"等。
????????sum(bytes) / 1024 / 1024 M: 這是一個計算撤銷空間總容量的表達式。bytes字段表示撤銷空間的字節大小,通過除以1024*1024將其轉換為MB(兆字節)。結果字段標記為M表示結果將以MB為單位顯示。
????????group by tablespace_name, status: 這部分代碼將結果按照表空間名稱和狀態進行分組。這意味著對于每個獨特的表空間名稱和狀態組合,都會有一個對應的行在結果集中。
????????查詢的結果集將顯示每個獨特的表空間名稱和狀態組合的撤銷空間總容量(以MB為單位)。可以幫助了解數據庫中各個表空間的撤銷空間的總體使用情況。如果發現某個表空間的撤銷空間使用量非常大,那么可能需要增加該表空間的存儲容量,或者優化該表空間的存儲結構。
26、查看ASM磁盤組使用率
select name,round(total_mb / 1024) "總容量",round(free_mb / 1024) "空閑空間",round((free_mb / total_mb) * 100) "可用空間比例"from gv$asm_diskgroup
????????在Oracle數據庫中查詢磁盤組信息
????????name: 這個字段表示磁盤組的名稱。在Oracle磁盤組是用于存儲數據的邏輯卷,可以由多個物理磁盤組成。
????????round(total_mb/1024) "總容量": 這個字段表示磁盤組的總容量。total_mb是磁盤組的總字節數,通過除以1024將其轉換為KB(千字節)。使用round函數對結果進行四舍五入,以保留一位小數。
????????round(free_mb/1024) "空閑空間": 這個字段表示磁盤組的空閑空間大小。free_mb是磁盤組中未使用的字節數,通過除以1024將其轉換為KB(千字節)。使用round函數對結果進行四舍五入,以保留一位小數。
????????round((free_mb/total_mb)*100) "可用空間比例": 這個字段表示磁盤組的可用空間比例。它通過計算未使用的字節數(free_mb)占總字節數(total_mb)的比例,并將其乘以100得到可用空間百分比。?
?
????????通過查詢gv$asm_diskgroup視圖,可以得到數據庫中所有磁盤組的名稱、總容量、空閑空間和可用空間比例的信息。了解數據庫存儲的總體使用情況,。根據查詢結果確定哪些磁盤組已接近滿容量,需要增加存儲空間,或者哪些磁盤組有大量未使用的空間,可以重新分配給其他需要更多空間的磁盤組。此外,磁盤組的可用空間比例也可以及時發現并處理存儲瓶頸問題。
????????Oracle中的ASM磁盤組是一種分布式存儲方案,是Oracle數據庫的一種功能模塊。它主要用于幫助用戶管理磁盤,提高磁盤的調度效率,以及防止數據的丟失
?
?27、統計每個用戶使用表空間率
SELECT c.owner "用戶",a.tablespace_name "表空間名",total/1024/1024 "表空間大小M",free/1024/1024 "表空間剩余大小M",( total - free )/1024/1024 "表空間使用大小M",Round(( total - free ) / total, 4) * 100 "表空間總計使用率%",c.schemas_use/1024/1024 "用戶使用表空間大小M",round((schemas_use)/total,4)*100 "用戶使用表空間率%"
FROM (SELECT tablespace_name,Sum(bytes) freeFROM DBA_FREE_SPACEGROUP BY tablespace_name) a,(SELECT tablespace_name,Sum(bytes) totalFROM DBA_DATA_FILESGROUP BY tablespace_name) b,(Select owner ,Tablespace_Name,Sum(bytes) schemas_useFrom Dba_SegmentsGroup By owner,Tablespace_Name) c
WHERE a.tablespace_name = b.tablespace_name
and a.tablespace_name =c.Tablespace_Name
order by c.owner,a.tablespace_name;
????????用于獲取數據庫中表空間的使用情況,包括表空間的總大小、剩余大小、使用大小以及使用率等。
????????owner :這個字段表示表空間的所有者,即哪個用戶擁有這個表空間。
????????tablespace_name :這個字段表示表空間的名稱。
????????total/1024/1024 :這個字段表示表空間的總大小,單位是MB(兆字節)。它通過將總字節數除以1024*1024得到。
????????free/1024/1024 :這個字段表示表空間的剩余大小,單位是MB(兆字節)。它通過將剩余字節數除以1024*1024得到。
????????(total - free)/1024/1024 :這個字段表示表空間的使用大小,單位是MB(兆字節)。它通過將已使用的字節數(總字節數減去剩余字節數)除以1024*1024得到。
????????Round((total - free) / total, 4) * 100 :這個字段表示表空間的使用率,單位是百分比。它通過計算已使用的字節數占總字節數的比例,并將其乘以100得到,同時使用ROUND函數將其保留到小數點后4位。
????????schemas_use/1024/1024 :這個字段表示用戶在表空間中使用的空間大小,單位是MB(兆字節)。它通過將用戶在表空間中使用的字節數除以1024*1024得到。
????????round((schemas_use)/total,4)*100 :這個字段表示用戶在表空間中的使用率,單位是百分比。它通過計算用戶在表空間中使用的字節數占總字節數的比例,并將其乘以100得到,
?
????????這個查詢的結果集提供了數據庫中表空間的詳細使用情況,包括每個表空間的大小、剩余大小、使用大小和使用率等信息。了解數據庫中各個表空間的存儲情況,及時發現存儲瓶頸并進行優化。
?












)


)


)
