1.前言
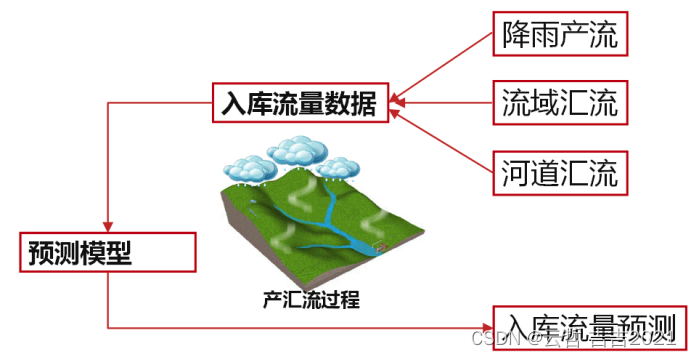
該文檔主要是介紹通過機器學習模型LightGBM進行水電站流量入庫預測。 對于水電站來說,發電是主要經濟效益來源,而水就是生產的原料。對進入水電站水庫的入庫流量進行精準預測,能夠幫助水電站對防洪、發電計劃調度工作進行合理安排,實現避免洪澇災害和提升發電經濟效益的目的。
2.目標
基于歷史數據和當前觀測信息,對電站未來7日入庫流量進行預測(每3小時一個預測值,共56個待預測值)。
3.數據解析
競賽主辦方共提供了4類數據,包括歷史入庫流量數據、環境數據、降雨預報數據以及遙測站降雨觀測數據。數據均為時序數據。
其中入庫流量數據包含時間和流量兩個字段。環境數據提供了溫度、風速、方向三個字段。天氣預報包含了未來五天的降雨情況。遙測站數據則包括了39個點的降雨量。
初賽提供:2013年-2018年的歷史數據
決賽提供:2019年數據
數據維度:3小時為一個粒度點
數據缺失:初賽數據在14年缺少部分數據,決賽未提供18年數據
綜上述,經過對數據的了解和分析,影響模型預測主要歸納為一下四個方面:
?歷史數據存在樣本缺失
?使用何種模型進行預測,NN還是回歸
?如何選取、構造特征,使用特征
?數據的準確性
4.賽題分析與模型選擇
從數據表現來看,是一個完完全全的時序題,針對時序題的做法有很多,找周期擬合、使用NN模型,本人嘗試過LSTM、GRU、RNN、CNN等,通過線下擬合,自劃分樣本進行測試,可以觀測到擬合效果非常好
(如圖4-1),但是反饋則是,只是存在部分段分數很高,部分分段很低,導致結果評分為BR,模型穩定性差。
遂轉換思路,將問題轉換成線性擬合問題,將時序數據看成一個單獨的點,構造特征將時序保留,進行回歸預測,重新構造測試數據,預測的輸出作為下一次預測的輸入,進行預測。最終選擇競賽界比較通用的LightGBM模型進行線性擬合。得到的表現卻是各段分數平平如其,雖然分數較低,但是每一段的偏差相差不大,模型表現較為穩定。相對NN魯棒性更強,這也是為什么在決賽選擇LightGBM的原因。各個特征的重要程度表現如圖4-2所示。
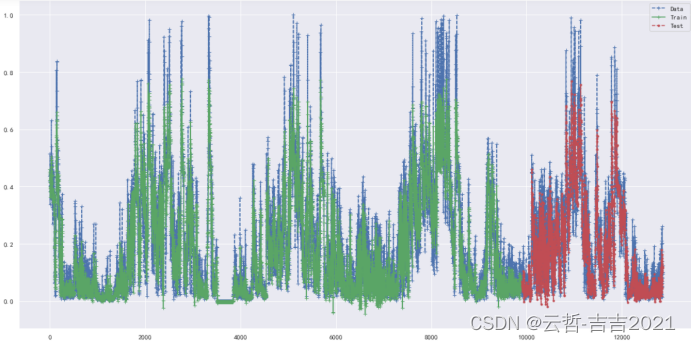
圖4-1 cnn-gru擬合
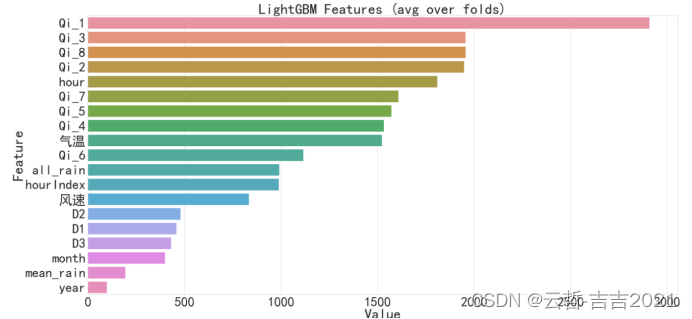
圖4-2 特征重要度
5.方法
?數據預處理
將初賽、復賽數據讀入,相同類別數據進行concat合并。如歷史入庫數據。并將時間轉換成datetime格式。其他三類數據類似處理。

?特征工程、訓練集、測試集構造
1.遙測站數據處理和特征工程
(1)39個遙測站數據直接求和,而且發現遙測站的數據更像是一個類別數據,和QI也存在一定的相關性。
(2)將原始的天數據轉換成入庫流量一直的時序數據3H粒度數據,方便關聯
2.天氣預報數據
(1)這里使用的前期預報不是未來五天,而是前三天的一個天氣預報作為特征輸入。

3.環境數據
(1)環境數據使用當天數據,考慮到風向數據分布不一致的問題,將其剔除,只是用溫度和風速作為特征輸入。
4.入流流量數據
(1)歷史8個點的時刻數據作為特征輸入Q1-Q8
5.保留時序特征
(1)構造年、月、小時、小時IDX特征(保留時序,作為也可以理解為相近數據的權重)

6.數據構造
按照待預測的時間段進行測試集構造。

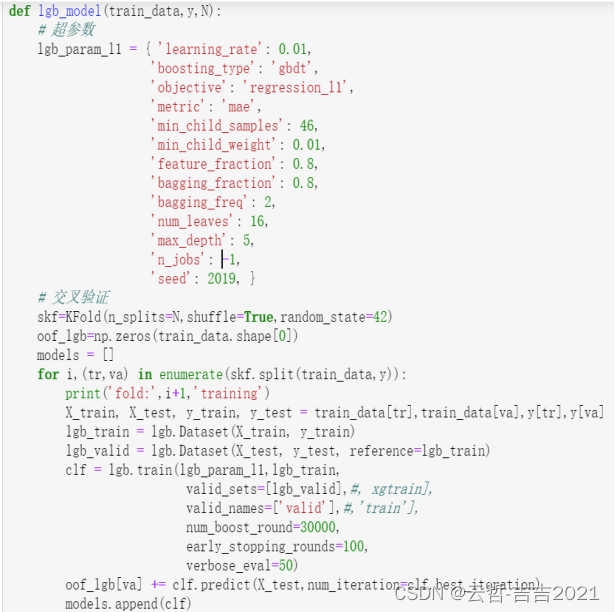
?模型構建
這里使用的是五折的交叉驗證,對最終結果也是5折之后的平均結果。
?結果預測
對5段結果進行分別預測。每一次的輸出作為下一次的輸入,進行構造Q1-Q8的特征更新。五段預測方式一致。

?結果提交
將5段結果數據進行拼接,保存至csv進行提交。

6.總結
從模型表現來看,最終結果五段結果均為負數,但是整體偏差不大,魯棒性比較強,最終五段的平均在-75左右,其他朋友的模型肯定都比這個模型更加精致,從表現來看,他們在其他幾段預測的結果表現都很不錯,比這個模型更強,但是在第四段出現了意外,但這也是數據中不可計算的意外。他們的方案更加值得學習,共同進步,共同學習。
完整代碼下載地址:水電站入庫流量預測









)


)


)



