聚類與判別分析概述
基本概念
聚類分析
????????聚類分析的基本思想是找出一些能夠度量樣本或指標之間相似程度的統計量,以這些統計量為劃分類型的依據,把一些相似程度較大的樣本(或指標)聚合為一類,把另外一些彼此之間相似程度較大的樣本又聚合為一類。根據分類對象的不同,聚類分析可分為對樣本的聚類和對變量的聚類兩種。
?判別分析?
????????判別分析是判別樣本所屬類型的一種統計方法。
樣本間親疏關系的度量
連續變量的樣本間距離常用度量
????????主要方法有歐氏距離(Euclidean Distance)、歐氏平方距離(Squared Euclidean Distance)、切比雪夫距離(Chebychev Distance)、明可斯基距離(Minkowski Distance)、用戶自定義距離(Customize Distance)、Pearson相關系數、夾角余弦(Cosine)等
順序變量的樣本間距離常用度量
????????常用的有 ![]() ?統計量(Chi-square measure)和
?統計量(Chi-square measure)和 ![]() ?統計量(Phi-square measure)。
?統計量(Phi-square measure)。
二者區別
????????不同之處在于,判別分析是在已知研究對象分為若干類型(或組別)并已取得各種類型的一批已知樣本的觀測量數據的基礎上,根據某些準則建立判別式,然后對未知類型的樣本進行差別分析。
說明
- 聚類分析的目的是找到樣本中數據的特點,因此應注意所選擇的變量是否已經能夠反應所要聚類樣本的主要特點。
- 聚類分析時應注意所選擇的變量是否存在數量級上的差別。如果一個樣本包含不同數量的變量,則應先對變量進行標準化處理,而后再進行聚類。
- 變量間的關系度量模型與樣本間相類似,只不過一個用矩陣的行進行計算,另一個用矩陣的列進行計算。
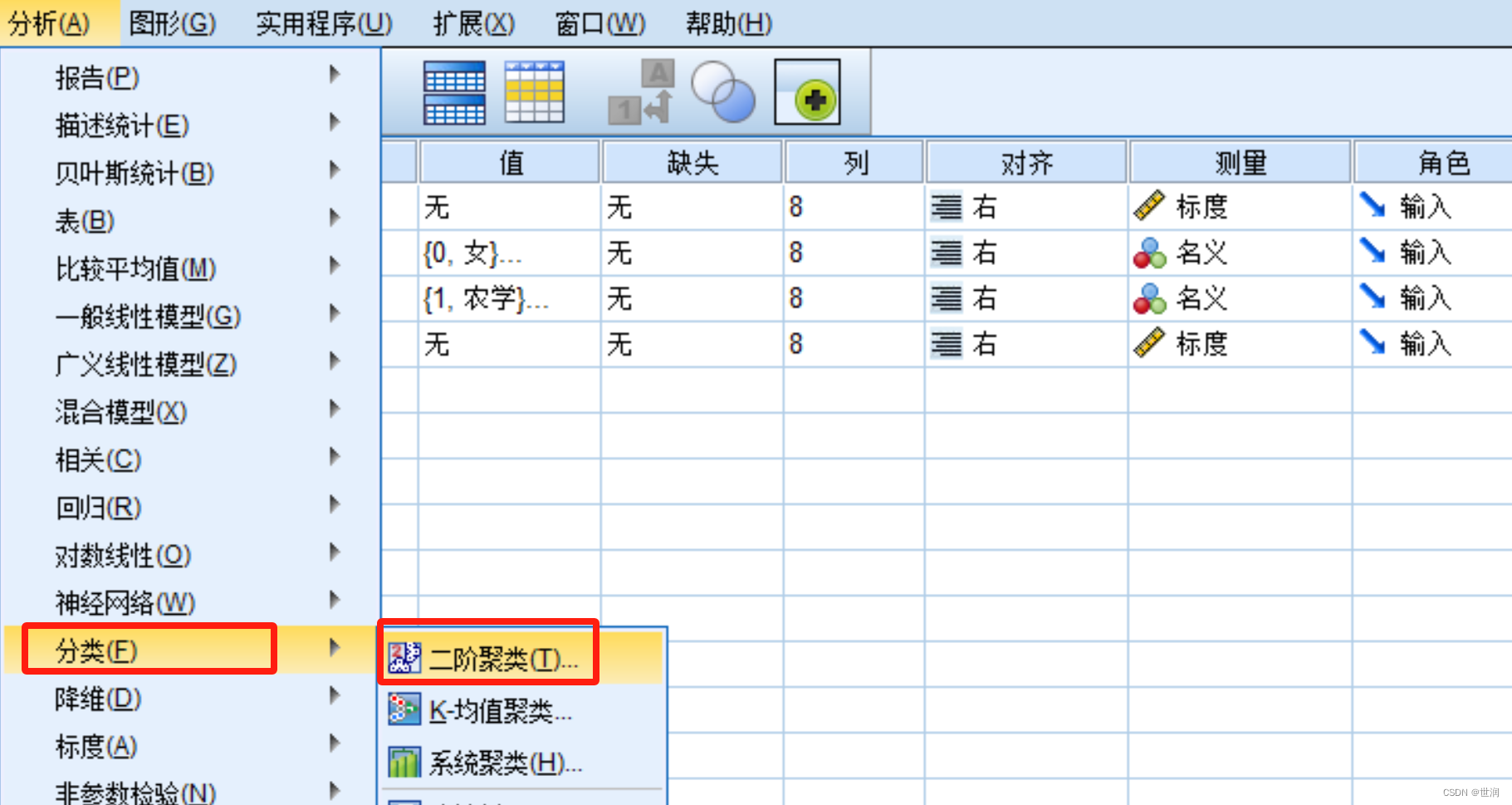
二階聚類
基本概念
????????二階聚類(TwoStep Cluster)(也稱為兩步聚類)是一個探索性的分析工具,為揭示自然的分類或分組而設計,是數據集內部的而不是外觀上的分類。它是一種新型的分層聚類算法(Hierarchical Algorithms),目前主要應用到數據挖掘(Data Mining)和多元數據統計的交叉領域——模式分類中。該過程主要有以下幾個特點:
- 分類變量和連續變量均可以參與二階聚類分析;
- 該過程可以自動確定分類數; 可以高效率地分析大數據集;
- 用戶可以自己定制用于運算的內存容量。
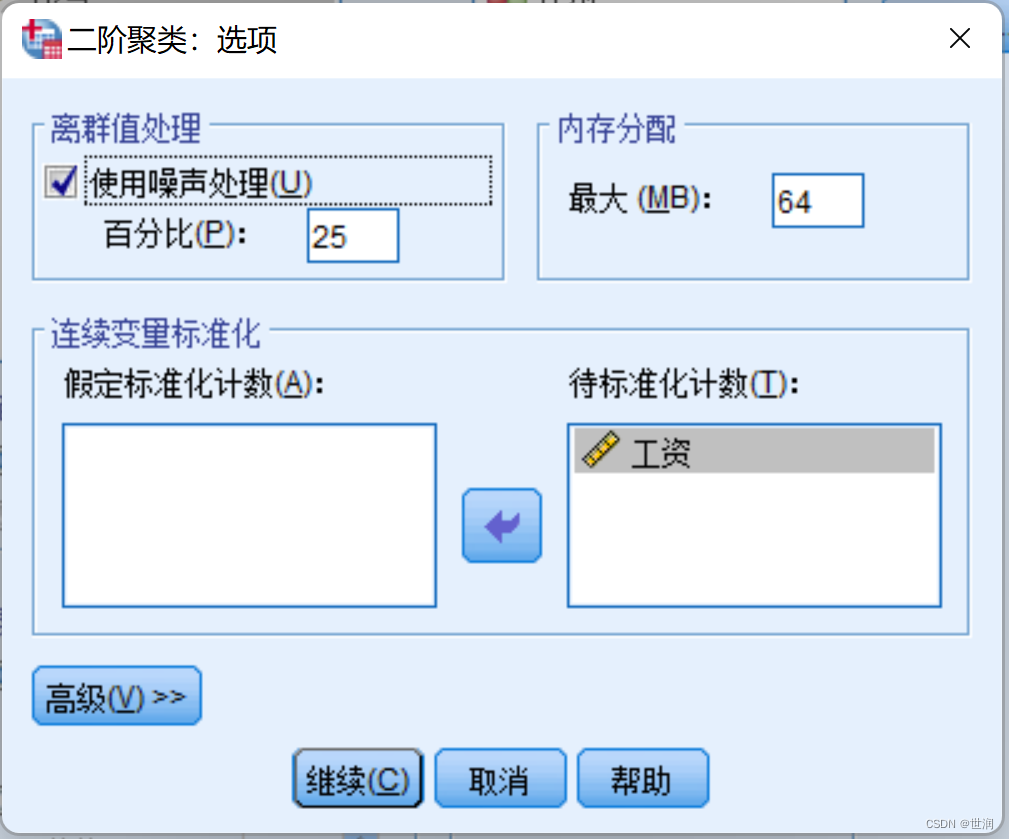
統計原理
????????兩步法的功能非常強大,而原理又較為復雜。他在聚類過程中除了使用傳統的歐氏距離外,為了處理分類變量和連續變量,它用似然距離測度,它要求模型中的變量是獨立的,分類變量是多項式分布,連續變量是正態分布的。分類變量和連續變量均可以參與兩步聚類分析。
分析步驟
第1步 預聚類:對每個觀測變量考察一遍,確定類中心。根據相近者為同一類的原則,計算距離并把與類中心距離最小的觀測量分到相應的各類中去。這個過程稱為構建一個分類的特征樹(CF)。
第2步 正式聚類:使用凝聚算法對特征樹的葉節點分組,凝聚算法可用來產生一個結果范圍。

 ?
?

 ?
?
?????????從中可以看出,此算法采用的是兩步(二階)聚類,共輸入3個變量,將所有個案聚成3類。聚類的平均輪廓值為0.6(其范圍值為-1.0~1.0,值越大越好),說明聚類質量較好。??????
? ? ? ? 因此,數據類別打標??





![LeetCode [簡單] 1. 兩數之和](http://pic.xiahunao.cn/LeetCode [簡單] 1. 兩數之和)





)
)





)

