本文整理自Flink數據通道的Flink負責人、Flink CDC開源社區的負責人、Apache Flink社區的PMC成員徐榜江在云棲大會開源大數據專場的分享。本篇內容主要分為四部分:
- CDC 數據實時集成的挑戰
- Flink CDC 核心技術解讀
- 基于 Flink CDC 的企業級實時數據集成方案
- 實時數據集成 Demo 演示
CDC 數據實時集成的挑戰
首先介紹一下CDC技術,CDC就是Change Data Capture的縮寫,意思是變更數據捕獲。如果有一個數據源的數據隨著時間一直在變化,這種能夠捕獲變更數據的技術就稱之為CDC。但是在真正的業務生產實踐過程中,通常說的CDC都是指面向數據庫的變更,用于捕獲數據庫中某一張表業務,不斷地寫入的新數據、更新的數據、甚至刪除的數據。我們在談到捕獲變更數據的技術時,之所以主要面向數據庫,主要是因為數據庫里面的數據是業務價值最高的數據,數據庫的變更數據也是業務里時效性最高、最寶貴的數據。

CDC技術應用是非常廣泛,主要有三個方面。
第一,數據同步,比如數據備份、系統容災會用到CDC。
第二,數據分發,比如把數據庫里面變化的數據分發到Kafka里面,再一對多分發給多個下游。
第三,數據集成,不管是在數倉構建還是數據湖構建都需要做一個必要工作數據集成,也就是將數據入湖入倉,同時會有一些ETL加工,這個工作中CDC技術也是必不可少的應用場景。

從CDC底層的實現機制上可以將CDC技術分成兩類:基于查詢的CDC技術、基于日志的CDC技術。
基于查詢的CDC技術。假設數據庫有一張表在不斷更新,我們可以每5分鐘查詢一次,查詢里比如按照更新時間字段對比一下看看有哪些新的數據,這樣就能獲取到CDC數據。這種技術需要基于離線調度查詢,是典型的批處理,沒法保證保障數據的強一致性,也不能夠保障實時性。一個離線調度從行業的實踐來看到5分鐘已經是極限了,很難做到分鐘級甚至秒級的離線調度。
基于日志的CDC技術。這就是基于數據庫的變更日志解析變更的技術,比兔大家都知道MySQL的數據庫有Binlog的機制。基于數據庫的變更日志的CDC技術可以做到實時消費日志做流處理,上游只要更新一條數據,下游馬上就能感知到這一條數據,可以保障整個數據的強一致性,還可以提供實時的數據。基于日志的CDC技術通常實現復雜度上會比基于查詢的方式更高一些。
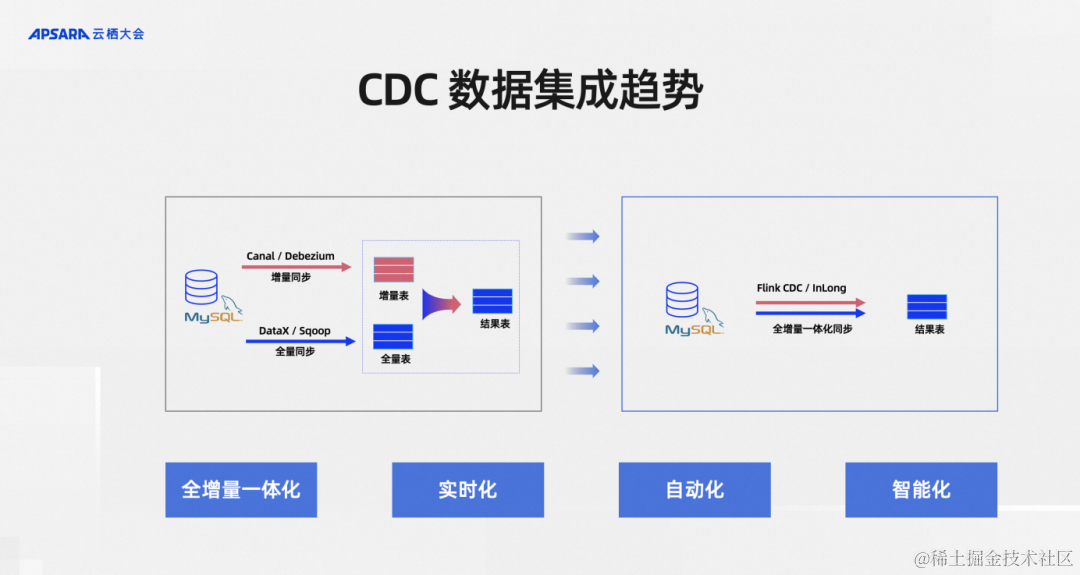
從CDC數據集成這個細分領域的發展趨勢來看,總結了下大致四個方向:
第一,全增量一體化。
第二,實時化。
第三,自動化。
第四,智能化。
全增量一體化是相對于全量和增量分別做數據集成,所以全量很好的例子就是一張MySQL的表有海量的歷史數據。但同時上游的業務系統源源不斷地在往里面實時更新,實時更新的那部分就是增量數據,歷史的那部分就是全量數據
往往這兩部分數據在早期采用不同的工具,比如說全量有國內開源的DataX,海外有Apache Sqoop可以做全量的同步。增量部分比如說國內阿里巴巴開源的Canal、MySQL、Debezium、InLong等等開源項目。用戶一般會結合這兩種類型的工具分別做全量數據和增量數據集成,其代價是需要維護很多組件。全增量一體化就是把這些組件盡可能地減少,比如說采用Flink CDC、InLong這樣的方式來做一個全增量一體化降低運維壓力。
第二個就是實時化,大家都知道為什么我們要提實時化,因為業務數據的時效性越高代表價值越高。比如說一些風控業務、策略配置業務如果能做秒級的處理,和兩天之后才能把數據準備好,其帶來的業務效果是完全不一樣的,所以實時化被日趨重視。
自動化是說我們在做全量和增量去結合的時候,全量完了之后需不需要人為干預,全量同步完了以后增量如何保障銜接,這是CDC框架提供的自動銜接能力還是需要運維人員手動操作,自動化就是將這類手動操作降低,自動化可以說是降低運維成本和產品體驗提升方面的訴求。
智能化就是一張MySQL里面的業務表,隨著業務的變化是不斷在變的,不僅是數據在變,里面的表結構都會變。應對這些場景,數據集成的作業能不能保持健壯,進而能不能自動地、智能地處理上游的這些變更,這是一個智能化的訴求,這也是CDC數據集成的趨勢。

分析了整個CDC數據集成這個細分領域的一些架構演進方向,從中也看到了很多問題,若想去解決,會有哪些技術挑戰呢?大致梳理為四個方面:
第一,歷史數據規模很大,一些MySQL單表能夠達到上億或者基幾十億的級別,在分庫分表的場景,甚至有更大的歷史數據規模。
第二,增量數據那部分實時性要求越來越高,比如說現在的湖倉場景都已經需要5分鐘級的低延遲。在一些更極端的場景中,比如說風控、CEP規則引擎等等應用場景甚至需要秒級、亞秒級的延遲。
第三,CDC數據有一個重要的保序性,全量和增量能不能提供一個跟原始的MySQL庫里面一致性的快照,這樣的保序性需求對整個CDC的集成框架提出了很大的挑戰。
第四,表結構變更,包括新增字段和已有字段的類型變更,比如一個字段業務開發長度升級了,這樣的變更框架能不能自動地支持,這都是CDC數據集成的技術挑戰。
針對這些挑戰,我挑選業界現有的主流開源技術方案,也是幾個大家比較常見進和應用比較廣泛的進行分析,包括 Flink CDC、Debezium、Canal、Sqoop、Kettle,我們分別從一下幾個維度來分析,首先是CDC的機制,就是底層的機制來看它是日志的還是查詢的。

其次是斷點續傳,斷點續傳就是全量數據歷史規模很大,同步到一半的時候能不能停下來再次恢復,而不是從頭開始重刷數據。全量同步維度就是框架支不支持歷史數據同步。全增量一體化維度澤是全量和增量過程是框架解決的還是要開發人員手動解決。架構維度則是評價 CDC框架是可擴展的分布式架構,還是單機版。轉換維度衡量的是CDC數據在數據集成做ETL的時候往往要做一些數據清洗,比如說做一個大小寫轉換,這個框架能不能很好地支持,比如需要做一些數據的過濾,框架能不能很好地支持,以及另外一個就是這個工具的上下游生態,框架上游支持多少數據源,下游的計算引擎能支持哪些,支持寫入的湖倉有哪些,因為在選擇一個CDC數據集成框架或者工具的時候肯定是結合整個大數據團隊其他產品的架構設計統一考慮的。從上述這幾個維度分析,Flink CDC 在這幾個維度下的表現都非常優秀。
Flink CDC 核心技術解讀
剛剛我們說到,Flink CDC這個框架在全增量一體化、分布式架構上等維度下都有一些優勢,我們接下來就來解析一下框架底層的核心技術實現,帶著大家去理解Flink CDC如何具備這些優勢,以及我們設計的一些初衷。
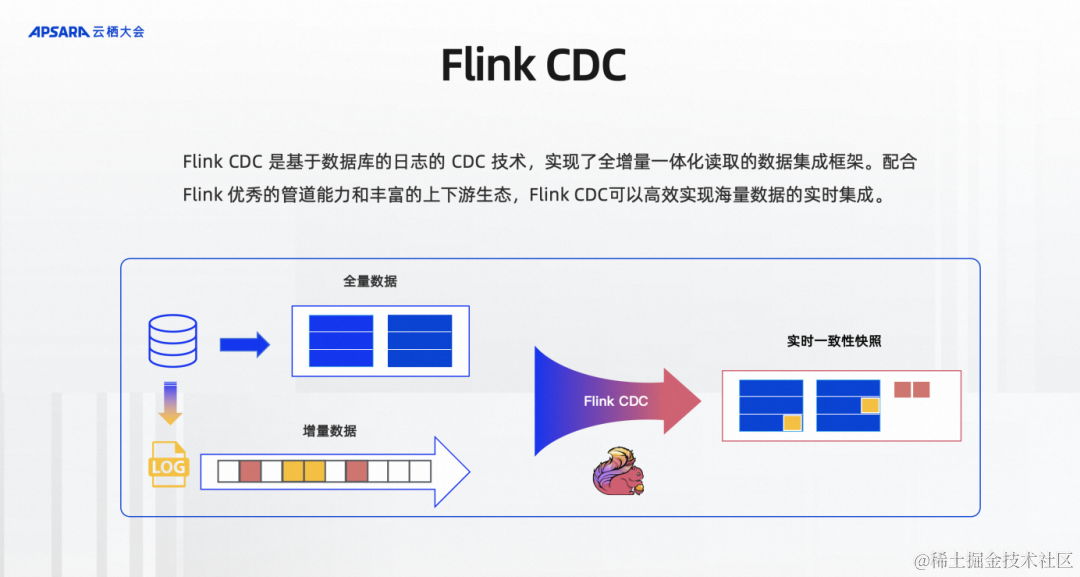
Flink CDC是基于數據庫日志的CDC技術及實現了全增量一體化讀取的數據集成框架,配合Flink優秀的管道能力和豐富的上下游生態,Flink CDC可以高效實現海量數據的實時集成。如圖所示,比如說MySQL有一張表有歷史的全量數據,也有源源不斷寫入的增量數據、業務更新的增量數據MySQL都會先存在自己的Log里面,Flink CDC既讀取全量數據,又通過基于日志的CDC技術讀取增量數據,并且給下游提供實時一致性的快照,框架提供了全量和增量的自動對接,保證了不丟不重的數據傳輸語義,開發者不用關心底層的細節。
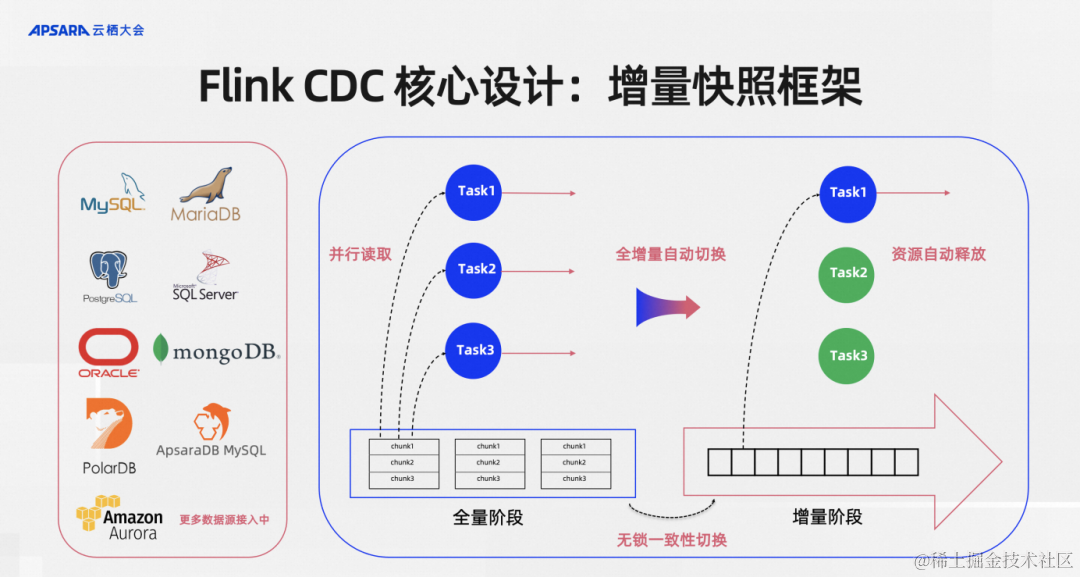
整體來說,Flink CDC有兩個最為核心的設計;
第一個是增量快照框架。這是我在Flink CDC 2.0的時候提出的一個增量快照算法,后面演變成增量快照框架。左邊的這些數據源是現在Flink CDC社區已經支持或者已經接入的增量快照框架。增量快照框架體現的是什么能力呢?在讀取數據一張表到全量數據的時候可以做并行讀取,這張表即使歷史數據規模很大,只要增加并發、擴資源,這個框架是具備水平擴容的能力,通過并行讀取可以達到擴容的需求。
第二個是全量和增量是通過無鎖一致性算法來做到無鎖一致性切換。這其實在生產環境非常重要,在很多CDC的實現里面是需要對MySQL的業務表加鎖來獲得數據一致性的,單這個加鎖會直接影響到上游的生產業務庫,一般DBA和業務同學是不會同意的,如果用增量快照框架是能夠對數據庫不加鎖的,這是對業務非常友好的設計。
切換到增量階段之后結合Flink框架可以做到資源自動釋放的,一般來說全量階段并發是需要很大的,因為數據量很多,增量階段其實寫入MySQL上游基本上都是一個單獨的日志文件寫入,所以一個并發往往就夠了,多余的資源這個框架是可以支持自動釋放的。
總結起來如圖所示四個紅色的關鍵短語突出的就是增量快照框架給Flink CDC提供的核心能力。
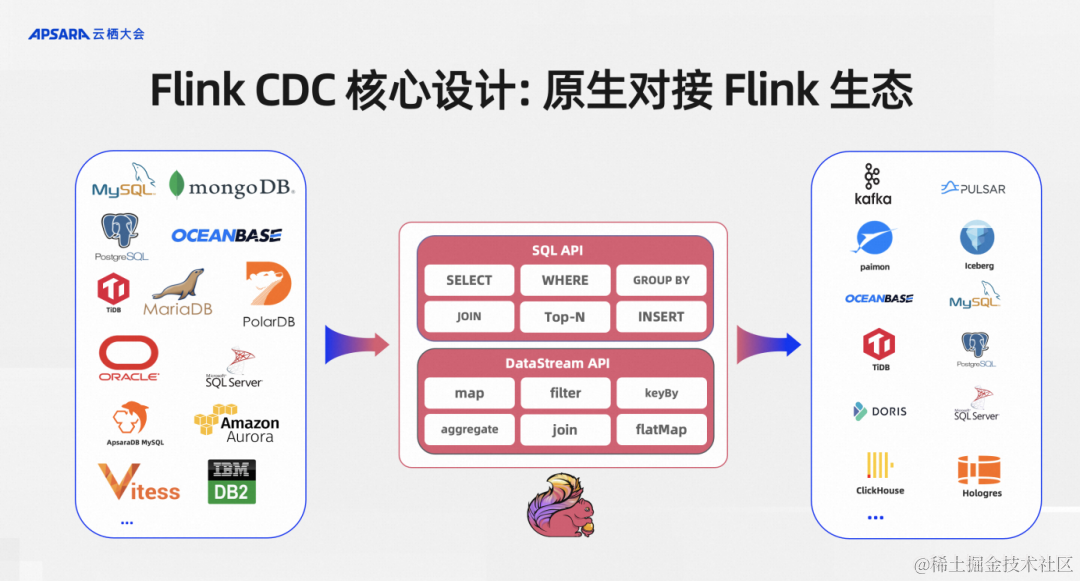
第二個核心設計就是原生對接Flink生態。對接Flink生態最關心的就是能否無縫使用Flink的SQL API、DataStream API以及下游。Flink CDC作為Flink作業的上游時,當前我們所有的connect都是支持SQL API和DataStream API。
支持 SQL API的好處是用戶不需要有底層JAVA開發基礎,會寫SQL就行了,這其實把一個難度系數很高的CDC數據集成交給BI開發同學就可以搞定了。DataStream API則是面向一些更高級的開發者可能要實現一些更復雜、更高級的功能,我們同時提供了DataStream API,讓更底層的開發者通過這種DataStream API 可以通過 Java編程的方式來實現整庫同步、Schema Evolution等高級功能。
在原生對接到Flink的生態之后,Flink上支持的所有下游,比如說消息隊列、Kafka、Pulsar,數據湖Paimon或者傳統的數據庫,Flink CDC 都可以直接寫入。

借助這些核心設計,總體來講:Flink CDC的技術優勢有四個。
第一,并行讀取。這個框架提供了分布式讀取的能力,Flink CDC 這個框架可以支持水平擴容,只要資源夠,讀取的吞吐可以線性擴展。
第二,無鎖讀取。對線上的數據庫和業務沒有侵入。
第三,全增量一體化。全量和增量之間的一致性保障、自動銜接是框架給解決的,無需人工介入。
第四,生態支持。我們可以原生支持Flink現有生態,用戶開發部署成本低。如果說開發者已經是一個Flink用戶,那他不需要安轉額外的組件,更不需要部署比如Kafka 集群,如果是SQL用戶只需要將一個connector jar包放到Flink的lib目錄下即可。
還有一個聽眾可能比較感興趣的點,Flink CDC這個項目是完全開源的,并且從誕生的第一天就是從開源社區出來的,到現在已經從0.x 版本發到最新的2.4.2版本,在全體社區貢獻者的維護下已經走過三年,作為個人興趣項目逐步打磨起來的開源項目,三年的時間這個社區的發展是非常迅速的。我這里說的發展并不只是說Github Star 4500+?的非常快速的發展,其實我們更看重的是代碼Fork數和社區貢獻者數量。Fork數指標表示了有多少組織、多少的開源社區貢獻者在使用Flink CDC倉庫,比如說Apache InLong這樣的頂級項目都是集成了Flink CDC,
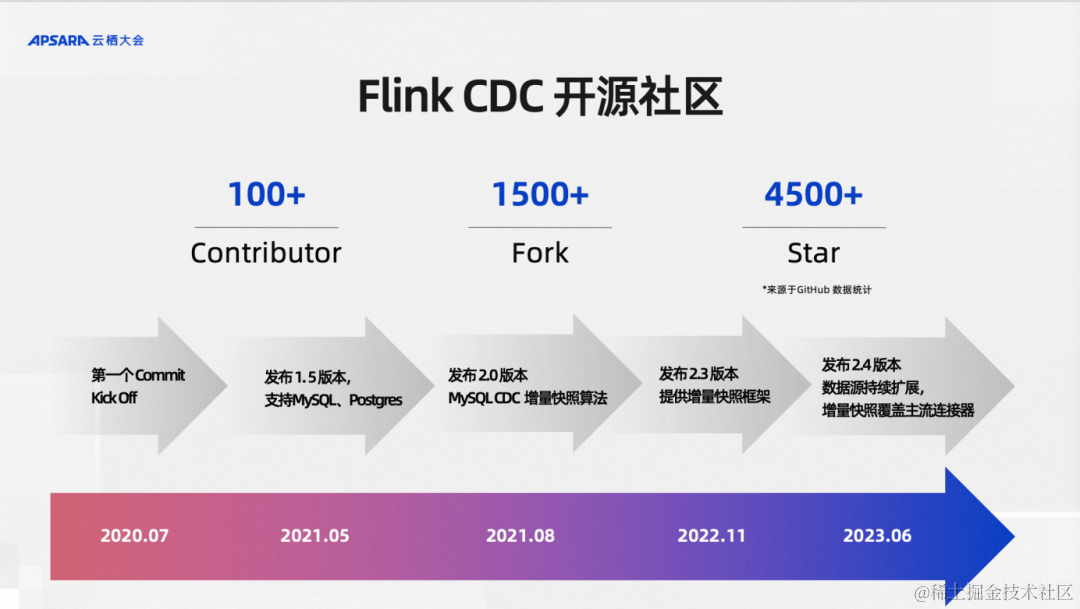
同時這里面不乏海外和國內一些頂級的公司也在用我們的項目。最近我們的開源社區來自國內和海外的貢獻者數量超過100+,這說明我們的開源社區發展還是非常健康的。
講完Flink CDC的開源社區,有一個點大家會關注到,就是它提供的能力還是偏底層引擎,是比較面向底層開發者,離我們最終的數據集成用戶中間還有一層gap,這個gap就是引擎怎么形成產品給最終的用戶。有一個事實需要注意到,數據集成的用戶其實不一定懂Flink,不一定懂Java,甚至不一定懂SQL,那么如何能讓他們使用這個框架?如何提面向用戶的產品來服務好這些用戶?其實很多參與開源的公司、組織都有一些最佳實踐方案。
阿里云基于 Flink CDC 的企業級實時數據集成方案
今天分享的第三部分就是我今天要介紹的,在阿里云內部我們是怎么基于開源的Flink CDC數據集成框架來提供我們的實時數據集成方案,也就是將阿里云的一些實踐方案和大家一起分享。
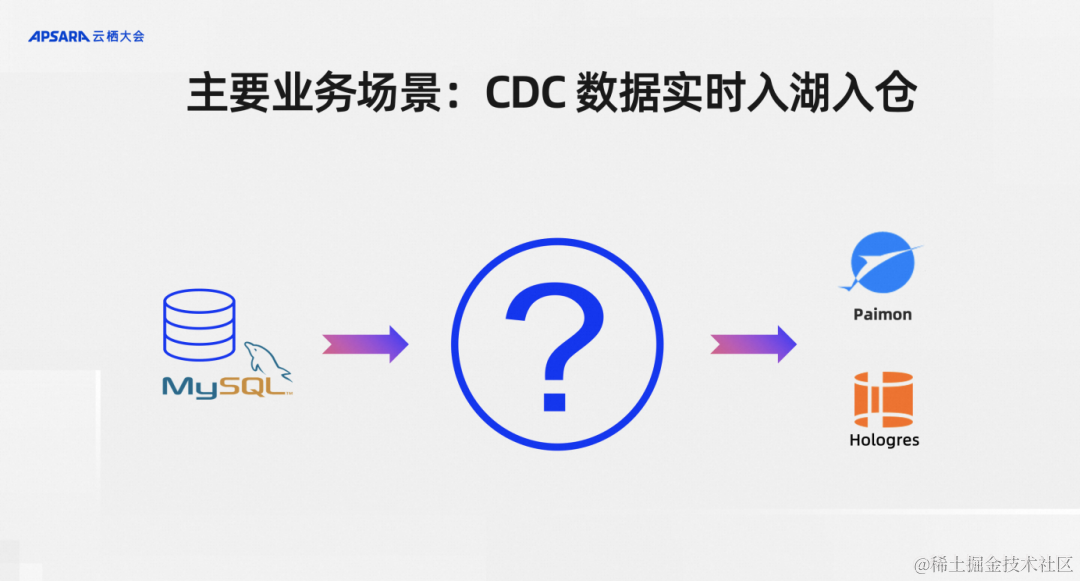
在阿里云上,我們Flink CDC最主要的業務場景就是CDC數據實時入湖入倉。比如說我的業務庫是MySQL,當然其他數據庫也一樣,我其實就是要把MySQL里面的數據一鍵同步到湖倉里面,比如說Paimon、Hologres,?業務場景就是CDC數據實時入湖入倉,這個場景下用戶的核心訴求什么?
我們大致整理了四個關鍵點:需要表結構自動發現,需要表結構的變更自動同步,需要支持整庫同步,需要支持動態加表。
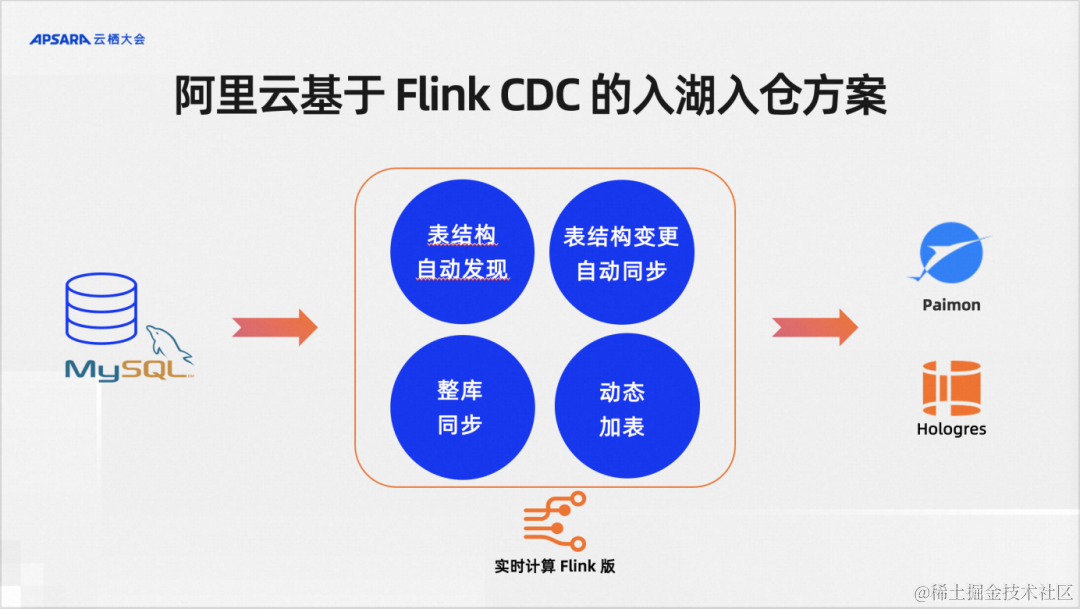
Flink CDC是一個數據集成框架,在阿里云上并沒有單獨的Flink CDC產品,它是在我們serverless Flink,也就是阿里云實時計算Flink版提供了上述的能力。除了在實時計算Flink版,在阿里云另一款產品Dataworks上也提供了基于Flink的CDC數據集成方案。
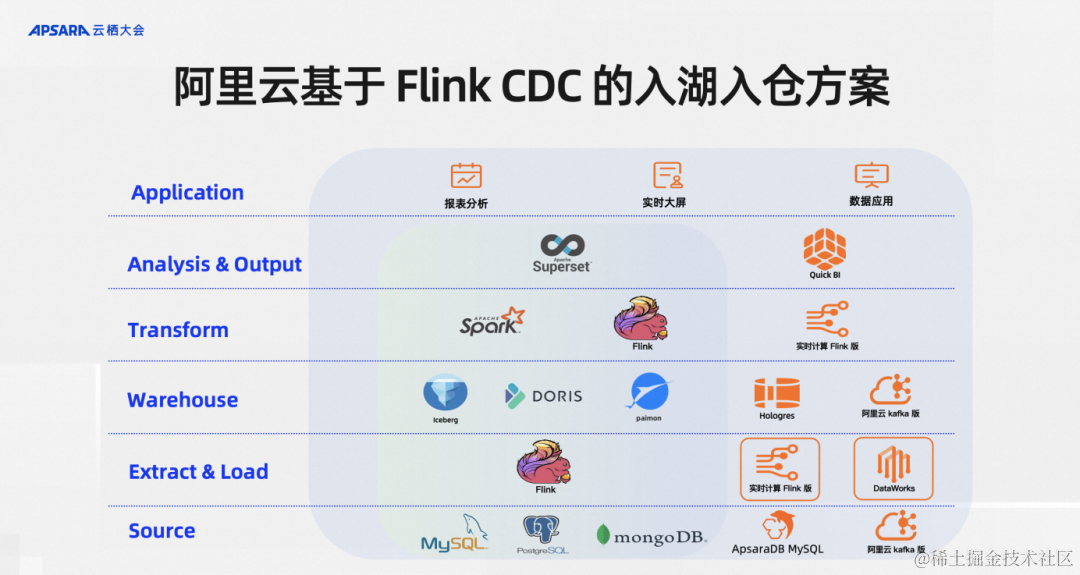
按照現代數據棧的分層理念,Flink CDC 所在處的是EL層,分工特別明確。最下面一層是數據源,Flink CDC專注于做數據集成,在ELT數據集成的模型里里面負責做E和L,當然實踐里面也會支持一些輕量級的T,就是Transform 操作。

在阿里云實時計算Flink版我們設計兩個語法糖,分別是CDAS(Create Database As Database)和CTAS(Create Table As Table)。CDAS就是通過一行SQL實現整庫同步,比如說MySQL里面有一個TPS DS庫同步至Paimon的ODS庫就可以搞定。同時我也提供CTAS,比如說在應對分庫分表的重點業務時,可能對單表要做一些分庫分表的合并,合并到Paimon里面做一個大寬表等等,多個表合成一個表的邏輯。這個表還會做一些事情,比如要推導最寬的表結構,以及分表的表結構變化了之后,在下游最寬的表里面也要看到對應表結構的同步,這些是通過CTAS實現的。

最終的效果是,用戶只需要在實時計算Flink里面寫一行SQL,當這行SQL下面其實做了很多的工作,最終的效果是拉起來了一個Flink數據集成作業。大家可以看到上圖中,作業的拓撲里有四個節點,最前置的一個節點就是讀MySQL的source節點,后面三個節點就是對應我們紅框里面的三張表,自動生成了三個 sink 節點。對于用戶來說就是寫一行SQL,便可以實現全增量一體化的CDC數據集成。
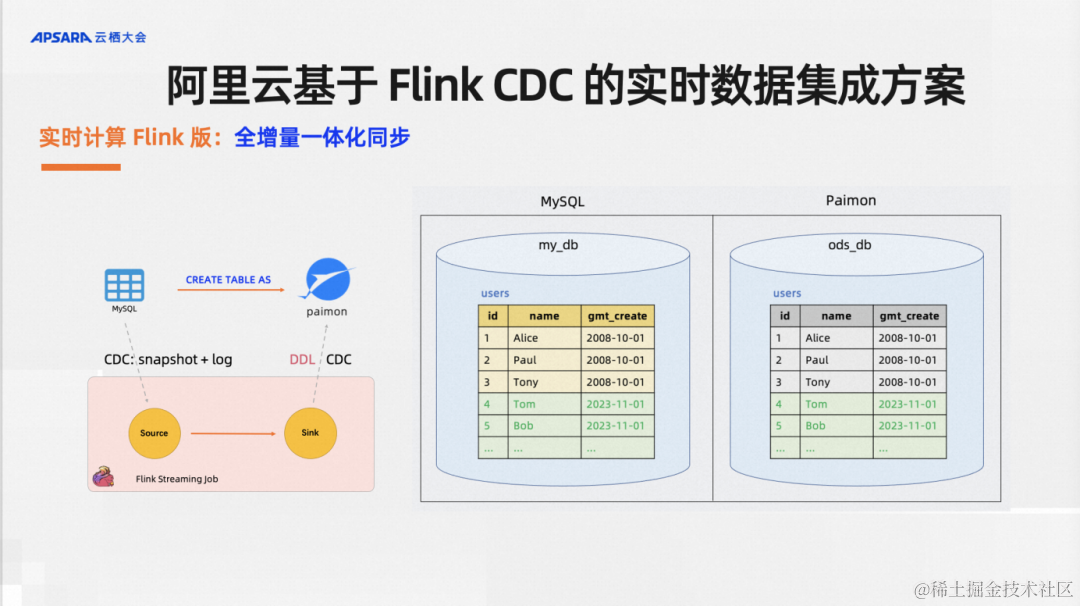
實時計算Flink版里面提供了默認支持全增量一體化同步。舉一個例子,我有一些歷史全量數據和增量數據,一個CTAS語法默認支持全量和增量的數據同步,當然你也可以選擇通過配置不同的參數選擇只同步全量或者只全部增量。
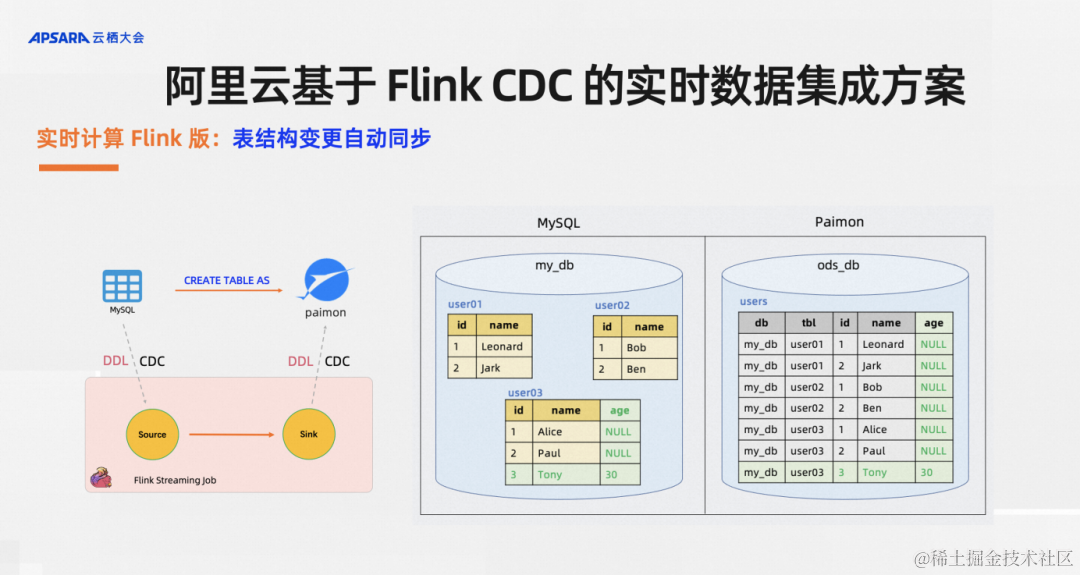
實時計算Flink版還支持表同步變更,比如說有一個分庫分表的場景,庫里有一張名為user03的表,業務同學新加了一個字段age,后續插入的記錄里面也多個了一個age的字段,用戶想要的效果是在下游的湖倉里中自動加列,新的數據能夠自動寫入。對于這樣的需求,CTAS/CDAS語法均默認就支持。
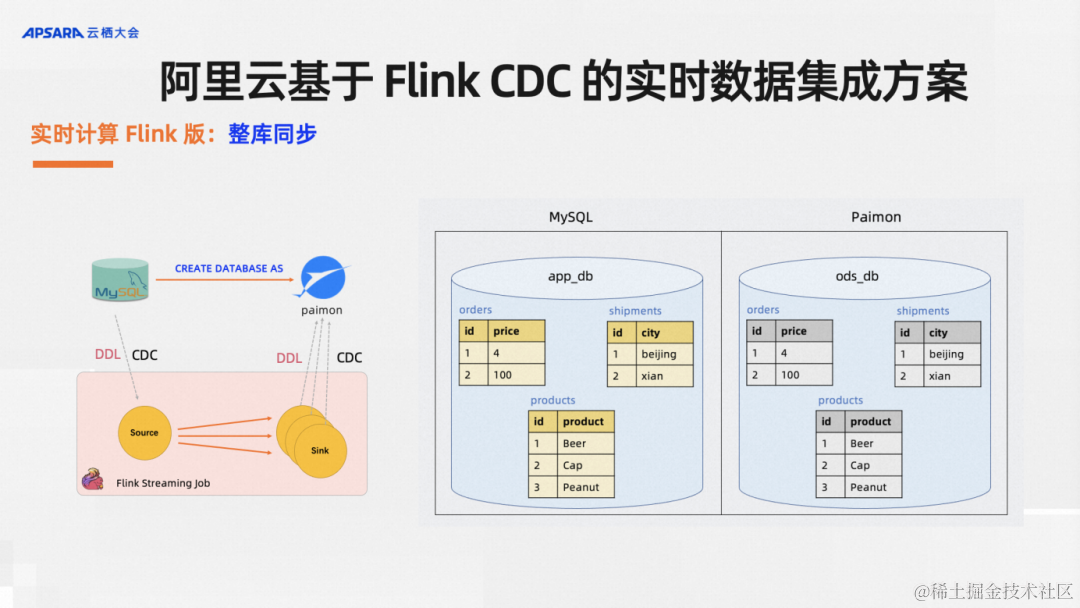
實時計算Flink版支持整庫同步,對于單表同步,每一個表同步都需要寫一行SQL對用戶來說還是太費勁,用戶想要的就是盡可能簡單,功能盡可能強大,CDAS語法糖就是幫用戶干這件事。比如說原庫里面有若干張表,只需要寫一行SQL,我通過捕獲庫里面所有的表,自動改寫多個CTAS語句,然后同步到下游,并且每一張表都支持表結構變更自動同步,源頭這三張表可以各自加列刪列,下游Paimon里的數據自動加列刪列同步。
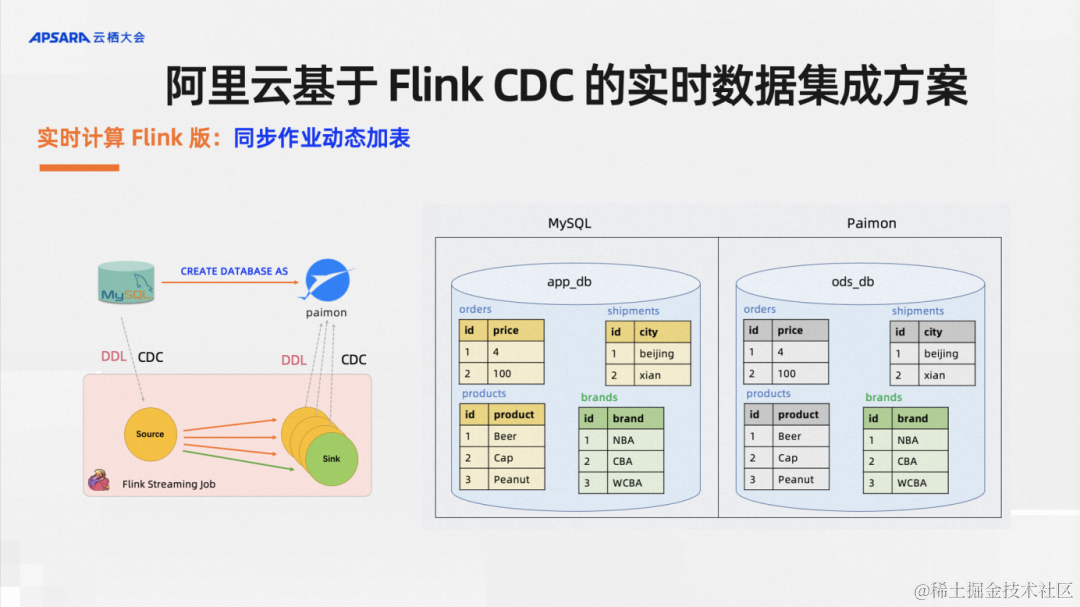
實時計算Flink版還支持同步作業動態加表,在當下IT行業降本增效的背景下,盡可能節省資源能大幅降低業務成本。在CDC數據集成的場景中,比如說我之前的一個作業里面、業務庫里面有1000張表,我用了5CU資源的作業來同步數據。如果說現在業務庫加了兩張表,這個時候我是新起一個作業還是在原有作業里面加表呢?這就是我們開發的動態加表功能,它可以直接復用原有作業的state和資源,不用新開作業的資源,實現動態地給歷史作業加表。這個功能的效果如上圖所示:MySQL庫里面之前有三張表,現在加了一張表,這個歷史同步作業支持把新加的這一張表同步過去,這就是同步作業的動態加表。
上述這個功能是我們在阿里云內部實踐下來業務效果不錯,數據集成的用戶反饋也比較好的一些企業級CDC數據實時集成的方案,分享出來希望可以和同行朋友交流,希望大家可以有收獲。
實時數據集成 Demo 演示
Demo 演示觀看地址:
https://yunqi.aliyun.com/2023/subforum/YQ-Club-0044開源大數據專場回放視頻?02:28:30?-?02:34:00?時間段
在這里,我錄制了一個Demo來演示上述功能,這個Demo 展示了從MySQL到剛剛介紹的Streaming Lakehouse Paimon的CDC數據集成,為大家演示一下怎么在實時計算Flink版里面高效地實現整庫同步、Schema evolution、以及復用歷史作業來實現動態加表。
首先我們創建一個MySQL的Catalog,這在頁面點擊就可以創建,再創建一個Paimon的Catalog。創建好這個Catalog之后就可以寫SQL了,其實有幾個參數設置不設置也可以,這里設置是為了演示時速度更快,我們先寫一個CDAS語句。第一個語句是同步兩張表,訂單表和產品表,把作業提交一下,我只想把庫里面的訂單和產品同步到Paimon里面,這個作業提交稍微等一下,同步兩張表的Flink 作業就生成了。我們可以在控制臺這邊再起一個作業,這個作業可以把Paimon里面的數據撈出來給大家看一下,比如說訂單表里面的數據跟我們上游MySQL的數據是一樣的,并且是實時同步的。MySQL里面馬上插入一行數據,我現在去Paimon里面看一下插入的數據,其實就已經可以看得到了。這個端到端的延遲是非常低的,同時可以演示一個表結構變更功能,從源頭的表中新加一列,用戶不需要做任何操作,在下游Paimon在數據湖里面對應表結構的變更,會自動到Paimon目標表。上游創建加了一個列,現在再插入一列,比如說插入一條數據,后面有一個值新增的列,我把這行數據給插入,接下來我們就看一下我們Paimon里面對應的這張表,大家可以看最后一行這個帶著新增列的數據已經插入了。
接下來給大家演示一下我們動態加表的功能,這是是我們最近在阿里云上剛剛推出的一個重磅功能。一個作業里,之前只同步了訂單表和產品表,現在用戶想添加一張物流表,對于用戶來說只需要改一下之前的SQL,多加一個表名。我們先看一下MySQL上游的這張物流表里的數據,對于用戶來只需要把作業做一個Savepoint停一下,增加下物流表名,重啟一下作業就可以了。我們為什么要從Savepoint重啟,是因為Savepoint保留了一些必要的元數據信息,之前同步兩張表,現在加了一張表,框架會去做一些校驗,把新的表加進去做一個自動的同步,值得注意的是,在這個功能里,我們可以能夠保證原有兩張表的同步數據不斷流繼續同步,新的表支持全增量一體化同步。現在的作業有第三張表了,就是新增的物流表的同步。我們也可以在Paimon里面通過Flink查一下,可以看到表里面的數據都已經同步了,不僅是全量數據,如果有新增的表的增量數據也可以做實時的同步,這個延遲也是非常低的,這是得益于CDC的框架和Flink整體框架提供的一個端到端低延遲。
整體demo就到這里,從這個Demo大家可以看到我們在阿里云這個數據集成的實踐方案上,是比較面向用戶,從最終端的數據集成用戶出發盡量為用戶屏蔽掉Flink、DataStream或者說Java API甚至是SQL的概念,讓用戶的操作盡可能地簡單,比如說他可以在頁面點擊創建一個Catalog,后面再寫幾行簡單的SQL即可實現CDC數據集成。此外,我們也有一些同步作業模板,對于同步模板來說,用戶都不需要寫SQL,直接在頁面點擊就能夠編輯出一個CDC數據集成作業。整體來說,我們在產品的設計上,一個核心理念就是面向數據集成的終端用戶,而不是面向于社區的貢獻者和開發者,這樣更利于我們這個方案推廣到更多的用戶。

SpringMVC的視圖)






)










