文章目錄
- 什么是緩存?
- 為什么要使用緩存
- 如何使用緩存
- 功能實現
- 緩存模型和思路
- 代碼實現
- 緩存更新策略
- 數據庫緩存不一致解決方案
- 代碼實現
什么是緩存?
緩存(Cache),就是數據交換的緩沖區,俗稱的緩存就是緩沖區內的數據,一般從數據庫中獲取,存儲于本地代碼(例如:
例1:Static final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(); 本地用于高并發例2:static final Cache<K,V> USER_CACHE = CacheBuilder.newBuilder().build(); 用于redis等緩存例3:Static final Map<K,V> map = new HashMap(); 本地緩存
由于其被Static修飾,所以隨著類的加載而被加載到內存之中,作為本地緩存,由于其又被final修飾,所以其引用(例3:map)和對象(例3:new HashMap())之間的關系是固定的,不能改變,因此不用擔心賦值(=)導致緩存失效;
為什么要使用緩存
緩存數據存儲于代碼中,而代碼運行在內存中,內存的讀寫性能遠高于磁盤,緩存可以大大降低用戶訪問并發量帶來的服務器讀寫壓力。
實際開發過程中,企業的數據量,少則幾十萬,多則幾千萬,這么大數據量,如果沒有緩存來作為"避震器",系統是幾乎撐不住的,所以企業會大量運用到緩存技術;
但是緩存也會增加代碼復雜度和運營的成本:
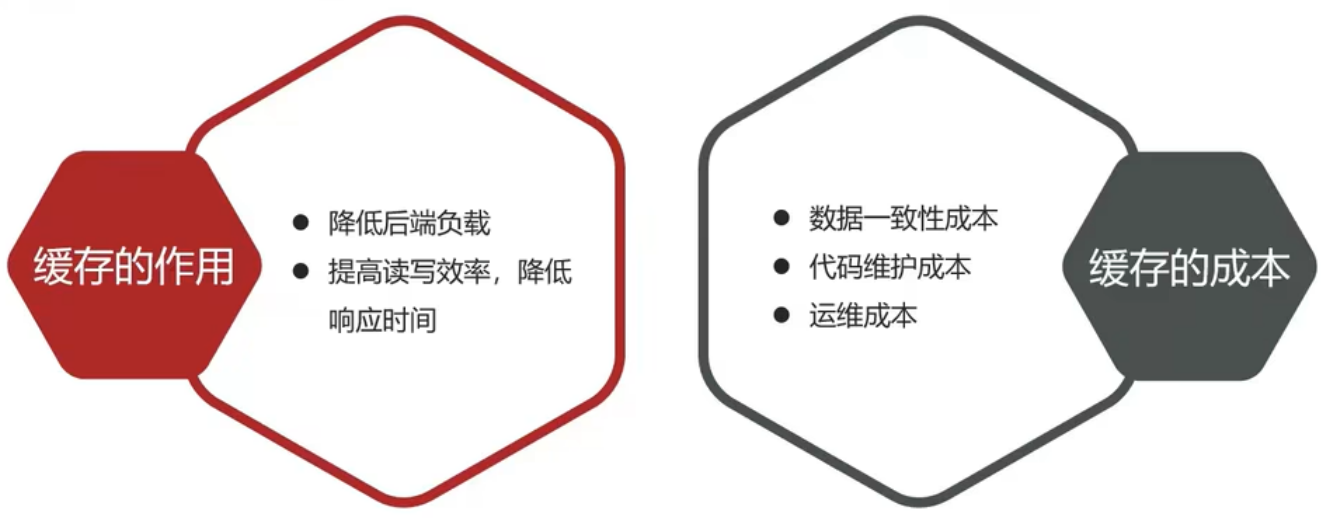
如何使用緩存
實際開發中,會構筑多級緩存來使系統運行速度進一步提升,例如:本地緩存與redis中的緩存并發使用
瀏覽器緩存:主要是存在于瀏覽器端的緩存
應用層緩存:可以分為tomcat本地緩存,比如之前提到的map,或者是使用redis作為緩存
數據庫緩存:在數據庫中有一片空間是 buffer pool,增改查數據都會先加載到mysql的緩存中
CPU緩存::當代計算機最大的問題是 cpu性能提升了,但內存讀寫速度沒有跟上,所以為了適應當下的情況,增加了cpu的L1,L2,L3級的緩存
功能實現
緩存模型和思路
大體的思路是,把每次讀取數據時,先從redis查詢是否有數據,如果沒有數據就從數據庫中查詢,然后把查詢到的數據返回給前端,并且把數據寫入redis。但是這個模型仍然存在一些問題,這些問題我們會在下面介紹。
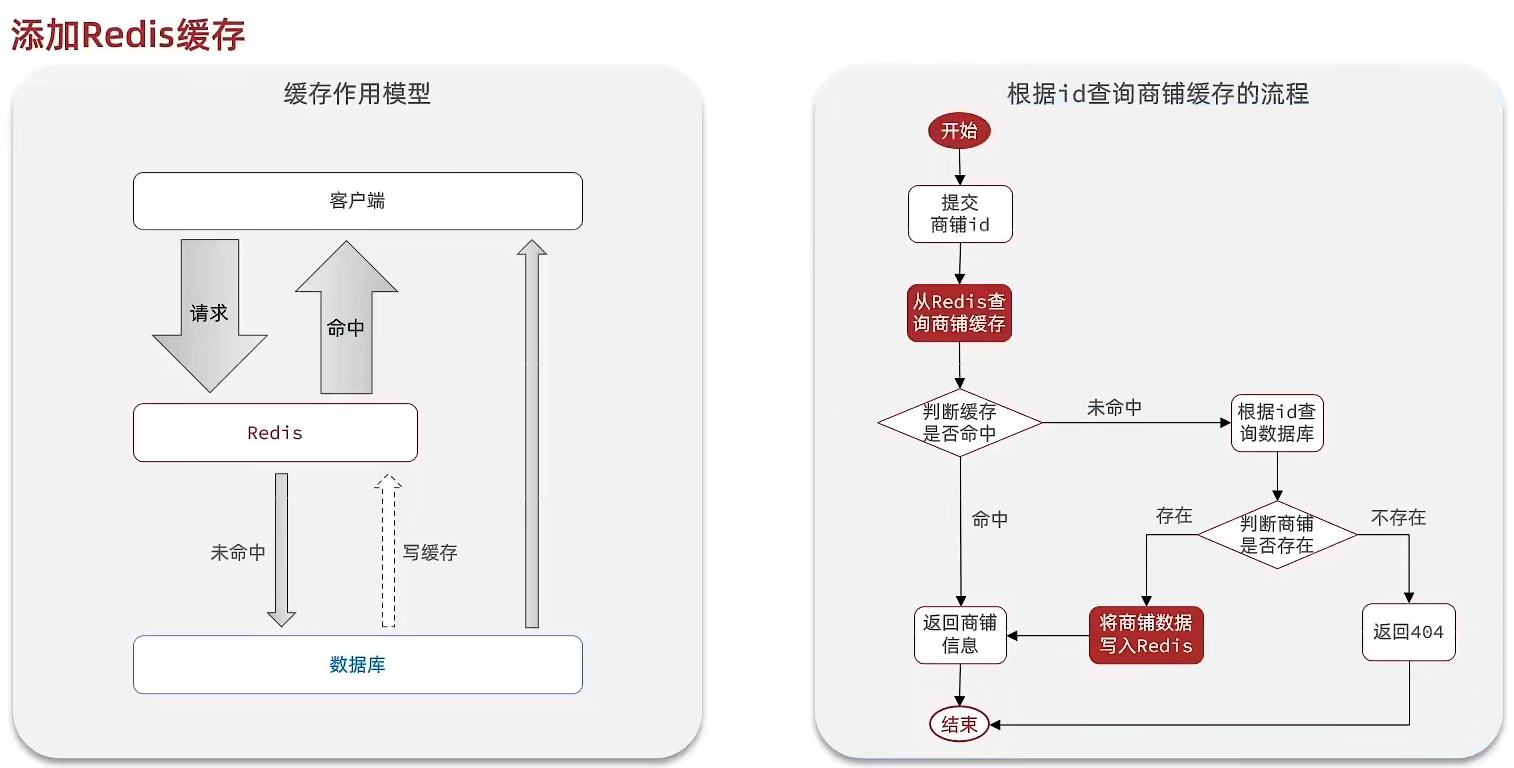
代碼實現
代碼思路:如果緩存有,則直接返回,如果緩存不存在,則查詢數據庫,然后存入redis。
@Overridepublic Result queryById(Long id) [String key = "cache:shop:" + id;// 1.從redis查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isNotBlank(shopJson)) [// 3,存在,直接返回Shop shop = JSONUtil.toBean(shopJson,Shop.class);return Result.ok(shop);}// 4.不存在,根id查詢數據庫Shop shop = getById(id);// 5,不存在,返回錯誤if (shop == null) [return Result,fail("店鋪不存在!");}// 6.存在,寫AredisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));// 7.返回return Result.ok(shop);
}
緩存更新策略
緩存更新是redis為了節約內存而設計出來的一個東西,主要是因為內存數據寶貴,當我們向redis插入太多數據,此時就可能會導致緩存中的數據過多,所以redis會對部分數據進行更新,或者把他叫為淘汰更合適。
內存淘汰:redis自動進行,當redis內存達到咱們設定的max-memery的時候,會自動觸發淘汰機制,淘汰掉一些不重要的數據(可以自己設置策略方式)
超時剔除:當我們給redis設置了過期時間ttl之后,redis會將超時的數據進行刪除,方便咱們繼續使用緩存
主動更新:我們可以手動調用方法把緩存刪掉,通常用于解決緩存和數據庫不一致問題
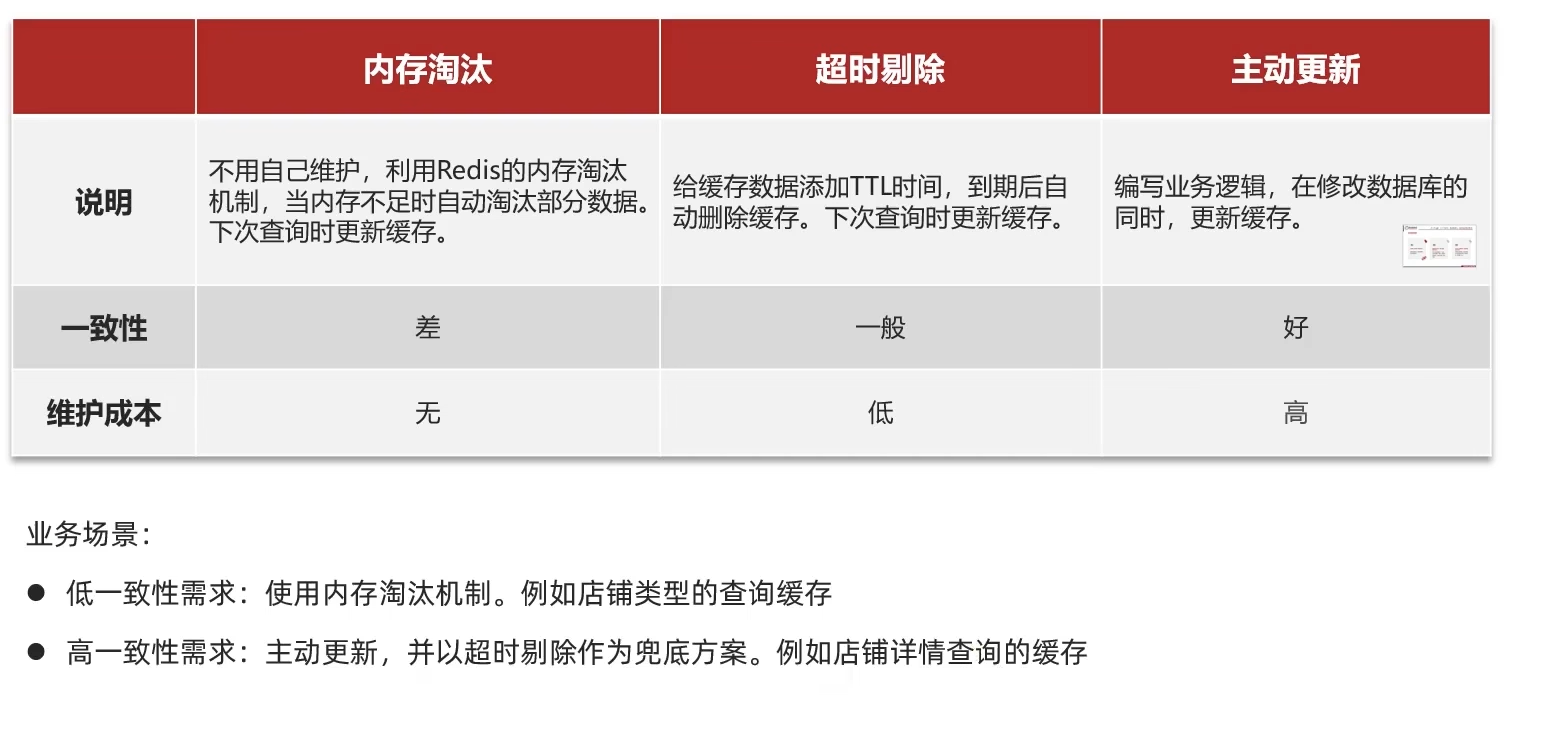
數據庫緩存不一致解決方案
由于我們的緩存的數據源來自于數據庫,而數據庫的數據是會發生變化的,因此,如果當數據庫中數據發生變化,而緩存卻沒有同步,此時就會有一致性問題存在,其后果是:造成了數據不一致。
解決方案:
- Cache Aside Pattern 人工編碼方式:緩存調用者在更新完數據庫后再去更新緩存,也稱之為雙寫方案
- Read/Write Through Pattern : 由系統本身完成,數據庫與緩存的問題交由系統本身去處理
- Write Behind Caching Pattern :調用者只操作緩存,其他線程去異步處理數據庫,實現最終一致
操作緩存和數據庫時有三個問題需要考慮:
如果采用第一個方案,那么假設我們每次操作數據庫后,都操作緩存,但是中間如果沒有人查詢,那么這個更新動作實際上只有最后一次生效,中間的更新動作意義并不大,我們可以把緩存刪除,等待再次查詢時,將緩存中的數據加載出來
-
刪除緩存還是更新緩存?
- 更新緩存:每次更新數據庫都更新緩存,無效寫操作較多
- 刪除緩存:更新數據庫時讓緩存失效,查詢時再更新緩存
-
如何保證緩存與數據庫的操作的同時成功或失敗?
- 單體系統,將緩存與數據庫操作放在一個事務
- 分布式系統,利用TCC等分布式事務方案
應該具體操作緩存還是操作數據庫,我們應當是先操作數據庫,再刪除緩存,原因在于,如果你選擇第一種方案,在兩個線程并發來訪問時,假設線程1先來,他先把緩存刪了,此時線程2過來,他查詢緩存數據并不存在,此時他寫入緩存,當他寫入緩存后,線程1再執行更新動作時,實際上寫入的就是舊的數據,新的數據被舊數據覆蓋了。
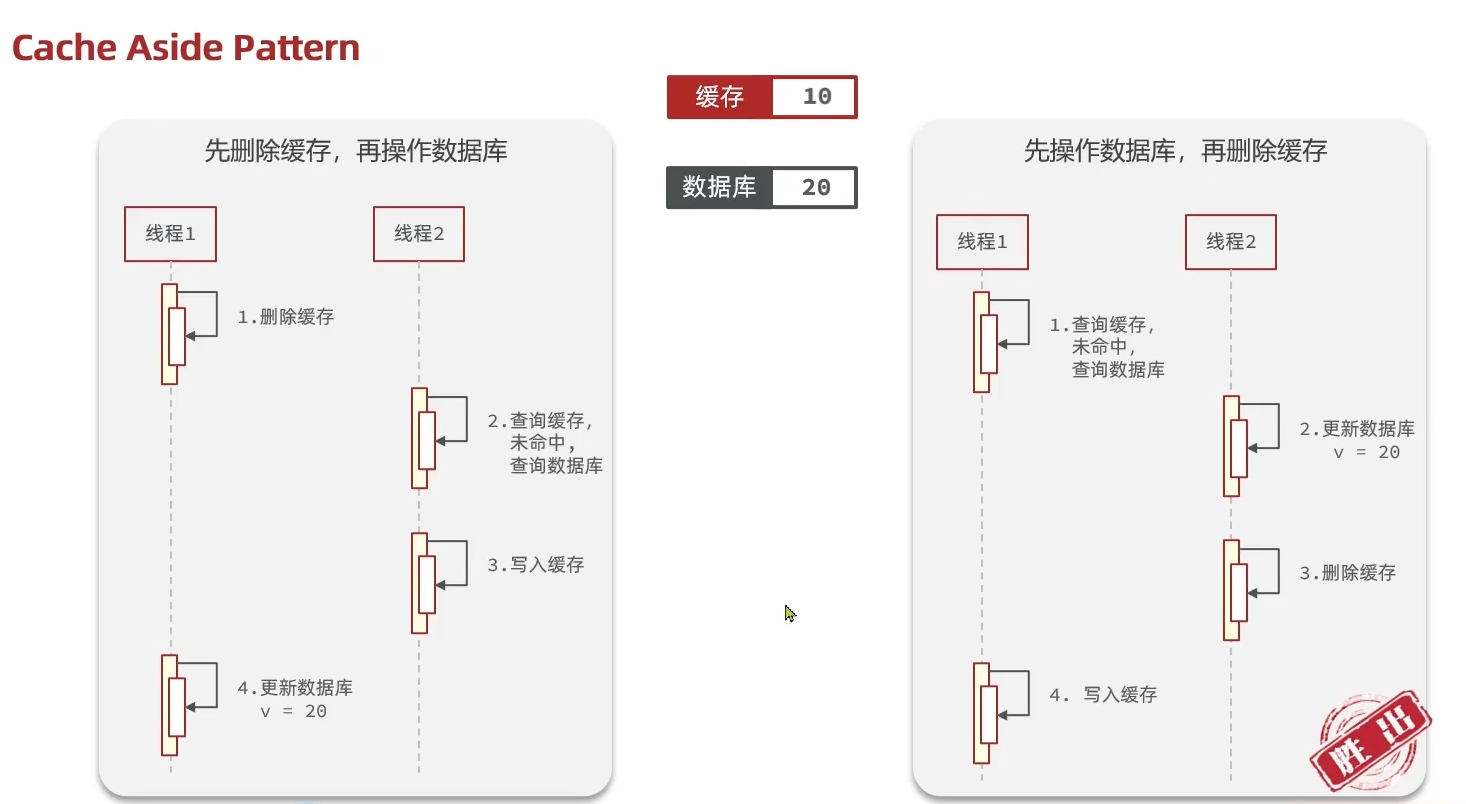
代碼實現
我們首先要在業務代碼里添加redis邏輯緩存的過期時間。
@Overridepublic Result queryById(Long id) [String key = "cache:shop:" + id;// 1.從redis查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isNotBlank(shopJson)) [// 3,存在,直接返回Shop shop = JSONUtil.toBean(shopJson,Shop.class);return Result.ok(shop);}// 4.不存在,根id查詢數據庫Shop shop = getById(id);// 5,不存在,返回錯誤if (shop == null) [return Result,fail("店鋪不存在!");}// 6.存在,寫redis,添加過期時間stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), timeout: 30L,TimeUnit.MINUTES);// 7.返回return Result.ok(shop);
}
插入代碼修改,當我們修改了數據之后,然后把緩存中的數據進行刪除,查詢時發現緩存中沒有數據,則會從mysql中加載最新的數據,從而避免數據庫和緩存不一致的問題
@Overridepublic Result updateShop(Shop shop) {Long id = shop.getId();if(id==null){return Result.fail("店鋪id不能為空");}updateById(shop);//添加的更新后刪除的代碼stringRedisTemplate.delete(CACHE_SHOP_KEY+id);return Result.ok();}



)

![[項目管理-33/創業之路-87/管理者與領導者-127]:如何提升自己項目管理的能力和水平](http://pic.xiahunao.cn/[項目管理-33/創業之路-87/管理者與領導者-127]:如何提升自己項目管理的能力和水平)







—介紹》)





