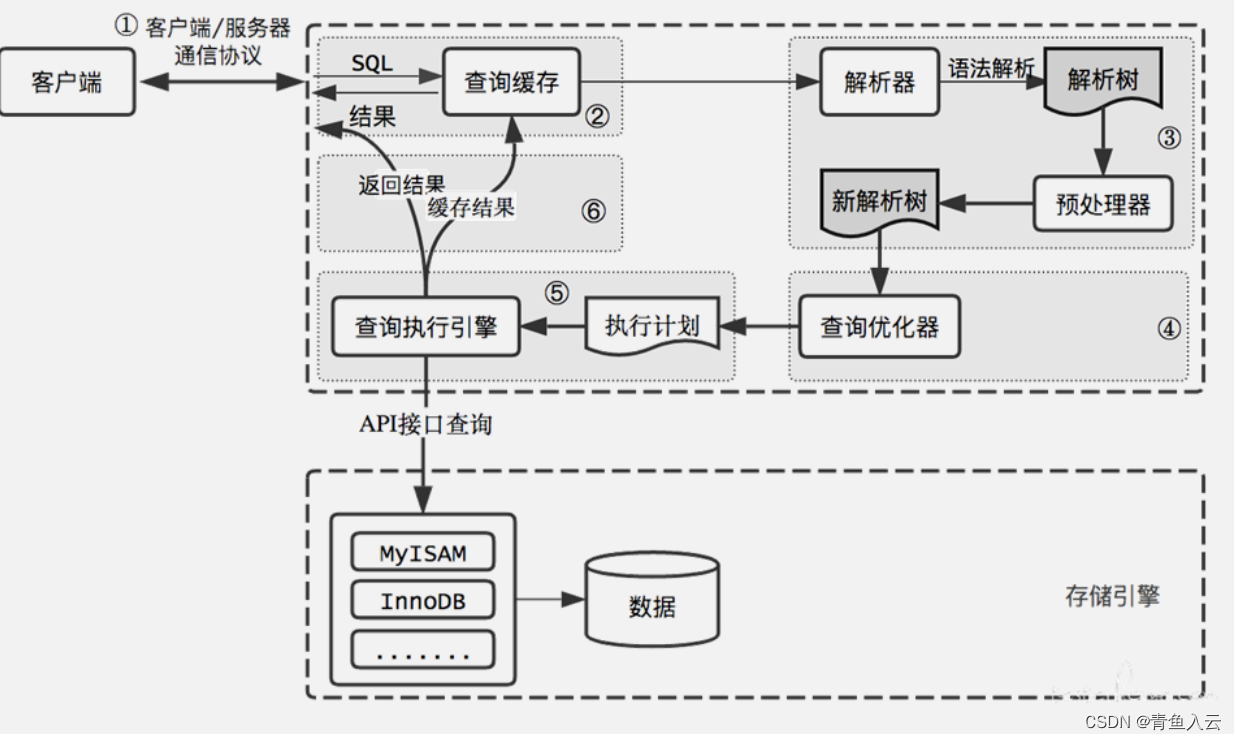
一條 SQL 的執行過程可以大致分為以下幾個步驟:
- 連接器:
○ 客戶端與數據庫建立連接,并發送 SQL 語句給數據庫服務。
○ 連接器驗證客戶端的身份和權限,確保用戶有足夠的權限執行該 SQL 語句。- 查詢緩存:
○ 連接器首先檢查查詢緩存,嘗試找到與當前 SQL 語句完全相同的查詢結果。
○ 如果在緩存中找到匹配的結果,查詢緩存直接返回結果,避免了后續的執行過程。- 分析器:
○ 若查詢不命中緩存,連接器將 SQL 語句傳遞給分析器進行處理。
○ 分析器對 SQL 語句進行語法分析,確保語句的結構和語法正確。
○ 分析器還會進行語義分析,檢查表、列、函數等對象的存在性和合法性,并進行權限驗證。- 優化器:
○ 分析器將經過驗證的 SQL 語句傳遞給優化器。
○ 優化器根據統計信息和數據庫的規則,生成多個可能的執行計劃,這些計劃包括不同的索引選擇、連接順序、篩選條件等。
○ 目的是選出最優的執行路徑以提高查詢性能。- 執行器:
○ 優化器選擇一個最優的執行計劃,并將其傳遞給執行器。
○ 執行器根據執行計劃執行具體的查詢操作。
○ 它負責調用存儲引擎的接口,處理數據的存儲、檢索和修改。
○ 執行器會根據執行計劃從磁盤或內存中獲取相關數據,并進行聯接、過濾、排序等操作,生成最終的查詢結果。- 存儲引擎:
○ 執行器將查詢請求發送給存儲引擎組件。
○ 存儲引擎組件負責具體的數據存儲、檢索和修改操作。
○ 存儲引擎根據執行器的請求,從磁盤或內存中讀取或寫入相關數據。- 返回結果:
○ 存儲引擎將查詢結果返回給執行器。
○ 執行器將結果返回給連接器。
○ 最后,連接器將結果發送回客戶端,完成整個執行過程。需要注意的是,查詢緩存在一些場景下可能不太適用,因為它有一定的缺陷和開銷。MySQL 8.0 版本開始,默認情況下查詢緩存已被廢棄。因此,在實際應用中,需要權衡是否使用查詢緩存。



)


發布!)










目前對數據庫解決)

