1,YARN組件
1.1YARN簡介
YARN表示分布式資源調度,簡單地說,就是:以分布式技術完成資源的合理分配,讓MapReduce能高效完成計算任務。
YARN是Hadoop核心組件之一,用于提供分布式資源調度服務。
而在Hadoop 1.x時,這個過程主要是通過MapReduce中的TaskTracker、JobTracker通信來完成。
這種架構方案主要缺點是:
1)服務器集群資源調度管理和MapReduce執行過程耦合在一起;
2)如果想在當前集群中運行其他計算任務,比如Spark、Storm,則無法統一使用集群中的資源。
在早期Hadoop時,大數據技術就只有Hadoop一家,這個缺點并不明顯。
但隨著大數據技術的發展,各種新的計算框架不斷出現,我們不可能為每一種計算框架部署一個服務器集群,而且就算能部署新集群,數據還是在原來集群的HDFS上,這嚴重阻礙了大數據技術的發展。
由此,在Hadoop 2.x引來了最主要變化:將Yarn從MapReduce中分離出來,成為一個獨立的資源調度框架。
可別小瞧了這個做法,單獨分離出YARN帶來的優勢尤其明顯:
(1)解耦了MapReduce框架,專注于計算;
(2)分工更加明確、精細化;[專業的事由專業的人去做]
(3)正因為有了分離YARN,后期誕生了一個個優秀的專注于計算引擎的大數據框架,比如Spark、Flink等。
Yarn是"Yet Another Resource Negotiator"的縮寫,字面意思就是:另一種資源調度器。主要區別于當時已有的另一些資源調度器產品,比如Mesos等。通常情況下,YARN是與MapReduce交互配合使用,并給MapReduce合理分配資
源。
比如,MapReduce程序向YARN申請資源,YARN合理分配資源。
當成功分配好資源后,MapReduce即可完成計算任務,而空閑資源也可供其它程序使用。
Hadoop架構有三大核心組件,分別是:HDFS、MapReduce、YARN。
1.2YARN架構組成
在了解YARN架構之前,先來了解一下三個名詞:
(1)資源
服務器硬件資源,如CPU、內存、硬盤、網絡等
(2)資源調度
管控硬件資源,提升服務器的利用率
(3)分布式資源調度
管控整個分布式服務器集群的全部資源,并整合進行統一調度
YARN架構是由四個模塊組成,分別是:
a)ResourceManager(資源管理器):用于接收用戶的計算請求任務,并負責集群
的資源分配;
b)NodeManager(節點管理器):單個服務器的資源調度者,負責調度單個服務
器資源并提供給程序使用;
c)ApplicationMaster(任務管理器):單個任務運行的管理者;
d)Client Application:客戶端提交的應用程序。
會發現,ResourceManager與NodeManager是Yarn資源調度的核心模塊。
YARN分布式資源調度,也遵循中心化模式(主從模式),有兩個核心角色:
(1)主(Master)角色:ResourceManager
(2)從(Slave) 角色:NodeManager
1.3YARN提交MR的流程
了解YARN的基本執行流程?
1)我們向Yarn提交應用程序,包括ApplicationMaster、我們的MapReduce程序,以及MapReduce程序啟動命令;
2)ResourceManager進程和NodeManager進程通信,根據集群資源,為用戶程序分配第一個容器,并將ApplicationMaster分發到這個容器上面,并在容器里面啟ApplicationMaster;
3)ApplicationMaster啟動后,立即向ResourceManager進程注冊,并為自己的應用程序申請容器資源;
4)ApplicationMaster申請到需要的容器后,立即和相應的NodeManager進程通信,將用戶MapReduce程序分發到NodeManager進程所在服務器,并在容器中運行,運行的就是Map或者Reduce任務;
5)Map或者Reduce任務在運行時,和ApplicationMaster通信,匯報自己的運行狀態。
如果運行結束,ApplicationMaster向ResourceManager進程注銷并釋放所有的容器資源。到這里,MapReduce程序已執行完成!1.4 YARN的三大調度器
1,先進先出調度器
FIFO Scheduler表示先進先出調度器。
先進先出調度器指的是:把應用按提交的順序排成一個隊列,在進行資源分配時,先給隊列中【隊頭】的應用進行分配資源,待【隊頭】的應用需求滿足后,再給下一個
應用分配,以此類推。
(1)優點
能夠保證每一個任務都能拿到充足的資源, 對于大任務的運行非常有好處。
(2)缺點
如果先有大任務后有小任務, 會導致后續小任務無資源可用, 長期處于等待狀態。
一般地,在普通數據量提交計算時,幾乎不會涉及調度器的設定,但海量數據處理時,要多考慮下調度器的設定。
2,公平調度器
Fair Scheduler表示公平調度器。
Fair Scheduler不需要保留集群的資源,因為它會動態在所有正在運行的作業之間平衡資源。
Fair Scheduler 當一個大job提交時,只有這一個job在運行,此時它獲得了所有集群資源;當后面有小任務提交后,公平調度器會分配一半資源給這個小任務,讓這兩個
任務公平的共享集群資源。通常情況下,各分享50%資源!
公平調度器執行效果:
(1)優點
能夠保證每個任務都有資源可用, 不會有大量的任務等待在資源分配中。
(2)缺點
如果大任務非常的多, 就會導致每個任務獲取資源都非常的有限, 也會導致執行時間會拉長。
相比較而言,公平調度器相對來說,分配資源時較為公平公正。
3,容量調度器
Capacity Scheduler表示容量調度器。
Capacity Scheduler為每個組織分配專門的隊列和一定的集群資源,這樣整個集群就可以通過設置多個隊列的方式給多個組織提供服務了。
在每個隊列內部,資源的調度是采用的是先進先出(FIFO)策略。
(1)優點
可以保證多個任務都可以使用一定的資源, 提升資源的利用率。
(2)缺點
如果遇到非常大的任務, 此任務不管運行在哪個隊列中, 都無法使用到集群中所有的資源, 導致大任務執行效率比較低, 當任務比較繁忙時, 依然會出現等待狀態。
(1)調度器的使用,是通過/export/server/hadoop-3.3.0/etc/hadoop/yarnsite.xml配置文件中的。
yarn.resourcemanager.scheduler.class參數進行配置的,默認采用
Capacity Scheduler調度器。
(1)在這個配置中,在root隊列下面定義了兩個子隊列prod和dev,分別占40%和60%的容量;
(2)prod由于沒有設置maximum-capacity屬性,它有可能會占用集群全部資源;
(3)dev的maximum-capacity屬性被設置成了75%,所以即使prod隊列完全空閑
dev也不會占用全部集群資源,也就是說,prod隊列仍有25%的可用資源用來應急。
2, ZooKeeper概述
2.1ZooKeeper簡介
Zookeeper(動物管理員)是一個分布式協調服務的開源框架,簡要地說,就是管理大數據生態圈的各類"動物"。
ZooKeeper本質上是一個分布式的小文件存儲系統。
采用樹形層次結構,ZooKeeper樹中的每個節點被稱為Znode,且樹中的每個節點可以擁有子節點。
Zookeeper具有如下特性:
1)全局數據一致:集群中每個服務器保存一份相同的數據副本,Client客戶端無論連接哪個服務器,展示的數據都是一致的;[最重要]
2)可靠性:如果消息被其中一臺服務器接收,那么將被所有的服務器接受;
3)順序性:包括全局有序和偏序兩種。
全局有序是指如果在一臺服務器上消息a在消息b前發布,則在所有Server上消息a都將在消息b前被發布;
偏序是指如果一個消息b在消息a后被同一個發送者發布,a必將排在b前面。
4)數據更新原子性:一次數據更新要么成功(半數以上節點成功),要么失敗,不存在中間狀態;
5)實時性:Zookeeper保證客戶端將在一個時間間隔范圍內獲得服務器的更新信息,或者服務器失效的信息。
2.2集群角色
Zookeeper表示分布式協調服務。
使用Zookeeper時至少需要兩個Hadoop服務,一主一備,主服務對外提供業務功能,備用等待主服務不可用時,啟用備用服務器對外提供業務功能。
在Zookeeper中,可供服務的角色有三類,分別是:
(1)leader:管理者,負責管理follower,處理所有的事務請求(數據的保存,修改,刪除);
(2)follower:追隨者,負責選舉(選舉leader)和數據的同步及獲取;
(3)observer:觀察者,負責數據的同步及獲取(需要在配置文件中指定才能生效)。
(1)leader管理者
leader管理者是Zookeeper集群工作的核心。負責管理follower,處理所有的事務請求(包括數據的保存,修改,刪除)。
(2)follower追隨者
follower追隨者負責處理客戶端非事務(讀操作)請求,并轉發事務請求給leader管理者。
同時,follower還會參與集群Leader選舉投票。
(3)observer觀察者
而針對訪問量比較大的Zookeeper集群,還可新增observer觀察者角色
負責數據的同步及獲取(需要在配置文件中指定才能生效)。
Zookeeper的集群常見角色有三個,分別是:leader、follower、observer。
2.3 ZooKeeper服務
1,配置環境變量
(1)未配置環境變量 按Shell腳本方式完成執行。此時,需要依次執行命令:
leader管理者是Zookeeper集群工作的核心。負責管理follower,處理所有的事務
請求(包括數據的保存,修改,刪除)。
follower追隨者負責處理客戶端非事務(讀操作)請求,并轉發事務請求給leader管理者。
同時,follower還會參與集群Leader選舉投票。
負責數據的同步及獲取(需要在配置文件中指定才能生效)。
(1)未配置環境變量
按Shell腳本方式完成執行
(2)先配置環境變量,再直接執行
cd /export/server/zookeeper/bin 1./zkServer.sh status 1
(2)先配置環境變量,再直接執行
此時,需要來配置zookeeper環境變量,注意:三臺虛擬機都要進行配置。
echo 'export ZOOKEEPER_HOME=/export/server/zookeeper' >>
/etc/profile
echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile
source /etc/profile
此時,可以在虛擬機的任意位置執行命令:
zkServer.sh status
我們會發現,配置環境變量的好處是能讓命令在不同路徑下,都能成功執行。
2.4啟動ZooKeeper
對于ZooKeeper的服務,需要在虛擬機中啟動后才能使用。啟動ZooKeeper命令:
zkServer.sh start
對于ZooKeeper的服務,還可以查看狀態與關閉服務,命令:
# 查看狀態
zkServer.sh status
# 如果想關閉可以使用stop
zkServer.sh stop
一般地,當僅在一臺服務器上啟動了ZooKeeper服務,可能無法查看到它所對應的服務角色。
此時,可以多開啟一臺虛擬機的ZooKeeper服務,再查看角色信息。
當要啟動Zookeeper服務時,可以執行zkServer.sh start;命令
在查看服務時,記住三個關鍵字:start啟動、status狀態、stop停止。
3,使用ZooKeeper
3.1,客戶端連接
當已經成功開啟了Zookeeper服務后,則可以使用客戶端來連接服務并執行相應操作了。
連接Zookeeper服務時,有兩種方式:
# 方式1:連接其他節點
[root@node1 ~]# zkCli.sh -server IP地址
# 方式2:直接連接本地
[root@node1 ~]# zkCli.sh
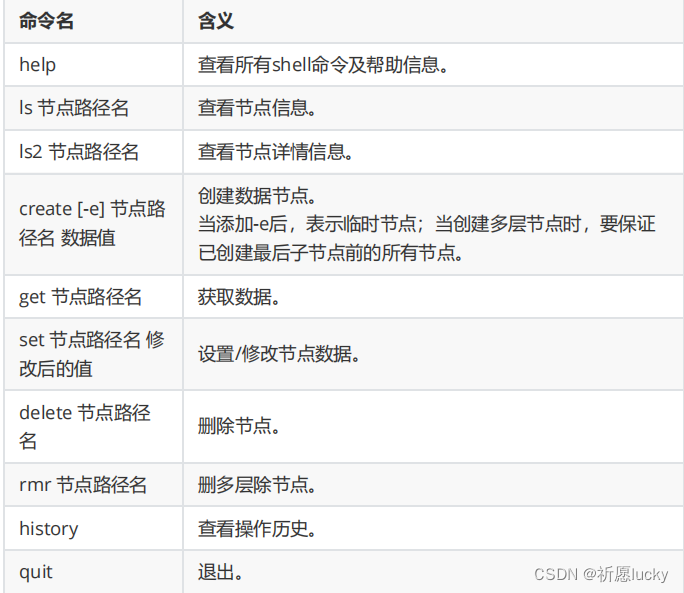
采用zkCli.sh直接連接本地的zkServer,并完成常見命令的使用。
(1)當要遠程連接不同服務器的Zookeeper服務時,使用zkCli.sh -server IP地址命令;
(2)注意,當想要快速查看zookeeper客戶端的操作命令,可以直接執行help命令。
3.2數據模型
ZooKeeper的數據模型稱為Znode,一般有兩種體現:
(1)目錄:可以存儲數據,也可以當做目錄使用
(2)文件:可以存儲數據,也可以當做目錄使用
ZooKeeper的數據模型也有一些不同之處:
(1)Znode兼具文件和目錄兩種特點:Znode沒有文件和目錄之分,Znode既能像文件一樣存儲數據,也能像目錄作為路徑標識的一部分;
(2)Znode具有原子性操作: 讀操作將獲取與節點相關的所有數據,寫操作也將替換掉節點的所有數據;
(3)Znode存儲數據大小有限制: 每個Znode的數據大小至多1M,但是在常規使用中,應該遠小于此值;
(4)Znode通過路徑引用: 路徑必須是絕對的,因此他們必須由斜杠字符來開頭。除此以外,他們必須是唯一的,也就是說每一個路徑只有一個表示,因此這些路徑不能改變。
并且,會發現:默認有/zookeeper節點用以保存關鍵的管理信息。
在zookeeper中的節點是目錄或文件都能存儲數據,這個描
述正確
(2)通常地,zookeeper數據模型分為目錄、文件,但本質上區別不大。
3.3節點類型
create [-e] 節點路徑名 數據值
創建數據節點。
當添加-e后,表示臨時節點;當創建多層節點時,要保證
已創建最后子節點前的所有節點。
Znode節點類型有兩類,分別為:
(1)永久節點
該節點的生命周期不依賴于會話,并且只有在客戶端顯示執行刪除操作時,他們才能被刪除;
注意: 永久節點可以擁有子節點。
(2)臨時節點
該節點的生命周期依賴于創建它們的會話。一旦會話結束,臨時節點將被自動刪除,也可手動刪除;
注意: 臨時節點不允許擁有子節點。
當然了,可以通過創建節點是否添加-e選項或ls2能查看到節點類型:
# 添加了-e表示臨時節點,否則為永久節點
create [-e] 節點路徑名 數據值
# 查看ephemeralOwner字段為0x0時,為永久節點; 結果值較長的為臨時節點
ls2 節點路徑名
cZxid:Znode創建的事務id。
ctime:Znode創建時的時間戳。
mZxid:Znode被修改的事務id,即每次對當前znode的修改都會更新mZxid。
mtime:Znode最新一次更新發生時的時間戳。
pZxid:Znode的子節點列表變更的事務ID,添加子節點或刪除子節點就會影響子節點列表。
cversion:子節點進行變更的版本號。添加子節點或刪除子節點就會影響子節點版本號。
dataVersion:數據版本號,每次對節點進行set操作,dataVersion的值都會增
加1(即使設置的是相同的數據),可有效避免了數據更新時出現的先后順序問題。
aclVersion:權限變化列表版本 access control list Version。
ephemeralOwner:字面翻譯臨時節點擁有者,持久節點值為0x0,非持久節點不為0(會話ID)。
dataLength:Znode數據長度。
numChildren:當前Znode子節點數量(不包括子子節點)。
當在使用create關鍵字創建節點時,添加-e表示創建臨時節點
(2)當在查看節點詳細信息時,可以通ephemeralOwner字段值來區分臨時或永久節點
3.4Watch監聽機制
通常地,一個典型的發布/訂閱模型系統定義了一種一對多的訂閱關系,能讓多個訂閱者同時監聽某一個主題對象,當這個主題對象自身狀態發生變化時,會通知所有訂
閱者,使他們能夠做出相應的處理。
ZooKeeper允許客戶端向服務端注冊一個Watcher監聽,當服務端的一些事件觸發了這個Watcher,那么就會向指定客戶端發送一個事件通知來實現分布式的通知功能。
watch監聽機制過程有:
(1)客戶端向服務端注冊Watcher;
(2)服務端事件發生觸發Watcher;
(3)客戶端回調Watcher得到觸發事件情況
僅需到某客戶端中設定監聽機制格式為
get /節點名 watch
Watch監聽機制有如下特點:
a)先注冊再觸發: Zookeeper中的watch機制,必須客戶端先去服務端注冊監聽,這樣事件發送才會觸發監聽,并通知給客戶端;
b)一次性觸發: 事件發生觸發監聽后,一個watcher event就會被發送到設置監聽的客戶端,這種效果是一次性的,后續再次發生同樣的事件,不會再次觸發;
c)異步發送: watcher的通知事件從服務端發送到客戶端是異步的;(同時進行)
d)通知內容: 通知狀態(keeperState),事件類型(EventType)和節點路徑(path)。
3.5選舉機制
(1)數據發布/訂閱
數據發布/訂閱系統,就是發布者將數據發布到ZooKeeper的一個節點上,提供訂閱者進行數據訂閱,從而實現動態更新數據的目的,實現配置信息的集中式管理和數據的動態更新。監聽機制就是[數據發布/訂閱]快速實現。
(2)提供集群選舉
在分布式環境下,不管是主從架構集群,還是主備架構集群,要求在服務時,有且僅有一個正常的對外提供服務的主服務器,我們稱之為Master。
當master出現故障之后,需要重新選舉出新的Master,用以保證服務的連續可用性。
而Zookeeper則可以提供這樣的功能服務,但一般會涉及到:znode唯一性、臨時節點短暫性、監聽機制等知識使用。
通常情況下,選舉機制要求:過半原則。
所以,我們會發現搭建集群一般都是奇數,即只要某個node節點票數過半立刻成為leader。
當然了,選舉機制下,也有兩個特殊情況:
(1)集群第一次啟動
啟動follower每次投票后,他們會相互同步投票情況,如果票數相同,誰的myid大,誰就當選leader。
一旦確定了leader,后面來的默認就是follower,即使它的myid大,leader也不會改變(除非leader宕機了)。
# 進入數據目錄
cd /export/server/zookeeper/zkdatas
# 查看myid值大小
cat myid
(2)leader宕機后,再次啟動
每一個leader當老大時,都會產生新紀元epoch,且每次操作完節點數據都會更新事務id(高32位_低32位) ,而當leader宕機后,剩下的follower就會綜合考慮幾個因素
選出最新的leader。先比較最后一次更新數據事務id(高32位_低32位),誰的事務id最大,誰就當選leader。
如果更新數據的事務id都相同的情況下,就需要再次考慮myid,誰的myid大,誰就當選leader。
(1)通常情況下,不管選舉時屬于哪種情況,都有考慮myid值的大小

dami CMS)


















