目錄
- 窗口
- 窗口的概念
- 窗口的分類
- 滾動窗口(Tumbling Windows)
- 滑動窗口(Sliding Windows)
- 會話窗口(Session Windows)
- 全局窗口(Global Windows)
- 窗口API概覽
- 窗口函數
- 增量聚合函數
- ReduceFunction
- AggregateFunction
- 全窗口函數
- 窗口函數(WindowFunction)
- 處理窗口函數(ProcessWindowFunction)
- 增量聚合和全窗口函數的結合使用
- 其他API
- 觸發器(Trigger)
- 移除器(Evictor)
- 窗口_原理簡析_劃分&觸發時機&生命周期
在批處理統計中,我們可以等待一批數據都到齊后,統一處理。但是在實時處理統計中,我們是來一條就得處理一條,那么我們怎么統計最近一段時間內的數據呢?引入“窗口”。
所謂的“窗口”,一般就是劃定的一段時間范圍,也就是“時間窗”;對在這范圍內的數據進行處理,就是所謂的窗口計算。所以窗口和時間往往是分不開的。接下來我們就深入了解一下Flink中的時間語義和窗口的應用。
窗口
窗口的概念
Flink是一種流式計算引擎,主要是來處理無界數據流的,數據源源不斷、無窮無盡。想要更加方便高效地處理無界流,一種方式就是將無限數據切割成有限的“數據塊”進行處理,這就是所謂的“窗口(Window)。
注意:Flink中窗口并不是靜態準備好的,而是動態創建——當有落在這個窗口區間范圍的數據達到時,才創建對應的窗口。另外,這里我們認為到達窗口結束時間時,窗口就觸發計算并關閉。
窗口的分類
窗口本身是截取有界數據的一種方式,所以窗口一個非常重要的信息其實就是 “怎樣截取數據”。換句話說,就是以什么標準來開始和結束數據的截取,我們把它叫作窗口的 “驅動類型”。
(1)時間窗口(Time Window)
時間窗口以時間點來定義窗口的開始(start)和結束(end),所以截取出的就是某一時間段的數據。到達結束時間時,窗口不再收集數據,觸發計算輸出結果,并將窗口關閉銷毀。所以可以說基本思路就是 “定點發車”。
(2)計數窗口(Count Window)
計數窗口基于元素的個數來截取數據,到達固定的個數時就觸發計算并關閉窗口。每個窗口截取數據的個數,就是窗口的大小。基本思路是 “人齊發車”。
按照窗口分配數據的規則分類
根據分配數據的規則,窗口的具體實現可以分為4類:滾動窗口(Tumbling Window)、滑動窗口(Sliding Window)、會話窗口(Session Window),以及全局窗口(Global Window)。
滾動窗口(Tumbling Windows)
滾動窗口有固定的大小,是一種對數據進行“均勻切片”的劃分方式。窗口之間沒有重疊,也不會有間隔,是“首尾相接”的狀態。這是最簡單的窗口形式,每個數據都會被分配到一個窗口,而且只會屬于一個窗口。
滾動窗口可以基于時間定義,也可以基于數據個數定義;需要的參數只有一個,就是窗口的大小(window size)。
比如我們可以定義一個長度為1小時的滾動時間窗口,那么每個小時就會進行一次統計;或者定義一個長度為10的滾動計數窗口,就會每10個數進行一次統計。
滾動窗口應用非常廣泛,它可以對每個時間段做聚合統計,很多BI分析指標都可以用它來實現
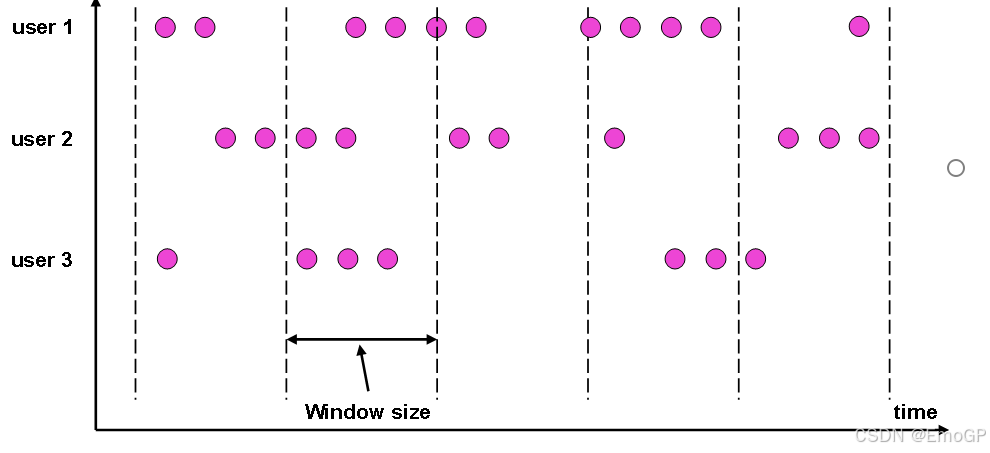
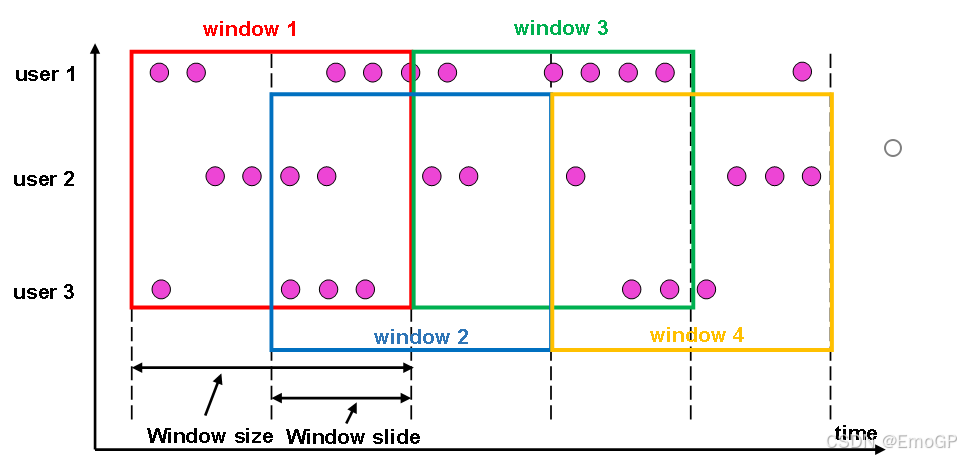
滑動窗口(Sliding Windows)
滑動窗口的大小也是固定的。但是窗口之間并不是首尾相接的,而是可以“錯開”一定的位置。
定義滑動窗口的參數有兩個:除去窗口大小(window size)之外,還有一個“滑動步長”(window slide),它其實就代表了窗口計算的頻率。窗口在結束時間觸發計算輸出結果,那么滑動步長就代表了計算頻率。
當滑動步長小于窗口大小時,滑動窗口就會出現重疊,這時數據也可能會被同時分配到多個窗口中。而具體的個數,就由窗口大小和滑動步長的比值(size/slide)來決定。
滾動窗口也可以看作是一種特殊的滑動窗口——窗口大小等于滑動步長(size = slide)。
滑動窗口適合計算結果更新頻率非常高的場景
會話窗口(Session Windows)
會話窗口,是基于“會話”(session)來對數據進行分組的。會話窗口只能基于時間來定義。
會話窗口中,最重要的參數就是會話的超時時間,也就是兩個會話窗口之間的最小距離。如果相鄰兩個數據到來的時間間隔(Gap)小于指定的大小(size),那說明還在保持會話,它們就屬于同一個窗口;如果gap大于size,那么新來的數據就應該屬于新的會話窗口,而前一個窗口就應該關閉了。
會話窗口的長度不固定,起始和結束時間也是不確定的,各個分區之間窗口沒有任何關聯。會話窗口之間一定是不會重疊的,而且會留有至少為size的間隔(session gap)。
在一些類似保持會話的場景下,可以使用會話窗口來進行數據的處理統計。
全局窗口(Global Windows)
“全局窗口”,這種窗口全局有效,會把相同key的所有數據都分配到同一個窗口中。這種窗口沒有結束的時候,默認是不會做觸發計算的。如果希望它能對數據進行計算處理,還需要自定義“觸發器”(Trigger)。
全局窗口沒有結束的時間點,所以一般在希望做更加靈活的窗口處理時自定義使用。Flink中的計數窗口(Count Window),底層就是用全局窗口實現的。
窗口API概覽
窗口函數
定義了窗口分配器,我們只是知道了數據屬于哪個窗口,可以將數據收集起來了;至于收集起來到底要做什么,其實還完全沒有頭緒。所以在窗口分配器之后,必須再接上一個定義窗口如何進行計算的操作,這就是所謂的“窗口函數”(window functions)。
窗口函數定義了要對窗口中收集的數據做的計算操作,根據處理的方式可以分為兩類:增量聚合函數和全窗口函數
增量聚合函數
增量聚合:來一條數據,計算一條數據,窗口觸發的時候輸出計算結果
ReduceFunction
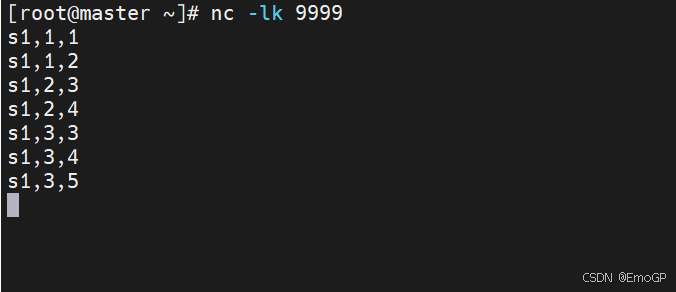
package window;
import env.WaterSensor;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import split.WaterSensorMap;
public class WindowReduceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> source = env.socketTextStream("master", 9999).map(new WaterSensorMap());KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = source.keyBy(sensor -> sensor.getId());WindowedStream<WaterSensor, String, TimeWindow> sensorWS = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(20)));SingleOutputStreamOperator<WaterSensor> reduce = sensorWS.reduce(new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {System.out.println("調用reduce方法,value1=" + value1 + ",value2=" + value2);return new WaterSensor(value1.getId(), value2.ts, value1.vc + value2.vc);}});reduce.print();env.execute();}
}
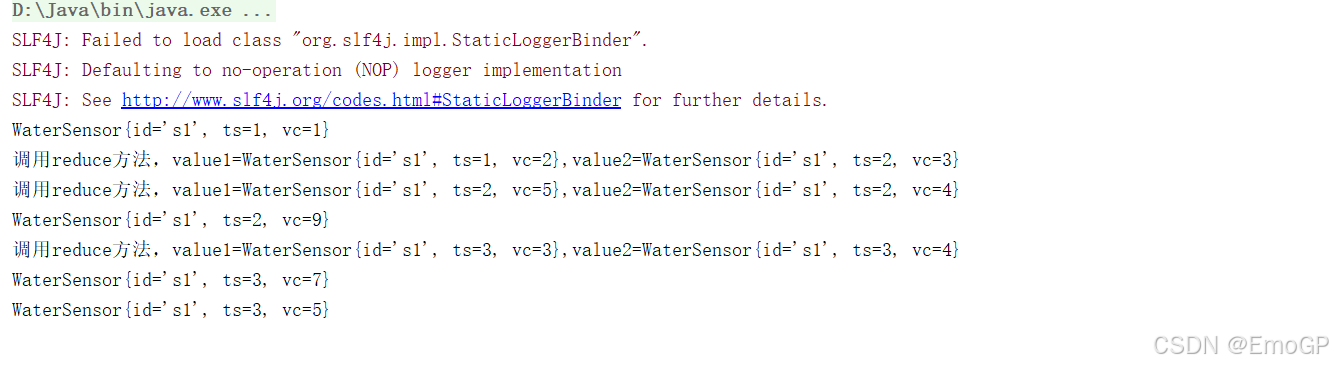
窗口的reduce:
相同key的第一條數據來的時候,不會調用reduce方法
增量聚合:來一條數據,就會計算一次,但是不會輸出
在窗口觸發的時候,才會輸出窗口的最終計算結果
AggregateFunction
ReduceFunction可以解決大多數歸約聚合的問題,但是這個接口有一個限制,就是聚合狀態的類型、輸出結果的類型都必須和輸入數據類型一樣。
Flink Window API中的aggregate就突破了這個限制,可以定義更加靈活的窗口聚合操作。這個方法需要傳入一個AggregateFunction的實現類作為參數。
AggregateFunction可以看作是ReduceFunction的通用版本,這里有三種類型:輸入類型(IN)、累加器類型(ACC)和輸出類型(OUT)。輸入類型IN就是輸入流中元素的數據類型;累加器類型ACC則是我們進行聚合的中間狀態類型;而輸出類型當然就是最終計算結果的類型了。
接口中有四個方法:
- createAccumulator():創建一個累加器,這就是為聚合創建了一個初始狀態,每個聚合任務只會調用一次。
- add():將輸入的元素添加到累加器中。
- getResult():從累加器中提取聚合的輸出結果。
- merge():合并兩個累加器,并將合并后的狀態作為一個累加器返回。
所以可以看到,AggregateFunction的工作原理是:首先調用createAccumulator()為任務初始化一個狀態(累加器);而后每來一個數據就調用一次add()方法,對數據進行聚合,得到的結果保存在狀態中;等到了窗口需要輸出時,再調用getResult()方法得到計算結果。很明顯,與ReduceFunction相同,AggregateFunction也是增量式的聚合;而由于輸入、中間狀態、輸出的類型可以不同,使得應用更加靈活方便。
package window;import env.WaterSensor;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import split.WaterSensorMap;public class WindowAggregateDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> source = env.socketTextStream("master", 9999).map(new WaterSensorMap());KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = source.keyBy(sensor -> sensor.getId());WindowedStream<WaterSensor, String, TimeWindow> sensorWS = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));SingleOutputStreamOperator<String> aggregate = sensorWS.aggregate(new AggregateFunction<WaterSensor, Integer, String>() {@Overridepublic Integer createAccumulator() {System.out.println("初始化累加器");return 0;}@Overridepublic Integer add(WaterSensor value, Integer accumulator) {System.out.println("調用add方法,value=" +value);return accumulator + value.getVc();}@Overridepublic String getResult(Integer accumulator) {System.out.println("調用getResult方法");return accumulator.toString();}@Overridepublic Integer merge(Integer a, Integer b) {System.out.println("調用merge方法");return null;}});aggregate.print();env.execute();}
}

屬于本窗口的第一條數據來,創建窗口,創建累加器
增量聚合:來一條計算一條,調用add方法
窗口輸出時調用一次getResult方法
輸入,中間累加器,輸出,類型可以不一樣,非常靈活
全窗口函數
數據來了不計算,存起來,窗口觸發的時候,計算并輸出結果
process
有些場景下,我們要做的計算必須基于全部的數據才有效,這時做增量聚合就沒什么意義了;另外,輸出的結果有可能要包含上下文中的一些信息(比如窗口的起始時間),這是增量聚合函數做不到的。
所以,我們還需要有更豐富的窗口計算方式。窗口操作中的另一大類就是全窗口函數。與增量聚合函數不同,全窗口函數需要先收集窗口中的數據,并在內部緩存起來,等到窗口要輸出結果的時候再取出數據進行計算。
在Flink中,全窗口函數也有兩種:WindowFunction和ProcessWindowFunction。
窗口函數(WindowFunction)
WindowFunction字面上就是“窗口函數”,它其實是老版本的通用窗口函數接口。我們可以基于WindowedStream調用.apply()方法,傳入一個 WindowFunction 的實現類。
stream.keyBy(<key selector>).window(<window assigner>).apply(new MyWindowFunction());
這個類中可以獲取到包含窗口所有數據的可迭代集合(Iterable),還可以拿到窗口(Window)本身的信息。
不過WindowFunction能提供的上下文信息較少,也沒有更高級的功能。事實上,它的作用可以被ProcessWindowFunction全覆蓋,所以之后可能會逐漸棄用。
處理窗口函數(ProcessWindowFunction)
ProcessWindowFunction是Window API中最底層的通用窗口函數接口。之所以說它“最底層”,是因為除了可以拿到窗口中的所有數據之外,ProcessWindowFunction還可以獲取到一個“上下文對象”(Context)。這個上下文對象非常強大,不僅能夠獲取窗口信息,還可以訪問當前的時間和狀態信息。這里的時間就包括了處理時間(processing time)和事件時間水位線(event time watermark)。這就使得ProcessWindowFunction更加靈活、功能更加豐富,其實就是一個增強版的WindowFunction。
package window;import env.WaterSensor;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import split.WaterSensorMap;public class WindowProcessDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> source = env.socketTextStream("master", 9999).map(new WaterSensorMap());KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = source.keyBy(sensor -> sensor.getId());WindowedStream<WaterSensor, String, TimeWindow> sensorWS = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(20)));SingleOutputStreamOperator<String> process = sensorWS.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {/**** @param s* @param context* @param elements* @param out* @throws Exception*/@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {long start = context.window().getStart();long end = context.window().getEnd();String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + "]包含" + count + "條數據===>" + elements.toString());}});process.print();env.execute();}
}增量聚合和全窗口函數的結合使用
在實際應用中,我們往往希望兼具這兩者的優點,把它們結合在一起使用。Flink的Window API就給我們實現了這樣的用法。
我們之前在調用WindowedStream的.reduce()和.aggregate()方法時,只是簡單地直接傳入了一個ReduceFunction或AggregateFunction進行增量聚合。除此之外,其實還可以傳入第二個參數:一個全窗口函數,可以是WindowFunction或者ProcessWindowFunction。
package window;
import env.WaterSensor;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import split.WaterSensorMap;public class WindowAggregateAndProcessDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();SingleOutputStreamOperator<WaterSensor> source = env.socketTextStream("master", 9999).map(new WaterSensorMap());KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = source.keyBy(sensor -> sensor.getId());WindowedStream<WaterSensor, String, TimeWindow> sensorWS = waterSensorStringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));SingleOutputStreamOperator<String> result = sensorWS.aggregate(new MyAgg(), new MyProcess());result.print();env.execute();}public static class MyProcess extends ProcessWindowFunction<String,String,String,TimeWindow>{@Overridepublic void process(String s, Context context, Iterable<String> elements, Collector<String> out) throws Exception {long start = context.window().getStart();long end = context.window().getEnd();String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + "]包含" + count + "條數據===>" + elements.toString());}}public static class MyAgg implements AggregateFunction<WaterSensor, Integer, String> {@Overridepublic Integer createAccumulator() {return null;}@Overridepublic Integer add(WaterSensor value, Integer accumulator) {return null;}@Overridepublic String getResult(Integer accumulator) {return null;}@Overridepublic Integer merge(Integer a, Integer b) {return null;}}
}這樣調用的處理機制是:基于第一個參數(增量聚合函數)來處理窗口數據,每來一個數據就做一次聚合;等到窗口需要觸發計算時,則調用第二個參數(全窗口函數)的處理邏輯輸出結果。需要注意的是,這里的全窗口函數就不再緩存所有數據了,而是直接將增量聚合函數的結果拿來當作了Iterable類型的輸入。
結合兩者的優點:
- 增量聚合:來一條計算一條,存儲中間的計算結果,占用空間少
- 全窗口函數:可以通過上下文實現靈活的功能
其他API
對于一個窗口算子而言,窗口分配器和窗口函數是必不可少的。除此之外,Flink還提供了其他一些可選的API,讓我們可以更加靈活地控制窗口行為
觸發器(Trigger)
觸發器主要是用來控制窗口什么時候觸發計算。所謂的“觸發計算”,本質上就是執行窗口函數,所以可以認為是計算得到結果并輸出的過程。
基于WindowedStream調用.trigger()方法,就可以傳入一個自定義的窗口觸發器(Trigger)。
stream.keyBy(...).window(...).trigger(new MyTrigger())
移除器(Evictor)
移除器主要用來定義移除某些數據的邏輯。基于WindowedStream調用.evictor()方法,就可以傳入一個自定義的移除器(Evictor)。Evictor是一個接口,不同的窗口類型都有各自預實現的移除器。
窗口_原理簡析_劃分&觸發時機&生命周期
以時間類型的滾動窗口為例,分析原理
窗口什么時候觸發輸出?
時間進展 >= 窗口的最大時間戳(end - 1ms)
窗口是怎么劃分的?
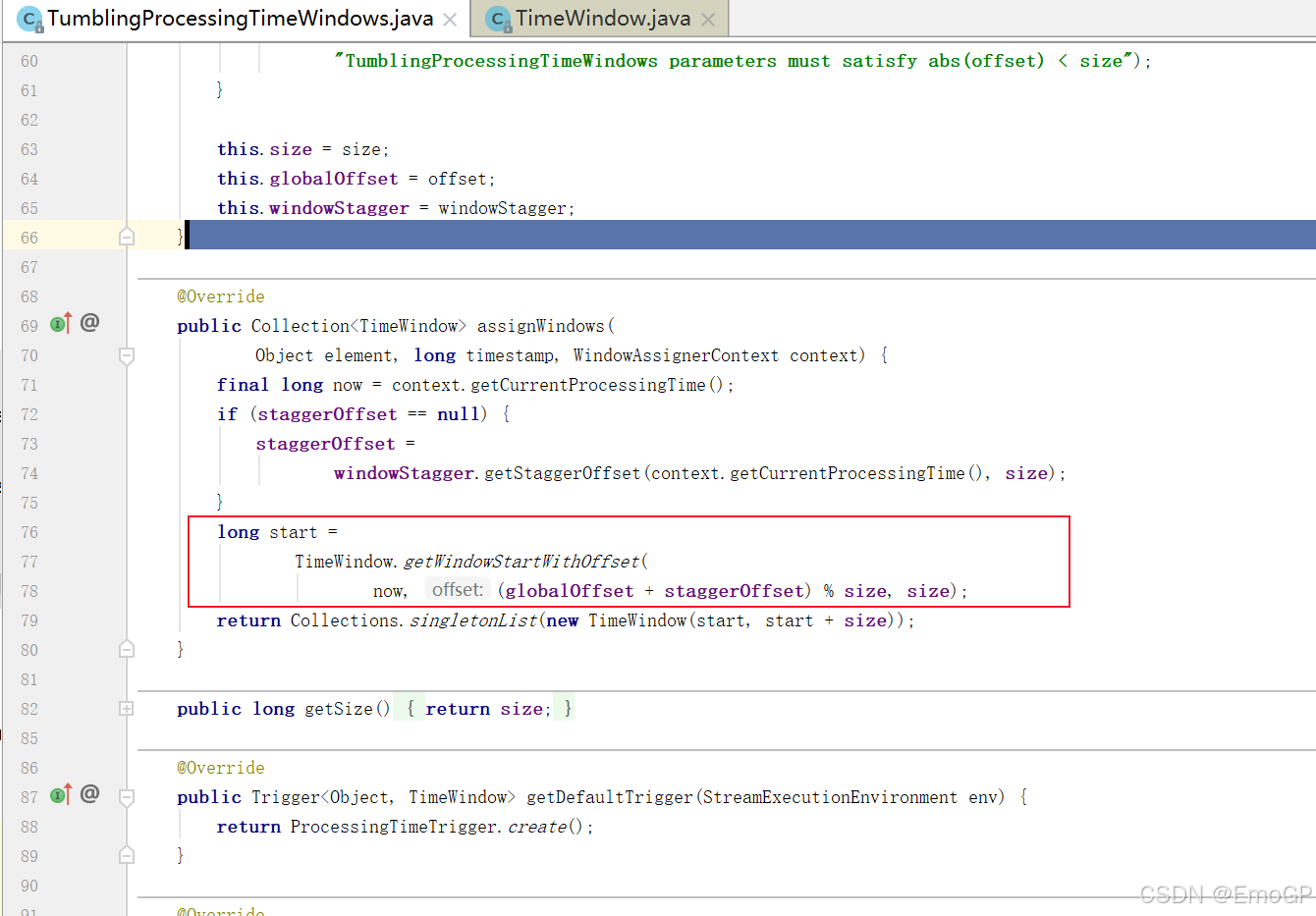
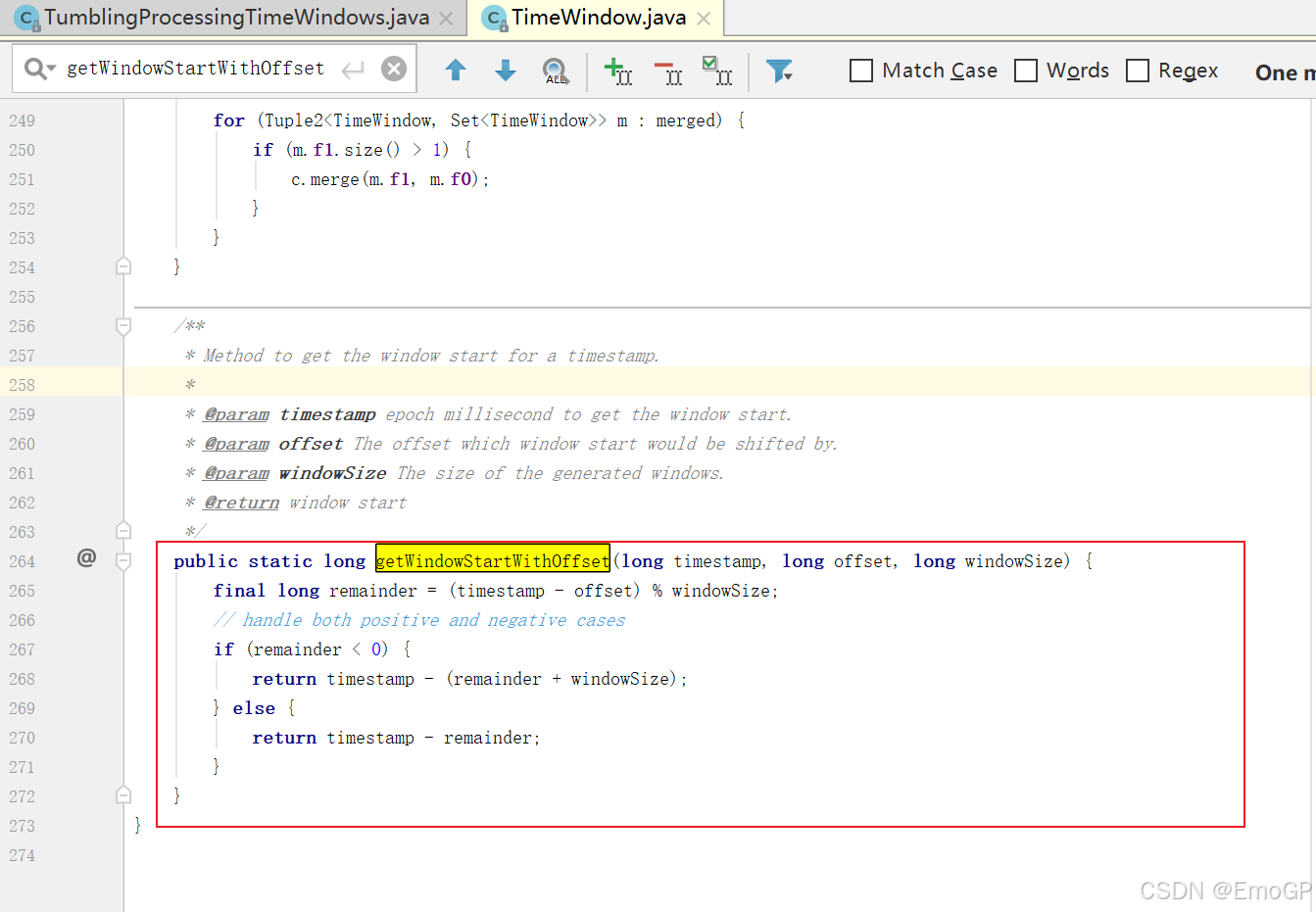
offset默認為0
timestamp = 13
windowsize = 10
remainder = 3
start = 10timestamp = 27
windowsize = 10
remainder = 7
start = 20timestamp = 35
windowsize = 10
remainder = 5
start = 30
start = 向下取整、取窗口長度的整數倍
end = start + 窗口長度
窗口左閉右開 => 屬于本窗口的最大時間戳 = end - 1ms
窗口的生命周期
創建:屬于本窗口的第一條數據來的時候,現new的,放入一個singleton單例的集合中
銷毀(關窗):時間進展 >= 窗口的最大時間戳(end - 1ms)+ 允許遲到的時間(默認為0)
:API安全風險導致敏感數據泄漏)

: com.XXX.XXx.service.xxx無法執行service)
what why when【前端TS】)

)
)
)


)
-Spark 是什么?)

網絡層)



)

