
????????集成學習(Ensemble Learning)的核心思想是“集思廣益”,它通過構建并結合多個基學習器(Base Learner)來完成學習任務,從而獲得比單一學習器更顯著優越的泛化性能。俗話說,“三個臭皮匠,頂個諸葛亮”。
根據基學習器的生成方式,集成學習主要可以分為三大流派:Bagging、Boosting 和 Stacking。
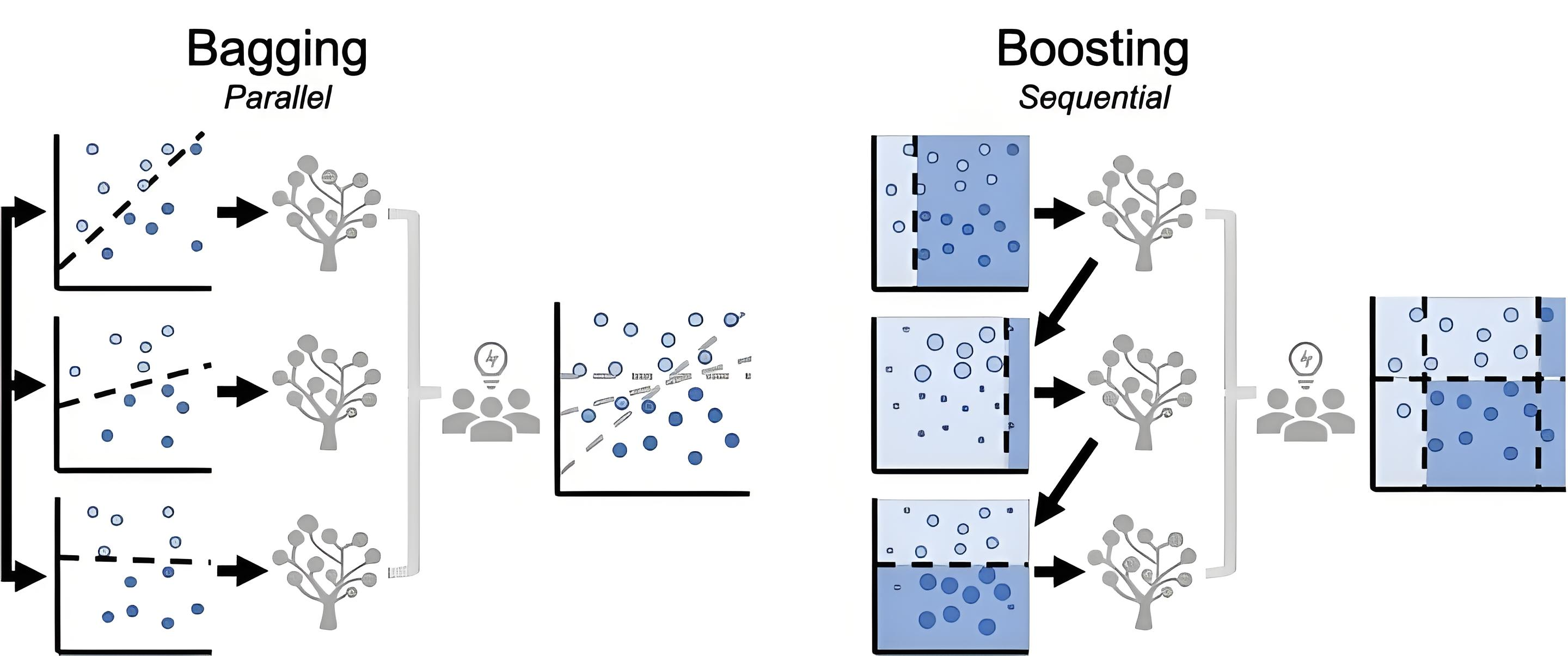
1. Bagging - 并行之道
核心思想:?Bootstrap?Aggregating?的縮寫。
Bootstrap: 通過有放回的隨機抽樣(自助采樣法)從訓練集中生成多個不同的子訓練集。
Aggregating: 每個子訓練集獨立地訓練一個基學習器(通常是決策樹這樣的不穩定學習器),最后通過投票(分類)或平均(回歸)的方式聚合所有基學習器的預測結果。
核心假設: 通過降低模型的方差(Variance)來提高整體泛化能力。通過平均多個模型,可以平滑掉單個模型因訓練數據噪聲而帶來的過擬合風險。
最著名的算法:隨機森林(Random Forest)
隨機森林是Bagging的一個擴展變體,它在Bagging的“數據隨機性”基礎上,增加了“特征隨機性”。
工作流程:
從原始數據集中使用Bootstrap采樣抽取N個樣本子集。
對于每棵決策樹的每個節點進行分裂時,不是從所有特征中而是從一個隨機選擇的特征子集(例如√p個特征,p是總特征數)?中選擇最優分裂特征。
優點:
強大的抗過擬合能力: 雙重隨機性(數據+特征)的引入,使得每棵樹都變得不同,降低了模型復雜度。
訓練高效,可并行化: 因為每棵樹的訓練是獨立的,可以輕松進行分布式訓練。
能處理高維數據: 特征隨機子集的選擇使其能處理特征數量很大的數據集。
內置特征重要性評估: 通過觀察每個特征被用于分裂時帶來的不純度下降的平均值,可以評估特征的重要性。
適用場景: 當您的基模型容易過擬合(高方差)時,Bagging非常有效。隨機森林是許多任務的“首選基準模型”,因為它開箱即用,效果通常很好。
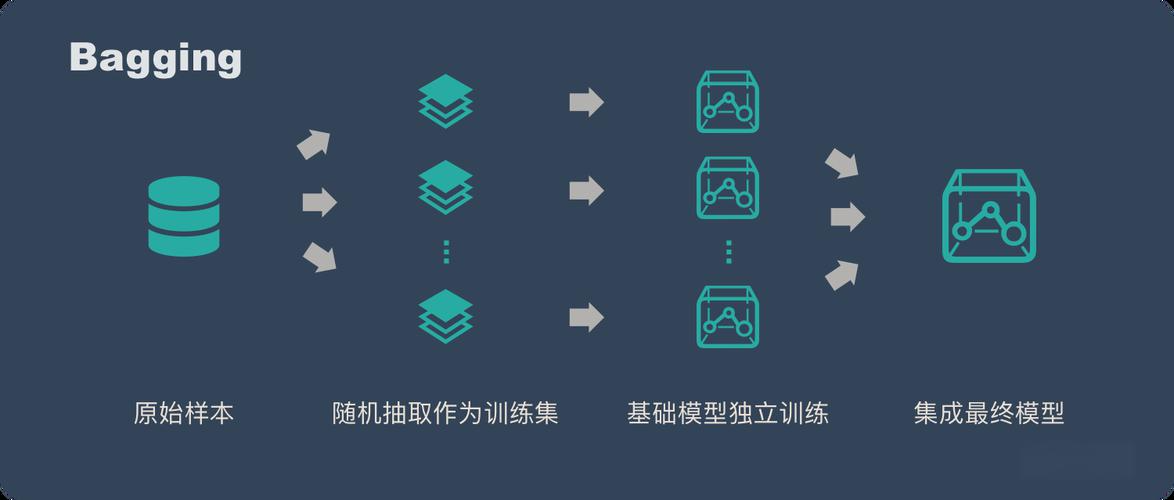
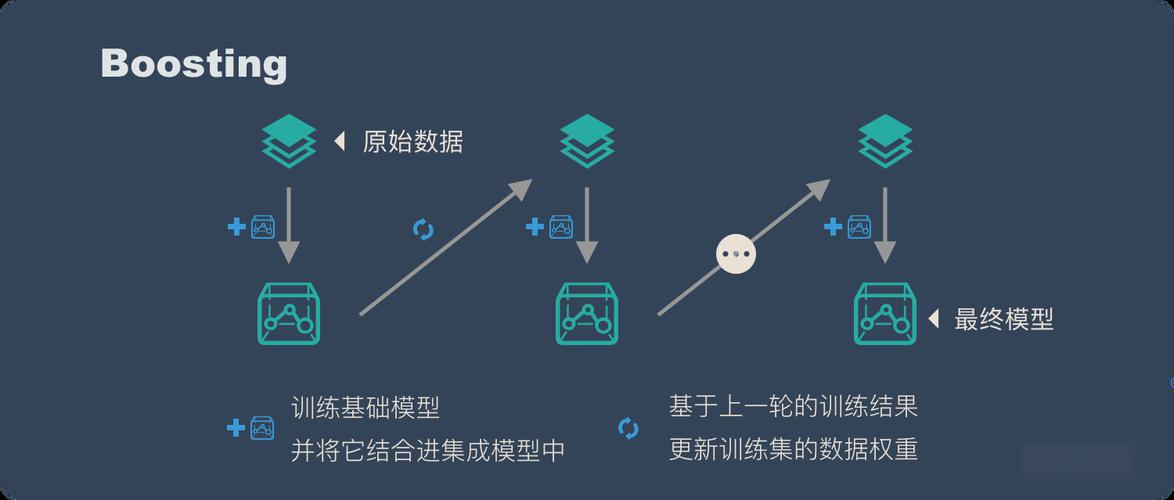
2. Boosting - 串行之道
核心思想: 與Bagging的并行獨立訓練不同,Boosting的基學習器是順序生成的。
每一個后續的模型都會更加關注前一個模型預測錯誤的樣本。
通過不斷地迭代和修正錯誤,提升整體模型的性能。它是一個“知錯就改”的過程。
核心假設: 通過持續降低模型的偏差(Bias)來提升性能,將多個弱學習器(如淺層決策樹)組合成一個強學習器。
著名算法:
AdaBoost (Adaptive Boosting)
工作流程:
第一棵樹正常訓練。
訓練完成后,增加那些被錯誤預測樣本的權重,降低正確預測樣本的權重。
用更新權重后的數據訓練下一棵樹。
重復此過程,最后將所有樹的預測結果進行加權投票(準確率越高的樹,權重越大)。
直觀理解: 讓后面的學習器“重點關照”之前犯過的錯誤。
梯度提升決策樹 (Gradient Boosting Decision Tree, GBDT)
工作流程: 這是Boosting思想的一種更通用的實現。它不是通過調整樣本權重,而是通過擬合損失函數的負梯度(即殘差的近似)?來迭代訓練。
第一棵樹直接預測目標值。
計算當前所有樣本的預測值與真實值之間的殘差(對于平方損失函數來說,負梯度就是殘差)。
訓練下一棵樹來擬合這個殘差。
將新樹的預測結果加到之前的預測上,逐步減小殘差。
直觀理解: 每一步都在彌補當前模型與真實值之間的差距。
XGBoost, LightGBM, CatBoost
這些都是GBDT的高效、現代化實現,在算法和工程上做了大量優化(正如我們之前討論的XGBoost)。
它們是目前在Kaggle等數據科學競賽和工業界中最主流、最強大的集成算法。
適用場景: 當您的基模型表現較弱(高偏差)時,Boosting能顯著提升模型精度。它在結構化/表格數據上幾乎是無敵的存在。
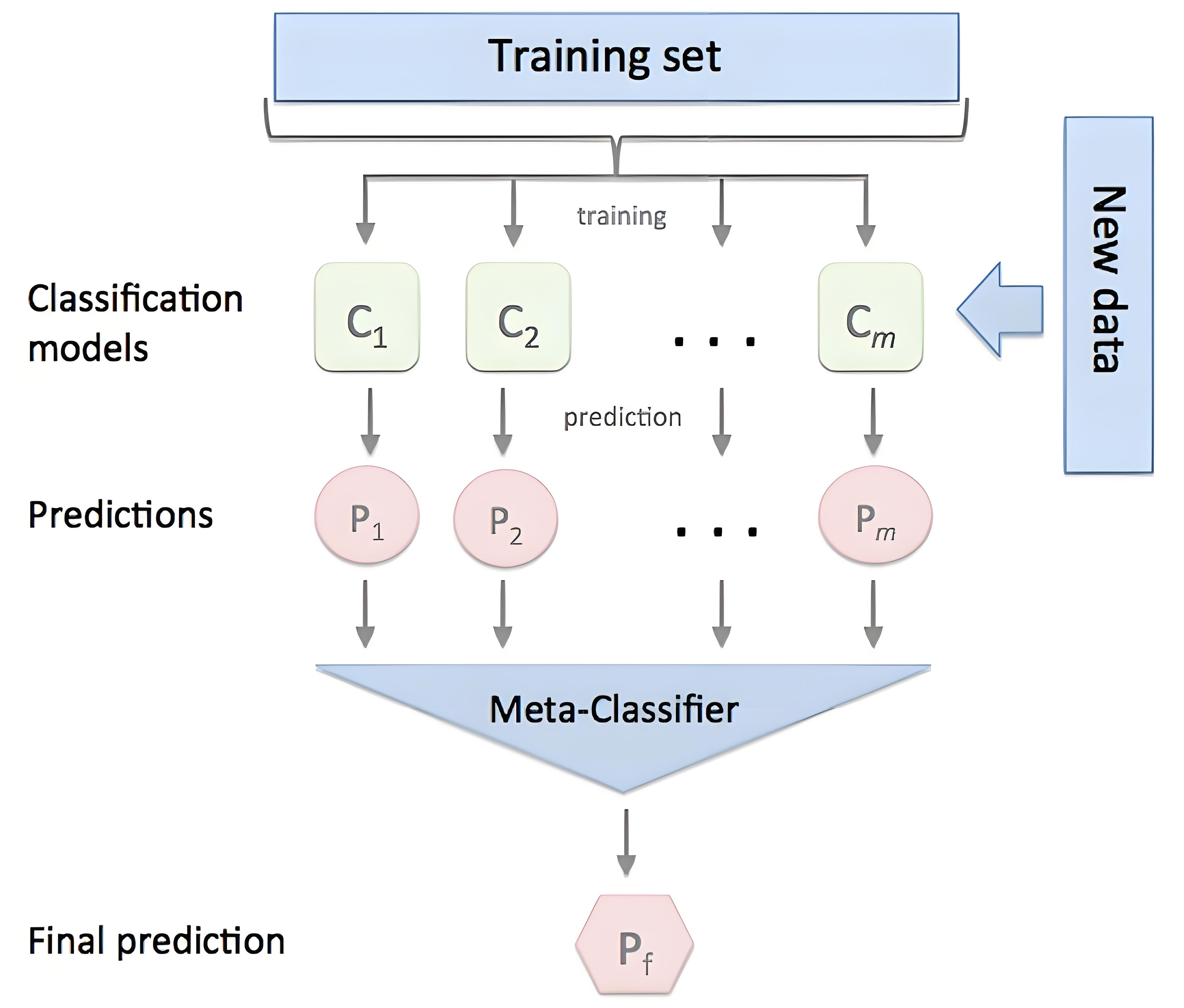
3. Stacking - 模型聚合之道
核心思想: 訓練一個元學習器(Meta-Learner),來學習如何最佳地組合多個基學習器(Base-Learner)?的預測結果。
第一層: 用原始訓練數據訓練多個不同的基模型(例如,一個隨機森林、一個XGBoost、一個SVM)。
第二層: 將第一層所有模型的預測輸出作為新的特征,并以其真實標簽為目標,訓練一個新的元模型(通常是線性回歸、邏輯回歸等簡單模型)。
關鍵要點: 為了防止信息泄露和過擬合,通常使用交叉驗證的方式生成第一層模型的預測。例如,使用5折交叉驗證,每次用4折訓練基模型,預測剩下的1折,這樣就能得到整個訓練集完整且無偏的OOF(Out-of-Fold)預測,用于訓練元模型。
適用場景: 當您想榨干最后一滴性能,不介意復雜的訓練流程時。常用于頂級機器學習競賽中,但在工業界中由于復雜度高,部署維護成本也高,應用相對較少。
總結與對比
| 方法 | 核心思想 | 訓練方式 | 核心目標 | 代表算法 |
|---|---|---|---|---|
| Bagging | 自主采樣,平等聚合 | 并行 | 降低方差 | 隨機森林 |
| Boosting | 關注錯誤,迭代修正 | 串行 | 降低偏差 | AdaBoost, GBDT,?XGBoost |
| Stacking | 模型預測作為新特征,元模型學習組合 | 分層訓練 | 提升預測精度 | 各種模型的組合 |
如何選擇?
追求簡單、高效、穩定: 從隨機森林開始。
追求極致的預測精度: 首選梯度提升框架(XGBoost, LightGBM)。
參加競賽或研究: 可以嘗試復雜的Stacking或Blending。
總而言之,集成學習通過巧妙地組合多個模型,有效地突破了單一模型的性能瓶頸,是現代機器學習中不可或缺的強大工具。
: com.XXX.XXx.service.xxx無法執行service)
what why when【前端TS】)

)
)
)


)
-Spark 是什么?)

網絡層)



)



