Kotaemon 是一個基于 RAG(Retrieval-Augmented Generation)架構的開源文檔問答工具,為用戶提供與文檔對話的智能交互體驗。該項目同時服務于終端用戶和開發者,具有高度的可擴展性和定制化能力。
技術棧分析
核心技術棧
- 后端框架
- Python 3.10+: 主要開發語言
- Gradio: Web UI 框架,用于構建交互式界面
- FastAPI/Flask: API 服務層(推測)
- AI/ML 技術棧
- LangChain: LLM 集成和管道構建
- Transformers: 模型推理和嵌入
- llama-cpp-python: 本地 LLM 支持
- Ollama: 本地模型管理
- 向量數據庫和檢索
- ChromaDB: 默認向量數據庫
- LanceDB: 高性能向量存儲
- Elasticsearch: 全文搜索支持
- Milvus/Qdrant: 可選向量數據庫
- 文檔處理
- Unstructured: 多格式文檔解析
- PDF.js: PDF 瀏覽器內預覽
- Azure Document Intelligence: OCR 和表格解析
- Adobe PDF Extract: 高級 PDF 內容提取
- Docling: 開源文檔解析
- 部署和容器化
- Docker: 容器化部署
- Docker Compose: 多服務編排
支持的 LLM 提供商
- OpenAI (GPT-3.5, GPT-4)
- Azure OpenAI
- Cohere
- Groq
- Ollama (本地模型)
- 本地 GGUF 模型
項目優勢
1. 架構設計優勢
- 模塊化設計: 高度解耦的組件架構
- 混合檢索: 結合全文檢索和向量檢索
- 多模態支持: 處理文本、圖像、表格等多種內容
- 插件化架構: 易于擴展和定制
2. 用戶體驗優勢
- 直觀的 Web UI: 基于 Gradio 的現代化界面
- 多用戶支持: 支持用戶權限管理和協作
- 實時預覽: 內置 PDF 查看器和高亮顯示
- 詳細引用: 提供來源追溯和相關性評分
3. 技術實現優勢
- 混合 RAG 管道: 提高檢索準確性
- 復雜推理支持: 支持 ReAct、ReWOO 等智能體
- GraphRAG 集成: 支持知識圖譜增強檢索
- 本地化部署: 支持完全離線運行
4. 開發者友好
- 豐富的文檔: 詳細的開發和使用指南
- 可定制性強: 支持自定義推理和索引管道
- Docker 支持: 簡化部署流程
項目劣勢
1. 性能局限性
- 資源消耗: 多模型并行可能消耗大量內存
- 處理速度: 復雜文檔解析可能較慢
- 擴展性: 單機部署在大規模使用時可能存在瓶頸
2. 技術依賴
- 版本沖突: 多個 AI 庫可能存在依賴沖突
- API 依賴: 某些功能強依賴外部 API
- 模型兼容性: 不同模型格式的支持程度不一
3. 維護復雜性
- 配置復雜: 多種組件需要協調配置
- 更新維護: AI 技術棧更新頻繁,維護成本高
- 調試困難: 復雜的 RAG 管道難以調試
使用場景
1. 企業知識管理
- 內部文檔檢索: 企業內部知識庫建設
- 技術文檔問答: 開發團隊技術資料查詢
- 合規文檔管理: 法務和合規文件智能檢索
2. 教育培訓
- 學術研究: 研究論文和資料分析
- 在線教育: 教材內容智能問答
- 培訓材料: 員工培訓資料互動學習
3. 個人知識助手
- 文檔整理: 個人文檔集合管理
- 閱讀助手: 長文檔快速理解
- 筆記系統: 智能筆記檢索和整理
4. 專業服務
- 法律咨詢: 法律條文和案例檢索
- 醫療文檔: 醫學資料和病歷分析
- 金融報告: 財務文檔智能分析
代碼結構分析
主要目錄結構
kotaemon/
├── app.py # 主應用入口
├── flowsettings.py # 應用配置
├── libs/
│ └── ktem/
│ ├── ktem/
│ │ ├── reasoning/ # 推理模塊
│ │ ├── index/ # 索引模塊
│ │ ├── retrieval/ # 檢索模塊
│ │ ├── llms/ # LLM 集成
│ │ └── embeddings/ # 嵌入模型
├── ktem_app_data/ # 應用數據存儲
├── docker/ # Docker 配置
└── docs/ # 文檔核心組件架構
1. 推理引擎 (Reasoning Engine)
python
# 簡化的推理管道接口
class ReasoningPipeline:def __init__(self, retriever, generator, reranker):self.retriever = retrieverself.generator = generatorself.reranker = rerankerdef process(self, query: str, documents: List[Document]):# 檢索相關文檔retrieved = self.retriever.retrieve(query, documents)# 重新排序reranked = self.reranker.rerank(query, retrieved)# 生成答案answer = self.generator.generate(query, reranked)return answer2. 文檔索引系統
python
# 混合索引實現
class HybridIndex:def __init__(self, vector_store, text_store):self.vector_store = vector_store # 向量檢索self.text_store = text_store # 全文檢索def add_document(self, document):# 向量化存儲embeddings = self.embed(document.content)self.vector_store.add(document.id, embeddings)# 全文索引self.text_store.add(document.id, document.content)def search(self, query, top_k=10):# 混合檢索vector_results = self.vector_store.similarity_search(query, top_k//2)text_results = self.text_store.keyword_search(query, top_k//2)return self.merge_results(vector_results, text_results)主要執行流程
1. 文檔上傳和索引流程
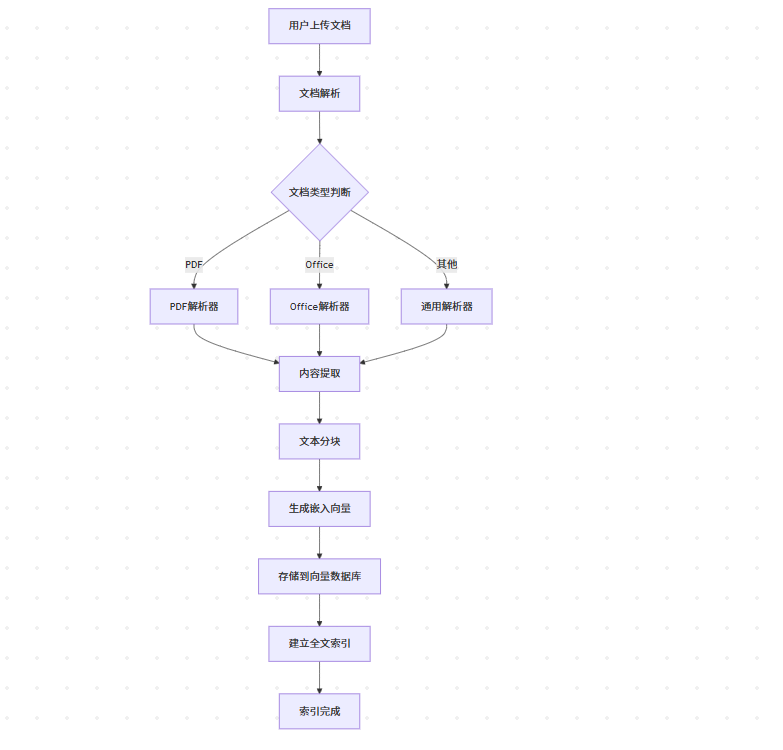
2. 問答查詢流程
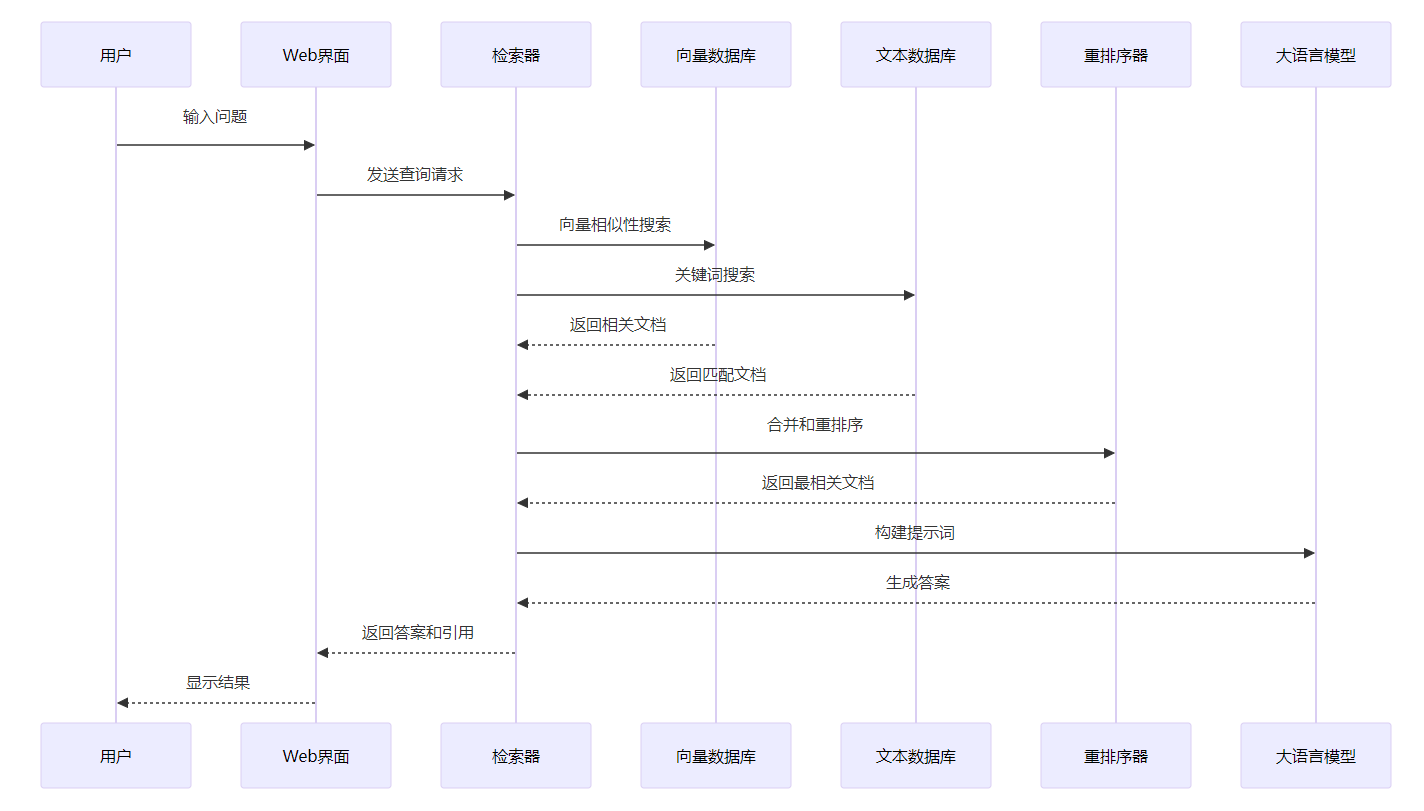
開發示例
1. 自定義推理管道
python
from ktem.reasoning.base import BaseReasoning
from ktem.llms.manager import LLMManager
from ktem.retrieval.manager import RetrievalManagerclass CustomQAPipeline(BaseReasoning):"""自定義問答管道"""def __init__(self):super().__init__()self.llm_manager = LLMManager()self.retrieval_manager = RetrievalManager()def run(self, query: str, conversation_id: str = None):"""執行問答流程"""# 1. 預處理查詢processed_query = self.preprocess_query(query)# 2. 檢索相關文檔retrieved_docs = self.retrieval_manager.retrieve(query=processed_query,top_k=10)# 3. 文檔重排序reranked_docs = self.rerank_documents(processed_query, retrieved_docs)# 4. 構建上下文context = self.build_context(reranked_docs[:5])# 5. 生成答案prompt = self.create_prompt(processed_query, context)response = self.llm_manager.generate(prompt)# 6. 后處理final_answer = self.postprocess_answer(response, reranked_docs)return {"answer": final_answer,"sources": [doc.metadata for doc in reranked_docs[:3]],"confidence": self.calculate_confidence(response, reranked_docs)}def preprocess_query(self, query: str) -> str:"""查詢預處理"""# 可以添加查詢擴展、糾錯等邏輯return query.strip()def rerank_documents(self, query: str, docs: List) -> List:"""文檔重排序"""# 實現自定義重排序邏輯return sorted(docs, key=lambda x: x.score, reverse=True)def build_context(self, docs: List) -> str:"""構建上下文"""context_parts = []for i, doc in enumerate(docs):context_parts.append(f"文檔{i+1}: {doc.content}")return "\n\n".join(context_parts)def create_prompt(self, query: str, context: str) -> str:"""創建提示詞"""prompt = f"""基于以下上下文信息,回答用戶問題。請確保答案準確且有據可依。上下文信息:{context}用戶問題:{query}請提供詳細的答案,并指出信息來源:"""return promptdef postprocess_answer(self, response: str, docs: List) -> str:"""答案后處理"""# 可以添加答案驗證、格式化等邏輯return responsedef calculate_confidence(self, response: str, docs: List) -> float:"""計算置信度"""# 實現置信度計算邏輯return 0.852. 自定義文檔解析器
python
from ktem.index.file.base import BaseFileIndexRetriever
from typing import List, Dict, Anyclass CustomDocumentParser(BaseFileIndexRetriever):"""自定義文檔解析器"""def __init__(self, **kwargs):super().__init__(**kwargs)self.supported_extensions = ['.txt', '.md', '.json']def parse_document(self, file_path: str) -> Dict[str, Any]:"""解析文檔內容"""if file_path.endswith('.json'):return self.parse_json(file_path)elif file_path.endswith('.md'):return self.parse_markdown(file_path)else:return self.parse_text(file_path)def parse_json(self, file_path: str) -> Dict[str, Any]:"""解析JSON文檔"""import jsonwith open(file_path, 'r', encoding='utf-8') as f:data = json.load(f)# 提取文本內容text_content = self.extract_text_from_json(data)return {'content': text_content,'metadata': {'file_type': 'json','source': file_path,'structure': self.analyze_json_structure(data)}}def parse_markdown(self, file_path: str) -> Dict[str, Any]:"""解析Markdown文檔"""with open(file_path, 'r', encoding='utf-8') as f:content = f.read()# 提取標題和內容sections = self.extract_markdown_sections(content)return {'content': content,'metadata': {'file_type': 'markdown','source': file_path,'sections': sections}}def extract_text_from_json(self, data: Dict) -> str:"""從JSON中提取文本"""text_parts = []def extract_recursive(obj, path=""):if isinstance(obj, dict):for key, value in obj.items():new_path = f"{path}.{key}" if path else keyif isinstance(value, str):text_parts.append(f"{new_path}: {value}")else:extract_recursive(value, new_path)elif isinstance(obj, list):for i, item in enumerate(obj):extract_recursive(item, f"{path}[{i}]")extract_recursive(data)return "\n".join(text_parts)def extract_markdown_sections(self, content: str) -> List[Dict]:"""提取Markdown章節"""import resections = []lines = content.split('\n')current_section = Nonefor line in lines:if re.match(r'^#+\s', line):if current_section:sections.append(current_section)level = len(line) - len(line.lstrip('#'))title = line.lstrip('# ').strip()current_section = {'level': level,'title': title,'content': []}elif current_section:current_section['content'].append(line)if current_section:sections.append(current_section)return sections# 使用示例
parser = CustomDocumentParser()
document_data = parser.parse_document('example.json')3. 自定義檢索器
python
from ktem.retrieval.base import BaseRetriever
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarityclass TfidfRetriever(BaseRetriever):"""基于TF-IDF的檢索器"""def __init__(self, **kwargs):super().__init__(**kwargs)self.vectorizer = TfidfVectorizer(max_features=10000,stop_words='english',ngram_range=(1, 2))self.document_vectors = Noneself.documents = []def add_documents(self, documents: List):"""添加文檔到索引"""self.documents.extend(documents)# 提取文檔內容doc_contents = [doc.page_content for doc in self.documents]# 訓練TF-IDF向量器self.document_vectors = self.vectorizer.fit_transform(doc_contents)def retrieve(self, query: str, top_k: int = 10) -> List:"""檢索相關文檔"""if self.document_vectors is None:return []# 將查詢轉換為向量query_vector = self.vectorizer.transform([query])# 計算相似度similarities = cosine_similarity(query_vector, self.document_vectors).flatten()# 獲取top-k結果top_indices = np.argsort(similarities)[::-1][:top_k]results = []for idx in top_indices:if similarities[idx] > 0: # 過濾相似度為0的結果doc = self.documents[idx]doc.metadata['retrieval_score'] = similarities[idx]results.append(doc)return results二次開發建議
1. 系統架構優化
分布式部署
- 微服務化: 將檢索、生成、索引等功能拆分為獨立服務
- 負載均衡: 使用 Nginx 或云負載均衡器分發請求
- 緩存層: 引入 Redis 緩存常用查詢結果
- 消息隊列: 使用 RabbitMQ 或 Kafka 處理異步任務
數據庫優化
python
# 數據庫連接池配置示例
from sqlalchemy import create_engine
from sqlalchemy.pool import QueuePoolengine = create_engine("postgresql://user:pass@localhost/kotaemon",poolclass=QueuePool,pool_size=20,max_overflow=30,pool_recycle=3600
)2. 性能優化策略
檢索性能優化
python
class OptimizedRetriever:def __init__(self):self.cache = {}self.batch_size = 100def retrieve_with_cache(self, query: str, top_k: int = 10):cache_key = f"{query}_{top_k}"if cache_key in self.cache:return self.cache[cache_key]results = self.retrieve(query, top_k)self.cache[cache_key] = resultsreturn resultsdef batch_retrieve(self, queries: List[str]):"""批量檢索提高效率"""results = []for i in range(0, len(queries), self.batch_size):batch = queries[i:i + self.batch_size]batch_results = [self.retrieve(q) for q in batch]results.extend(batch_results)return results異步處理
python
import asyncio
from concurrent.futures import ThreadPoolExecutorclass AsyncProcessor:def __init__(self, max_workers=4):self.executor = ThreadPoolExecutor(max_workers=max_workers)async def async_retrieve(self, query: str):"""異步檢索"""loop = asyncio.get_event_loop()return await loop.run_in_executor(self.executor, self.retriever.retrieve, query)async def async_generate(self, prompt: str):"""異步生成"""loop = asyncio.get_event_loop()return await loop.run_in_executor(self.executor,self.llm.generate,prompt)3. 功能擴展建議
A. 多語言支持
python
class MultiLanguageProcessor:def __init__(self):self.language_detectors = {'zh': ChineseProcessor(),'en': EnglishProcessor(),'ja': JapaneseProcessor()}def detect_language(self, text: str) -> str:# 語言檢測邏輯passdef process_by_language(self, text: str, lang: str):processor = self.language_detectors.get(lang)if processor:return processor.process(text)return textB. 實時協作功能
python
import websocket
import jsonclass CollaborationManager:def __init__(self):self.active_sessions = {}self.document_locks = {}def handle_user_action(self, user_id: str, action: dict):"""處理用戶協作行為"""if action['type'] == 'document_edit':self.broadcast_change(action, exclude_user=user_id)elif action['type'] == 'comment_add':self.save_comment(action)self.notify_collaborators(action)def broadcast_change(self, change: dict, exclude_user: str = None):"""廣播文檔變更"""for session_id, session in self.active_sessions.items():if session.user_id != exclude_user:session.send_message(change)C. 高級分析功能
python
class AnalyticsEngine:def __init__(self):self.query_analyzer = QueryAnalyzer()self.performance_monitor = PerformanceMonitor()def analyze_user_behavior(self, user_id: str):"""分析用戶行為模式"""queries = self.get_user_queries(user_id)patterns = self.query_analyzer.identify_patterns(queries)return {'frequent_topics': patterns['topics'],'query_complexity': patterns['complexity'],'usage_trends': patterns['trends']}def generate_insights(self):"""生成系統洞察報告"""return {'popular_documents': self.get_popular_documents(),'query_success_rate': self.calculate_success_rate(),'performance_metrics': self.performance_monitor.get_metrics()}4. 安全性增強
用戶認證和授權
python
from flask_jwt_extended import JWTManager, create_access_token
from werkzeug.security import check_password_hashclass AuthManager:def __init__(self):self.jwt = JWTManager()def authenticate_user(self, username: str, password: str):"""用戶身份驗證"""user = self.get_user(username)if user and check_password_hash(user.password_hash, password):access_token = create_access_token(identity=user.id)return {'access_token': access_token, 'user': user}return Nonedef authorize_document_access(self, user_id: str, document_id: str):"""文檔訪問授權"""document = self.get_document(document_id)return document.is_accessible_by(user_id)數據加密
python
from cryptography.fernet import Fernetclass DataEncryption:def __init__(self, key: bytes = None):self.key = key or Fernet.generate_key()self.cipher = Fernet(self.key)def encrypt_document(self, content: str) -> bytes:"""加密文檔內容"""return self.cipher.encrypt(content.encode())def decrypt_document(self, encrypted_content: bytes) -> str:"""解密文檔內容"""return self.cipher.decrypt(encrypted_content).decode()5. 監控和運維
系統監控
python
import logging
import time
from functools import wrapsclass SystemMonitor:def __init__(self):self.logger = logging.getLogger('kotaemon_monitor')self.metrics = {'request_count': 0,'error_count': 0,'avg_response_time': 0}def monitor_function(self, func):"""函數監控裝飾器"""@wraps(func)def wrapper(*args, **kwargs):start_time = time.time()try:result = func(*args, **kwargs)self.metrics['request_count'] += 1return resultexcept Exception as e:self.metrics['error_count'] += 1self.logger.error(f"Error in {func.__name__}: {str(e)}")raisefinally:duration = time.time() - start_timeself.update_response_time(duration)return wrapperdef update_response_time(self, duration: float):"""更新平均響應時間"""current_avg = self.metrics['avg_response_time']count = self.metrics['request_count']self.metrics['avg_response_time'] = (current_avg * (count - 1) + duration) / count6. 部署建議
Docker Compose 生產配置
yaml
version: '3.8'
services:kotaemon-app:build: .ports:- "7860:7860"environment:- POSTGRES_URL=postgresql://user:pass@db:5432/kotaemon- REDIS_URL=redis://redis:6379- ELASTICSEARCH_URL=http://elasticsearch:9200depends_on:- db- redis- elasticsearchvolumes:- ./app_data:/app/ktem_app_datadeploy:replicas: 3resources:limits:memory: 4Gcpus: '2'db:image: postgres:15environment:POSTGRES_DB: kotaemonPOSTGRES_USER: userPOSTGRES_PASSWORD: passvolumes:- postgres_data:/var/lib/postgresql/dataredis:image: redis:7-alpinevolumes:- redis_data:/dataelasticsearch:image: elasticsearch:8.8.0environment:- discovery.type=single-node- xpack.security.enabled=falsevolumes:- elasticsearch_data:/usr/share/elasticsearch/datavolumes:postgres_data:redis_data:elasticsearch_data:CI/CD 管道
yaml
# .github/workflows/deploy.yml
name: Deploy Kotaemonon:push:branches: [main]jobs:test:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v3- name: Set up Pythonuses: actions/setup-python@v4with:python-version: '3.10'- name: Install dependenciesrun: |pip install -r requirements.txtpip install -r requirements-dev.txt- name: Run testsrun: pytest tests/deploy:needs: testruns-on: ubuntu-lateststeps:- name: Deploy to productionrun: |docker-compose -f docker-compose.prod.yml up -d總結
Kotaemon 是一個技術棧豐富、架構合理的開源 RAG 項目,具有很高的實用價值和擴展潛力。通過合理的二次開發,可以構建出滿足特定業務需求的智能文檔問答系統。建議開發者在使用時注重性能優化、安全防護和系統監控,以確保系統的穩定性和可擴展性。

)















和insubclass())
里的函數是否調用成功)
