基于 Apache Doris 構建數據倉庫的方案和具體例子。Doris 以其高性能、易用性和實時能力,成為構建現代化數據倉庫(特別是 OLAP 場景)的優秀選擇。
一、為什么選擇 Doris 構建數據倉庫?
Doris(原名 Palo)是一個基于 MPP 架構的高性能、實分析型數據庫,非常適合作為數據倉庫(DW)和即席查詢(Ad-hoc Query)的解決方案。
核心優勢:
極高性能:
列式存儲、向量化執行引擎、預聚合(物化視圖)。
支持高并發點查詢,響應延遲可低至毫秒級。
簡單易用:
兼容 MySQL 協議,使用標準 SQL,學習和使用成本極低。
無需依賴 Hadoop 生態(HDFS/Hive/Spark)的繁重組件,架構簡單,運維方便。
實時分析:
支持實時數據導入(如通過 Routine Load 消費 Kafka 數據),從數據產生到可查詢可達秒級延遲。
統一化:
一個系統同時支持離線批量數據和實時流式數據的導入與分析,避免了 Lambda 架構的復雜性。
聯邦查詢:
支持通過 ODBC/MySQL 外表功能查詢其他數據源(如 MySQL, PostgreSQL, Elasticsearch, Hive 等),方便地整合現有數據。
二、典型數據倉庫架構方案(基于 Doris)
二、典型數據倉庫架構方案(基于 Doris)(文字描述版)
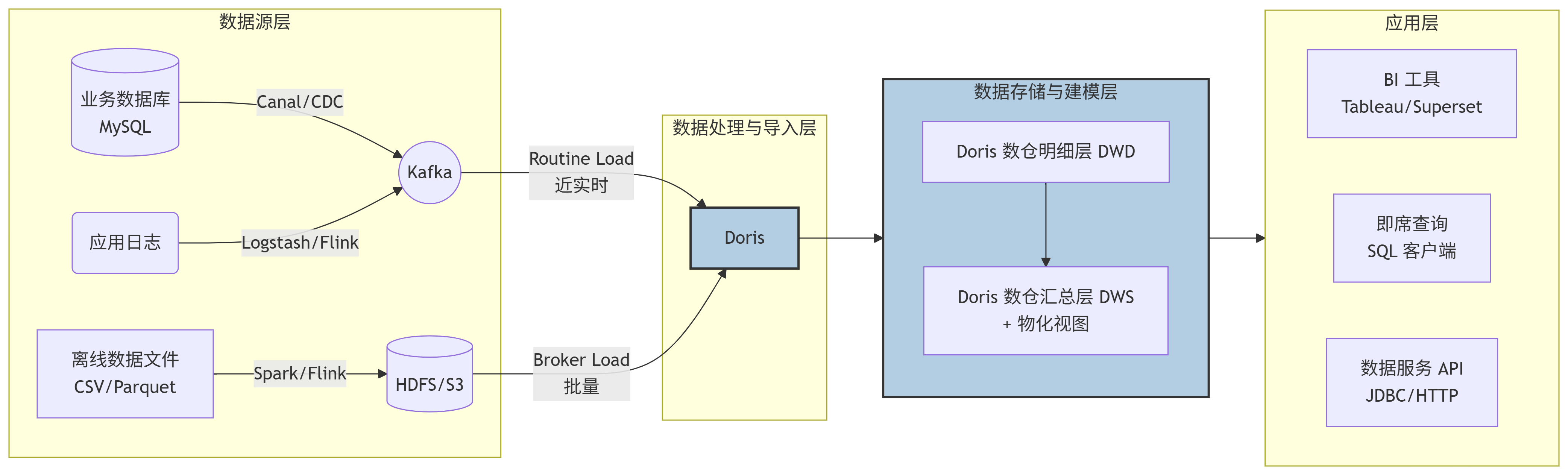
整個數據流向可以清晰地分為四個層級,數據從左向右流動:
數據源層 (Data Sources) -> 數據處理與導入層 (Data Ingestion) -> 數據存儲與建模層 (Data Storage & Modeling) -> 數據應用層 (Data Application)
1. 數據源層 (Data Sources)
業務數據庫 (MySQL/PostgreSQL等): 通過 Change Data Capture (CDC) 工具(如 Canal, Debezium)實時捕獲數據變更,并將變更日志推送到消息隊列。
應用日志/點擊流: 通過日志收集工具(如 Logstash, Flume)或實時計算框架(如 Flink)進行初步處理后,寫入消息隊列。
離線數據文件: 來自其他數據處理系統(如 Spark, Hive 作業)的批量數據文件,通常以列式格式(如 Parquet, ORC)存放在分布式文件系統(如 HDFS)或對象存儲(如 S3)上。
2. 數據處理與導入層 (Data Ingestion)
這是 Doris 與數據源對接的關鍵環節,它提供了多種靈活的導入方式:
對于實時數據流 (Kafka): 使用?Routine Load?功能。Doris 可以作為一個消費者,持續地從 Kafka 主題中拉取數據,并近乎實時地(秒級延遲)導入到內部表中。
對于批量數據文件 (HDFS/S3): 使用?Broker Load?功能。Doris 通過部署的 Broker 節點,并行地讀取遠端存儲上的大量數據文件,并高效地導入到內部表中。也可以使用?Spark-Doris-Connector?從 Spark 直接寫入。
3. 數據存儲與建模層 (Data Storage & Modeling in Doris)
這是 Doris 的核心,數據在這里被有序地組織和管理。
采用經典的數倉分層思想:
明細層 (DWD): 通常創建?
Duplicate?明細表,存儲最細粒度的原始數據,保留所有細節,用于全明細查詢和回溯。匯總層 (DWS/ADS): 通常創建?
Aggregate?或?Unique?表。更重要的是,可以利用?物化視圖 (Materialized View)?在這一層對常用維度和指標進行預聚合,極大提升后續的查詢性能。
數據按照分區和分桶策略進行分布式存儲,保證查詢和導入的效率。
4. 數據應用層 (Data Application)
處理好的數據最終服務于上層應用:
BI 工具 (Tableau, Superset, FineBI): 這些工具通過標準的?MySQL 協議?直接連接到 Doris,執行查詢并生成報表和儀表盤。
即席查詢 (Ad-hoc Query): 數據分析師和開發人員可以通過任何兼容 MySQL 的客戶端(如 MySQL CLI, DBeaver, HeidiSQL)直接編寫 SQL 進行探索式分析。
數據服務 API: 后端應用程序可以通過?JDBC?或?HTTP?接口(如 Doris 的 RESTful API)來獲取數據,為業務系統提供數據支持。
架構圖(Mermaid 代碼塊)
為了更直觀的理解,以下是上述架構的 Mermaid 流程圖代碼。您可以在支持 Mermaid 的編輯器(如 Typora、Obsidian、GitHub 等)中直接渲染查看:
架構圖(純文本示意圖)
如果 Mermaid 仍然無法渲染,請參考以下純文本描述的數據流圖:
text
+------------------+ +-------------------------+ +-----------------------+ | 數據源層 | | 數據處理與導入層 | | 數據存儲與建模層 | | | | | | | | MySQL -> CDC -> | ---> | Kafka -> Routine Load ->| ---> | Doris DWD層 | | 日志 -> Flume ->| ---> | | | | | HDFS -> Spark ->| ---> | HDFS -> Broker Load --->| ---> | Doris DWS層 | | | | | | (物化視圖加速) | +------------------+ +-------------------------+ +-----------------------+|v +------------------+ +---------------------------------+ +-----------------------+ | 數據應用層 | <--- | MySQL Protocol | <--- | | | | | JDBC / HTTP | | | | BI 工具 | <--- | | | | | 即席查詢 | <--- | | | | | 數據API | <--- | | | | +------------------+ +---------------------------------+ +-----------------------+
各層說明:
數據源 (Data Sources):
業務數據庫: 如 MySQL、PostgreSQL,通過 CDC(Change Data Capture)工具(如 Canal, Debezium)將增量數據實時送入 Kafka。
應用日志: 通過 Logstash、Flume 或 Flink 處理后寫入 Kafka。
離線文件: 來自其他系統(如 Spark/ Hive 作業)的 CSV、Parquet 文件,通常存放在 HDFS 或 S3 上。
數據處理與導入 (Data Ingestion):
實時導入: 使用 Doris 的?Routine Load?功能,持續消費 Kafka 中的消息,實現實時數據接入。
批量導入: 使用?Broker Load?或?Spark-Doris-Connector?將 HDFS/S3 上的大批量數據高效導入 Doris。
數據存儲與建模 (Data Storage & Modeling in Doris):
這是核心。Doris 內部采用?星型模型?或?雪花模型?來組織數據。
明細層 (DWD): 創建?
Duplicate?明細表,存儲最細粒度的原始數據,用于全明細查詢。匯總層 (DWS/ADS): 創建?
Aggregate?或?Unique?表,或者利用物化視圖(Materialized View)預聚合常用維度指標,極大提升查詢性能。
數據應用 (Data Application):
BI 工具: 通過 MySQL 協議直接連接 Doris,進行可視化分析(Tableau, Superset, FineBI)。
即席查詢: 數據分析師使用標準 SQL 客戶端直接查詢 Doris。
數據服務 API: 應用程序通過 JDBC 或 HTTP 接口(如 RESTful API)從 Doris 獲取數據。
三、具體實現例子:電商數據倉庫
我們以一個經典的電商場景為例,分析用戶行為和訂單數據。
步驟 1:創建數據庫與表
首先,在 Doris 中創建數據庫。
sql
CREATE DATABASE IF NOT EXISTS ecommerce_dw; USE ecommerce_dw;
1. 創建明細表 (DWD?層):dwd_user_behavior
存儲用戶的所有行為數據(點擊、加購、購買等)。
sql
CREATE TABLE IF NOT EXISTS dwd_user_behavior (`user_id` INT COMMENT '用戶ID',`item_id` INT COMMENT '商品ID',`category_id` INT COMMENT '商品類目ID',`behavior_type` VARCHAR(20) COMMENT '行為類型: pv, buy, cart, fav',`timestamp` BIGINT COMMENT '行為發生的時間戳',`dt` DATE COMMENT '基于timestamp生成的日期, 用于分區'
) ENGINE=OLAP
DUPLICATE KEY(`user_id`, `item_id`, `timestamp`) -- 明細數據,用Duplicate模型
PARTITION BY RANGE(`dt`) () -- 按天分區
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES ("replication_num" = "3"
);2. 創建匯總表 (DWS?層):dws_user_behavior_daily
按用戶和天預聚合常用指標。
sql
CREATE TABLE IF NOT EXISTS dws_user_behavior_daily (`user_id` INT COMMENT '用戶ID',`dt` DATE COMMENT '日期',`pv_count` BIGINT SUM DEFAULT "0" COMMENT '當日總點擊數',`buy_count` BIGINT SUM DEFAULT "0" COMMENT '當日總購買次數',`cart_count` BIGINT SUM DEFAULT "0" COMMENT '當日加購次數',`fav_count` BIGINT SUM DEFAULT "0" COMMENT '當日收藏次數',`last_visit_time` DATETIME REPLACE COMMENT '最后訪問時間'
) ENGINE=OLAP
AGGREGATE KEY(`user_id`, `dt`) -- 匯總數據,用Aggregate模型
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES ("replication_num" = "3"
);注意:也可以使用物化視圖(Materialized View)在明細表上自動維護匯總數據,無需手動創建和更新此表。
步驟 2:數據導入
實時導入用戶行為數據(從 Kafka):
假設用戶行為日志已經寫入 Kafka 的?user_behavior_topic。
sql
CREATE ROUTINE LOAD ecommerce_dw.user_behavior_kafka_load ON dwd_user_behavior
COLUMNS(user_id, item_id, category_id, behavior_type, timestamp, dt=from_unixtime(timestamp, '%Y%m%d')),
ROUTINE LOAD PROPERTIES
("desired_concurrent_number" = "5","max_error_number" = "1000"
)
FROM KAFKA
("kafka_broker_list" = "kafka-host01:9092,kafka-host02:9092","kafka_topic" = "user_behavior_topic","property.group.id" = "doris-dw","property.security.protocol" = "SASL_PLAINTEXT",-- ... 其他Kafka認證配置
);批量導入歷史訂單數據(從 HDFS):
sql
LOAD LABEL ecommerce_dw.hdfs_order_load_20231027
(DATA INFILE("hdfs://namenode:8020/path/to/orders/*.parquet")INTO TABLE `dwd_orders` -- 假設有訂單明細表FORMAT AS "parquet"
)
WITH BROKER "broker_name"
("username" = "hdfs_user","password" = "hdfs_password"
)
PROPERTIES
("timeout" = "3600"
);步驟 3:數據建模與查詢
1. 明細查詢 (DWD)
查詢某個用戶的所有原始行為記錄。
sql
SELECT * FROM dwd_user_behavior WHERE user_id = 123456 AND dt = '2023-10-27' ORDER BY timestamp DESC LIMIT 100;
2. 匯總分析 (DWS)
基于匯總表,查詢每日最活躍的 Top 10 用戶,性能極快。
sql
SELECT user_id, dt, pv_count FROM dws_user_behavior_daily ORDER BY pv_count DESC LIMIT 10;
3. 復雜分析
即使沒有預聚合,直接查詢明細表,Doris 也能提供不錯的性能。例如,分析購買轉化率(漏斗分析):
sql
SELECTdt,COUNT(DISTINCT user_id) AS total_uv,COUNT(DISTINCT IF(behavior_type = 'buy', user_id, NULL)) AS buy_uv,COUNT(DISTINCT IF(behavior_type = 'buy', user_id, NULL)) / COUNT(DISTINCT user_id) AS conversion_rate FROM dwd_user_behavior WHERE dt >= '2023-10-20' GROUP BY dt ORDER BY dt;
步驟 4:使用物化視圖(Materialized View)加速
為?dwd_user_behavior?表創建一個按?category_id?預聚合的物化視圖,加速類目分析查詢。
sql
-- 創建物化視圖 CREATE MATERIALIZED VIEW category_behavior_mv AS SELECTcategory_id,dt,COUNT(*) AS pv,COUNT(DISTINCT user_id) AS uv,SUM(IF(behavior_type = 'buy', 1, 0)) AS buy_count FROM dwd_user_behavior GROUP BY category_id, dt;-- 查詢會自動路由到物化視圖,速度極快 SELECT category_id, SUM(pv) AS total_pv FROM dwd_user_behavior WHERE dt BETWEEN '2023-10-01' AND '2023-10-31' GROUP BY category_id ORDER BY total_pv DESC LIMIT 10;
Doris 的查詢優化器會自動判斷是否可以使用物化視圖來加速查詢,對用戶透明。
四、最佳實踐與建議
數據模型設計:
謹慎選擇分區鍵(
PARTITION BY)和分桶鍵(DISTRIBUTED BY)。分區用于管理,分桶用于并行。小表(如維度表)可使用?
Unique?模型,大事實表根據場景選擇?Duplicate?或?Aggregate?模型。
物化視圖策略:
為最常用且耗時的分組聚合查詢創建物化視圖。
物化視圖是空間換時間的策略,不宜過多,優先考慮公共和高頻查詢。
資源與監控:
合理設置?
replication_num(通常 3 副本保證高可用)。監控 FE/BE 節點的 CPU、內存、磁盤使用情況,以及導入任務的延遲和錯誤率。
數據生命周期管理:
使用?
PARTITION?功能,結合動態分區特性,自動創建新分區和刪除舊分區(ALTER TABLE ... SET ("dynamic_partition.enable" = "true")),實現數據滾動更新。
總結
Apache Doris 提供了一個?簡單、高性能、實時統一?的數據倉庫解決方案。通過將實時流和批量數據高效導入,并利用其內置的聚合模型和物化視圖等特性,可以輕松構建從明細層到匯總層的數據體系,支撐企業級的高并發即席查詢和復雜的多維分析需求,極大地簡化了傳統大數據架構的復雜度。








)


)




-)

)
