
文章目錄
- 一、背景介紹
- 二、說明
- 核心概念:什么是字節序(Endianness)?
- 大端字節序 (Big-Endian)
- 小端字節序 (Little-Endian)
- 三、不同解析方式介紹
一、背景介紹
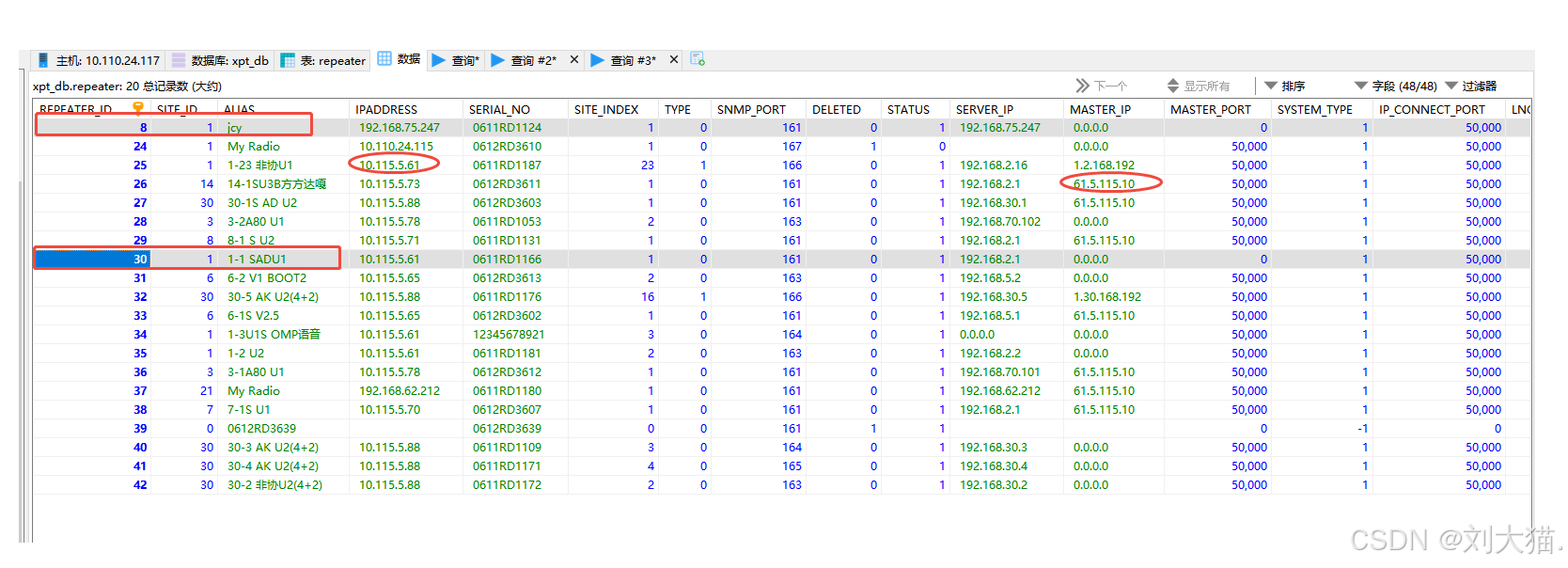
中轉臺通過SNMP協議V1\V2上報中轉臺IP,然后程序解析入庫,后來發現解析網絡分大端、小端的不同解析方法。
當時數據庫存多個字段:主節點IP、從節點IP、IP地址,通過看紅框的部分發現就是正序和反序的區別,實際是相同的IP地址,只不過大端小端解析不同,最后結果也不同。因此記錄下!
二、說明
核心概念:什么是字節序(Endianness)?
字節序指的是多字節數據在內存中或網絡傳輸時,各個字節的存儲順序。
對于一個像 0x12345678 這樣的32位整數(十六進制表示),它由4個字節組成:0x12, 0x34, 0x56, 0x78。
問題是:當我們把它存入內存(或通過網絡發送)時,哪個字節在先?哪個字節在后?
這就產生了兩種不同的規則:
大端字節序 (Big-Endian)

小端字節序 (Little-Endian)

三、不同解析方式介紹
大端解析
public String getBigEndianMasterIPAddress() {Object o = getItemValue(OID_REPEATER_MASTER_IP_ADDRESS);try {if (o != null) {int nIp = (Integer) o;byte[] ip = ByteBuffer.allocate(4).putInt(nIp).array();InetAddress ipaddr = InetAddress.getByAddress(ip);return ipaddr.getHostAddress();}} catch (UnknownHostException e) {logger.error("parse ip address error:", e);}return "";
}
小端解析
public String getMasterIPAddress() {Object o = getItemValue(OID_REPEATER_MASTER_IP_ADDRESS);try {if (o != null) {int nIp = (Integer) o;byte[] ip = new byte[]{(byte) (nIp & 0xFF),(byte) (nIp >> 8 & 0xFF),(byte) (nIp >> 16 & 0xFF),(byte) (nIp >> 24 & 0xFF)};InetAddress ipaddr = InetAddress.getByAddress(ip);return ipaddr.getHostAddress();}} catch (UnknownHostException e) {logger.error("parse ip address error:", e);}return "";
}











服務商發展趨勢與企業賦能白皮書)
)


:原理、實現與應用)

在路徑規劃中的應用)

