前言
如此文《KungfuBot——基于物理約束和自適應運動追蹤的人形全身控制PBHC,用于學習打拳或跳舞(即RL下的動作模仿和運控)》的開頭所說
如此,便關注到最新出來的三個工作
- 第一個是GMT: General Motion Tracking for Humanoid Whole-Body Control
- 第二個是R2S2和OpenWBT
- 第三個則是本文要解讀的KungfuBot
相當于今25年6月下旬便關注到了GMT這個工作,但當時忙于搞幾個客戶的項目,一直沒來得及解讀,而如今新的兩個客戶項目剛剛開搞,故有時間來解讀下這個GMT
畢竟我司七月在線
- 一半科研,故一直研究 復現 改進前沿
- ?一半落地,為場景落地服務 實用第一
科研中兼顧落地,可以更好科研;??落地中兼顧科研,可以更好落地,?這也是我司的獨特優勢之一
第一部分 GMT
1.1 引言、相關工作
1.1.1 引言
如原GMT論文所說,人形機器人實現的主要目標之一,是能夠在日常環境中執行廣泛的任務。賦予人形機器人產生多樣化類人動作的能力,是實現這一目標的有力途徑
- 為了生成這類類人動作,需要一個通用的全身控制器——它能夠利用豐富的運動技能庫,既能完成自然行走等基礎任務,也能實現踢球、奔跑等更為動態和靈活的動作
- 有了這樣強大的全身控制器,就可以集成高層規劃器,實現技能的自主選擇與編排,從而為通用型人形機器人鋪平道路
由于人形系統具有高度自由度(DoF)以及現實世界動力學的復雜性,人工設計此類控制器既具有挑戰性,又極為耗時。由于人形機器人旨在高度仿真人體結構,因此人體運動數據為機器人賦予豐富技能提供了理想資源
在計算機圖形學領域,研究人員利用人體運動數據和基于學習的方法,開發出能夠為模擬角色提供統一控制的控制器,使其能夠以極具人類特征的行為,重現多種運動并執行多樣化技能
- Deepmimic
- Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters
- Perpetual humanoid control for real-time simulated avatars
- Pdp: Physics-based character animation via diffusion policy
- Maskedmimic
盡管在模擬領域取得了巨大進展,但為人形機器人開發這樣一種通用的統一控制器仍然具有挑戰性,原因包括:
- 部分可觀測性
對于現實世界中的機器人,完整的狀態信息(如線速度和全局根部位置)無法獲取,而這些信息在學習運動跟蹤策略時非常重要
缺乏這些信息使得訓練過程更加具有挑戰性 - 硬件限制
現有的人體動作數據集通常包含諸如后空翻和翻滾等動作,但由于硬件限制,仿人機器人難以執行這些動作
此外,即使是行走和奔跑等較為基礎的技能,機器人也可能難以產生足夠的扭矩,從而無法準確匹配人體動作的速度和動態表現
這些不匹配問題在為機器人訓練動作跟蹤控制器時,需要額外的特殊處理 - 數據分布不均衡
大型動作捕捉數據集「如 AMASS [6-AMASS: Archive of motion capture as surface shapes]」通常表現出高度不均衡的分布,如圖2所示,其中大部分動作涉及行走或原地活動
更為復雜或動態的動作較為稀缺,這可能導致機器人在掌握這些不常見但至關重要的技能時遇到困難
- 模型表達能力
雖然基于簡單MLP的網絡在跟蹤少量動作剪輯時可能足以開發出令人滿意的控制策略,但在應用于大規模Mocap數據集時往往表現不佳
這類架構通常缺乏捕捉復雜時序依賴和區分多樣動作類別的能力。表達能力的不足會導致跟蹤性能不理想,并且在廣泛技能范圍內的泛化能力較差
盡管已有研究嘗試解決上述某些單獨的問題,例如
- 采用師生訓練框架應對部分可觀測性[7-Exbody2,8-Omnih2o]
- 利用多類小型數據集對不同的專家策略進行微調[7]
- 以及采用transformer模型提升模型的表達能力[9-Humanplus]
但開發一個統一的通用運動跟蹤控制器仍然是一個未解難題
對此,來自1 UC San Diego、2 Simon Fraser University的研究者通過聯合解決這些問題,并結合其他精心的設計決策,構建一個高效的系統GMT,且能夠從大型動作捕捉數據集為現實世界的人形機器人訓練單一統一且高質量的運動跟蹤策略
GMT 的核心有兩項關鍵創新:
- 一種新穎的自適應采樣策略,旨在緩解由于動作類別分布不均導致學習罕見動作困難的問題
- 以及一種運動專家混合(MoE)架構,以增強模型的表達能力和泛化能力
圖1 展示了GMT策略在現實世界中的部署,表明其能夠通過策略在執行廣泛的上半身和下半身技能(包括不同的步態、下蹲、踢腿及其他富有表現力的全身動作)方面的能力,并通過單一統一策略實現了業界領先的性能

表1簡要對比了GMT與高度相關的現有研究

1.1.2 相關工作
開發一種通用的全身控制器,使人形機器人能夠執行廣泛的技能,一直是一個基礎但極具挑戰性的問題,主要原因在于系統的高維度和固有的不穩定性
- 傳統的基于模型的方法通過步態規劃和動力學建模,已經實現了對雙足和人形機器人具有魯棒性的全身運動控制器
12-Dynamic walk of a biped
13-A compliant hybrid zero dynamics controller for stable, efficient and fast bipedal walking on mabel
14-Positive force feedback in bouncing gaits? Proceedings of the Royal Society of London
然而,設計此類控制器通常需要大量的人工投入,并且需要對復雜動力學進行細致處理 - 近年來,基于學習的方法在構建全身控制器方面取得了顯著進展
這些方法
要么通過精心設計的任務獎勵來開發控制器
15-Humanoid locomotion as next token prediction
16-Learning humanoid locomotion over challenging terrain
17-Real-world humanoid locomotion with reinforcement learning,詳見此文:伯克利Digit——基于下一個token預測技術預測機器人動作token:從帶RL到不帶RL的自回歸預測
18-Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning
19-Learning smooth humanoid locomotion through lipschitz-constrained policies
20-Homie
21-Whole-body humanoid robot locomotion with human reference,其首次將人類運動數據用于全尺寸人形機器人的模仿學習
要么以人類動作為參考
11-ASAP
8-Omnih2o
9-Humanplus
7-Exbody2
10-Exbody,Expressive whole-body control for humanoid robots
22-Hover
23-H2O
首先,對于基于學習的人形機器人全身控制
本研究聚焦于人形機器人的全身控制
- 以往的研究表明,通過手動設計獎勵函數訓練的全身控制策略,能夠使人形機器人實現如行走[15,16,17,18,19]、跳躍[24,25,26]以及跌倒恢復[27,28]等運動技能
- 然而,這些控制器通常是針對特定任務設計的,需要為每個任務分別訓練帶有定制獎勵函數的策略。例如,為行走開發的策略難以直接遷移到跳躍或操作等其他任務中
相比之下,人類運動數據為開發通用控制器提供了一種有前景的方法,無需為每一項技能單獨設計任務特定的獎勵函數
其次,對于仿人動作模仿
利用人體運動數據為機器人開發類人的全身行為在角色動畫領域得到了廣泛研究
- 以往的工作已經在仿真角色上實現了高質量且通用的動作追蹤[1,3,5,4],并為各種下游任務提供了多樣化的動作技能任務 [29,2,30,31,32]
然而,由于現實世界中的部分可觀測性,為真實機器人開發此類全身控制器[10,33,9,8,7,11,34,35,36] 具有挑戰性 - 為開發統一的通用全身運動跟蹤控制器,一些工作將上半身與下半身控制解耦,以在表現力與平衡性之間做出權衡 [10,33]
HumanPlus [9] 和 OmniH2O [8] 隨后在全尺寸機器人上成功實現了全身動作模仿,但下半身動作不自然
ExBody2 [7] 實現了更好的全身跟蹤性能,但采用了多個獨立的專用策略
VMP [34] 展示了在真實機器人上高保真再現多種技能的能力,但其在部署時對動作捕捉系統的依賴限制了其在真實環境中的適用性
1.2?通用運動跟蹤控制器的學習
GMT采用了與先前研究[7,8]類似的兩階段師生訓練框架:
- 首先使用PPO[37]訓練具有特權信息的教師策略
即,繼先前的研究[7,8],在第一階段,訓練一個具有特權的教師策略,該策略能夠同時觀察本體感知信息和特權信息,并輸出關節目標動作,使用PPO [37]進行優化
- 然后通過DAgger[38]模仿教師策略的輸出來訓練一個可部署的學生策略
該策略以一系列本體感知觀測歷史作為輸入,并通過DAgger [38]由教師策略進行監督。學生策略通過最小化其輸出?與教師輸出
?之間的?2損失,即
,實現優化
- 對于仿真到現實遷移
為了實現成功的仿真到現實遷移,作者在教師策略和學生策略的訓練過程中應用了域隨機化方法 [41,42]。為了進一步對齊仿真與現實世界的物理動力學,且顯式建模了減速器轉動慣量的影響
具體而言,給定減速比k和減速器轉動慣量I,作者在仿真器中將armature參數配置為:
以近似由減速驅動器引入的有效慣量- 作者使用 IsaacGym [43] 作為物理仿真器,并設置了4096個并行環境。在一塊 RTX4090GPU 上,特權策略訓練大約持續3天,隨后學生策略訓練約1天。仿真頻率為500Hz,控制頻率為50Hz。訓練完成的策略會先在 Mujoco [46] 中進行驗證,然后再部署到真實機器人上
接下來,將首先介紹方法的核心組成部分,即自適應采樣策略和運動MoE架構。隨后,還會介紹對策略學習同樣至關重要的一些關鍵設計,包括運動輸入設計和數據集整理流程
1.2.1 自適應采樣
如圖2所示
- 大型動作數據集(如AMASS [6])存在顯著的類別不平衡。這種不平衡會極大阻礙對較少出現且更為復雜動作的學習
- 此外,這類數據集中的較長序列通常是復合動作,由一系列技能組成,既包含基礎片段,也包含具有挑戰性的片段
采用以往的采樣策略 [5,3] 時,當策略在較難片段上失敗,仍會在整個動作序列上進行訓練——而序列大多被簡單部分主導——這導致困難片段的有效采樣率很低
為了解決這些問題,作者引入了自適應采樣方法,該方法包含兩個關鍵組成部分
- 隨機剪輯:時長超過10秒的動作會被剪切成多個子片段,每個子片段的最長時長為10秒。為了防止片段銜接處出現偽影,作者通過引入最多2秒的隨機偏移,實現了隨機化剪輯
此外,所有動作在訓練過程中都會定期重新裁剪,以進一步豐富采樣的子片段; - 基于跟蹤性能的概率:在訓練過程中,作者會記錄每個動作的完成度
,并在跟蹤誤差超過
時終止該回合。當某一動作成功完成時,
因此,每個動作的采樣概率定義為:
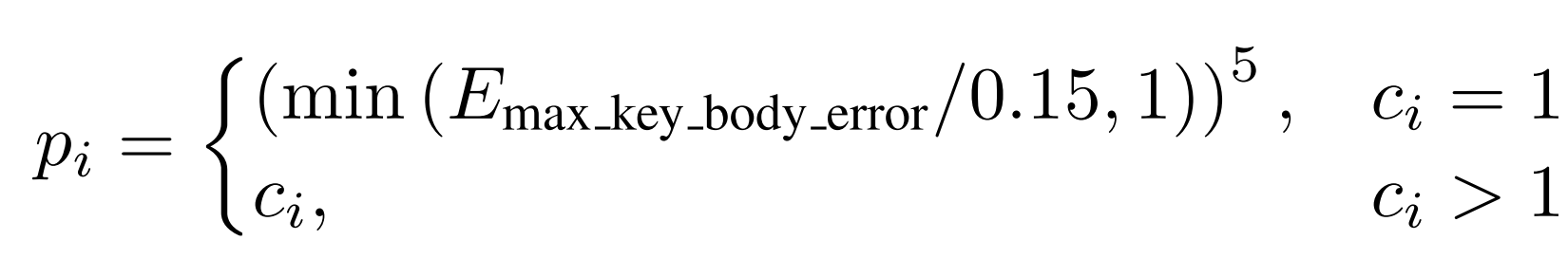
通過應用自適應采樣,作者避免了對長動作中簡單片段的重復采樣,從而將訓練重點放在跟蹤誤差較高的難動作上,以提升模型表現
1.2.2?動作混合專家模型
為了增強模型的表達能力,作者在教師策略的訓練過程中引入了一個軟MoE 模塊
具體模型如圖3 所示「其中,? 表示運動目標幀,
表示本體感知觀測,
表示特權信息」

策略網絡由一組專家網絡和一個門控網絡組成「The policy network consists of a group of expert networks and a gating network」
- 專家網絡expert networks以機器人狀態觀測和運動目標為輸入,輸出最終動作
- 門控網絡gating network 同樣以相同的觀測輸入,并輸出對所有專家的概率分布
最終的動作輸出是從每個專家的動作分布中采樣的動作的加權組合:,其中
為門控網絡輸出的每個專家的概率,
為每個專家策略的輸出
對于觀測與動作
- 對于教師策略,觀測由本體感知
、特權信息
和運動目標
?組成
- 對于學生策略,觀測包括本體感知
,以及運動目標
1.2.3?數據集整理
作者使用AMASS [6] 和LAFAN1 [39] 的組合來訓練動作追蹤策略。由于原始數據集包含由于硬件限制而出現的不可行動作,如爬行、倒地狀態以及極端動態動作
由于不可行動作代表噪聲并可能阻礙學習,作者采用了與以往工作[5] 類似的兩階段數據篩選流程
- 在第一階段,應用基于規則的過濾,去除不可行的動作——例如,根部的橫滾或俯仰角度超過指定閾值,或根部高度異常高或低的動作
- 在第二階段,在經過前述過濾的數據集上訓練一個初步策略,樣本量約為50 億
根據該策略的完成率,進一步過濾掉失敗的動作,最終得到的訓練數據集為經過篩選的AMASS 和LAFAN1 子集,共計8925 段,總時長33.12 小時
1.2.4?動作輸入:運動跟蹤——讓機器人在每一幀運動中跟蹤特定的目標
運動跟蹤的目標是讓機器人在每一幀運動中跟蹤特定的目標
作者將每一幀的運動跟蹤目標表示為
其中
表示關節位置
表示基座的線速度和角速度
表示基座的橫滾角和俯仰角
表示根部高度
對應于局部關鍵部位的位置
與以往采用全局關鍵部位位置的方法不同[8, 11],作者采用類似ExBody2[7] 的局部關鍵部位位置,并進一步改進為使局部關鍵部位相對于機器人的朝向對齊
- 此外,為了提高跟蹤性能,作者不僅僅使用緊接著的下一個運動幀作為輸入[7, 10, 8]。相反,作者堆疊了多個連續幀
,覆蓋大約兩秒的未來運動
- 這些堆疊的幀隨后通過卷積[40] 編碼器壓縮為一個潛在向量
,然后與緊接著的下一幀
結合,并輸入到策略網絡中
該設計使得策略能夠捕捉到運動序列的長期趨勢,并能夠明確識別當前的跟蹤目標
作者在實驗中表明,這一設計對于實現高質量的跟蹤至關重要
在本研究中,運動追蹤問題被定義為一個以目標為條件的強化學習問題,其中在給定目標的情況下,智能體根據策略π 與環境交互,以最大化目標函數[47]
- 在每一個時間步
?,智能體的策略以狀態
?和目標
?作為輸入,輸出動作
- 當動作
,會導致下一個狀態
。在每一個時間步,都會獲得獎勵
智能體的目標是最大化期望回報:
其中
表示軌跡
?的概率,
?表示時間范圍,
是折扣因子
下表表3是第一階段訓練的獎勵函數。這里
?表示關節位置,
表示關節速度,
表示關節加速度,r表示根部旋轉,v 表示根部速度,h 表示根部高度,p 表示關鍵身體位置

1.3 實驗
1.3.1 實驗設置
在仿真和真實環境中評估GMT
- 對于仿真實驗,每個策略使用大約68 億個樣本進行訓練,采用領域隨機化[41] 和動作延遲[42],訓練數據來自經過篩選的AMASS 和LAFAN1[39] 數據集子集;并在AMASS 測試集[3] 和LAFAN1 上進行評估
且使用IsaacGym[43] 作為仿真器,并行環境數量為4096 - 對于消融實驗和基線對比,作者主要關注特權策略的性能評估,因為可部署的學生策略僅通過模仿特權教師進行訓練
- 對于真實環境實驗,作者將他們的策略部署在Unitree G1 [44] 上,這是一款具有23 自由度、身高1.32 米的中型人形機器人
策略的跟蹤性能通過以下指標進行定量評估:
- Empkpe,每個關鍵身體位置的平均誤差,單位為mm
- Empjpe,每個關節位置的平均誤差,單位為rad
- Evel,線速度誤差,單位為m/s
- Evaw,偏航速度誤差,單位為rad/s
1.3.2 基線方法
在仿真中將GMT 的性能與ExBody2 [7] 進行了對比
作者重新實現了ExBody2,并在他們篩選后的數據集上對其進行了訓練
從表2 可以看出
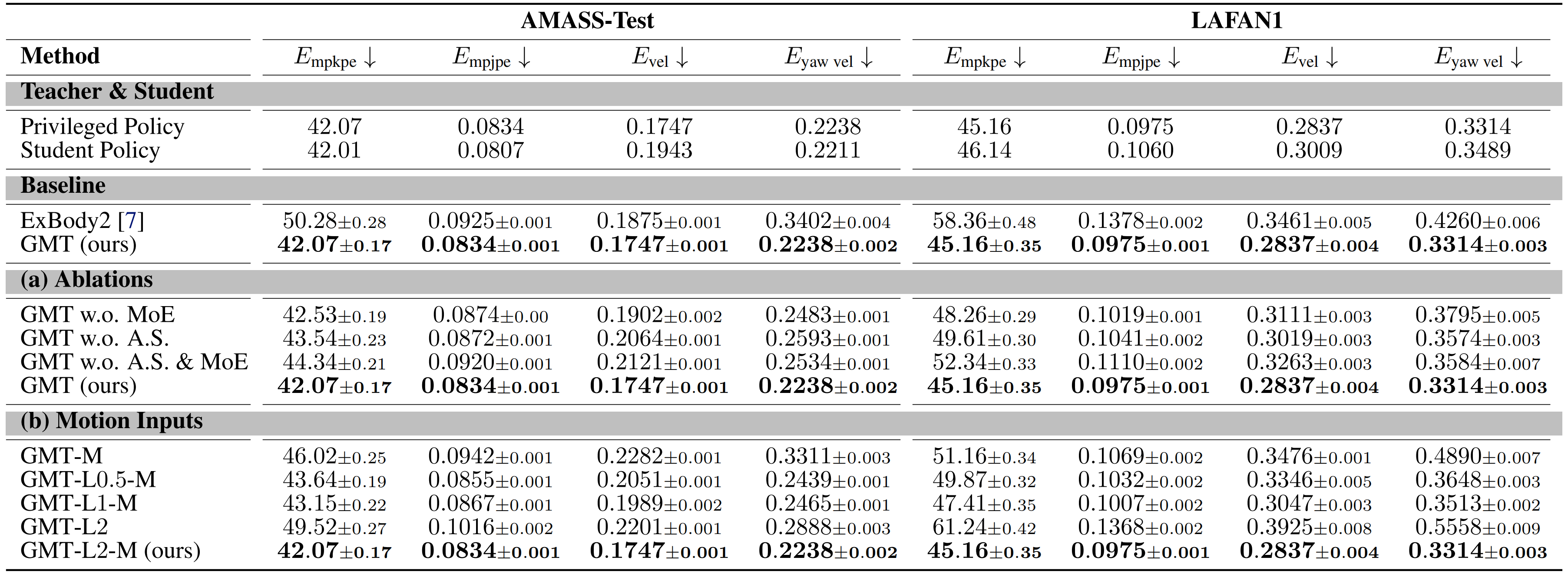
GMT 在局部跟蹤性能(Empkpe 和Empjpe )以及全局跟蹤性能(Evel 和Eyaw vel ) )上均優于ExBody2
1.3.3 消融研究
在本部分,作者進行了消融實驗,以探究各個組件的貢獻
具體而言,為了評估Motion MoE架構和自適應采樣策略的效果,設計了如下消融方案:
- GMT w.o. A.S. & MoE:將MoE模型替換為參數量相等的MLP,并移除自適應采樣
- GMT w.o. MoE:僅將MoE模型替換為相同規模的MLP
相當于有自適應采樣,但無MoE結構 - GMTw.o. A.S.:訓練過程中僅移除自適應采樣
相當于無自適應采樣,但有MoE結構
此外,作者還通過消融實驗研究了運動輸入配置的影響:
- GMT-M:僅將運動的下一個即時幀作為輸入提供給策略網絡
- GMT-Lx-M:將下一個即時幀以及未來x秒的運動幀窗口一同輸入到策略網絡中
- GMT-Lx:僅輸入未來x秒的運動幀窗口,不包括下一個即時幀
1.3.3.1?動作混合專家(Motion MoE)
如表2(a) 所示,GMT 在AMASS 測試集和整個LAFAN1 數據集上的跟蹤性能均優于基線方法

- 此外,如下圖圖5 所示,記錄了AMASS 上的頂端百分位跟蹤誤差。統計數據和圖表均表明,MoE 在更具挑戰性的動作上有更大的提升

- 對于定性評估,圖4 可視化了在一個包含站立、踢腿、向后走幾步以及再次站立的復合動作序列上的專家選擇

各專家隨時間的門控權重顯示出在動作不同階段專家激活的明顯轉換。這表明各專家在不同類型的動作上具有專長,驗證了MoE 結構在捕捉動作多樣性方面的預期作用
1.3.3.2?自適應采樣
如表2(a)所示
自適應采樣在兩個數據集上均有效提升了跟蹤性能
與MotionMoE類似,如圖5所示
自適應采樣在更具挑戰性的動作上提升更為顯著
- 為了定性評估該策略的影響,作者從一個長達240秒且復合的動作序列中提取了一個短片段,并在圖6(a)中對比了采用和未采用自適應采樣訓練的策略的表現

- 此外,作者在圖6(b)中繪制了關鍵關節(包括膝關節和髖關節滾轉)的力矩
結果顯示,如果沒有自適應采樣,策略無法高質量地學習該片段,并且難以保持平衡。這些問題使得實際部署變得不可能
1.3.3.3?運動輸入
表2(b)中的實驗結果顯示,增加運動輸入窗口的長度可以提升跟蹤精度。然而,GMT-L2的性能卻出現了顯著下降,這表明將緊接著的下一幀輸入到策略網絡同樣至關重要

這可以解釋為,雖然一系列未來幀能夠捕捉即將發生運動的整體趨勢,但可能會丟失一些細節信息。因此,輸入緊接著的下一幀納入策略中,可以通過提供最近的相關信息顯著提升跟蹤性能
1.3.4 真實世界部署與應用
如圖1所示,作者宣稱,他們已成功將他們的策略部署在真實的人形機器人上,能夠高保真地再現多種人類動作——包括風格化行走、高抬腿踢、跳舞、旋轉、蹲姿行走、足球踢球等,并實現了業界領先的性能
且在 MuJoCo [46] 的仿真到仿真(sim-to-sim)環境中,使用動作擴散模型MDM『45,詳見此文《可跳簡單舞蹈的Exbody 2——從MDM、RobotMDM到全身運動控制策略Exbody:人體運動擴散模型賦能機器人的訓練》的1.1節 動態擴散模型MDM』生成的動作對他們的策略進行了測試
圖 7 的結果顯示

GMT 能夠很好地執行通過文本提示由 MDM生成的動作,這證明了 GMT 應用于其他下游任務的潛力
總之,本文提出了GMT,一種通用且可擴展的運動跟蹤框架,可以通過訓練單一統一策略,使人形機器人在現實世界中模仿多樣化的動作
且作者進行了大量實驗,評估了各個組件對整體跟蹤性能的貢獻,并證明GMT能夠跟蹤來自其他資源(如MDM)的動作
當然,盡管GMT作為一個統一的通用運動跟蹤控制器實現了業界領先的性能,但它仍然存在一些局限性:
- 缺乏豐富接觸的技能
由于模擬接觸豐富行為所需的額外復雜性顯著增加 [27],再加上硬件的限制,他們的框架目前尚不支持諸如從倒地狀態起身或在地面翻滾等技能 - 對復雜地形的局限性
他們當前的策略是在沒有任何地形觀測的情況下訓練的,因此并未針對斜坡和樓梯等復雜地形進行模仿設計
未來的工作中,作者宣稱,計劃擴展他們的框架,開發一個能夠在平坦和復雜地形上均可運行的通用且魯棒的控制器
在路徑規劃中的應用)







抽象數據類型)





-- 使用im2col + GEMM 實現卷積)




)