文章目錄
- 前言
- 一、正則表達式概述
- 1.1 定義
- 1.2 主要用途
- 1.3 Linux 中的正則表達式分類
- 1.3.1 基礎正則表達式(BRE)
- 1.3.2 擴展正則表達式(ERE)
- 二、正則表達式的基本組成
- 2.1 普通字符
- 2.2 元字符
- 2.2.1 基本元字符
- 2.2.2 重復次數相關
- 2.2.3 擴展正則中的元字符(ERE)
- 2.2.4 `egrep`的用法
- 三、grep 工具的使用
- 3.1 常用選項
- 3.2 使用示例
- 四、正則表達式操作案例
- 4.1 查找特定字符
- 4.2 使用中括號集合
- 4.3 使用定位符
- 4.4 使用點與星號
- 4.5 使用次數限定符
- 五、基礎正則與擴展正則對比表
- 總結
- 🎯 核心價值
- 📊 體系結構
- ? 四大核心能力
- 🛠? 實戰應用
前言
你是否曾在成百上千行的日志文件中尋找某個關鍵錯誤信息,卻像大海撈針一樣無從下手?是否曾需要從雜亂的文本中快速提取電話號碼、郵箱地址或特定格式的數據,卻不得不手動逐行篩選?別擔心,正則表達式正是為你解決這些問題而生的“文本處理瑞士軍刀”。它就像是一套神奇的密碼,掌握了它,你就能讓計算機自動理解你想要的文本模式,無論是篩選日志、解析數據還是批量處理文檔,都將變得輕松高效。本章將帶你從零開始,解鎖這項讓無數程序員和系統管理員受益終身的強大技能。
一、正則表達式概述
1.1 定義
正則表達式(Regular Expression,常縮寫為 regex/regexp/RE)是一種用于描述字符串模式的規則。它能夠高效地進行檢索、替換和過濾符合特定規則的字符串。
1.2 主要用途
- 系統日志篩選(如定位“登錄失敗”“服務啟動失敗”等關鍵信息)
- 配置文件解析與提取
- 文本查找與替換
- 腳本編程中的條件匹配與驗證
1.3 Linux 中的正則表達式分類
| 類型 | 名稱 | 特點 | 需轉義字符 | 常用工具 |
|---|---|---|---|---|
| BRE | 基礎正則表達式 | 功能有限,傳統語法 | \{n\}, \+, \?, \(\), | | grep, sed |
| ERE | 擴展正則表達式 | 功能強大,語法簡潔 | 無需轉義 | grep -E, egrep, awk |
1.3.1 基礎正則表達式(BRE)
- 語法較為傳統,功能相對有限
- 量詞如
{}需轉義為\{n,m\} +、?、()等符號也需要轉義- 常用工具:
grep、sed
1.3.2 擴展正則表達式(ERE)
- 功能更強大,語法更簡潔
+、?、()、{}、|等符號無需轉義- 常用工具:
egrep(或grep -E)、awk
二、正則表達式的基本組成
2.1 普通字符
包括字母、數字、標點符號等,匹配其本身。
2.2 元字符
2.2.1 基本元字符
.:匹配任意單個字符(除換行符\r\n)[]:匹配字符集合中的一個字符,如[abc]、[a-z]、[0-9A-Z][^]:匹配不在集合中的任意一個字符,如[^a-z]表示非小寫字母^:匹配行首$:匹配行尾\:轉義符,用于取消元字符的特殊含義
2.2.2 重復次數相關
*:匹配前一個字符 0 次或多次\+:匹配前一個字符至少 1 次(BRE 中需轉義)\{n\}:匹配前一個字符恰好 n 次\{n,m\}:匹配前一個字符 n 到 m 次\{n,\}:匹配前一個字符至少 n 次
2.2.3 擴展正則中的元字符(ERE)
+:匹配前一個字符至少 1 次(無需轉義)?:匹配前一個字符 0 次或 1 次|:表示“或”關系,匹配多個模式之一():用于分組,可對一組字符進行重復或選擇()+:匹配重復的組
2.2.4 egrep的用法
egrep 是 Unix/Linux 系統中的一個文本搜索工具,屬于 GNU grep 的擴展版本(grep -E 的別名)。它支持擴展正則表達式(Extended Regular Expressions, ERE),比基礎正則表達式(BRE)提供更靈活的語法,例如直接使用 +、?、| 等元字符而無需轉義。
基本量詞語法
egrep和awk使用{n}、{n,}、{n,m}進行匹配時,{}前無需加轉義符\- 示例:
egrep -E -n 'wo{2}d' demo # 匹配"wood" egrep -E -n 'wo{2,3}d' demo # 匹配"wood"或"woood"
常用量詞操作符
-
+重復一個或多個前導字符- 示例:
egrep -n 'wo+d' demo匹配"wood"、“woood”、"woooooood"等字符串
- 示例:
-
?零個或一個前導字符- 示例:
egrep -n 'bes?t' demo匹配"bet"和"best"
- 示例:
-
|或操作(匹配多個模式)- 示例:
egrep -n 'of|is|on' demo匹配"of"、“if"或"on”
- 示例:
-
()分組匹配- 示例:
egrep -n 't(a|e)st' demo
匹配"tast"和"test",利用分組將共有的"t"和"st"提取,僅將差異部分"a|e"放入組內
- 示例:
-
()+重復分組匹配- 示例:
egrep -n 'A(xyz)+C' demo
匹配以"A"開頭、"C"結尾,中間包含一個或多個"xyz"的字符串
- 示例:
三、grep 工具的使用
3.1 常用選項
| 選項 | 功能說明 | 使用示例 |
|---|---|---|
-E | 啟用擴展正則表達式 | grep -E 'wo{2}d' file |
-c | 統計匹配行數 | grep -c root /etc/passwd |
-i | 忽略大小寫 | grep -i "the" file |
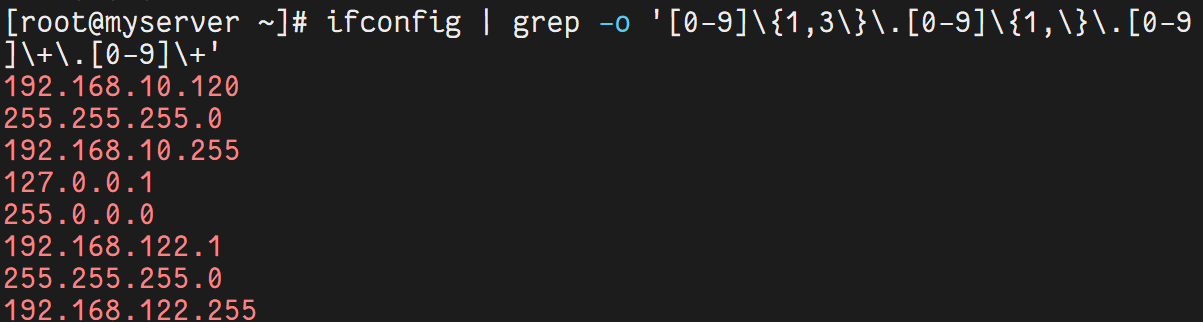
-o | 只輸出匹配內容 | grep -o '[0-9]\+' file |
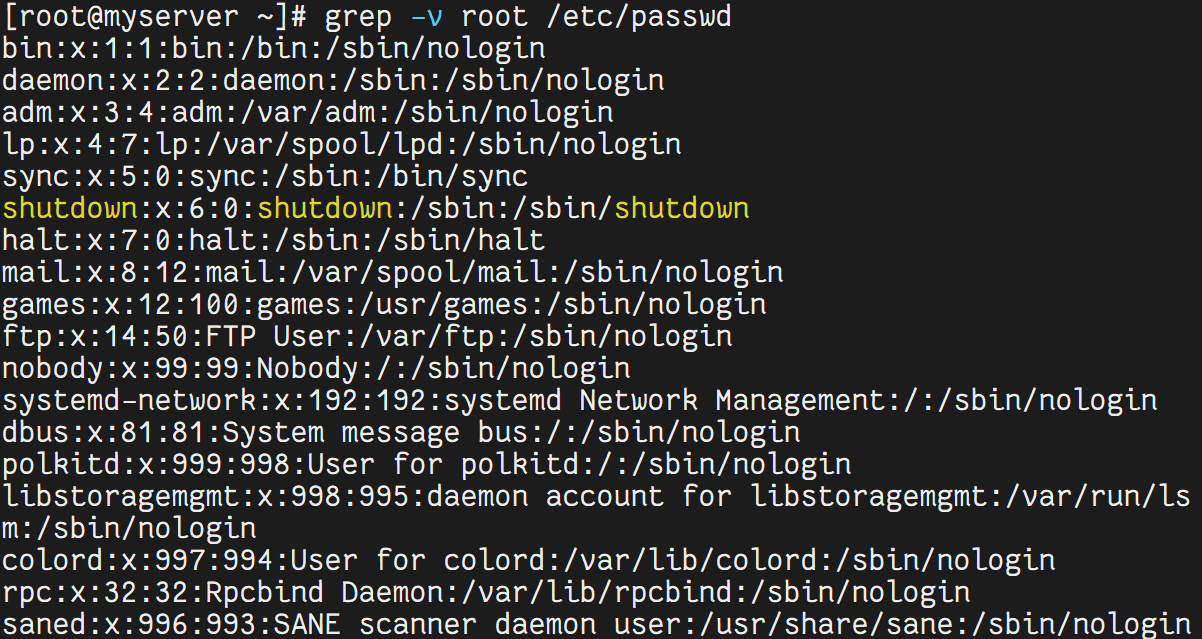
-v | 反向匹配(排除) | grep -v root /etc/passwd |
-n | 顯示行號 | grep -n pattern file |
--color=auto | 高亮顯示匹配內容 | grep --color=auto pattern file |
3.2 使用示例
grep -c root /etc/passwd # 統計包含 root 的行數
grep -i "the" web.sh # 忽略大小寫匹配 the
grep -v root /etc/passwd # 輸出不包含 root 的行
ipconfig | grep -o '[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+' | head -1 # 提取 IP 地址
-c

-i

-v
-o
四、正則表達式操作案例
| 元字符 | 功能說明 | 示例 | 匹配結果 |
|---|---|---|---|
. | 匹配任意單個字符(除\r\n) | w..d | wood, word, w00d |
[ ] | 匹配字符集合中的任意一個字符 | sh[io]rt | shirt, short |
[^ ] | 匹配不在集合中的任意一個字符 | [^w]oo | foo, boo(排除woo) |
^ | 匹配行首位置 | ^the | 以the開頭的行 |
$ | 匹配行尾位置 | \.$ | 以.結尾的行 |
\ | 轉義特殊字符 | a\.b | a.b(而不是ajb等) |
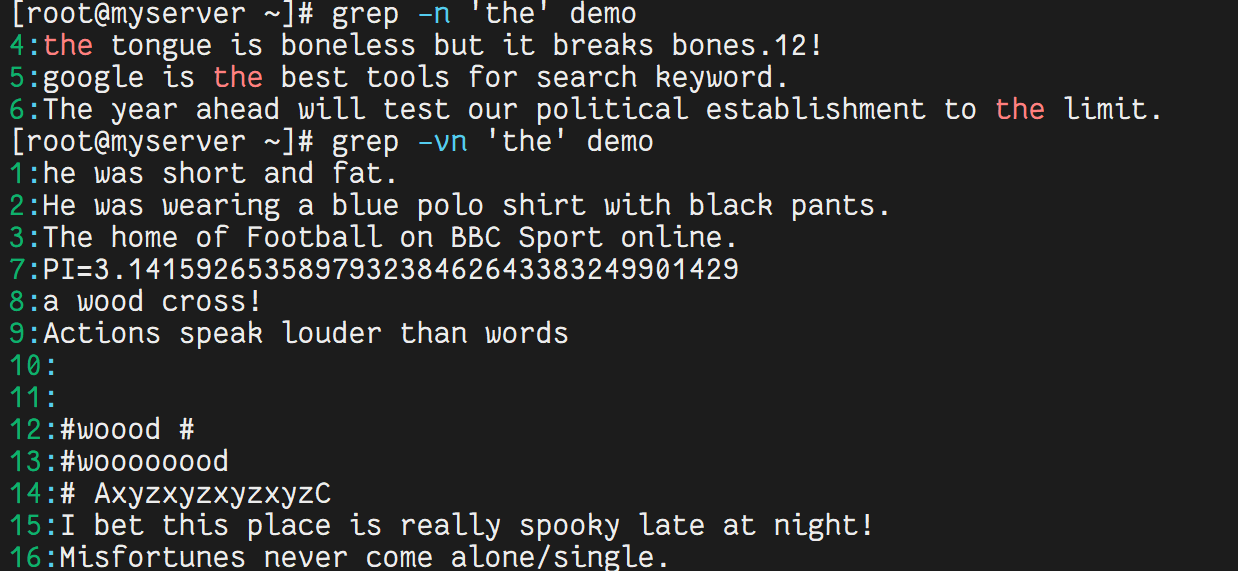
4.1 查找特定字符
grep -n 'the' demo # 查找包含 the 的行
grep -vn 'the' demo # 查找不包含 the 的行
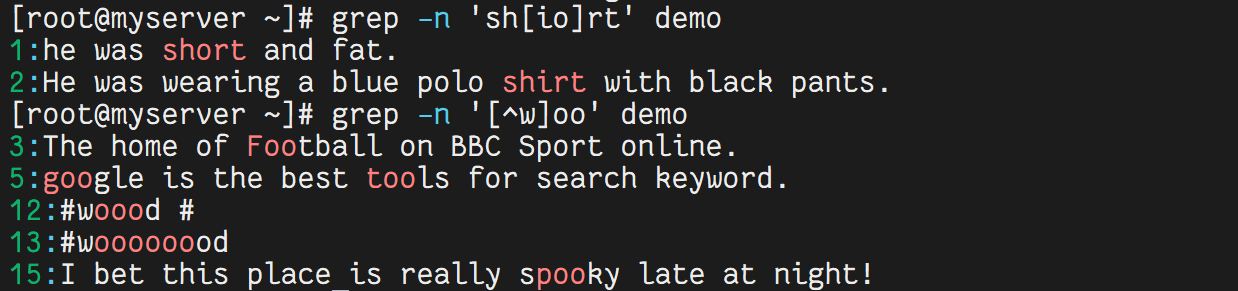
4.2 使用中括號集合
grep -n 'sh[io]rt' demo # 匹配 shirt 或 short
grep -n '[^w]oo' demo # 匹配開頭不是 w 且包含 oo 的行
4.3 使用定位符
grep -n '^the' demo # 匹配以 the 開頭的行
grep -n '\.$' demo # 匹配以 . 結尾的行
grep -n '^$' demo # 匹配空行
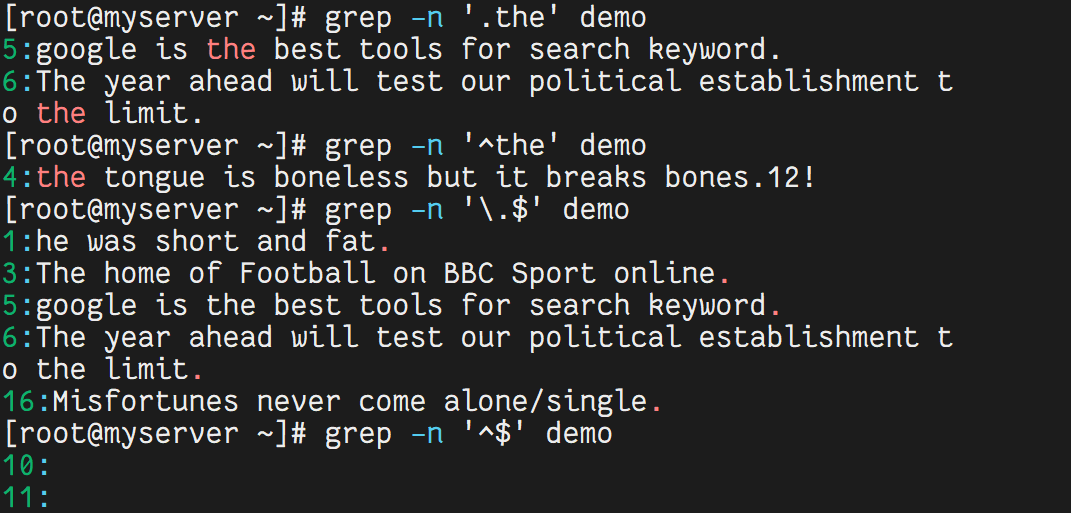
4.4 使用點與星號
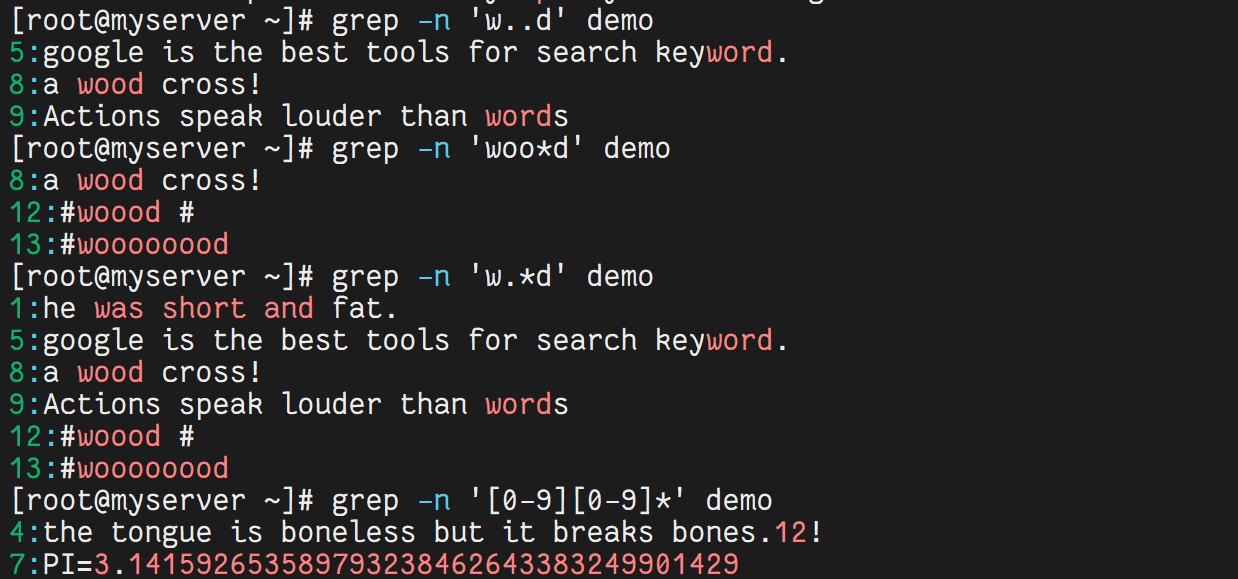
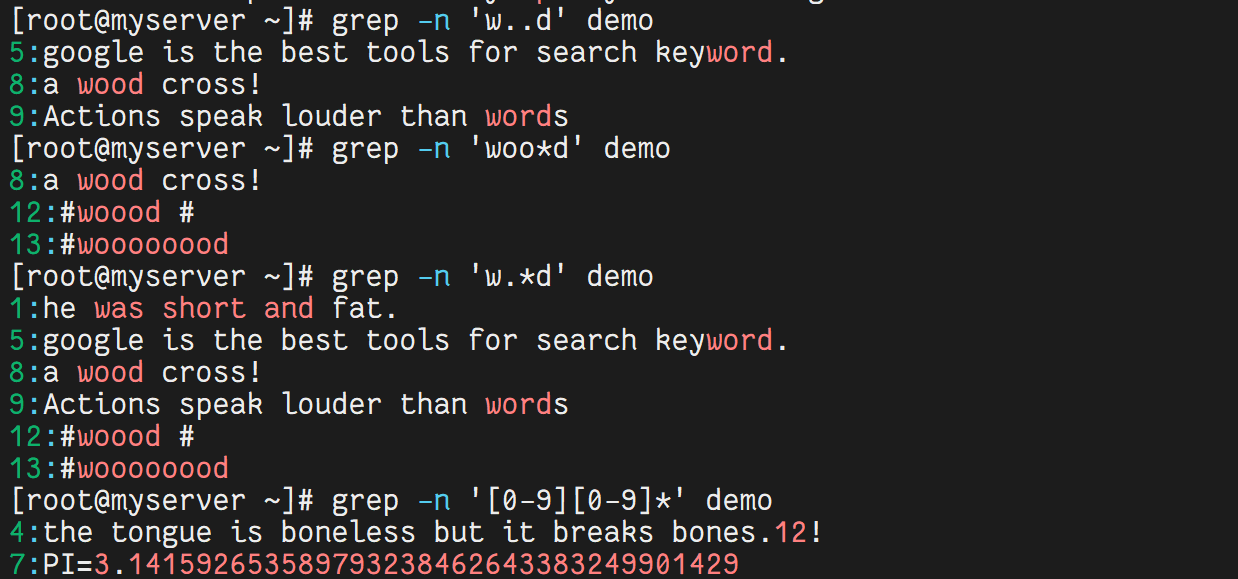
grep -n 'w..d' demo # 匹配 w 開頭、d 結尾,中間兩個任意字符
grep -n 'woo*d' demo # 匹配 w 開頭、d 結尾,中間有 0 個或多個 o
grep -n 'w.*d' demo # 匹配 w 開頭、d 結尾,中間任意多個字符
grep -n '[0-9][0-9]*' demo # 匹配任意數字
4.5 使用次數限定符
grep -n 'o\{2\}' demo # 匹配兩個連續的 o
grep -n 'wo\{2,5\}d' demo # 匹配 w 開頭、d 結尾,中間 2~5 個 o
grep -n 'wo\{2,\}d' demo # 匹配 w 開頭、d 結尾,中間至少 2 個 o
五、基礎正則與擴展正則對比表
| 量詞 | 功能說明 | BRE語法 | ERE語法 | 示例 |
|---|---|---|---|---|
* | 匹配0次或多次 | * | * | wo*d(wd, wod, wood) |
+ | 匹配1次或多次 | \+ | + | wo\+d(wod, wood) |
? | 匹配0次或1次 | \? | ? | bes?t(bet, best) |
{n} | 匹配恰好n次 | \{n\} | {n} | o\{2\}(oo) |
{n,} | 匹配至少n次 | \{n,\} | {n,} | o\{2,\}(oo, ooo, …) |
{n,m} | 匹配n到m次 | \{n,m\} | {n,m} | o\{2,5\}(oo, ooo, oooo, ooooo) |
總結
🎯 核心價值
正則表達式是文本處理的瑞士軍刀,通過模式匹配實現高效檢索、替換和過濾,極大提升數據處理效率。
📊 體系結構
兩大體系并行:
- BRE(基礎正則):傳統嚴謹,需轉義特殊字符
- ERE(擴展正則):現代簡潔,直接使用元字符
? 四大核心能力
- 精準定位 - 用
^$鎖定行首行尾 - 字符控制 - 用
[ ][^ ]精確字符范圍 - 數量調控 - 用
*+?{}控制出現次數 - 邏輯組合 - 用
|()實現復雜邏輯匹配
🛠? 實戰應用
和grep 、awk、sed等結合使用,可以處理99%的文檔
- 日志分析:快速定位錯誤信息
grep -n "error" logfile - 數據提取:匹配特定格式
grep -o '[0-9]\{3\}-[0-9]\{2\}-[0-9]\{4\}' - 文本清洗:過濾空行
grep -v '^$' file - 模式驗證:檢查格式合法性
grep -E '^[A-Za-z0-9]+@[A-Za-z0-9]+\.[a-z]{2,}$'








的8種典型情況及解決方案)
)









——畫線功能Linerenderer、范圍檢測、射線檢測)