基于muduo庫的圖床云共享存儲項目(一)
- 項目簡介
- 整體架構
- 項目依賴基礎組件
- muduo庫
- Channel類
- Poller / EpollPoller 類
- EventLoop
- Acceptor類
- FastDfs
- JSON的使用
項目簡介
當前所實現的項目是一個基于muduo庫的圖床云共享存儲項目,他的主要的功能就是我們可以注冊對應的賬號,然后登錄到系統當中,然后進行各類文件的上傳操作,同時,我們也可以將對用的文件進行共享,包括對應的一個下載熱榜,下面就是該項目的部分功能截圖: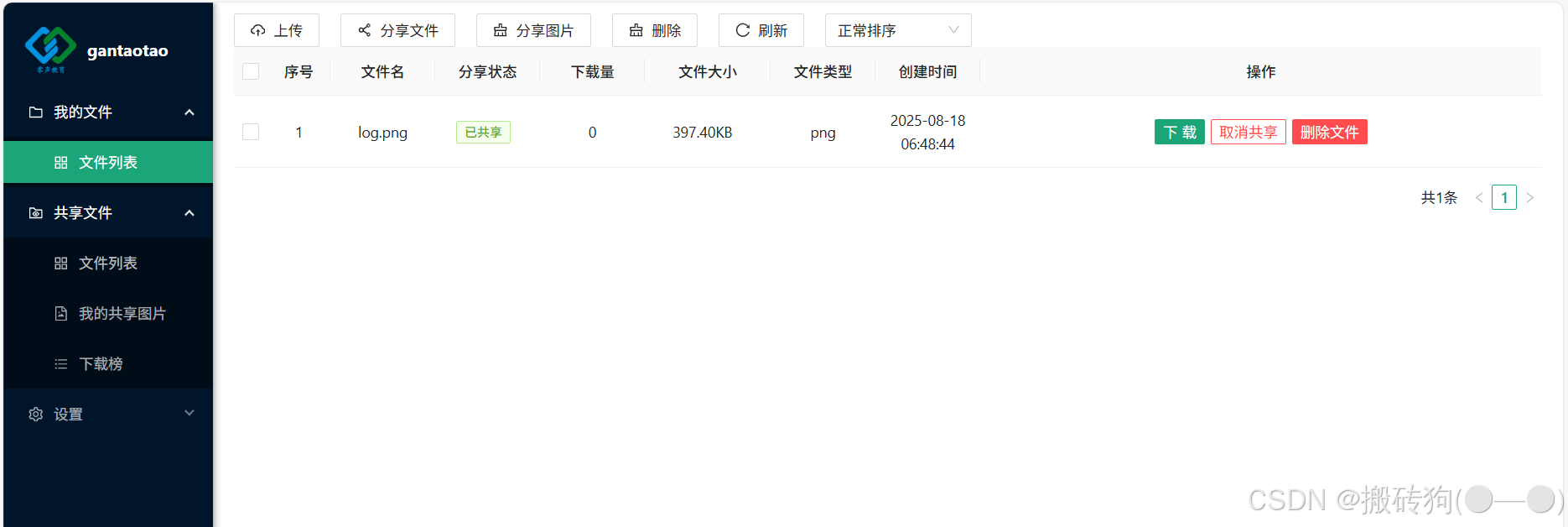
當然,當前項目我們實現是 C++ 后端部分,前端部分就不會涉及到,對于當前項目涉及到一些知識點就如下:Redis,MySQL,線程池,reactor網絡模型,http協議,fastfds等等諸多的知識點聯系在一起。
整體架構
該項目的整體架構如下圖所示,簡單理解就是客戶端發起一個 HTTP 請求以后(比如注冊,上傳文件等),通過 nginx 代理將請求發送到我們的服務端,服務端就會對請求進行處理,報錯請求的解析,任務處理(將數據保存到 MySQL ,Redis,FastDfs),然后將處理結果進行回發,最終我們對上傳的文件進行下載同樣是通過 nginx 代理進行下載的。
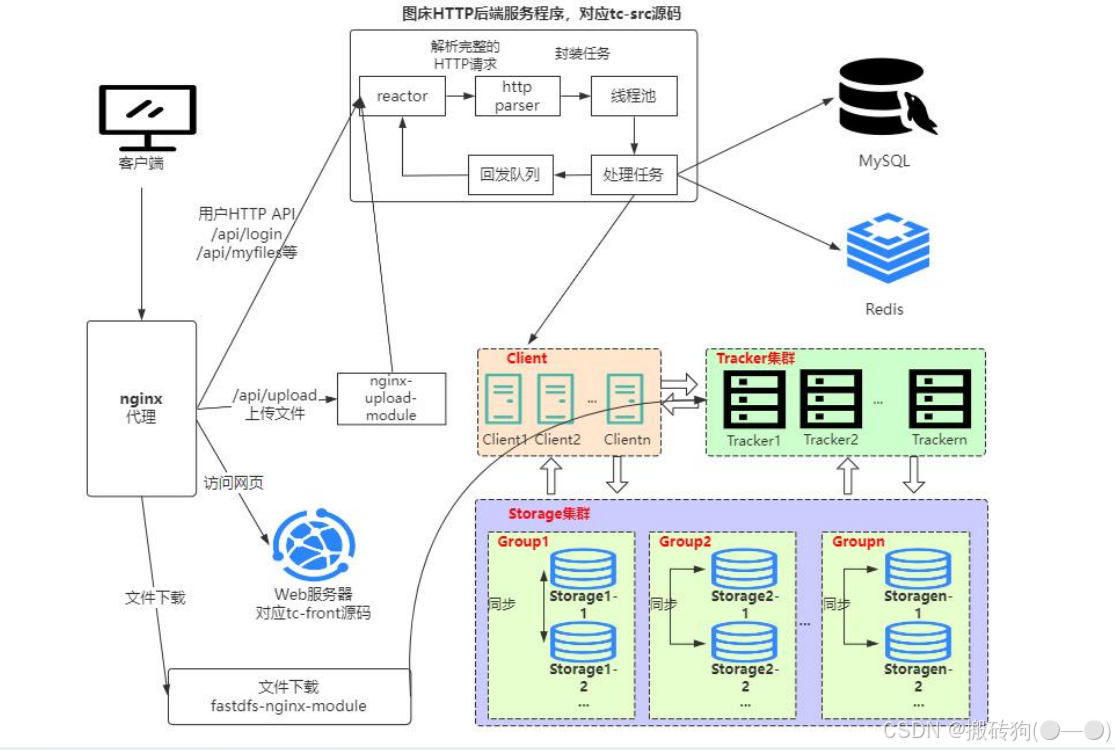
項目依賴基礎組件
了解項目的整體架構以后,接下我們就引入幾個新的知識點,也是我們項目所依賴的東西
muduo庫
Muduo網絡庫:底層實質上為Linux的epoll + pthread線程池,且依賴boost庫。 muduo的網絡設計核心為一個線程一個事件循環,有一個main Reactor負載accept連接,然后把連接分發到某個sub Reactor(采用輪詢的方式來選擇sub Reactor),該連接的所用操作都在那個sub Reactor所處的線程中完成。多個連接可能被分派到多個線程中,以充分利用CPU,Reactor poll的大小是固定的,根據CPU的數目確定。如果有過多的耗費CPU I/O的計算任務,可以提交到創建的ThreadPool線程池中專門處理耗時的計算任務。
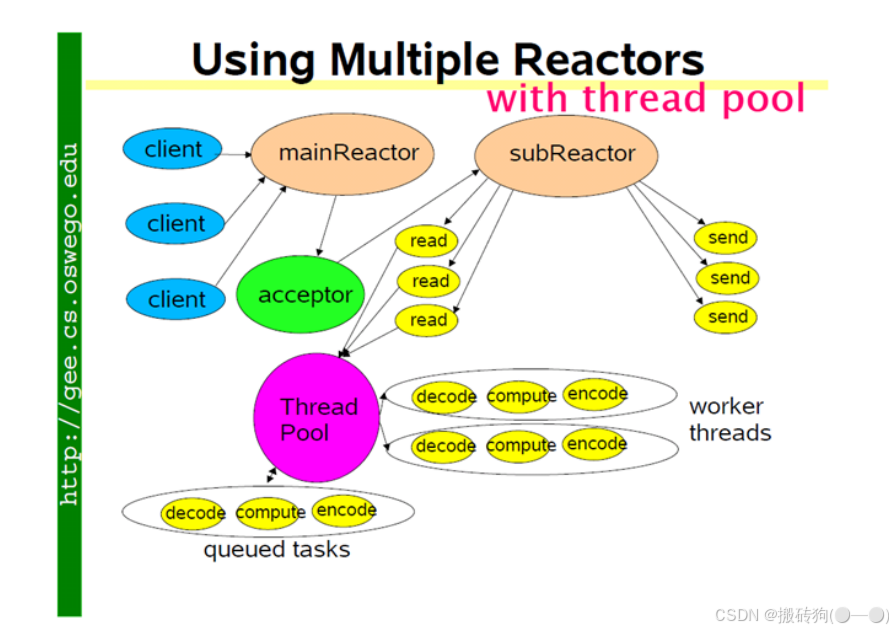
他的核心原理就在于:
- mainRecator 負責監聽所有連接請求,并且將這些連接均勻的分配給 subReactor ,后續新連接的 read ,write 事件由 subReactor 進行處理;
- subReactor 可以有多個,每一個 subReactor 會為其分配一個線程;
- ThreadPool 并不是針對某一個 subReactor ,而是針對于所有的 subReactor ,這兒需要注意的是,每一個 fd 對應的接收和發送數據以及最后的關閉,他其實都是在自己的 subReactor 中去實現的,并不會跳進別的 subReactor 中去;
- 讀取到數據以后,可以將數據封裝成一個任務,然后交給線程池進行處理,而且讀取數據以后,也并不是直接調用 send 函數進行發送,而是先將數據存入到緩沖區當中去,最終封裝成任務交給線程池進行處理。
Channel類
Channel類是指在Muduo庫中負責管理文件描述符(FD)及其事件處理的類。它相當于文件描述符的“保姆”,負責監聽文件描述符上的事件,并調用相應的處理函數來響應這些事件,他主要就是實現以下的四個功能:
- 監聽文件描述符:Channel類跟蹤文件描述符的狀態,包括讀寫事件、連接事件等。
- 事件處理:當文件描述符上發生事件時,Channel類會調用預先注冊的事件處理函數來處理這些事件。
- 封裝接口:Channel類提供了統一的接口來處理各種事件,使得開發者可以更方便地管理文件描述符及其事件。
- 狀態管理:Channel類管理文件描述符的就緒狀態,確保在事件發生時能夠及時響應。
重要的成員變量
- int fd_:Channel對象照看的文件描述符;
- int events_:代表fd感興趣的事件類型集合;
- int revents_:代表事件監聽器實際監聽到該fd發生的事件類型集合,當事件監聽器監聽到一個fd發生了什么事件,通過Channel::set_revents()函數來設置revents值;
- EventLoop* loop:fd屬于哪個EventLoop對象;
- read_callback_ 、write_callback_、close_callback_、error_callback_:這些是std::function類型,代表著這個Channel為這個文件描述符保存的各事件類型發生時的處理函數。
重要的成員方法
- 向Channel對象注冊各類事件的處理函數
void setReadCallback(ReadEventCallback cb) { readCallback_ = std::move(cb); }void setWriteCallback(EventCallback cb) { writeCallback_ = std::move(cb); }void setCloseCallback(EventCallback cb) { closeCallback_ = std::move(cb); }void setErrorCallback(EventCallback cb) { errorCallback_ = std::move(cb); }
- 將Channel中的文件描述符及其感興趣事件注冊事件監聽器上或從事件監聽器上移除
void enableReading() { events_ |= kReadEvent; update(); }void disableReading() { events_ &= ~kReadEvent; update(); }void enableWriting() { events_ |= kWriteEvent; update(); }void disableWriting() { events_ &= ~kWriteEvent; update(); }void disableAll() { events_ = kNoneEvent; update(); }
Poller / EpollPoller 類
負責監聽文件描述符事件是否觸發以及返回發生事件的文件描述符以及具體事件的模塊就是Poller,Poller是個抽象虛類,由EpollPoller和PollPoller繼承實現,與監聽文件描述符和返回監聽結果的具體方法也基本上是在這兩個派生類中實現。EpollPoller就是封裝了用epoll方法實現的與事件監聽有關的各種方法,PollPoller就是封裝了poll方法實現的與事件監聽有關的各種方法。
重要成員變量
- int epollfd_:epoll_create方法返回的epoll句柄;
- ChannelMap channels_:負責記錄文件描述符
--->Channel的映射; - EventLoop* ownerLoop_:所屬的EventLoop對象。
對外部提供的最重要的方法
TimeStamp poll(int timeoutMs, ChannelList *activeChannels)
poll 函數是 Poller 的核心,外界調用 poll 函數,其實就是獲取 epoll_wait 這個事件監聽器上發生事件的fd及其對應發生的事件,每個 fd 都是由一個 Channel 封裝的,通過哈希表 channels_ 可以根據fd找到封裝這個 fd 的 Channel ,將事件監聽器監聽到該 fd 發生的事件寫進這個 Channel 中的 revents 成員變量中。
然后把這個 Channel 裝進 activeChannels 中,這樣,當外界調用完poll之后就能拿到事件監聽器的監聽結果(activeChannels_),這個 activeChannels 就是事件監聽器監聽到的發生事件的 fd ,以及每個 fd 都發生了什么事件。
EventLoop
作為一個網絡服務器,需要有持續監聽、持續獲取監聽結果、持續處理監聽結果對應的事件的能力,也就是我們需要循環的去調用Poller:poll方法獲取實際發生事件的Channel集合,然后調用這些Channel里面保管的不同類型事件的處理函數。
EventLoop就是負責實現“循環”,Channel和Poller其實相當于EventLoop的手下,EventLoop整合封裝了二者并向上提供了更方便的接口來使用,下面就是核心代碼:
void EventLoop::loop(const int timeoutMs)
{assert(!looping_);assertInLoopThread();looping_ = true;quit_ = false; // FIXME: what if someone calls quit() before loop() ?LOG_TRACE << "EventLoop " << this << " start looping";while (!quit_){activeChannels_.clear();pollReturnTime_ = poller_->poll(timeoutMs, &activeChannels_);++iteration_;if (Logger::logLevel() <= Logger::TRACE){printActiveChannels();}// TODO sort channel by priorityeventHandling_ = true;for (Channel* channel : activeChannels_){currentActiveChannel_ = channel;currentActiveChannel_->handleEvent(pollReturnTime_);}currentActiveChannel_ = NULL;eventHandling_ = false;doPendingFunctors();}LOG_TRACE << "EventLoop " << this << " stop looping";looping_ = false;
}
EventLoop起到一個驅動循環的功能,Poller負責從事件監聽器上獲取監聽結果。而Channel類則在其中起到了將fd及其相關屬性封裝的作用,將fd及其感興趣事件和發生的事件以及不同事件對應的回調函數封裝在一起,這樣在各個模塊中傳遞更加方便。
EventLoop的主要功能就是持續循環的獲取監聽結果并且根據結果調用處理函數。
Acceptor類
Acceptor 就是接受新用戶連接并分發連接給SubReactor,Accetpor 封裝了服務器監聽套接字fd以及相關處理方法。
重要成員變量
- acceptSocket_:服務器監聽套接字的文件描述符;
- acceptChannel_:把acceptSocket_及其感興趣事件和事件對應的處理函數都封裝進去;
- EventLoop *loop:監聽套接字的fd由哪個EventLoop負責循環監聽以及處理相應事件,其實這個EventLoop就是main EventLoop;
- newConnectionCallback_:TcpServer構造函數中將TcpServer::newConnection( )函數注冊給了這個成員變量。這個TcpServer::newConnection函數的功能是公平的選擇一個subEventLoop,并把已經接受的連接分發給這個subEventLoop。
重要成員方法
- listen():開啟對acceptSocket_的監聽同時將acceptChannel及其感興趣事件(可讀事件)注冊到main EventLoop的事件監聽器上;
- handleRead():要注冊到acceptChannel_上的, 同時handleRead( )方法內部還調用了成員變量newConnectionCallback_保存的函數。當main EventLoop監聽到acceptChannel_上發生了可讀事件時(新用戶連接事件),就是調用這個handleRead( )方法。它最終實現的功能是什么,接受新連接,并且以負載均衡的選擇方式選擇一個sub EventLoop,并把這個新連接分發到這個subEventLoop上。
FastDfs
FastDFS 是一個開源的分布式文件系統,它旨在提供高性能、高可靠性和可擴展性的文件存儲解決方案,解決海量數據存儲問題。其主要的功能包括:文件存儲,同步和訪問。特別適合以中小文件(建議范圍:4KB < file_size <500MB)為載體的在線服務,如圖片分享和視頻分享網站。
比如說有一個大型的網站,用戶可以上傳和下載大量的圖片和視頻文件。如果這些文件都存儲在單個服務器上,可能會導致服務器負載過高、存儲空間不足以及訪問速度慢等問題。這時就需要將這些文件分布式地存儲在多臺服務器上,以提高整個系統的性能和可靠性。FastDFS 就是為了解決這個問題而設計的,它可以將大文件切分成小塊,并將這些小塊分散存儲在多個服務器上,實現文件的分布式存儲。
FastDFS由跟蹤服務器(tracker server)、存儲服務器(storage server)和客戶端(client)三部分組成,架構如下圖所示:
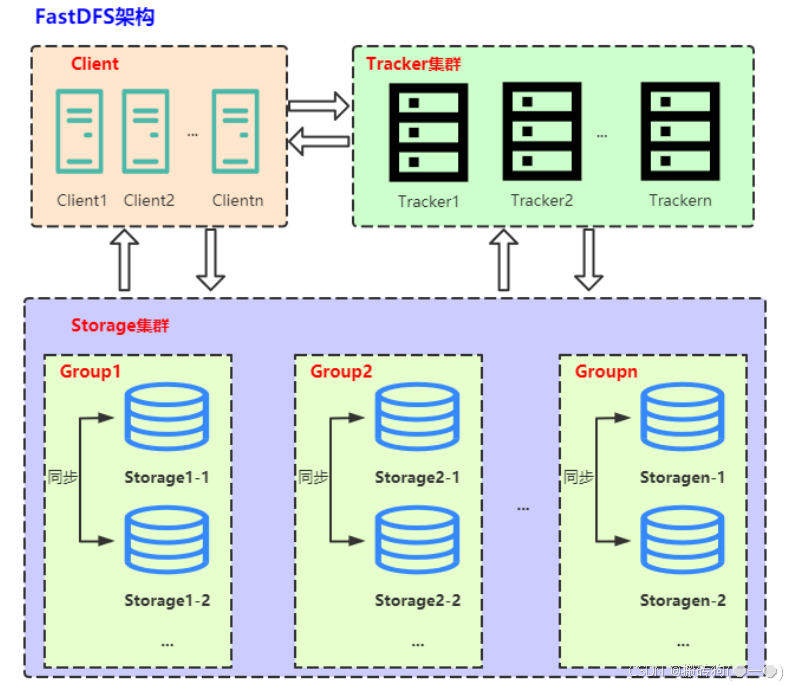
跟蹤服務器(tracker server)
Tracker是FastDFS的協調者,負責管理所有的storage server和group,每個storage在啟動后會連接Tracker,告知自己所屬的group等信息,并保持周期性的心跳,tracker根據storage的心跳信息,建立group==>[storage server list]的映射表。
client 訪問 storage server 之前,必須先訪問 tracker server,動態獲取到 storage server 的連接信息,最終數據是和一個可用的 storage server 進行傳輸。
存儲服務器(storage server)
Storage server以組(卷,group或volume)為單位組織,一個group內包含多臺storage機器,數據互為備份。存儲空間以group內容量最小的storage為準。
以group為單位組織存儲能方便的進行應用隔離、負載均衡、副本數定制,將不同應用數據存到不同的group就能隔離應用數據,根據應用的訪問特性來將應用分配到不同的group來做負載均衡。
缺點是group的容量受單機存儲容量的限制,同時當group內有機器壞掉時,數據恢復只能依賴group內地其他機器,使得恢復時間會很長。
group內每個storage的存儲依賴于本地文件系統,storage可配置多個數據存儲目錄,比如有10塊磁盤,分別掛載在/data/disk1 到 /data/disk10,則可將這10個目錄都配置為storage的數據存儲目錄。
storage接受到寫文件請求時,會根據配置好的規則,選擇其中一個存儲目錄來存儲文件。為了避免單個目錄下的文件數太多,在storage第一次啟動時,會在每個數據存儲目錄里創建2級子目錄,每級256個,總共65536個文件,新寫的文件會以hash的方式被路由到其中某個子目錄下,然后將文件數據直接作為一個本地文件存儲到該目錄中。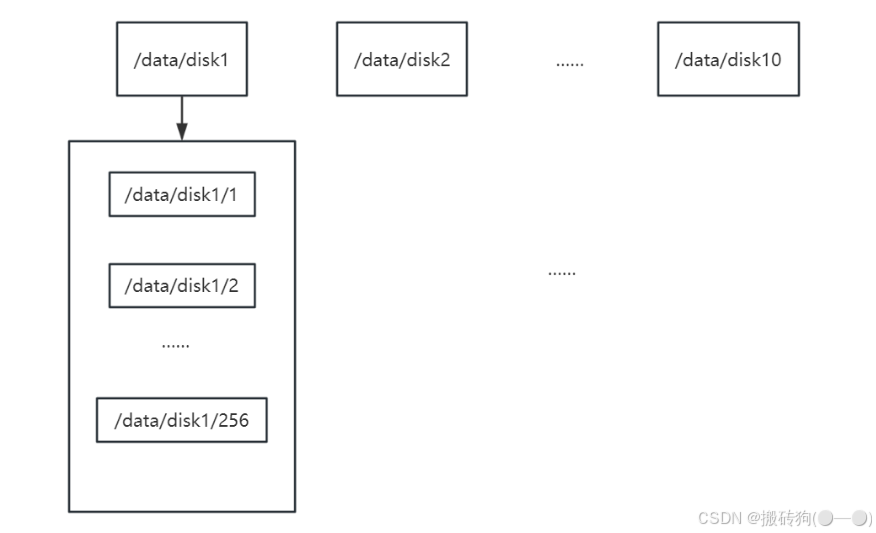
client
FastDFS向使用者提供基本文件訪問接口,比如monitor、upload、download、append、delete等,以客戶端庫的方式提供給用戶使用。
JSON的使用
在當前項目當中還涉及到了 json 的序列化以及反序列化,json 其實就屬于一種獨立的數據交換格式,通常是以明文字符串的形式進行組織,在網絡通信中我們也是會經常用到,其實就是以鍵值對的形式進行進行組織,如下所示對于學生信息的組織:
{"name":"張三","age":18,"grades":[88.8, 88.9, 90.1]
}
因為對于不同主機服務器來說,對應的數據格式以及處理規則可能是不一樣的,我們就需要通過這種序列化與反序列化的方式來對于不同的主機之間進行數據格式的轉換操作。
我們通常進行使用的就是 Value 類,Reader 類以及 Writer 類:
Value類
Value 類通常是用于中間數據的存儲,多個字段的數據要進行序列化,就必須先將數據存儲在 Value 對象中,而且如果要將一個 json 對象進行解析,也需要將解析結果存放在 Value 對象中,通常 Value 類中用到的比較多的接口就是下面的接口:
Value& operator=(Value other);
Value& operator[(const char* key; // Value["name"] = "張三"
Value& append(const Value& value); // 數據組的新增,Value["grades"].append(88)
std::string asString() const; // Value["name"].asSring();
ArrayIndex size() const; // 獲取數組元素個數
Value& operator[](ArrayIndex index); // 通過數組下標獲取數組元素
Writer類
Writer類 主要就是提供序列化的操作的一些接口:
class JSON_API StreamWriter {
protected:JSONCPP_OSTREAM* sout_; // not owned; will not delete
public:StreamWriter();virtual ~StreamWriter();virtual int write(Value const& root, JSONCPP_OSTREAM* sout) = 0;
}class JSON_API StreamWriterBuilder : public StreamWriter::Factory {
public:Json::Value settings_;StreamWriterBuilder();~StreamWriterBuilder() JSONCPP_OVERRIDE;StreamWriter* newStreamWriter() const JSONCPP_OVERRIDE;
}
主要是通過工廠模式去創建 StreamWriter 對象然后在進行接口的調用。
Reader類
class JSON_API CharReader {
public:virtual ~CharReader() {}virtual bool parse(char const* beginDoc, char const* endDoc, Value* root, JSONCPP_STRING* errs) = 0;
}class JSON_API CharReaderBuilder : public CharReader::Factory {
public:Json::Value settings_;CharReaderBuilder();~CharReaderBuilder() JSONCPP_OVERRIDE;CharReader* newCharReader() const JSONCPP_OVERRIDE;
}
通常也是工廠模式,創建一個 CharReader 對象以后然后調用 parse 方法進行反序列化。
以上就是當前項目的一個簡介,后續項目的具體實現也會逐步進行更新。


深入了解AVFoundation-編輯:視頻變速功能-實戰在Demo中實現視頻變速)
|實戰指南:構建論文分析智能體)








)
什么是 MCP?如何使用 Charry Studio 集成 MCP?)



以及行數復用)
- Mediatek KMS實現mtk_drm_drv.c(Part.1))
