文章目錄
- 心臟病預測
- 導入數據集
- 數據集介紹
- 理解數據
- 數據處理
- 機器學習
- K近鄰分類器
- 邏輯回歸
- 支持向量分類器(SVC)
- 決策樹分類器
- 隨機森林分類器
- 結論
心臟病預測
在這個機器學習項目中,我們使用UCI心臟病數據集 UCI ,并將使用機器學習方法預測一個人是否患有心臟病。
import numpy as np # 導入NumPy庫,用于支持大型、多維數組與矩陣運算,常用于數學計算
import pandas as pd # 導入Pandas庫,用于數據讀取、處理與分析(如DataFrame結構)
import matplotlib.pyplot as plt # 導入matplotlib中的pyplot模塊,用于繪圖和數據可視化
from matplotlib import rcParams # 導入rcParams用于設置matplotlib圖像的默認樣式(如字體、大小等)
from matplotlib.cm import rainbow # 從matplotlib的colormap模塊導入rainbow顏色映射,用于給圖像添加彩虹色彩
# %matplotlib inline # Jupyter Notebook專用魔法命令,使圖像內嵌顯示在Notebook中
import warnings # 導入warnings庫,用于控制警告信息的顯示
warnings.filterwarnings('ignore') # 忽略所有警告,避免在運行時輸出煩人的提示信息
為了處理數據,將導入一些庫。為了將可用的數據集劃分為訓練集和測試集,使用 train_test_split 方法。為了對特征進行標準化處理,使用 StandardScaler。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
接下來,我將導入所有將要使用的機器學習算法:
- K近鄰分類器(K Neighbors Classifier)
- 支持向量機分類器(Support Vector Classifier)
- 決策樹分類器(Decision Tree Classifier)
- 隨機森林分類器(Random Forest Classifier)
from sklearn.neighbors import KNeighborsClassifier # 從sklearn.neighbors模塊導入K近鄰分類器,用于基于距離進行分類
from sklearn.svm import SVC # 從sklearn.svm模塊導入支持向量機分類器,適合高維數據的分類任務
from sklearn.tree import DecisionTreeClassifier # 從sklearn.tree模塊導入決策樹分類器,用于構建樹結構進行決策
from sklearn.ensemble import RandomForestClassifier # 從sklearn.ensemble模塊導入隨機森林分類器,通過集成多棵決策樹提高準確率
導入數據集
現在我們已經導入了所有需要的庫,可以開始導入數據集并查看內容。數據集保存在文件 dataset.csv 中。我將使用 pandas 的 read_csv 方法來讀取該數據集。
dataset = pd.read_csv('dataset.csv')
數據集介紹
該數據集用于心臟病預測,包含患者的多個臨床和生理特征,及最終的心臟病診斷結果(target)。下面是每個字段的詳細說明:
| 字段名 | 含義 | 備注 |
|---|---|---|
age | 年齡 | 患者年齡(歲) |
sex | 性別 | 1表示男性,0表示女性 |
cp | 胸痛類型 | 0-3的分類,表示不同類型的胸痛 |
trestbps | 靜息血壓 | 靜息時的血壓(mm Hg) |
chol | 血清膽固醇 | 血液中的膽固醇含量(mg/dl) |
fbs | 空腹血糖 | 空腹血糖是否大于120 mg/dl(1表示是,0表示否) |
restecg | 靜息心電圖結果 | 0-2的分類,反映心電圖的不同類型結果 |
thalach | 最大心率 | 運動測試時達到的最大心率 |
exang | 運動誘發的心絞痛 | 1表示有,0表示無 |
oldpeak | 運動相較靜息的ST段壓低 | 表示心臟缺血的嚴重程度 |
slope | ST段抬高/壓低斜率 | 0-2的分類,表示運動時ST段的變化趨勢 |
ca | 主要血管數 | 0-3之間,血管造影檢測的主要血管數量 |
thal | 地中海貧血檢測結果 | 1、2、3表示不同類型 |
target | 心臟病診斷結果 | 1表示有心臟病,0表示無心臟病 |
總結:
此數據集包含了患者的年齡、性別、血壓、膽固醇、心電圖信息等多個變量,目標是預測患者是否患有心臟病。數據中既有數值型特征,也有分類特征,適合用機器學習分類算法進行建模。
數據集現在已經加載到變量 dataset 中。在正式開始處理和可視化之前,我會先用 describe() 和 info() 方法簡單查看一下數據的大致情況。
dataset.info()
# --------------<class 'pandas.core.frame.DataFrame'>
RangeIndex: 303 entries, 0 to 302
Data columns (total 14 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 age 303 non-null int64 1 sex 303 non-null int64 2 cp 303 non-null int64 3 trestbps 303 non-null int64 4 chol 303 non-null int64 5 fbs 303 non-null int64 6 restecg 303 non-null int64 7 thalach 303 non-null int64 8 exang 303 non-null int64 9 oldpeak 303 non-null float6410 slope 303 non-null int64 11 ca 303 non-null int64 12 thal 303 non-null int64 13 target 303 non-null int64
dtypes: float64(1), int64(13)
memory usage: 33.3 KB
看起來數據集總共有 303 行,并且沒有缺失值。數據集中共有 13 個特征,外加一個我們希望預測的目標值。
dataset.describe()

每個特征列的數值范圍不同,而且差別較大。例如,age(年齡)的最大值是 77,而 chol(血清膽固醇)的最大值則達到 564。
理解數據
現在,我們可以通過可視化來更好地理解數據,然后再考慮需要進行的處理操作。
import seaborn as sns # 導入seaborn庫,基于matplotlib的高級數據可視化工具,繪制美觀的統計圖表
import matplotlib.pyplot as plt # 導入matplotlib的pyplot模塊,用于繪圖和顯示圖像plt.figure(figsize=(20,14)) # 創建一個新的繪圖窗口,設置尺寸為寬20英寸,高14英寸
corr = dataset.corr() # 計算數據集中各特征之間的相關系數矩陣,返回一個DataFrame"""
viridis":漸變綠色調,視覺舒適。
"magma":暗色調漸變,風格現代。
"plasma":鮮艷明亮的漸變色。
"coolwarm":藍紅對比色,適合正負相關。
"cividis":色盲友好配色。
"rocket" 或 "mako":seaborn自帶的高級配色。
"""
sns.heatmap(corr, # 傳入相關系數矩陣作為熱力圖的數據來源annot=True, # 在熱力圖的每個方格內顯示對應的數值(相關系數)fmt=".2f", # 格式化數值,保留兩位小數cmap="viridis", # 使用“viridis”配色方案,顏色從藍綠到黃xticklabels=corr.columns, # 設置x軸刻度標簽為相關系數矩陣的列名(即特征名稱)yticklabels=corr.columns # 設置y軸刻度標簽為相關系數矩陣的列名(即特征名稱)
)
plt.show() # 顯示繪制的熱力圖窗口

從上面的相關矩陣可以看出,部分特征與目標值呈負相關,而有些特征則呈正相關。
接下來,將查看每個變量的直方圖。
# 繪制數據集中所有數值型特征的直方圖,幫助觀察各特征的分布情況和數據集中趨勢
import matplotlib.pyplot as pltplt.figure(figsize=(15,10)) # 設置畫布大小,寬15英寸,高10英寸
dataset.hist(figsize=(15,10)) # 也可以直接在hist里設置figsize
plt.tight_layout() # 自動調整子圖間距,避免重疊
plt.show()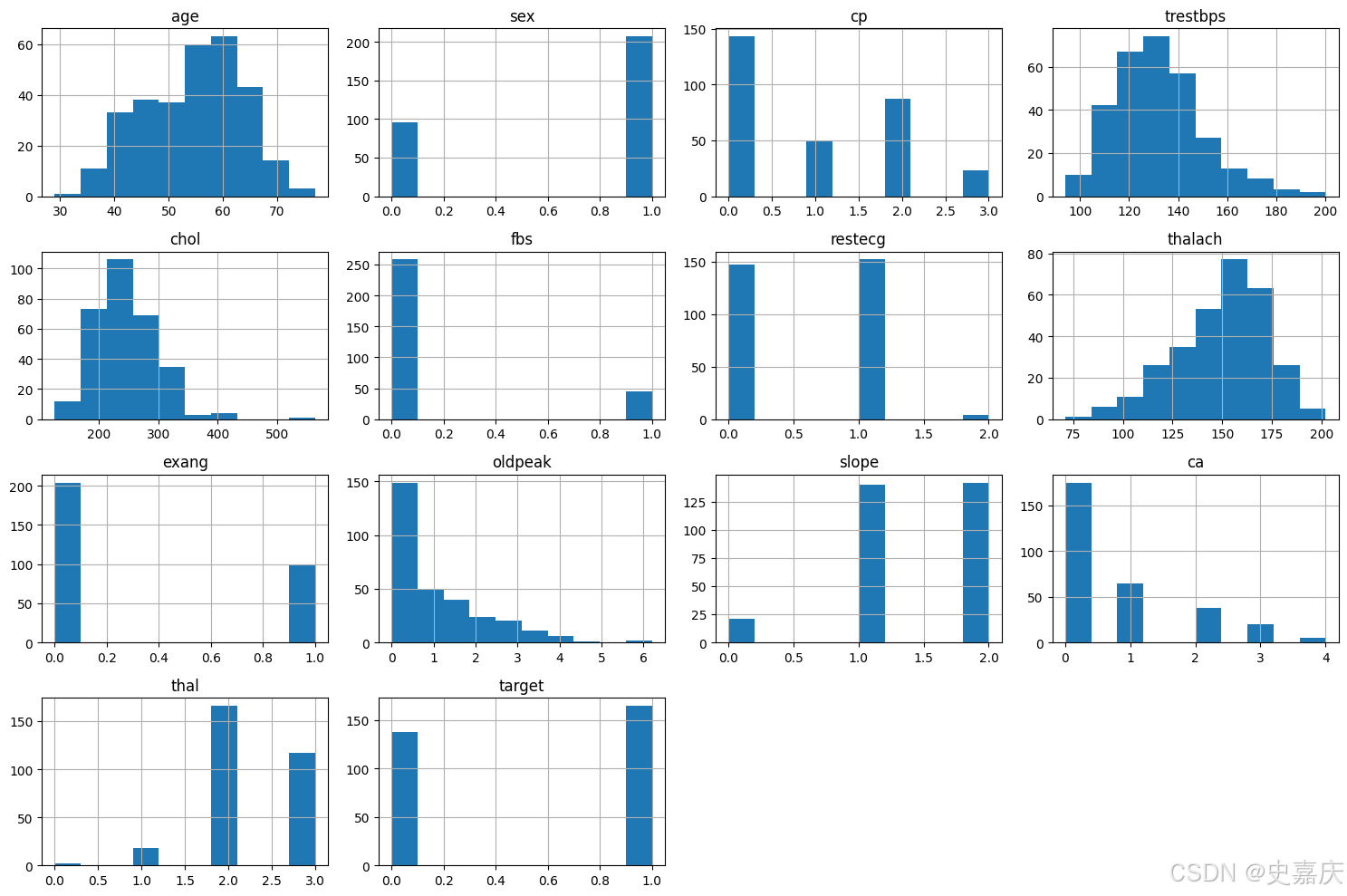
從上面的直方圖可以看出,每個特征的分布范圍都不同。因此,在進行預測之前進行特征縮放會很有幫助。此外,分類特征也非常明顯。
使用目標類別大致均衡的數據集是一個好的實踐。因此先檢查一下數據集中各類別的數量是否平衡。
rcParams['figure.figsize'] = 8, 6 # 設置繪圖窗口大小為寬8英寸,高6英寸
plt.bar( # 繪制柱狀圖dataset['target'].unique(), # x軸:目標類別的唯一值(如0和1)dataset['target'].value_counts(), # y軸:各類別對應的樣本數量color=['red', 'green'] # 柱子顏色,類別0為紅色,類別1為綠色
)
plt.xticks([0, 1]) # 設置x軸刻度為0和1,表示目標類別標簽
plt.xlabel('Target Classes') # x軸標簽為“目標類別”
plt.ylabel('Count') # y軸標簽為“數量”
plt.title('Count of each Target Class') # 圖表標題為“各目標類別的數量”
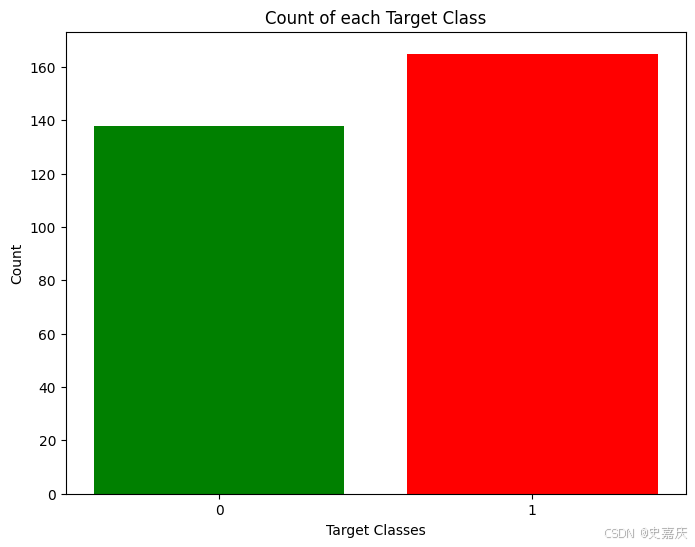
這兩個類別的比例雖然不完全是各占50%,但比例已經足夠合理,可以繼續使用當前數據,而無需刪除或增加樣本。
數據處理
在探索數據集后,發現需要將一些分類變量做編碼,并且在訓練機器學習模型之前對所有數值進行縮放。
首先,會使用 get_dummies 方法為分類變量進行one hot 編碼。在此之前,我們先回顧一下數據集。
dataset = pd.get_dummies(dataset, columns=['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal'],dtype=int)
# 使用 pandas 的 get_dummies 方法,將指定的分類變量列進行轉換
# columns 參數指定需要轉換的分類列,轉換后每個類別會變成單獨的二進制列(0或1)
# 這樣可以讓機器學習模型更好地處理分類數據
dataset
現在,將使用 sklearn 中的 StandardScaler 對數據集進行標準化處理。
standardScaler = StandardScaler()
# 創建 StandardScaler 對象,用于對數據進行標準化處理(均值為0,方差為1)columns_to_scale = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']
# 指定需要進行標準化的數值特征列dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
# 對指定列的數據進行標準化:先計算均值和標準差(fit),然后轉換數據(transform)
# 標準化后的數據替換原數據列
dataset
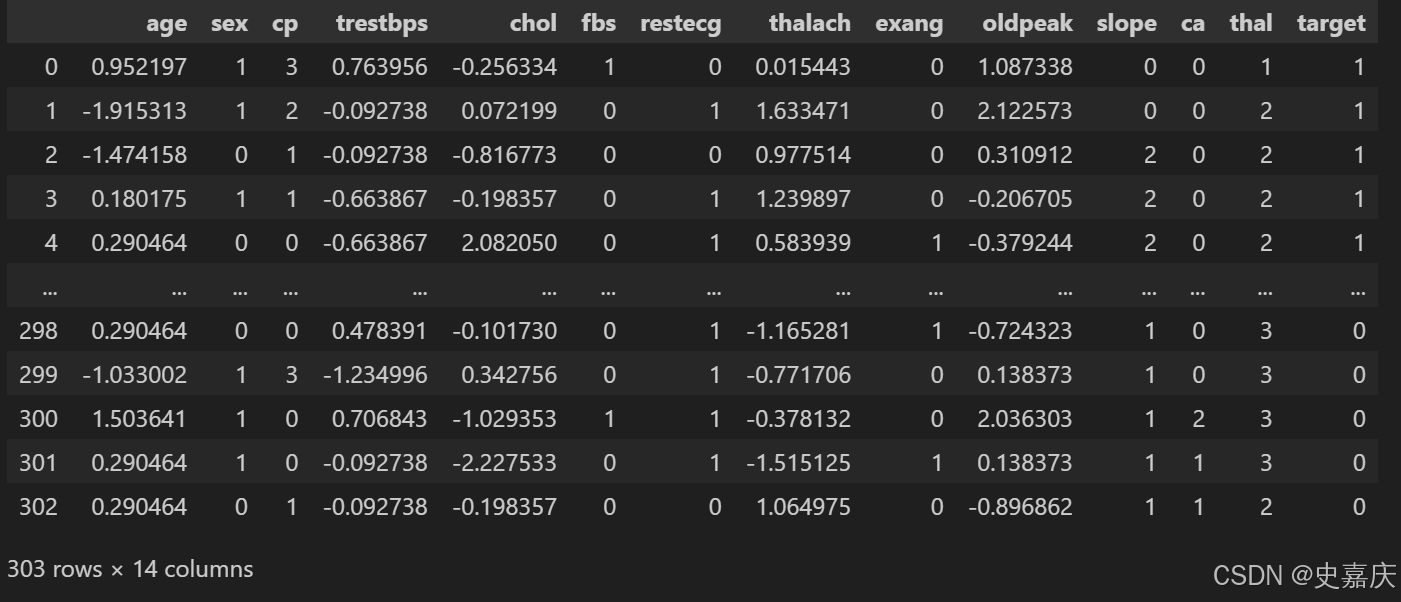
至此,數據已經準備好,可以用于我們的機器學習應用了。
機器學習
接下來,將導入 train_test_split,用來將數據集劃分為訓練集和測試集。然后會導入所有用于訓練和測試的機器學習模型。
y = dataset['target'] # 提取目標變量“target”,作為標簽y
X = dataset.drop(['target'], axis=1) # 從數據集中刪除“target”列,剩余特征作為輸入X# 使用train_test_split函數將數據集劃分為訓練集和測試集
# test_size=0.33表示33%的數據用作測試集,67%用作訓練集
# random_state=0保證分割的可重復性,即每次運行結果相同
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)K近鄰分類器
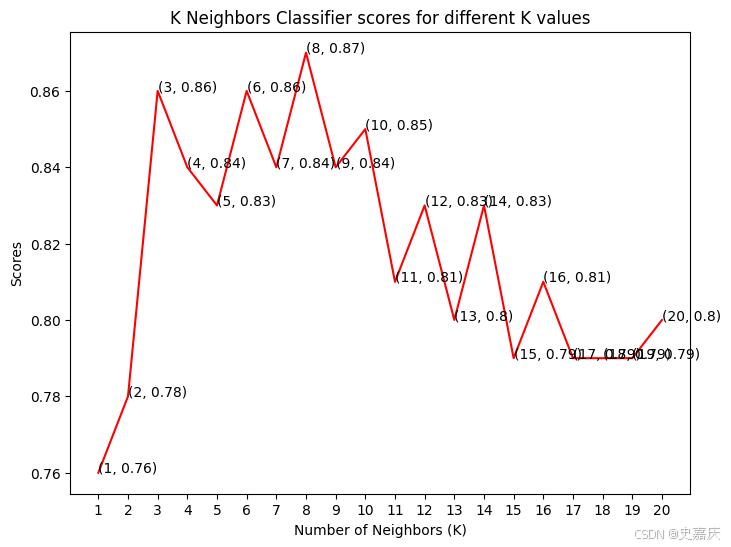
分類準確率會隨著我們選擇的鄰居數(K值)不同而變化。因此,將繪制不同K值對應的得分曲線,找出最佳的K值。
knn_scores = [] # 創建一個空列表,用來存儲不同K值對應的分類準確率for k in range(1, 21): # 遍歷K值從1到20knn_classifier = KNeighborsClassifier(n_neighbors=k) # 創建K近鄰分類器,設置鄰居數為kknn_classifier.fit(X_train, y_train) # 用訓練集訓練模型knn_scores.append(knn_classifier.score(X_test, y_test)) # 計算模型在測試集上的準確率,并加入列表中已經得到了不同鄰居數對應的準確率,保存在數組 knn_scores 中。 接下來,將繪制這組數據,看看哪個K值對應的準確率最高。
plt.plot([k for k in range(1, 21)], knn_scores, color='red')
# 繪制K值(1到20)與對應準確率的折線圖,線條顏色為紅色
for i in range(1, 21):plt.text(i, knn_scores[i-1], (i, knn_scores[i-1])) # 在每個點上顯示對應的K值和準確率,方便查看具體數值
plt.xticks([i for i in range(1, 21)])
# 設置x軸刻度為1到20的整數,表示不同的鄰居數K
plt.xlabel('Number of Neighbors (K)')
# 設置x軸標簽為“鄰居數(K)”
plt.ylabel('Scores')
# 設置y軸標簽為“準確率
plt.title('K Neighbors Classifier scores for different K values')
# 設置圖表標題為“不同K值下K近鄰分類器的準確率”
為了不復雜化代碼,文字重疊的問題我們就先忽略吧,繪圖可以交給ai大模型微調一下,此處不過多闡述。
從圖中可以看到,當我們鄰居數K=8的情況下,準確率是最高的,有87%。
邏輯回歸
# 導入邏輯回歸模型
from sklearn.linear_model import LogisticRegression# 初始化邏輯回歸模型,設置隨機種子和最大迭代次數
log_reg = LogisticRegression(random_state=0, max_iter=1000)# 在訓練數據上訓練模型
log_reg.fit(X_train, y_train)# 在測試數據上評估模型準確率
log_reg_score = log_reg.score(X_test, y_test)# 打印邏輯回歸模型的準確率
print("邏輯回歸模型的準確率為 {:.2f}%".format(log_reg_score * 100))
#打印結果
#邏輯回歸模型的準確率為 84.00%
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score# 預測測試集的標簽
y_pred = log_reg.predict(X_test)# 預測測試集的概率(用于計算ROC AUC)
y_prob = log_reg.predict_proba(X_test)[:, 1]# 計算各項指標
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_prob)print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1:.2f}")
print(f"ROC AUC: {roc_auc:.2f}")
# -------------------------------
# Precision: 0.85
# Recall: 0.85
# F1 Score: 0.85
# ROC AUC: 0.92
支持向量分類器(SVC)
支持向量分類器有多種核函數可選。將測試其中幾種,看看哪種核函數的準確率最高。
svc_scores = [] # 創建空列表,用來存儲不同核函數對應的準確率
kernels = ['linear', 'poly', 'rbf', 'sigmoid'] # 定義要測試的核函數列表for i in range(len(kernels)): # 遍歷所有核函數svc_classifier = SVC(kernel=kernels[i]) # 創建支持向量機分類器,指定當前核函數svc_classifier.fit(X_train, y_train) # 用訓練集訓練模型svc_scores.append(svc_classifier.score(X_test, y_test)) # 計算測試集準確率并存入列表現在將繪制每個核函數對應的準確率柱狀圖,看看哪種核函數表現最好。
colors = rainbow(np.linspace(0, 1, len(kernels)))
# 使用rainbow顏色映射生成與核函數數量相等的顏色列表,保證每個柱狀圖顏色不同plt.bar(kernels, svc_scores, color=colors)
# 繪制柱狀圖,x軸為核函數名稱,y軸為對應的準確率,柱子顏色由colors指定
for i in range(len(kernels)):plt.text(i, svc_scores[i], svc_scores[i]) # 在每個柱子上方顯示對應的準確率數值,方便查看
plt.xlabel('Kernels')
# 設置x軸標簽為“核函數”
plt.ylabel('Scores')
# 設置y軸標簽為“準確率”
plt.title('Support Vector Classifier scores for different kernels')
# 設置圖表標題為“不同核函數下支持向量分類器的準確率”
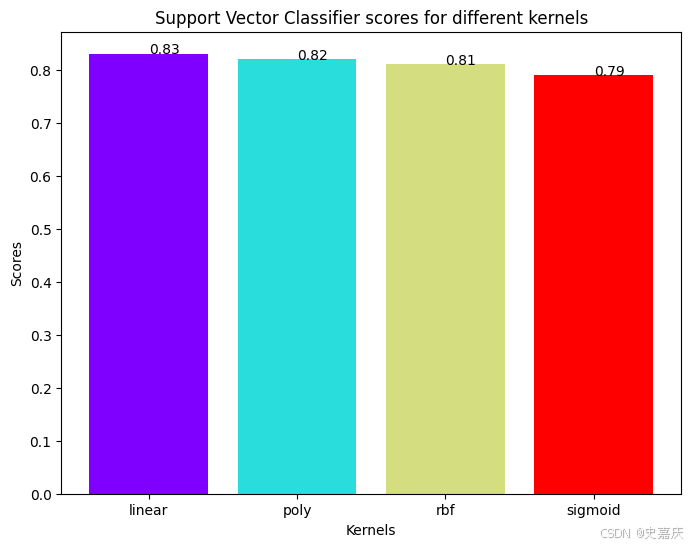
linear(線性)核表現最好,略優于 rbf 核。
決策樹分類器
這里將使用決策樹分類器來建模這個問題。調整一組 max_features 參數,看看哪個參數能得到最高的準確率。
dt_scores = [] # 創建空列表,用于保存不同 max_features 參數下的模型準確率for i in range(1, len(X.columns) + 1): # 遍歷 max_features 從1到特征總數的所有可能值dt_classifier = DecisionTreeClassifier(max_features=i, random_state=0) # 初始化決策樹分類器,設置當前 max_features 和隨機種子dt_classifier.fit(X_train, y_train) # 使用訓練集訓練模型dt_scores.append(dt_classifier.score(X_test, y_test)) # 計算測試集上的準確率并保存
選擇了從1到30個特征作為最大分裂特征數,現在來看一下每種情況下的準確率。
# 繪制最大特征數與準確率的折線
plt.plot([i for i in range(1, len(X.columns) + 1)], dt_scores, color='green') 圖,顏色為綠色for i in range(1, len(X.columns) + 1):plt.text(i, dt_scores[i-1], (i, dt_scores[i-1])) # 在每個點上顯示對應的 (最大特征數, 準確率) 值plt.xticks([i for i in range(1, len(X.columns) + 1)]) # 設置x軸刻度為從1到特征總數
plt.xlabel('Max features') # x軸標簽:最大特征數
plt.ylabel('Scores') # y軸標簽:準確率得分
# 圖表標題:不同最大特征數下的決策樹分類器得分
plt.title('Decision Tree Classifier scores for different number of maximum features')
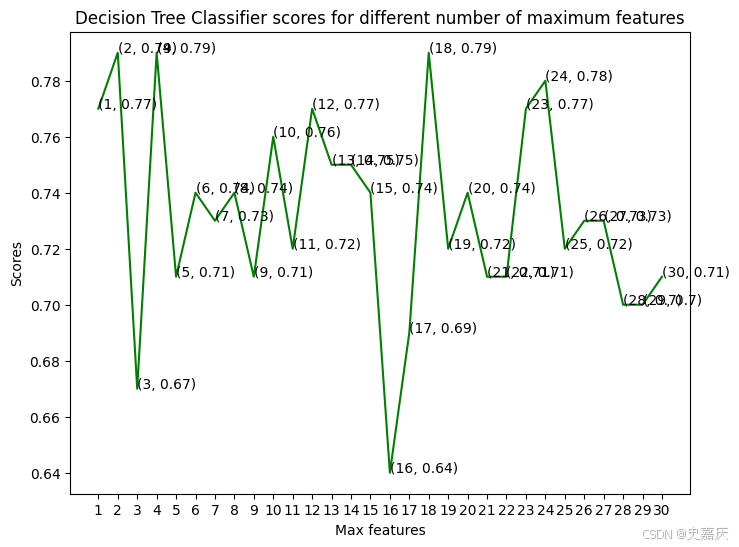
模型在最大特征數為 2、4 和 18 時,達到了最佳的準確率。
隨機森林分類器
現在,將使用集成方法——隨機森林分類器來創建模型,并改變估計器的數量以觀察其影響。
rf_scores = [] # 創建一個空列表,用于存儲不同估計器數量下模型的得分
estimators = [10, 100, 200, 500, 1000]# 定義不同的估計器數量列表,代表隨機森林中決策樹的數量。
for i in estimators: # 遍歷每個估計器數量# 初始化隨機森林分類器,設置估計器數量和隨機種子rf_classifier = RandomForestClassifier(n_estimators=i, random_state=0) rf_classifier.fit(X_train, y_train # 在訓練集上訓練模型rf_scores.append(rf_classifier.score(X_test, y_test)) # 計算模型在測試集上的準確率,并添加到得分列表中
模型已經訓練完畢,得分也記錄下來了,接下來繪制一個柱狀圖來比較各個得分。
colors = rainbow(np.linspace(0, 1, len(estimators))) # 生成顏色序列,數量與estimators列表長度相同,顏色從彩虹漸變取色
plt.bar([i for i in range(len(estimators))], rf_scores, color=colors, width=0.8) # 繪制柱狀圖,x軸為估計器數量的索引,y軸為對應的得分,柱寬設為0.8
for i in range(len(estimators)):plt.text(i, rf_scores[i], rf_scores[i]) # 在每個柱子頂部添加對應的得分文本標簽,方便查看具體數值
plt.xticks(ticks=[i for i in range(len(estimators))], labels=[str(estimator) for estimator in estimators]) # 設置x軸刻度標簽為estimators中的數字
plt.xlabel('Number of estimators') # 設置x軸標簽:估計器數量
plt.ylabel('Scores') # 設置y軸標簽:得分
plt.title('Random Forest Classifier scores for different number of estimators') # 設置圖表標題
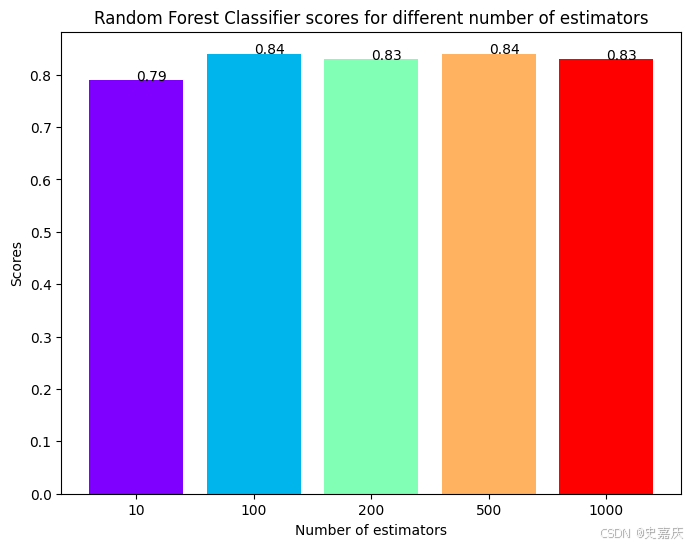
最大得分出現在估計器(決策樹)數量為100或500時。這里也能反映到決策樹數量要適中,因為太少會導致模型欠擬合和預測不穩定,太多則會造成計算資源浪費且準確率提升有限,存在收益遞減效應,需要在性能與效率之間找到最佳平衡點。
結論
在本項目中,使用機器學習來預測一個人是否患有心臟病。導入數據后,通過繪圖對數據進行了分析。然后,為類別特征生成了啞變量,并對其他特征進行了標準化處理。
接著,應用了四種機器學習算法:K近鄰分類器、邏輯回歸分類器、支持向量分類器、決策樹分類器和隨機森林分類器。在每個模型中調整參數,以提高模型的準確率。
最終,K近鄰分類器在使用8個鄰居時,取得了最高的準確率87%。


)



:)



啟動時提示Netty的某些類找不到)
- KMS drm_crtc.c)
)




)

)