目錄
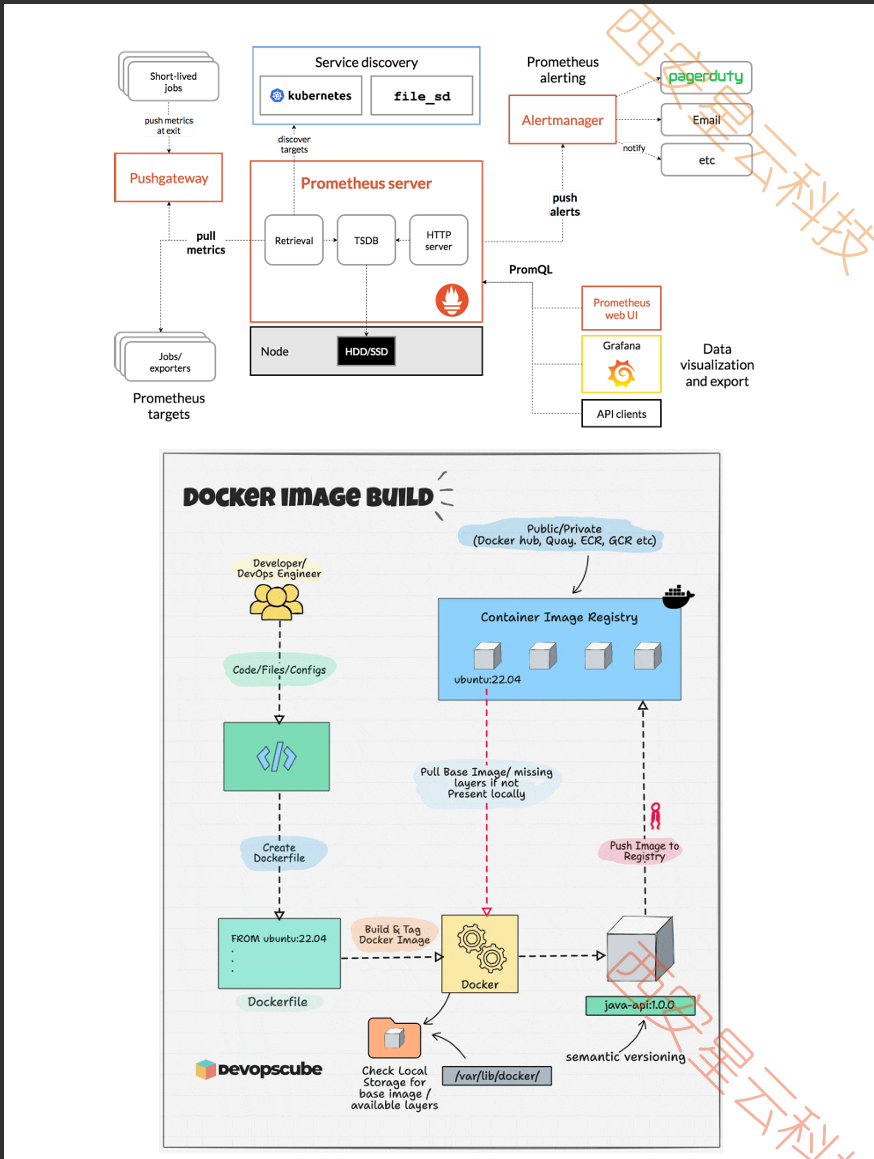
Prometheus組成及架構
prometheus核心組件
1.Prometheus Server
2.Exporters
3.Alertmanager
4.Pushgateway
數據流程
在k8s中部署Prometheus+Grafana+釘釘告警+郵件告警
將kube-Prometheus包下載后傳入虛擬機
tar -xzv kube-promethus.zip
cd 進入
ll 顯示目錄
至此prometheus以及釘釘告警、郵件告警修改完畢,先按步驟部署即可
1.創建pv
2.cd kube-state-metrics
3.cd node-export
4.cd alertmanager
5.cd prometheus-server
6.部署Grafana
7.現在為 Grafana添加一個數據源為Prometheus
8.添加模板
Prometheus組成及架構
prometheus核心組件
1.Prometheus Server
整個監控系統的核心 ,有以下功能
數據采集 :
通過http協議主動從目標服務器pull(拉取)指標數據,也可以通過 Pushgateway接受推送數據
數據存儲:
將采集的時序數據存儲到本地的時序數庫,默認保留15天
查詢與聚合提供PromeQL的查詢語言,支持實時分析聚合數據
告警與評估
根據定義的告警規則計算是否觸發告警,并將告警發送給Alertmanager
2.Exporters
用于將非Prometheus的數據類型轉換為Prometheus可識別的格式,如
主機監控:
node_exporter(收集CPU、內存、磁盤等主機指標)
應用監控:
如myspl_exporter(MySQL)、redis_exporter(redis)、blackbox_exporter(HTTP/ICMP探測)
自定義:
開發符合Prometheus規范的HTTP接口,暴露應用內不指標(如業務接口調用量)
3.Alertmanager
告警分組:
將同類的告警合并(如多臺服務器同時觸發高CPU告警)
告警抑制:
當某個告警觸發后,抑制其他相關的次要告警(如服務器宕機后,抑制其上應用告警)
告警路由:
根據規則將告警發送到不同的接收端(如郵件、Slack、PagerDuty、企業微信、釘釘等)
4.Pushgateway
可選組件,用于接收短期任務(如 CI/CD 作業)的指標數據,再由 Prometheus 定期從 Pushgateway 拉取。(因 Prometheus 原生是 Pull 模式,短期任務可能在被拉取前結束,故需 Pushgateway 中轉)
數據流程
- 目標服務通過 Exporter 暴露指標接口(或通過 Pushgateway 推送數據)。
- Prometheus Server 定期拉取指標并存儲到 TSDB。
- 用戶通過 PromQL 或 Grafana 查詢數據。
- Prometheus 評估告警規則,觸發時將告警發送給 Alertmanager。
- Alertmanager 處理告警并路由到指定接收端。
在k8s中部署Prometheus+Grafana+釘釘告警+郵件告警
需要自己部署好nfs環境最好在主節點
將kube-Prometheus包下載后傳入虛擬機
此目錄中文件全部可用,但需修改nfs的目錄路徑,已經nfs的IP、釘釘的Webhook,secret和郵件的收件人和發送人
tar -xzv kube-promethus.zip
![]()
cd 進入

ll 顯示目錄
1? cd alertmanager

vim alertmanager-configmap.yml
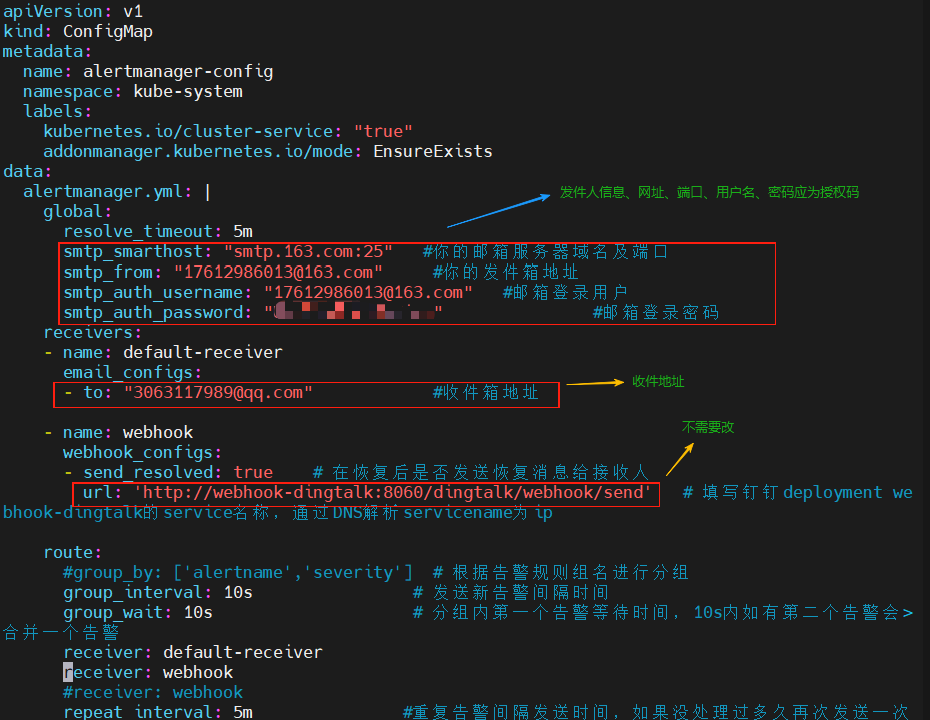
2? alertmanager 目錄只需修改此文件,現在退出至上一目錄
進入釘釘應用
選擇一個群,進入設置,點擊添加機器人,選擇加簽,選擇添加即可
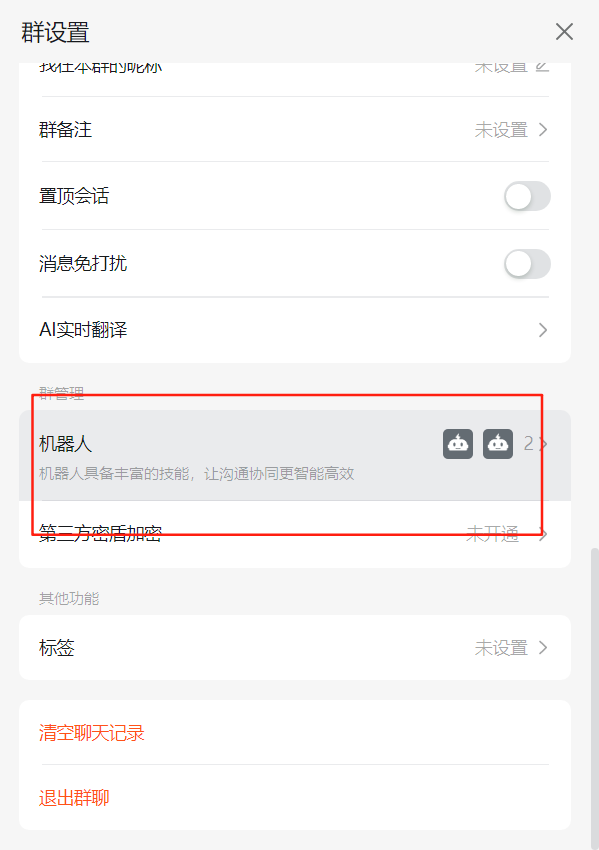
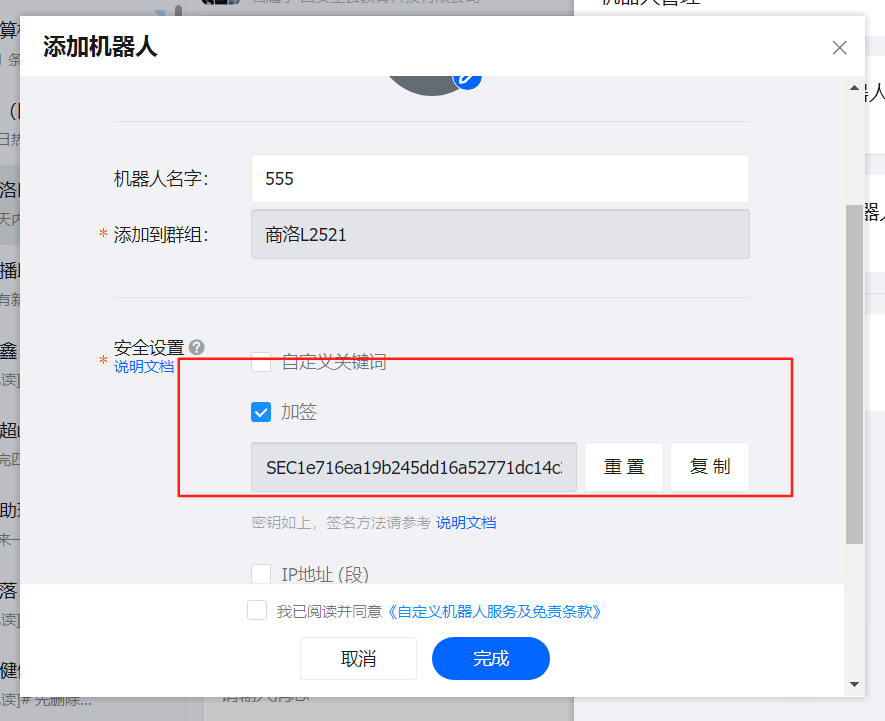
再次點擊機器人,下面會用到webhook和secret
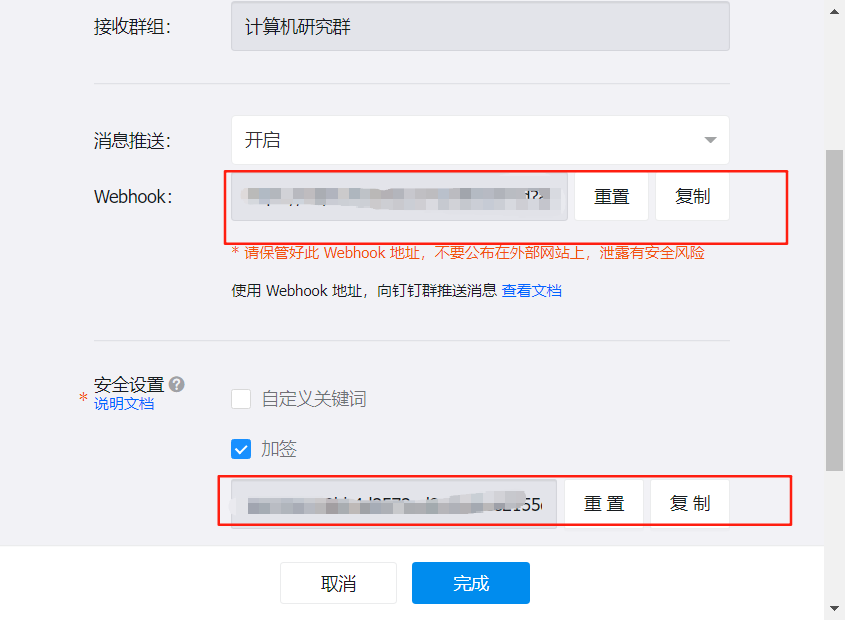
cd ..
cd dingding

vim dingtalk-configmap.yaml 修改圖中標出的url和secret
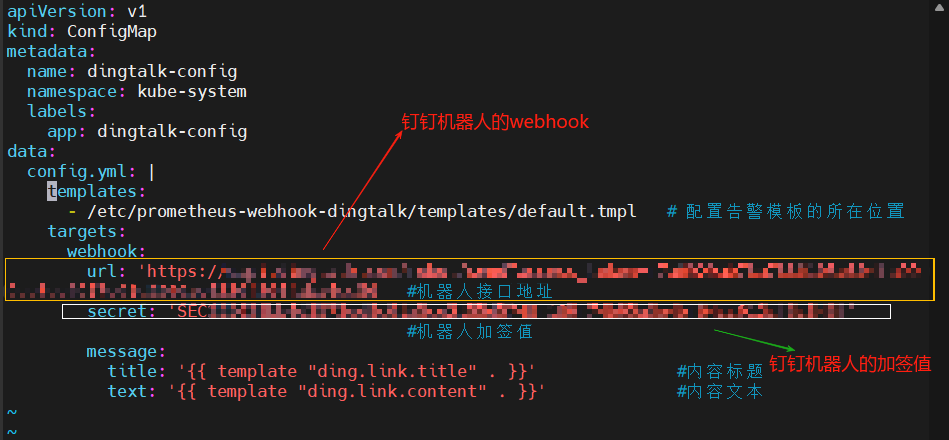
dingding修改完畢,現在退至上一目錄
3.? cd nfs-pv/

vim pv-demo.yml
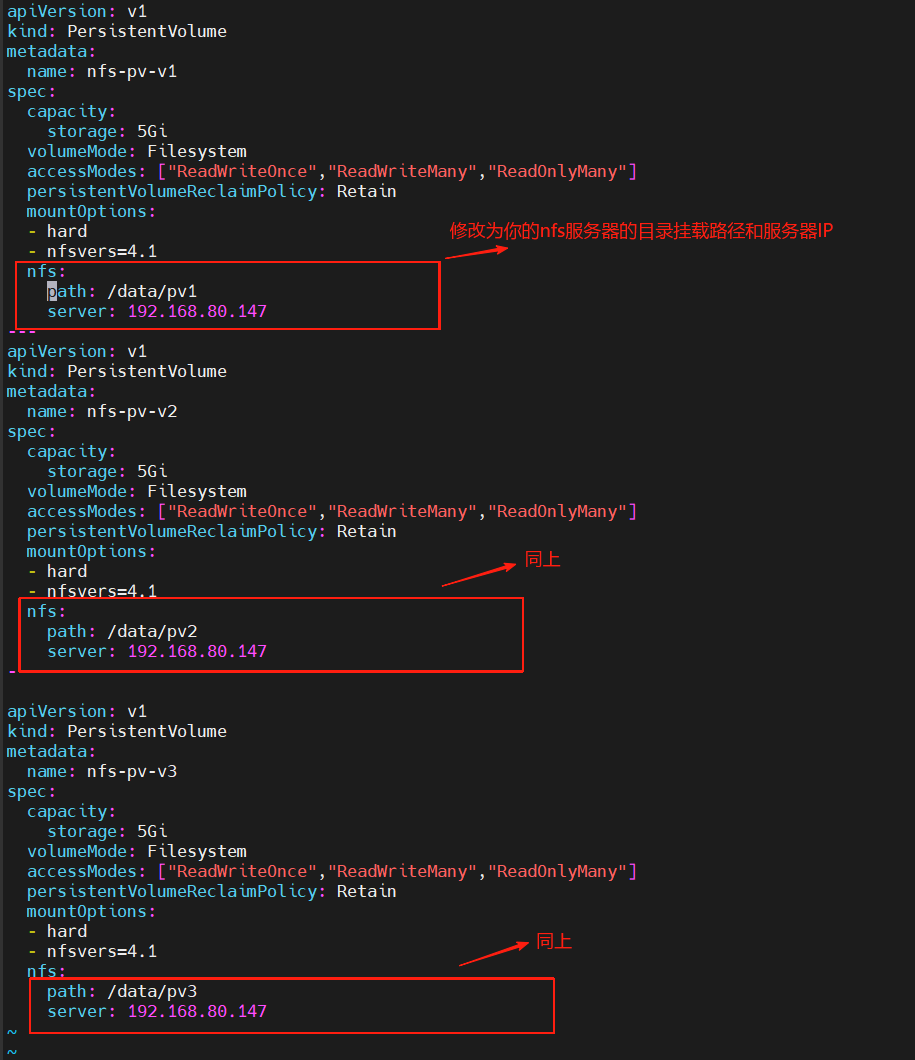
4.? nfs-pv 目錄修改完畢,退出至上一目錄
cd promethus-server

vim promethus-configmap.yml
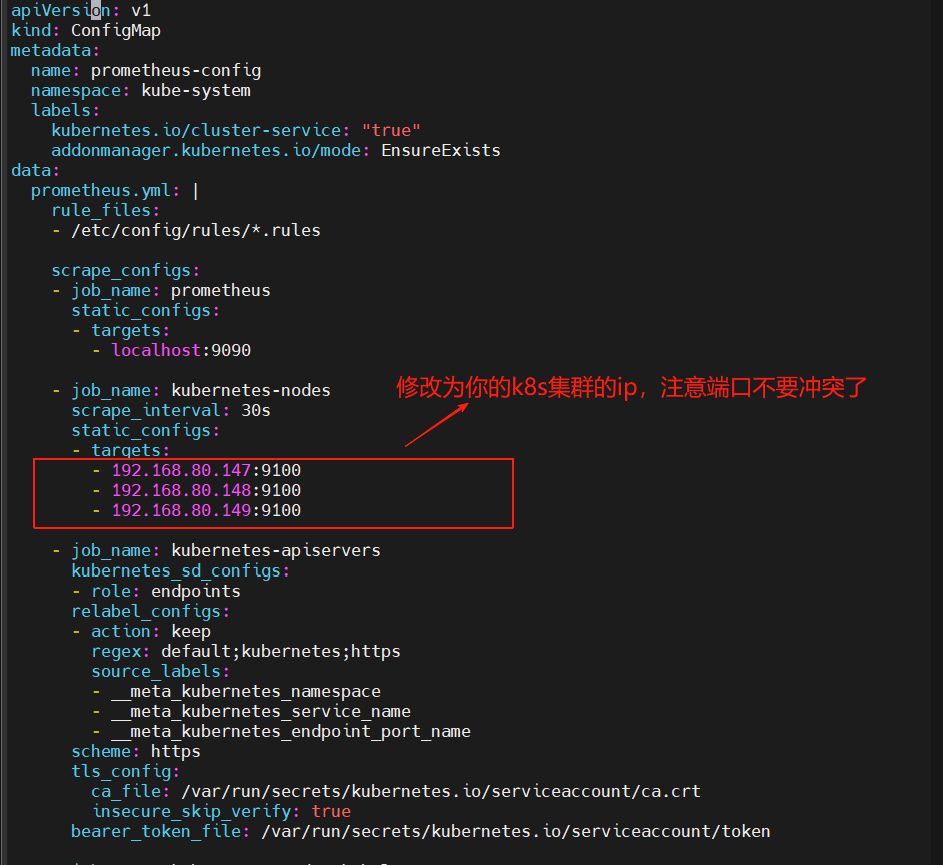
至此prometheus以及釘釘告警、郵件告警修改完畢,先按步驟部署即可
1.創建pv
cd nfs-pv
kubectl apply -f ./

我因為之前已經創建好了,所以這里顯示unchanged,正常顯示的是created
kubectl get pv 查看創建的pv 我的status是Bound因為已經綁定了pvc,正應該是Available

2.cd kube-state-metrics
kubectl apply -f .
同上,我的是unchanged,正常為created
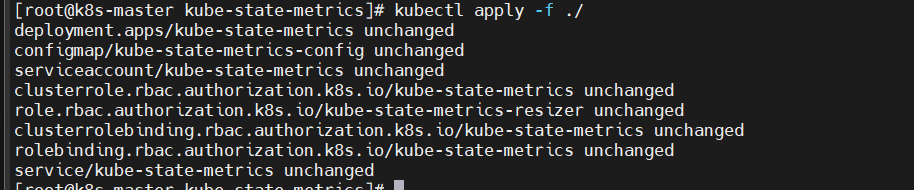
kubectl get pod -n kube-system 查看pod狀態 正常應為 reday 2/2 runing
若出現pod狀態為ErrImagePull ,則使用describe 查看pod狀態
![]()
kubectl describe pod kube-state-metrics-769d7f8b8b-rf2h2(換成自己的pod)命令查看報錯

發現鏡像拉不下來,則使用 -o wide 看pod分配到哪個節點,文章下面有對應的包
下載后傳到虛擬機上在使用 docker load -i 包名 即可拉取鏡像
等待2分鐘再次觀察pod的狀態,發現變為runing
3.cd node-export
啟動次pod時,注意使用的控制器時Daemonset,則每個節點都需要運行一個pod,但是master節點一般會有污點(為了提高master的管理效率,一般不在master上運行pod),所以我們需要清理污點
首先看master的污點類型
kubectl describe nodes master名稱 | grep Taint
過濾結果大概率為 node-role.kubernetes.io/master:NoSchedule
去除污點
將污點去除
kubectl taint nodes master名稱 node-role.kubernetes.io/master:NoSchedule- (注意這個減號,是去除的意思)
然后執行
kubectl apply -f ./
依舊同上

查看pod狀態
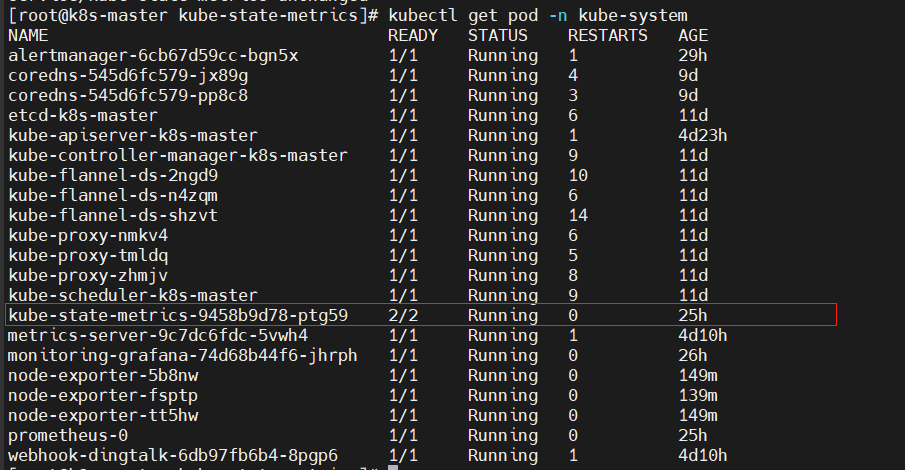
kubectl get pod -n kube-system -o wide
會有三個pod運行,且master、k8s-node01、k8s-node02各運行一個
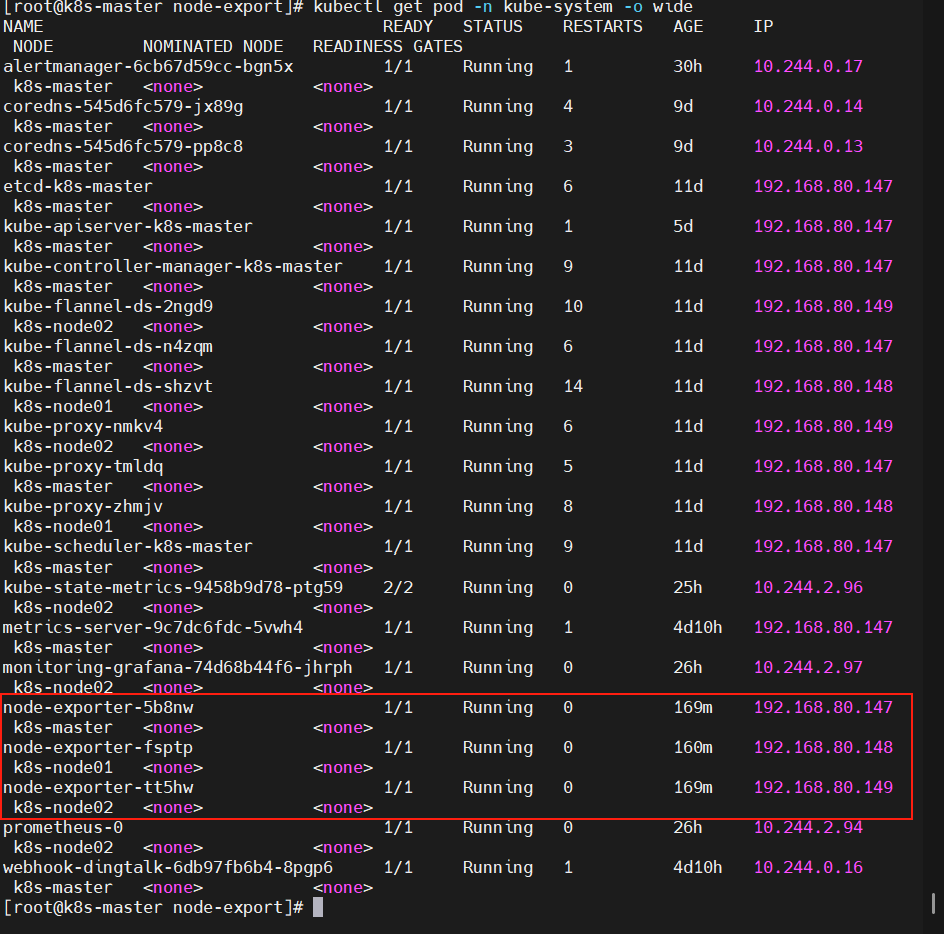
若狀態有問題,describe查看報錯,若鏡像 拉不下來,先給每個節點添加一個8.8.8.8的DNS,
vim /etc/sysconfig/network-scripts/ifcfg-ens33 編輯此文件添加一個DNS
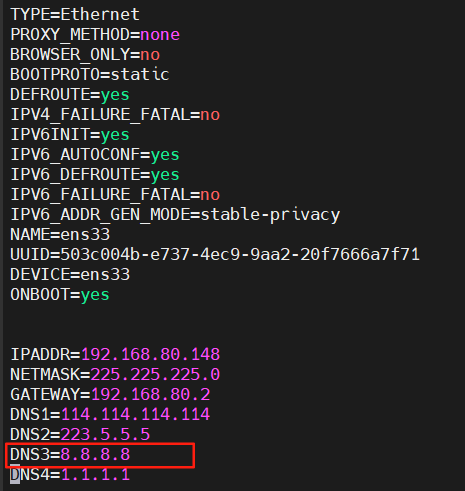
保存退出后重啟網絡
systemctl restart network
等待兩分中,若不行,使用下面方法
下載包(文章下面有),再傳到每個虛擬機,執行docker load -i 即可
查看svc
kubectl get svc -n kube-system
4.cd alertmanager
kubectl apply -f ./
同上

查看pod是否創建
kubectl get pods -l "k8s-app=alertmanager" -n kube-system

查看svc
kubectl get svc -n kube-system
5.cd prometheus-server
kubectl apply -f ./
同上

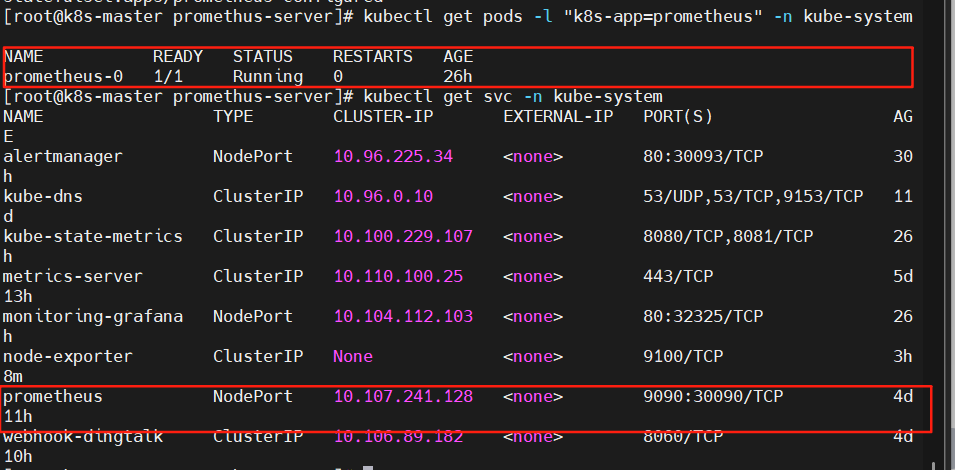
查看pod和svc是否成功創建
kubectl get pods -l "k8s-app=prometheus" -n kube-system
kubectl get svc -n kube-system
至此Prometheus部署完畢,測試是否可用
訪問任意節點的IP+30090端口
例如:192.168.80.147:30090
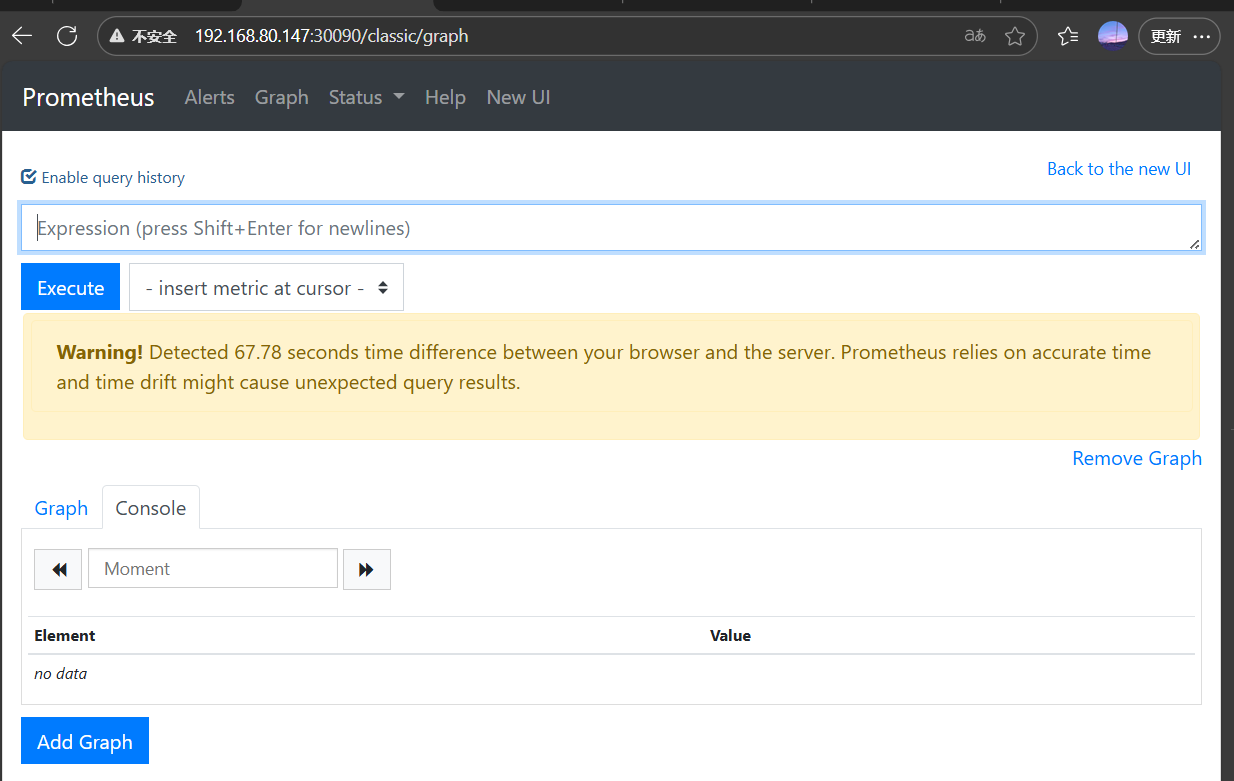
6.部署Grafana
cd grafana
kuebctl apply -f ./
同上

查看pod和svc狀況
kubectl get pod -n kube-system | grep monitoring-grafana
![]()
kubectl get svc -n kube-system | grep monitoring-grafana

至此Grafana部署完畢
測試訪問192.168.810.147:32325
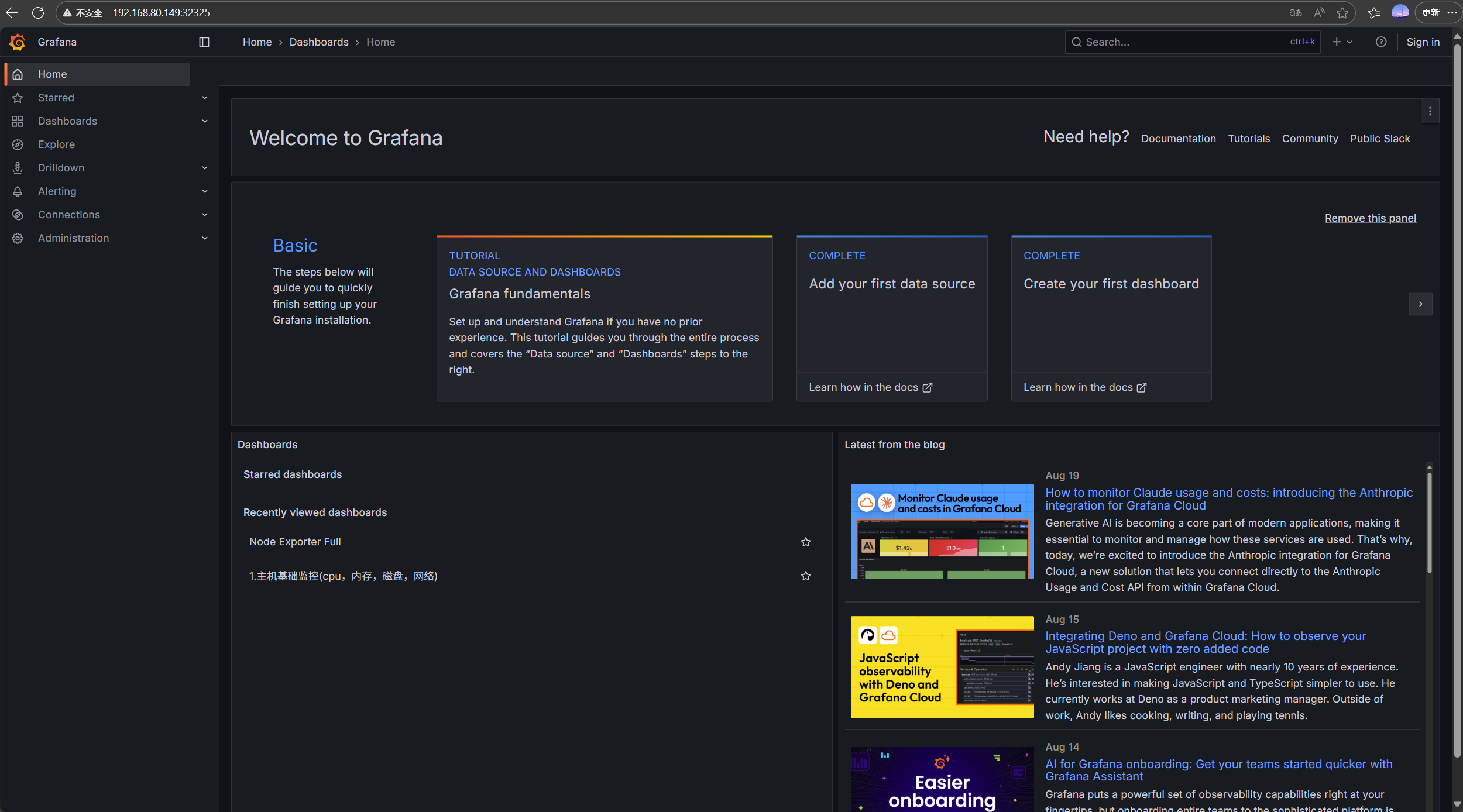
能進入代表部署成功
7.現在為 Grafana添加一個數據源為Prometheus
點擊Connections 連接
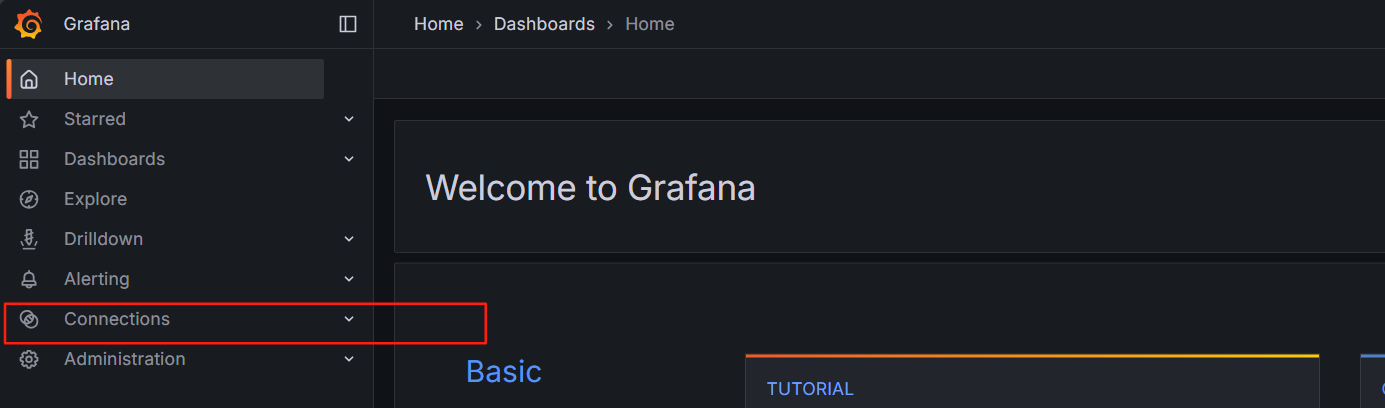
點擊 data sources數據源
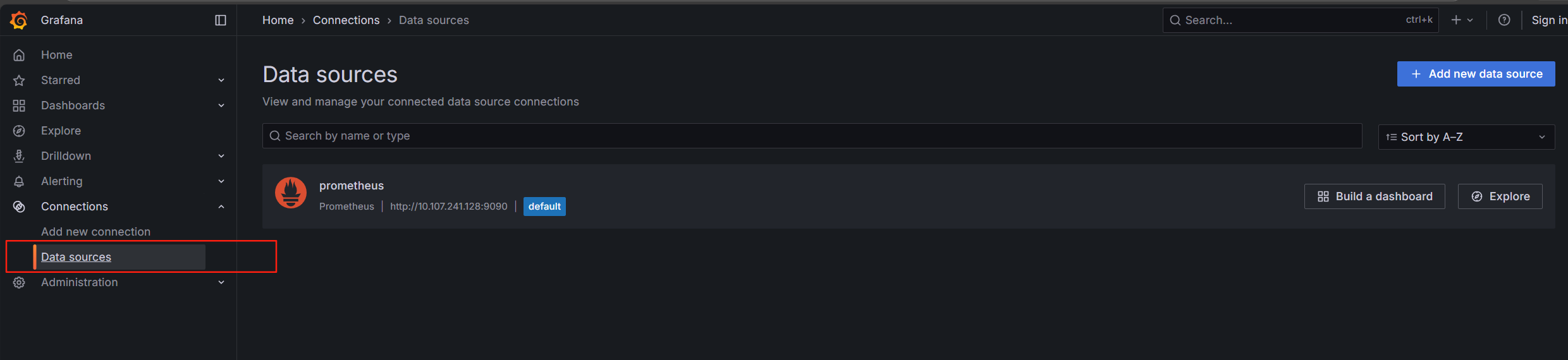
搜索prometheus

點進去
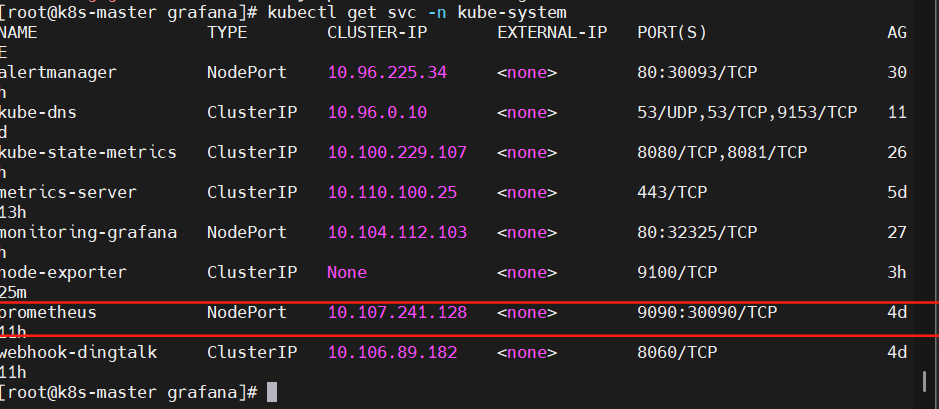
添加prometneus的svc IP和端口
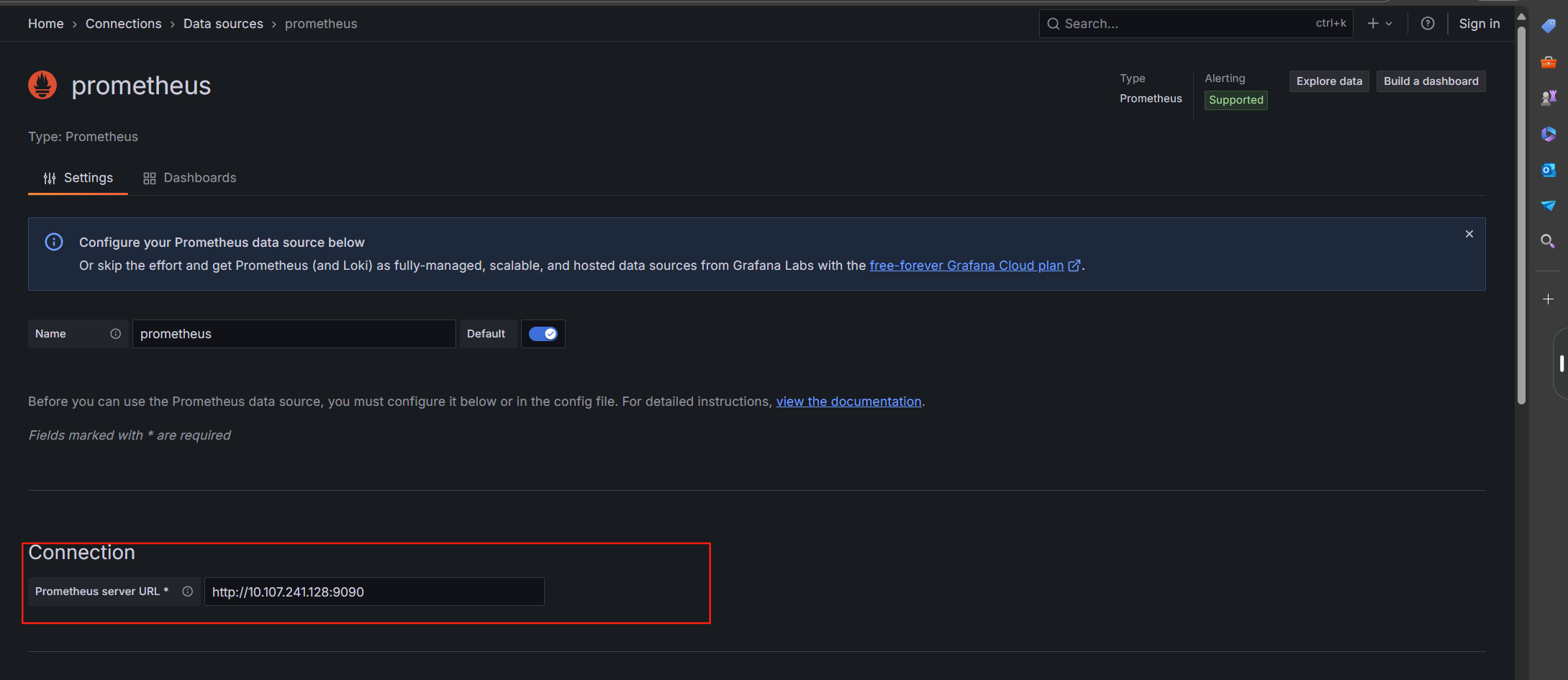
IP為prometheus的svc內部集群IP 端口為9090
添加好之后滑到最下面保存即可
8.添加模板
進入此網站搜索node,選擇第一個,進入后下載最新的
Grafana dashboards | Grafana Labs
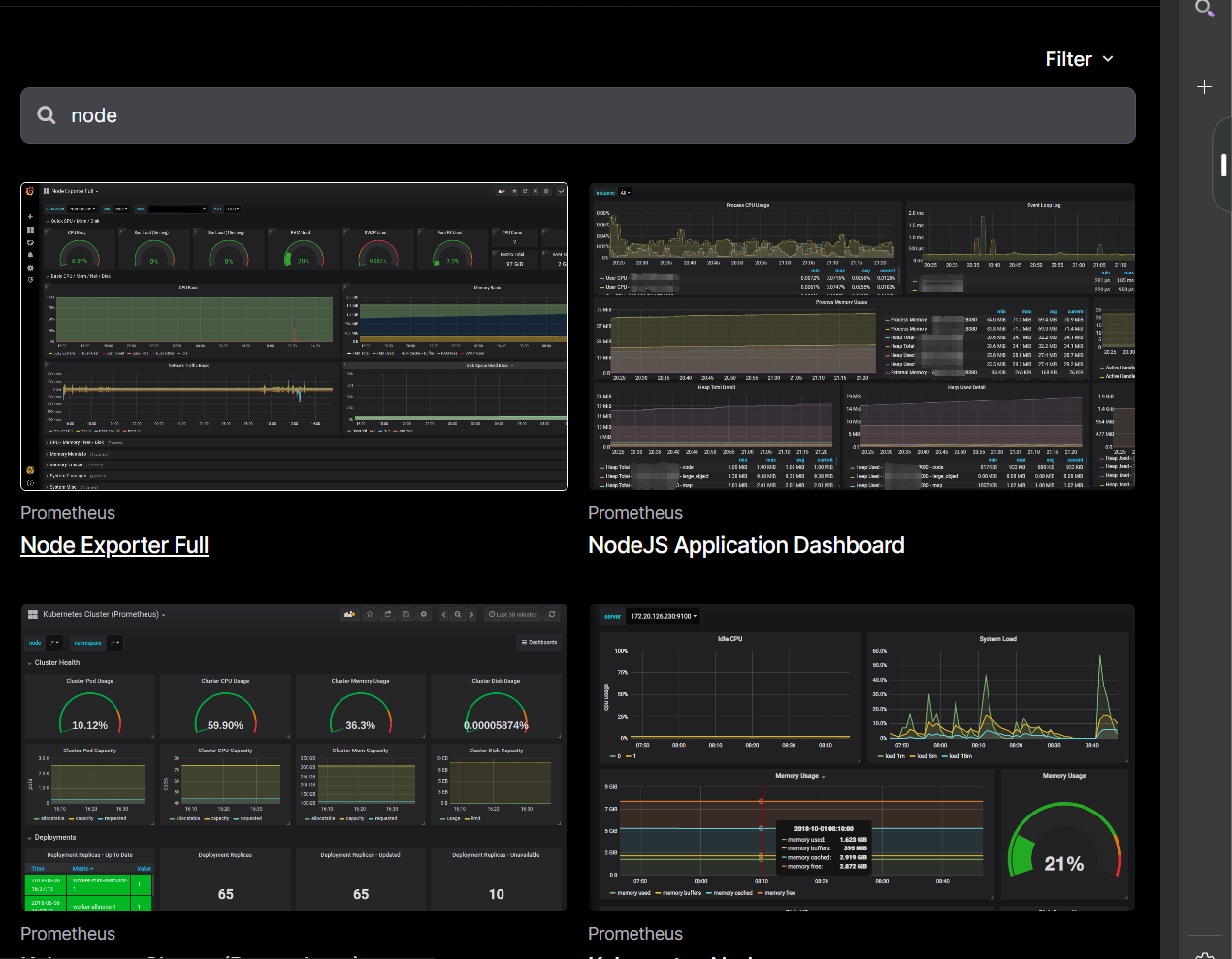
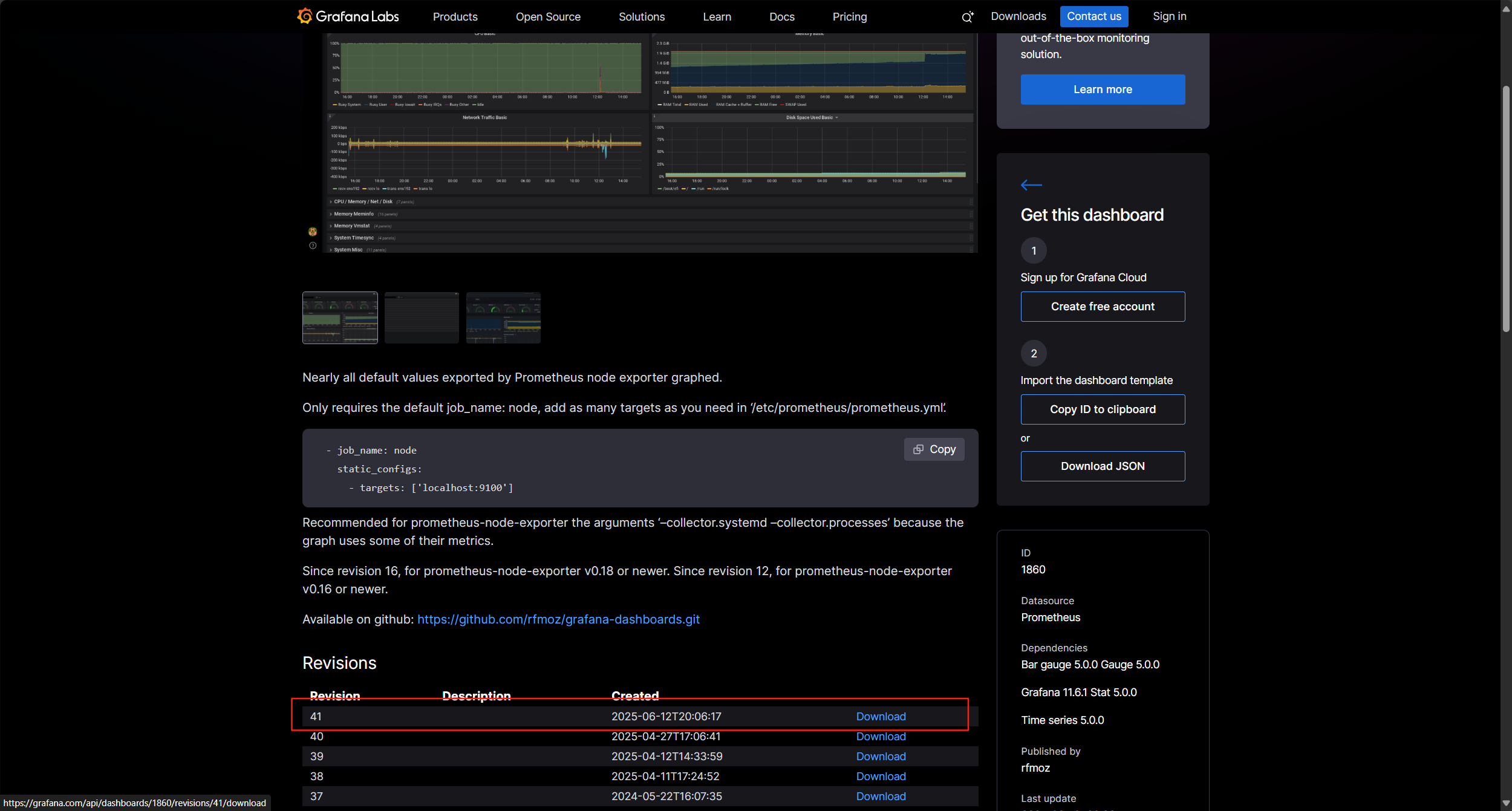
然后回到剛才的Grafana主頁的home
選擇Dashborad
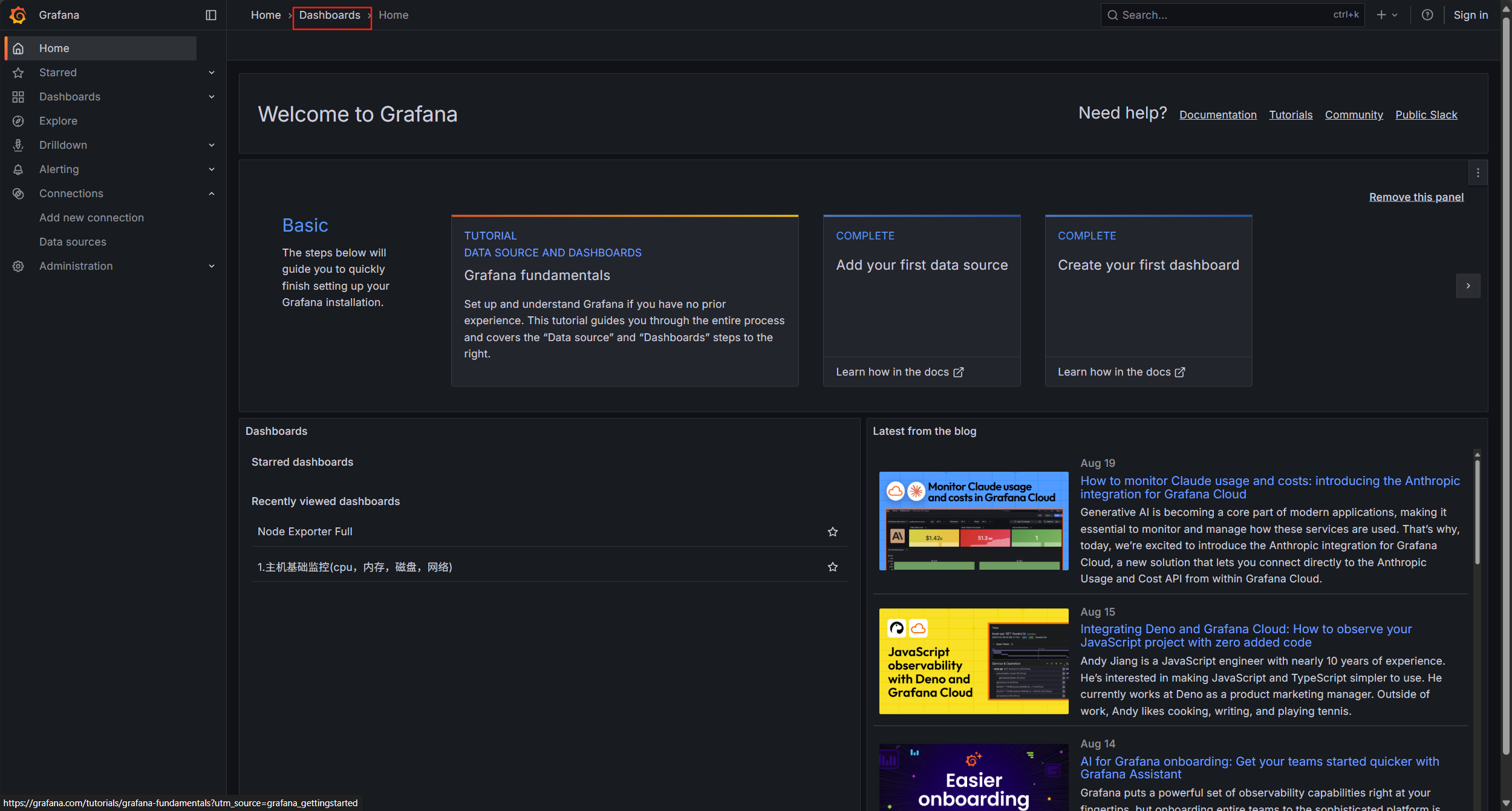
點擊右上角的 +
選擇import dashborad
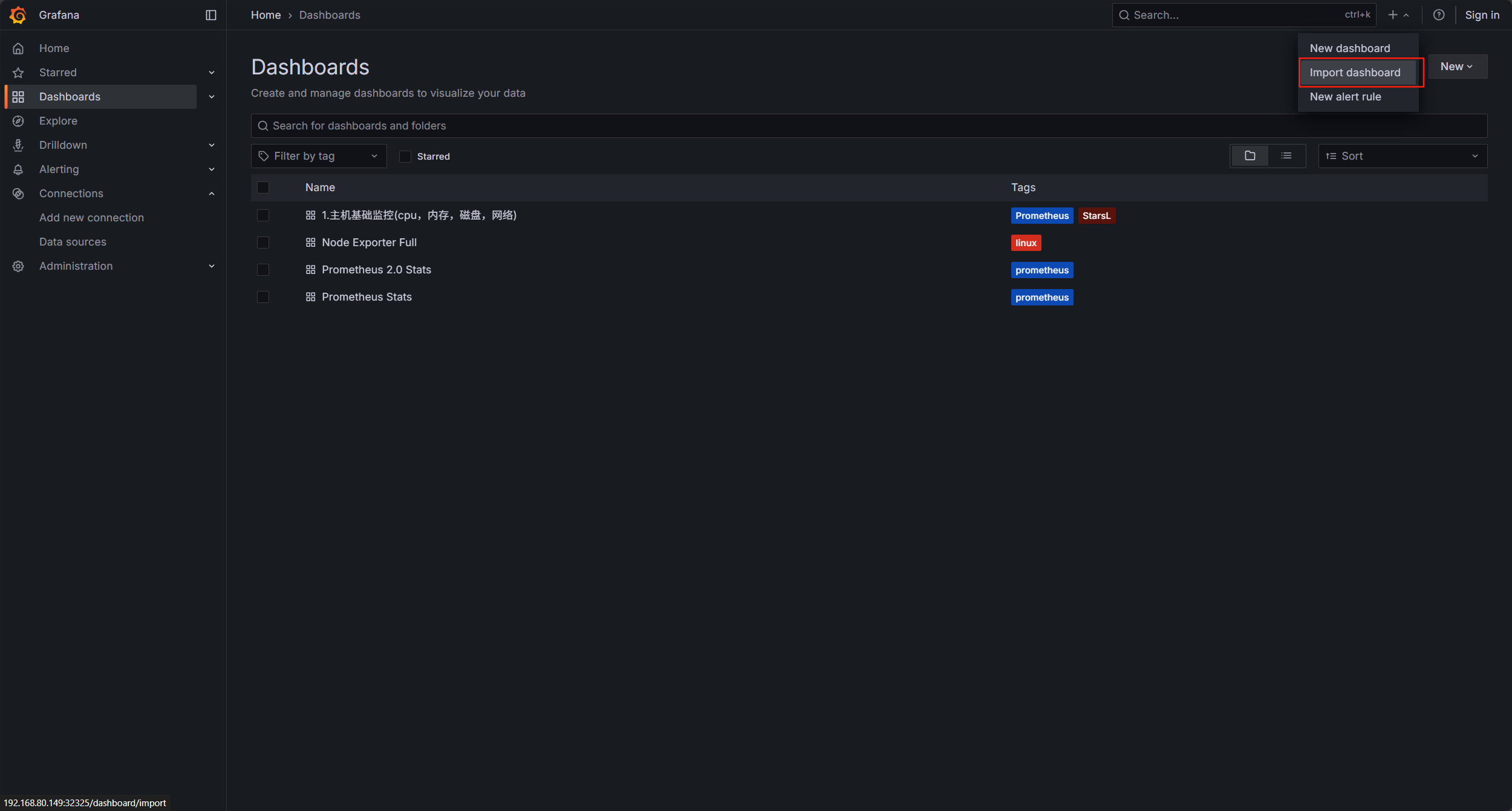
點擊導入模板,選擇剛才下載的模板,我這有三個,你們只有一個剛才下載的
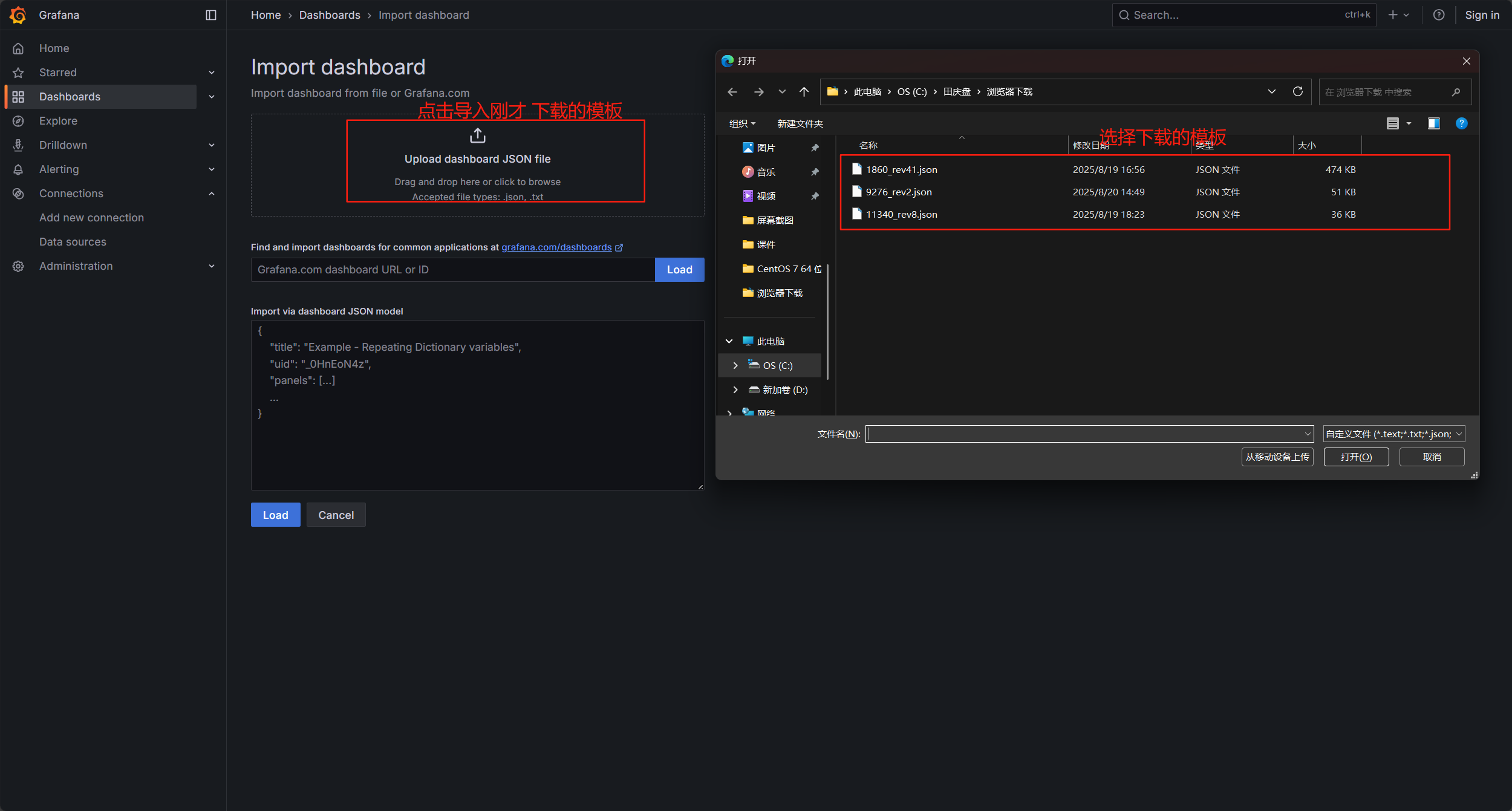
選擇數據源為 prometheus
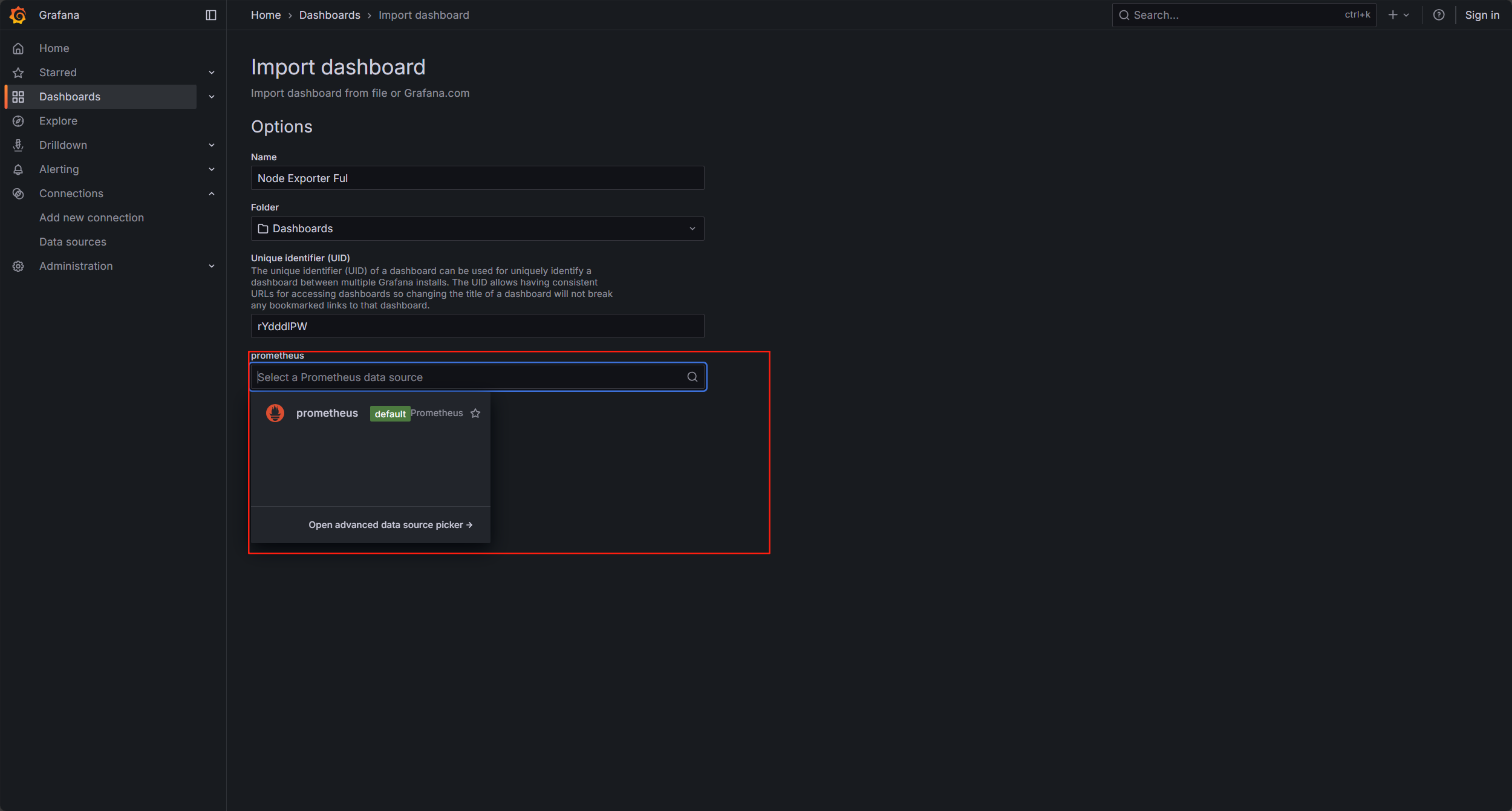
點擊import導入即可











)







