目錄
- 1.摘要
- 2.新穎獎勵與ε-貪婪衰減Q-learning算法
- 3.結果展示
- 4.參考文獻
- 5.代碼獲取
- 6.算法輔導·應用定制·讀者交流

1.摘要
路徑規劃是移動機器人的核心任務,需要在高效導航的同時規避障礙。本文提出了一種改進Q-learning算法——定制化獎勵與ε-貪婪衰減Q-learning(TRE-QL),該方法通過對重復訪問狀態進行懲罰,引導智能體探索新路徑;并設計了基于累計獎勵動態調整的ε-貪婪衰減策略,實現了從探索到利用的平滑過渡,保證學習過程的穩定性。
2.新穎獎勵與ε-貪婪衰減Q-learning算法
Q-learning用于移動機器人路徑規劃,通過試錯學習在未知環境中更新Q表,逐步形成最優策略,該方法能引導機器人以最短無障礙路徑到達目標,并在迭代中收斂,實現高效導航與避障。
環境建模

在Q-learning路徑規劃中,環境常通過網格離散化建模,將空間劃分為空閑單元與障礙單元,機器人在網格中選擇動作并判斷位置是否合法,從而實現路徑搜索。
L(st,at)=lt,lt∈{E,lt=eO,lt=oL(s_t,a_t)=l_t,\quad l_t\in \begin{cases} E, & l_t=e \\ O, & l_t=o & \end{cases} L(st?,at?)=lt?,lt?∈{E,O,?lt?=elt?=o??
環境網格化離散化為Q-learning路徑規劃提供狀態–動作框架,簡化Q表更新并顯著壓縮狀態空間,從而降低計算復雜度并加快收斂。該方法在室內或結構化環境中尤為適用,能高效支持實時路徑規劃。網格大小決定精度與效率的平衡:小網格提高路徑精度但計算代價大,大網格則降低負荷但精度不足。
動作空間
在網格化環境中,機器人動作空間采用4鄰域運動,每次移動一個單元格,該有限離散動作集簡化了Q-learning,實現高效路徑搜索與Q表更新。
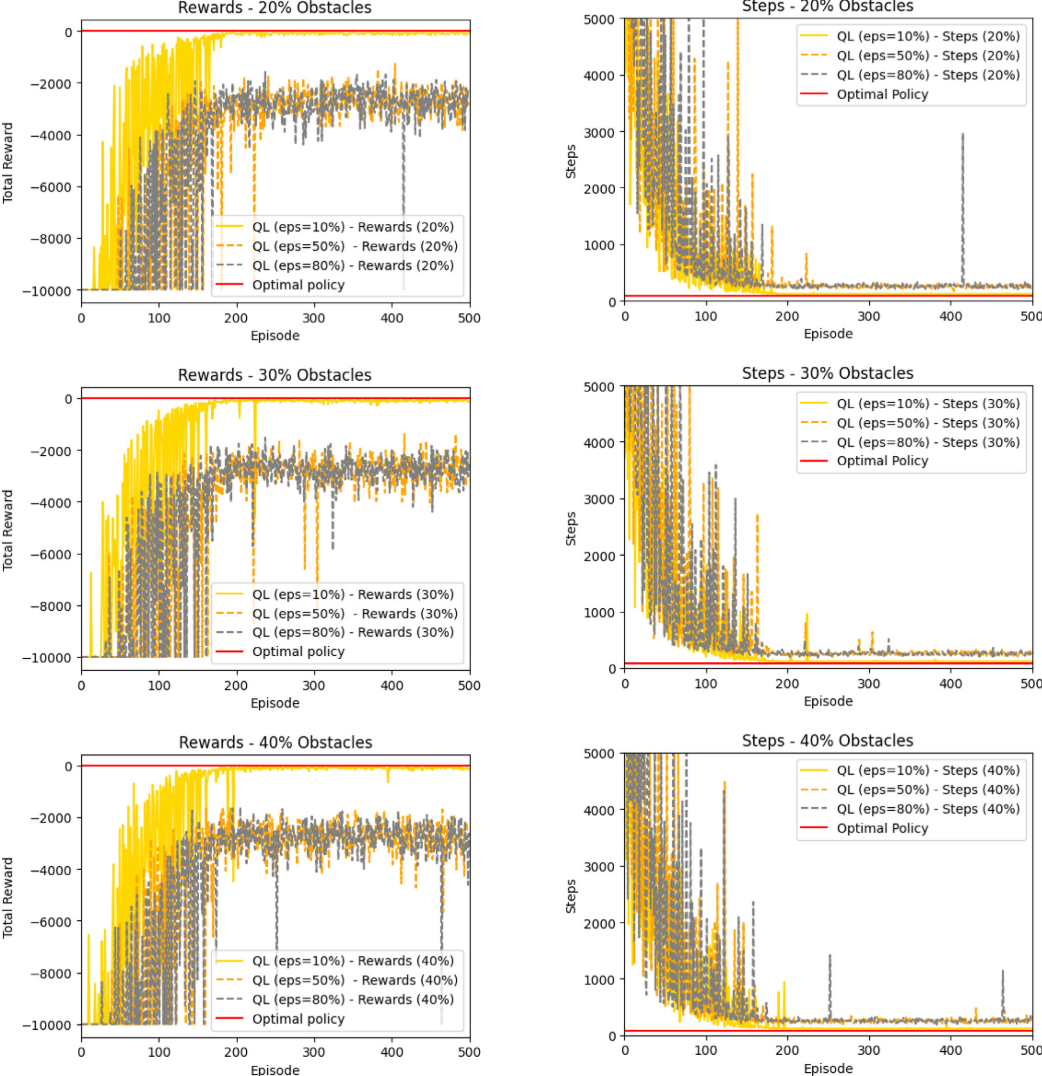
TRE-QL算法通過優化獎勵函數與引入動態ε-貪婪衰減機制,有效緩解了傳統Q-learning在探索—開發平衡中的局限性。實驗表明,當障礙密度超過10%時,固定 ε 值往往導致收斂失敗或陷入次優路徑。TRE-QL 根據累計獎勵自適應調整探索率,實現從探索到利用的平滑過渡,避免過早收斂并穩定智能體行為,從而在復雜環境中提升學習效率和收斂性能,顯著增強了Q-learning在受限環境下的魯棒性。
獎勵函數
在強化學習中,獎勵函數是智能體學習的核心反饋機制,直接決定其策略能否收斂至最優。傳統Q-learning常通過獎勵目標、懲罰碰撞的方式定義獎勵函數:
r={?r1collisionr2gettarget?r3other?statesr= \begin{cases} -r_1 & \mathrm{collision} \\ r_2 & \mathrm{get~target} \\ -r_3 & \text{other states} & \end{cases} r=?????r1?r2??r3??collisionget?targetother?states??
傳統Q-learning獎勵函數設定為:到達目標得正獎勵 +r2+r_2+r2?,碰撞受懲罰 ?r1-r_1?r1?,其他非目標狀態為?r3-r_3?r3?,且滿足r2>r3>r1r_2>r_3>r_1r2?>r3?>r1?,以突出先到達目標、再避障優先級。但該設計缺乏對重復訪問狀態的懲罰,易導致智能體在狀態間振蕩、學習效率降低。為此,本文提出優化離散獎勵函數:在單次回合內若狀態被重復訪問,則施加動態懲罰鼓勵探索新路徑、提升收斂速度與學習效率。
P(e)=C×KeP(e)=C\times K^e P(e)=C×Ke
在TRE-QL中,若累計獎勵Tcumulative>TthresholdT_\mathrm{cumulative}>T_\mathrm{threshold}Tcumulative?>Tthreshold?,則引入與成功經驗次數 eee 相關的動態懲罰機制,其中常數CCC與KKK控制懲罰的初始強度與衰減速率。由此,TRE-QL獎勵函數在傳統設計基礎上引入狀態重復訪問懲罰與動態調節項,更好地平衡目標達成與探索效率,實現更快、更穩定的收斂。
r={?r1collisionr2gettarget?r4=?P(e)revisit?same?state?more?than?once?r3other?statesr= \begin{cases} -r_1 & \mathrm{collision} \\ r_2 & \mathrm{get~target} \\ -r_4=-P(e) & \text{revisit same state more than once} \\ -r_3 & \text{other states} & \end{cases} r=?????r1?r2??r4?=?P(e)?r3??collisionget?targetrevisit?same?state?more?than?onceother?states??
動作選擇策略
為避免智能體過早收斂,TRE-QL引入自適應ε-貪婪衰減機制,其核心思想是在學習初期保持足夠探索,隨后依據累計獎勵動態調整探索率,使智能體平滑過渡到利用階段。若ε下降過快,會導致過早利用并陷入次優;若下降過慢,則會延遲收斂。自適應衰減通過累計獎勵與閾值比較來調控ε,若獎勵超過閾值,則以衰減因子更新ε:
?t+1=?t×CdifRcumulative>Tthreshold\epsilon_{t+1}=\epsilon_{t}\times C_{d}\quad\mathrm{if}\quad R_{\text{cumulative}}>T_{\mathrm{threshold}} ?t+1?=?t?×Cd?ifRcumulative?>Tthreshold?

3.結果展示
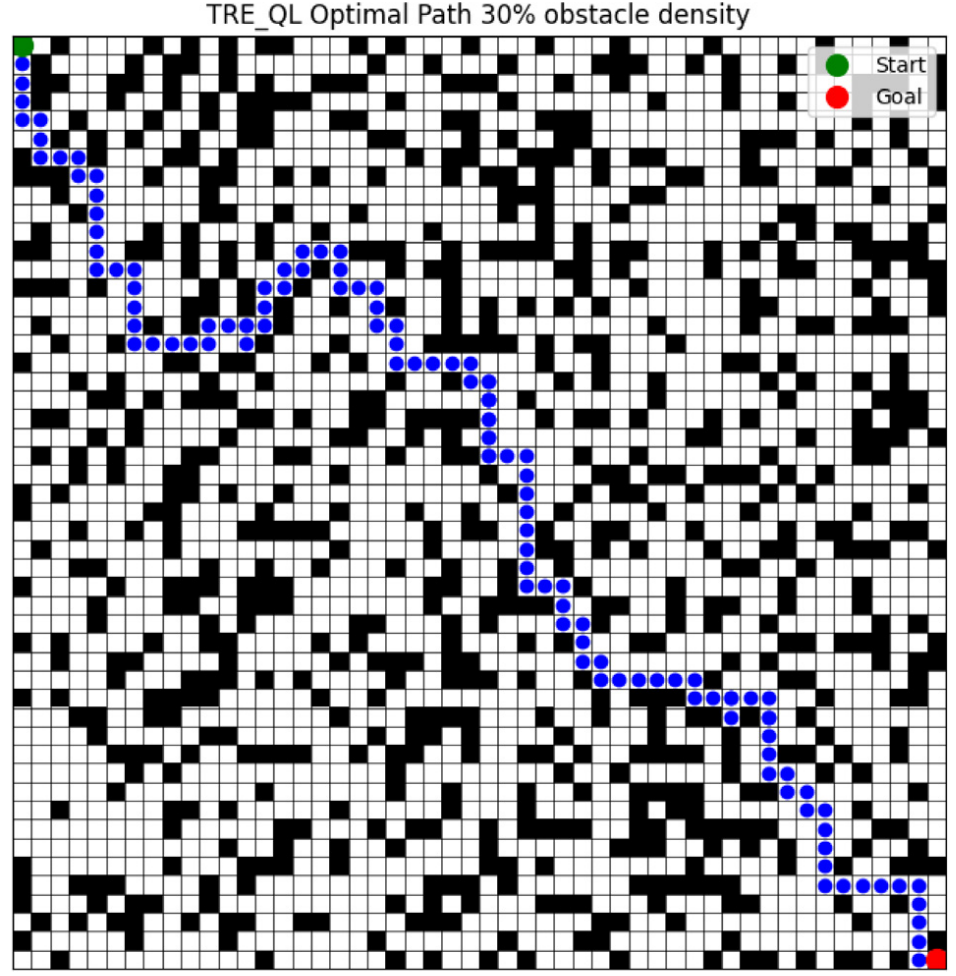
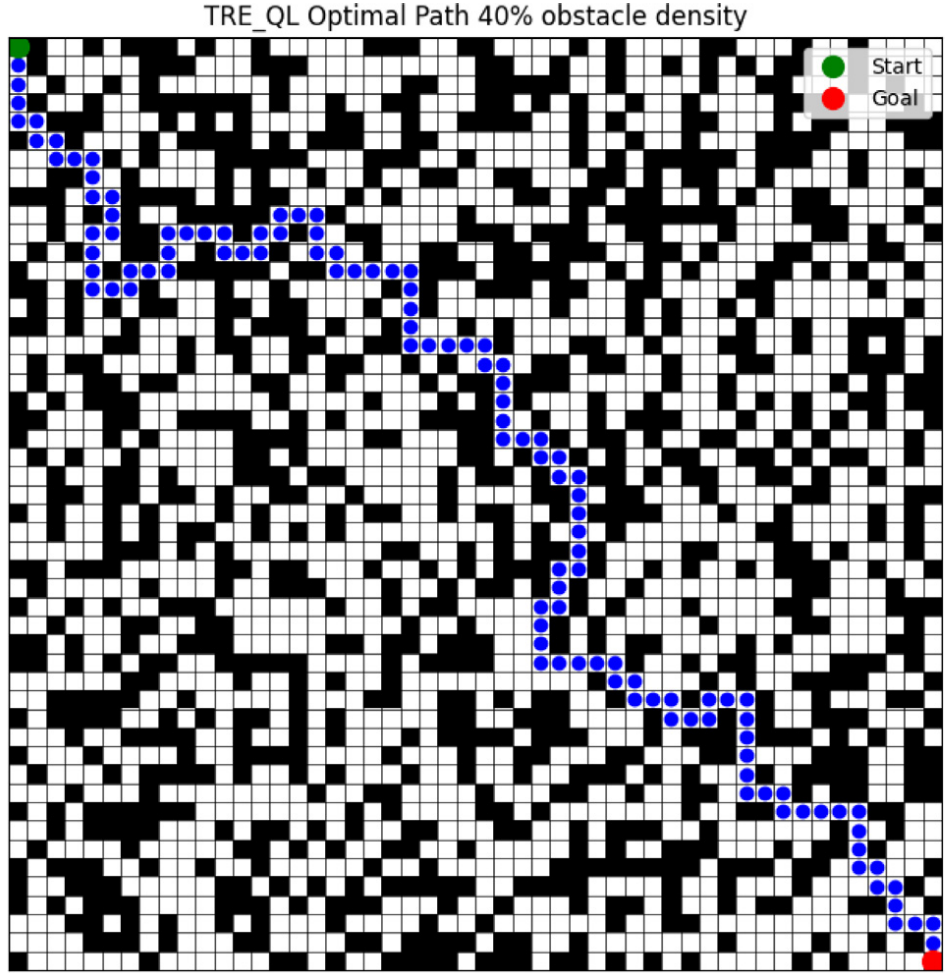
4.參考文獻
[1] Ben-Akka M, Tanougast C, Diou C. Novel design of reward and epsilon-greedy decay strategy tailored for Q-learning in optimizing local mobile robot path planning[J]. Knowledge-Based Systems, 2025: 113836.
5.代碼獲取
xx
6.算法輔導·應用定制·讀者交流
xx










)






)

