一、自適應彈性加速是提升芯片能效比的有力手段
自適應彈性加速技術是現代芯片設計中提升能效比的關鍵路徑之一。它摒棄了傳統芯片在設計時采用的靜態、固化的資源分配與功能設定模式,通過引入動態調整機制,使得芯片能夠根據實時的應用需求和負載變化,智能地調配其計算資源、功耗模式和硬件功能。這種“按需服務”的設計哲學,不僅極大地提升了資源的利用效率,也顯著降低了不必要的能量消耗,從而在整體上實現了性能與功耗的最佳平衡。以下將從資源、功耗和功能三個層面,結合實際應用場景,深入分析自適應彈性加速的優勢。
- 資源層面:動態激活與高效共享
在資源層面,自適應彈性的核心在于動態的資源管理與高效的硬件共享。其最具代表性的實現方式就是異構計算(Heterogeneous Computing),即在一顆芯片上集成不同類型的處理器核心,以應對不同性質的工作負載。
這一理念的典范是ARM公司的big.LITTLE技術(現已演進為DynamIQ),它被廣泛應用于全球幾乎所有的智能手機SoC中,例如高通的驍龍(Snapdragon)系列和聯發科的天璣(Dimensity)系列。圖1為所有彈性的設計架構的核心DynamIQ Shared Unit(DSU)。DSU構建了CPU、L3 cache、Snoop Filter、外圍設備總線buses、power management features之間異步通信的橋梁,同時也起到了節省功耗和時間的作用。這些芯片內部集成了用于處理高強度任務的大核(Performance Cores)和多個用于處理輕量級任務的小核(Efficiency Cores)。操作系統能夠智能地將大型游戲等高負載任務調度到大核,而將消息接收等后臺活動放在小核上運行,甚至在待機時完全關閉大核,從而極大延長電池續航。這一成功模式也延伸到了PC領域,英特爾(Intel)的酷睿(Core)處理器全面采納了類似的性能混合架構,并輔以硬件線程調度器(Intel Thread Director)技術,向Windows 11等操作系統提供精準的調度建議,確保不同類型的任務總能在最合適的P-core(性能核)或E-core(能效核)上執行,實現了能效與性能的優化。
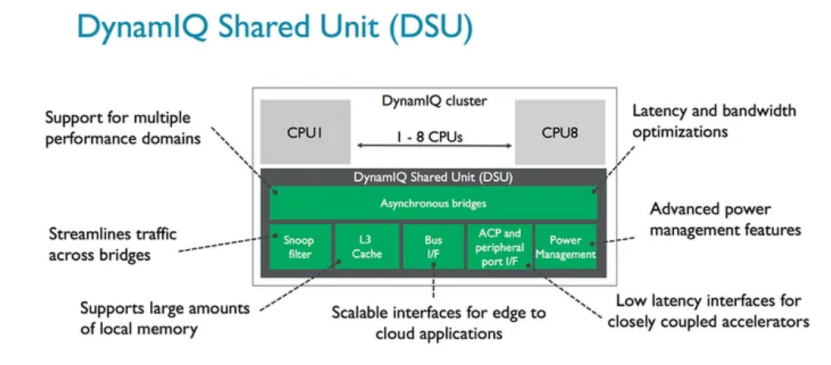
圖1 DSU架構示意圖[1]
- 功耗層面:精細化電源管理
功耗是制約芯片性能發揮的核心瓶頸。自適應彈性技術通過與PMIC(電源管理集成電路)的協同設計,實現了對芯片功耗的毫秒級、毫瓦級精細控制。
蘋果的M系列芯片(Apple Silicon) 是展現這一優勢的極致案例。得益于其強大的垂直整合能力,蘋果自主設計了從處理器核心到PMIC乃至macOS操作系統的所有關鍵環節。這使得其PMIC能為芯片上成百上千個獨立的電壓域提供極其精準和迅速的動態電壓與頻率調整(DVFS)。當用戶僅瀏覽網頁時,核心可以低頻運行;一旦開始視頻剪輯,相關單元的電壓和頻率會瞬間拉滿以保證性能。這種軟硬件的無縫配合是其實現業界領先能效比的關鍵。同樣,在其他高端移動SoC中,PMIC也將CPU、GPU、NPU等眾多功能單元劃分為獨立電源域,在不使用時可通過電源門控(Power Gating)技術徹底切斷供電,杜絕靜態功耗,確保每一毫瓦電量都用在刀刃上。以M1 Pro/M1 Max芯片為例,如圖2所示,M1 Pro和M1 Max內部集成多達10核中央處理器,同等功耗水平下的運行速度比最新款的8核PC筆記本電腦芯片快達1.7倍,達到其峰值水平性能所需功耗卻少了70%。
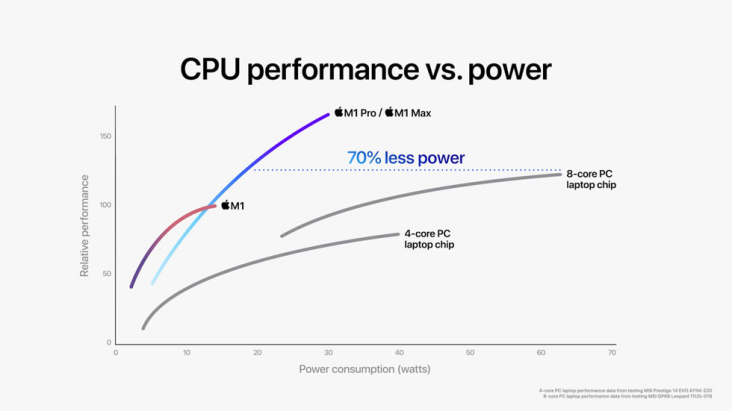
圖2 M1 Pro/M1 Max及PC筆記本電腦的功耗、性能比較[2]
- 功能層面:多模態與可重構加速
在功能層面,自適應彈性計算通過硬件的可重構性,打破了專用集成電路(ASIC)功能固化與通用處理器(CPU)效率低下的兩難困境,賦予了芯片“隨需而變”的能力。
現場可編程門陣列(FPGA)是這一理念的經典代表,以AMD(原Xilinx)和Intel的產品為首,被大規模部署于云數據中心。例如,微軟在其全球數據中心利用FPGA構建了“Catapult”加速平臺,可根據業務需求,將FPGA重構為網絡處理器以分擔CPU負載,或重構為AI加速器執行必應搜索模型,通過軟件推送即可完成芯片升級。面向未來,為應對AI算法的快速迭代,SambaNova Systems等公司研發了可重構數據流單元(RDU)。其編譯器能將不同神經網絡模型的數據流圖直接映射到硬件上,通過軟件配置“塑造”出最適合當前算法的硬件結構。這使得同一塊芯片能高效處理從CNN到Transformer等各類模型,真正實現了“以軟件定義硬件”,極大地擴展了芯片的通用性和生命周期。國內知存公司具有自研的用于神經網絡映射的編譯軟件棧WITIN_MAPPER,如圖3所示,可以將量化后的神經?絡模型映射到WTM2101 MPU加速器上,是?種包括RISCV和MPU的完整解決?案,可以完成多種算子和圖級別的轉換和優化,將預訓練權重編排到存算陣列中,并針對網絡結構和算子給出存算優化方案,是自適應彈性計算的一個典型例子。
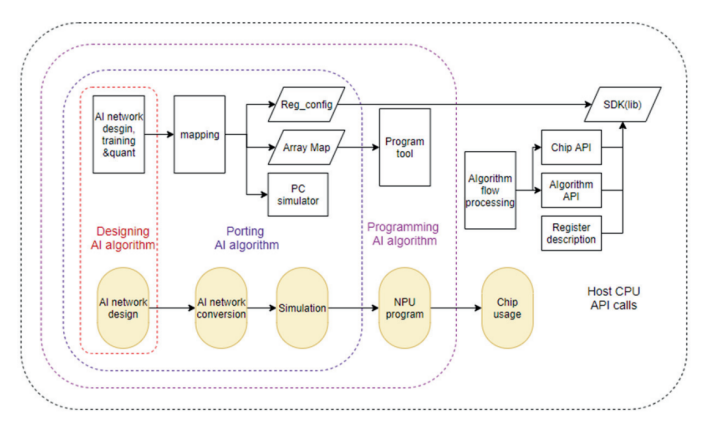
圖3 編譯軟件棧WITIN_MAPPER架構圖[3]
二、自適應彈性計算是優化浮點存內計算的方法論
為應對現代AI模型日益增長的復雜性與多樣性,浮點存內計算技術的優化進入了新的階段,其核心方法論便是自適應彈性計算。該方法論旨在打破傳統計算硬件“一招鮮吃遍天”的僵化設計,賦予存算單元根據算法需求動態調整自身計算特性的能力,從而在各種應用場景下實現能效與性能的最優化。在本文中,我們將這一理念通過兩個關鍵維度展開:自適應精度和可重構功能。
1.自適應精度
深度神經網絡在推理和訓練過程中,不同網絡層對計算精度的要求存在顯著差異。例如,一些層可能需要高精度的浮點(Floating-Point, FP) 運算來保留關鍵特征信息,而許多其他層的計算則可以在較低精度的定點或整數(Integer, INT)格式下完成,且對模型整體準確率的影響微乎其微。傳統的固定精度硬件設計無法適應這種多樣性,往往導致功耗和面積的冗余。自適應精度技術通過使CIM宏單元支持多種數據格式(如FP32、FP16、BF16、INT8、INT4等),并允許在運行時動態切換,實現了計算資源與算法需求的高度匹配,顯著提升了芯片的能效與吞吐率。
目前,學術界與工業界提出了許多方式來實現浮點存內計算的自適應精度方案。臺積電Khwa和Wu等人提出一種高精度的整數/浮點數雙模存算宏[4],通過消除指數計算中的減法、重用INT模式中的對齊電路、指數加和與加法器樹融合等方案,設計雙模可復用的存內計算單元,使存算宏可在同時支持INT8、BF16計算的同時下保持高硬件資源復用。
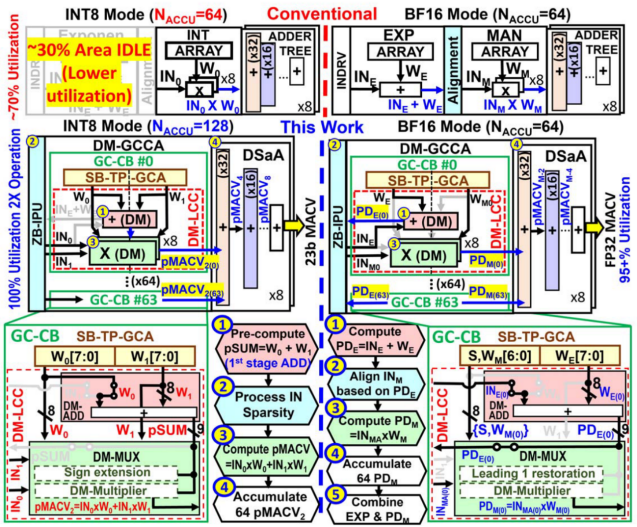
圖4?ISSCC 24 34.2提出的雙模計算宏
清華大學Yue和Xiang等人提出一種支撐復合AI(Compound AI)應用的存算宏,支持INT8、FP8、FP16精度計算[5]。通過提出并行尾數乘積和指數和的異質CIM宏,并在計算過程中設計混合精度計算模式,并通過稀疏感知進行計算加速,與先前的工作相比性能提升2.7倍以上,并且在能效與面效上達到了新的突破。
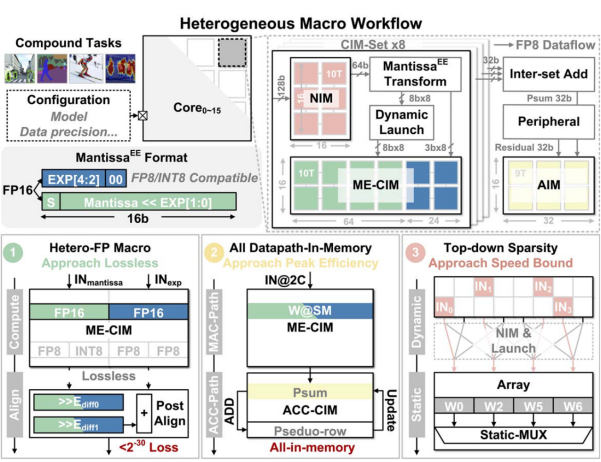
圖5?ISSCC 25 14.4提出的稀疏感知存算宏
2.可重構計算
如果說自適應精度是從數據層面賦予了存算單元靈活性,那么可重構功能則是從硬件架構的維度,通過重塑計算模式與數據路徑,將存內計算的“彈性”提升至全新高度。現代AI模型的計算圖譜遠比單純的矩陣乘法復雜,其中交織著大量的非線性激活、歸一化、池化乃至更復雜的逐元素運算。在傳統設計中,這些非MAC(乘加)操作往往需要中斷存內計算流程,將數據在存儲陣列與外部獨立的數字處理單元之間來回搬運,這構成了顯著的性能與功耗瓶頸。
可重構功能旨在打破這種化的“存儲-計算”分離模式,其核心思想是使CIM宏單元的物理結構能夠根據當前計算任務的需求,動態地改變其功能與內部數據流。這種重構體現在多個層次:
1)算子可重構:?使同一套硬件電路既能執行高并行的乘加運算,也能被配置執行非線性函數等其他關鍵算子。
2)計算模式與路徑可重構:允許CIM宏根據不同類型的神經網絡層(如卷積層、全連接層)或不同的數據復用需求,動態切換其內部的數據分發、累加路徑與工作模式(如權重固定、輸出固定數據流),以實現最優的計算效率。
普林斯頓大學N. Verma團隊于2021年在ISSCC上發表的一項研究設計了一種可擴展、可重構的數字存算核陣列[6]。該存內計算芯片在架構設計時引入2×2核心陣列模塊(CIMU),通過控制模塊間的數據流通路、改變輸入輸出擴展等方法動態調整存算核的計算模式,以支持神經網絡模型內不同層的空間映射。清華大學尹首一教授團隊于2022年在ISSCC上發表的一項研究提出了一種可兼顧能效比、精度和靈活性的可重構數字存內計算芯片新范式[7]。如下圖所示,該存內計算芯片在架構設計時引入不同層次的可重構計算,算力高達29.2TFLOPS/W(BF16浮點精度下)和26.5TOPS/W(INT8精度下)。
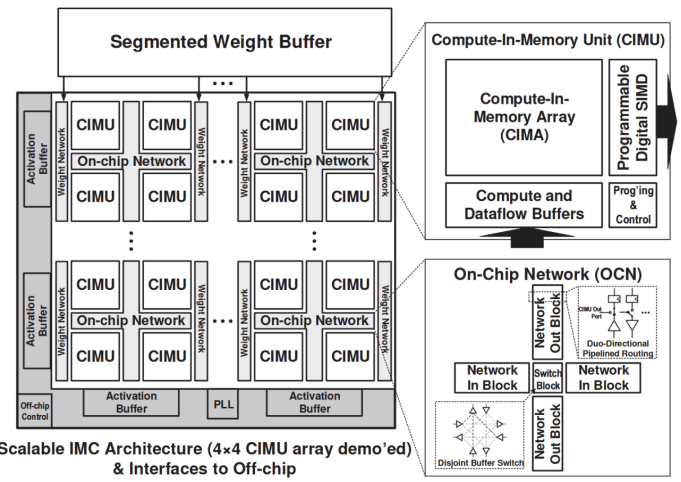
圖6?ISSCC 21 15.1提出的可重構計算宏
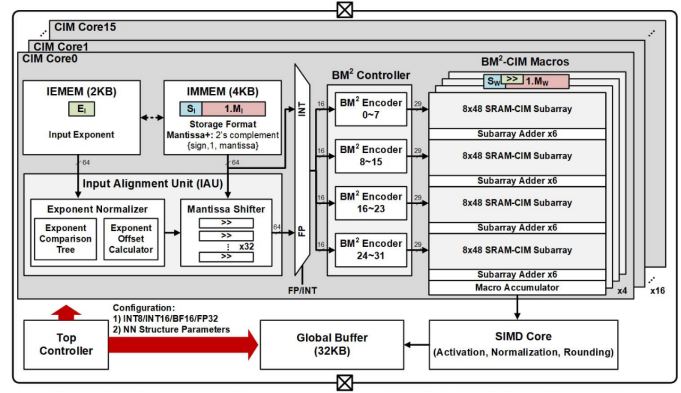
圖7?ISSCC 22 15.5提出的可重構計算宏
三、自適應彈性計算和浮點存算結合的優勢與風險
總的來說,自適應彈性加速與浮點存內計算的結合,旨在將存內計算強大的并行處理能力與彈性架構的智能適應性融為一體,為芯片的能效比、吞吐量、實用性帶來顯著提升,同時延長芯片的生命周期,從而設計出兼具極致能效、強大性能與廣泛通用性的AI芯片。
首先,存內計算從物理層面極大減少了數據在存儲與計算單元間“往返跑”的巨大能耗,構筑了高能效的基石,自適應彈性架構則扮演了精明的管理者的角色,進一步優化能效表現。其次,存內計算天然具備大規模并行計算的能力,理論峰值性能極高。但不代表其處理復雜多變任務時擁有優秀的有效性能,自適應彈性正是提升有效性能的關鍵。此外,AI領域的發展一日千里,算法的迭代速度遠超硬件的更新周期。正如前文所述,可重構功能使得當新的神經網絡算子或模型架構出現時,無需重新設計芯片,只通過更新編譯器和固件,就能重新配置硬件的數據通路和計算模式,高效地適應新算法。這賦予了芯片未來適應性,使其免于“一代算法,一代芯片”的窘境。
然而,為了實現這一美好愿景,當前在芯片設計和制造上,還面臨諸多挑戰。
存內計算高能效的前提是數據盡可能地存儲在片上存儲單元中,這使得存內計算芯片相比于傳統芯片,擁有更大的片上存儲容量。在此基礎上,浮點計算單元、可重構單元和彈性控制相關的電路會進一步增加芯片面積,提升流片成本,并且片上邏輯的復雜化也會影響流片成功率。此外,自適應彈性計算為芯片提供了高靈活性,為了充分利用它,編譯器需要建立一個能精確預測所有彈性狀態下(不同精度、不同數據流、不同資源配置)性能和功耗的模型,對“如何進行最優的數據映射、指令調度和精度選擇”等問題進行決策,這是一個巨大的組合優化問題。
因此,我們應在實現高精度存內計算的路上努力擁抱自適應彈性計算等先進設計理念,同時積極應對其帶來的風險。
參考資料
- big.LITTLE&DynamIQ-阿里云開發者社區
- M1 Pro 與 M1 Max 隆重登場:Apple 迄今打造的最強芯片 - Apple (中國大陸)
- 知存官網
- Khwa, Win-San, et al. "34.2 a 16nm 96Kb integer/floating-point dual-mode-gain-cell-computing-in-memory macro achieving 73.3-163.3 TOPS/W and 33.2-91.2 TFLOPS/W for AI-edge devices."?2024 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 67. IEEE, 2024.
- Yue, Zhiheng, et al. "14.4 A 51.6 TFLOPs/W Full-Datapath CIM Macro Approaching Sparsity Bound and< 2-30 Loss for Compound AI."?2025 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 68. IEEE, 2025.
- Jia, Hongyang, et al. "15.1 a programmable neural-network inference accelerator based on scalable in-memory computing."?2021 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 64. IEEE, 2021.
- Tu, Fengbin, et al. "A 28nm 29.2 TFLOPS/W BF16 and 36.5 TOPS/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise in-memory booth multiplication for cloud deep learning acceleration."?2022 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 65. IEEE, 2022.








)






)


)
