本篇摘要
- 本篇將介紹何為
HTTP協議,以及它的請求與答復信息的格式(請求行,請求包頭,正文等),對一些比較重要的部分來展開講解,其他不常用的即一概而過,從靜態網頁到動態網頁的過渡,最后底層基于TCP實現簡單的HTTP服務器的代碼編寫構建一個簡單的網頁(包含對應的跳轉,重定向,動態交互等功能),采取邊講解http結構邊用代碼形成效果展示的形式進行講解,望有助!


歡迎拜訪: 點擊進入博主主頁
本篇主題: 探秘HTTP應用層那些事兒!
制作日期: 2025.07.21
隸屬專欄: 點擊進入所屬Linux專欄
本文將要介紹的內容的大致流程圖如下:
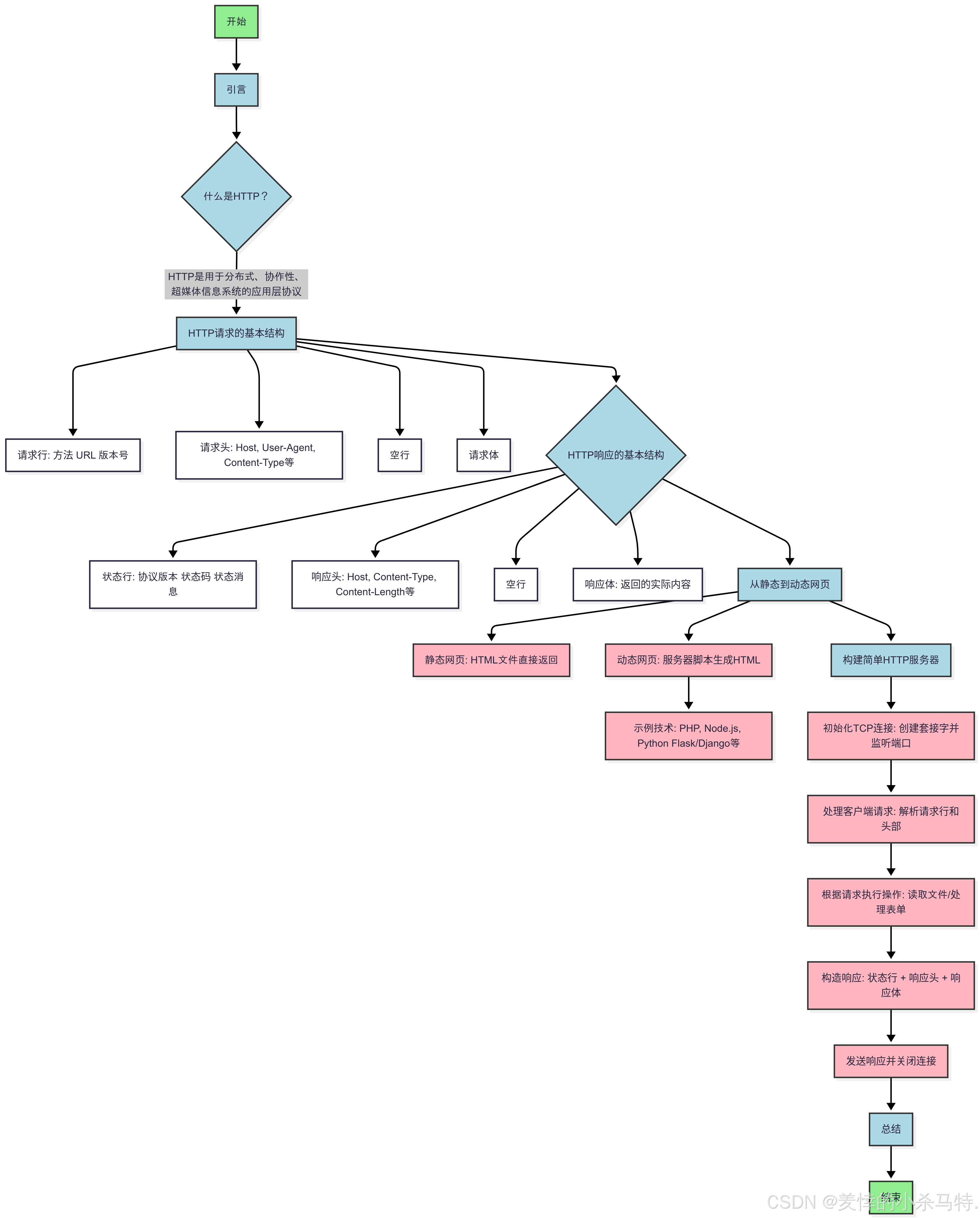
一· 認識HTTP
-
在互聯網世界中, HTTP(HyperText Transfer Protocol,
超文本傳輸協議) 是一個至關重要的協議。 它定義了客戶端(如瀏覽器) 與服務器之間如何通信, 以交換或傳輸超文本(如 HTML 文檔) 。 -
HTTP 協議是客戶端與服務器之間通信的基礎。
-
客戶端通過
HTTP 協議向服務器發送請求, 服務器收到請求后處理并返回響應。 HTTP 協議是一個無連接、 無狀態的協議, 即每次請求都需要建立新的連接, 且服務器不會保存客戶端的狀態信息(后面我們詳細講解)。
我們要明白:
- 我們上網要么從
遠端拿數據,要么上傳數據到遠端(數據:短視頻,視頻,網頁,圖片,音頻)。
本質:
- 訪問遠端linux服務器的
某個文件等(底層走的還是TCP那套邏輯)。
1.1認識URL
- 其實就是我們平時說的
網址!
下面就拿我的博客的URL為例說明:
https://blog.csdn.net/2401_82648291?spm=1010.2135.3001.5343
詳細解釋如圖:

解釋:我們輸入網址進行訪問(http協議)就是拿著指定ip+port連接到具體主機的具進程(類似我們之前寫的服務器)﹔然后瀏覽器把路徑按照規定進行編碼(特殊字符)然后這個符合要求的uri(路徑)發送給指定進程;再由這個進程執行完(找到對應內容或者進行對應方法執行)把結果返回來!
陪一張標準的介紹:

1.2urlencode與urldecode
-
這里
有些字符不能隨意出現.比如, 某個參數中需要帶有這些特殊字符(/ 或者?), 就必須先對特殊字符進行轉義。 -
將需要轉碼的字符轉為
16 進制, 然后從右到左, 取 4 位(不足 4 位直接處理), 每 2 位做一位, 前面加上%, 編碼成%XY 格式。
比如:

1.3 HTTP 協議請求與響應格式
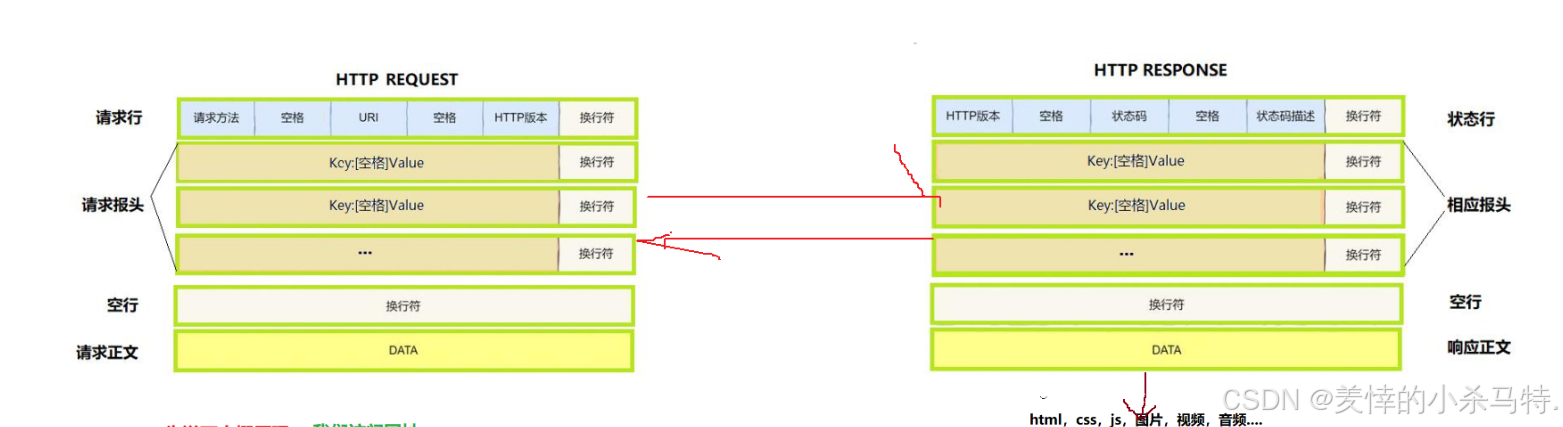
下面簡單認識下http結構:

- 注意:http協議,序列和反序列化用的是特殊字符進行子串拼接,且
不依賴任何第三方庫。
下面形象看一下:
-
http請求,攜帶的數據(可選,
不是所有的http請求,都會攜帶數據)。 -
我們之后拆解進行解析的時候,
把它看做一個長的字符串!
認識 http的請求以及回復
先放圖:
原理解釋:
- 首先瀏覽器把對應的域名進行轉化成ip然后–>對應的
ip+port就可以找到對應的服務器端進程了;接著把后面跟的具體路徑(uri)內容(也可以空)等進行填充請求報頭;是get還是post(請求方法);然后按照上面的request的格式打包之后成一個長的字符串;然后發送給服務端;服務端就要進行解析;根據uri具體位置把內容拿出來放到自己的響應正文里(html);最后序列化發回去;剩下就是瀏覽器提取進行先關轉化!!!
粗力度說一下如何序列化和反序列化
解析request
- 這段字符串由
瀏覽器構建。 - 報頭就是利用
哈希表的K-V結構儲存。
如何進行解析出來:
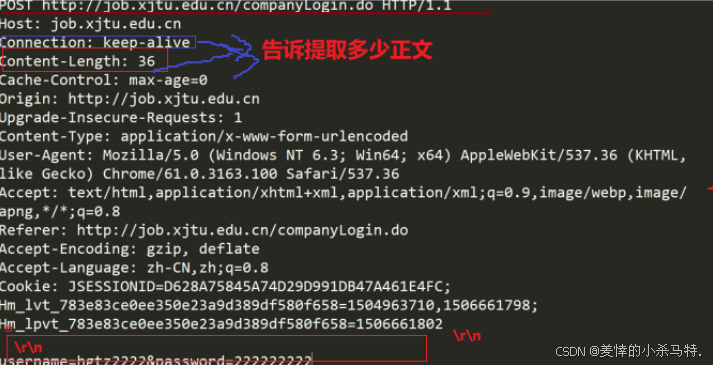
- 我們直接對這個長串進行找
\r\n(第一個)來成功提取請求行,把請求方法/版本/uri解析出來(第一個都找不到就是無效的http請求了)。 - 然后依次一行行讀取,發現是
空行,然后找到對應的Content-Length的長度,對應讀取下一行(千萬不要再繼續按照上面要求讀取因為最后一行無\r\n)
構建response
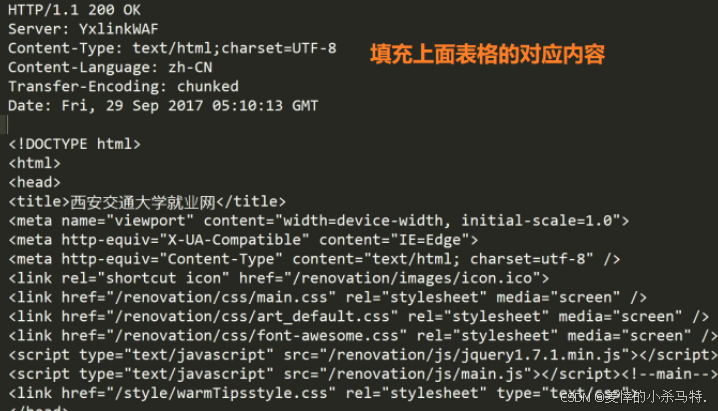
- 查找uri獲得對應的
響應正文。 - 根據相關信息填寫請求行以及報頭。
- 拼接成
長字符串。
剩下的就交給瀏覽器自己轉義即可!
1.4 剖析request與response的組成部分
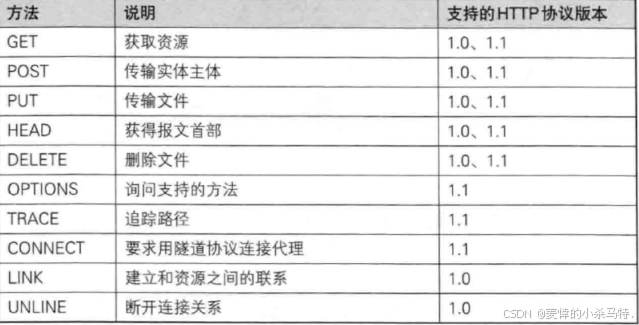
認識請求方法:
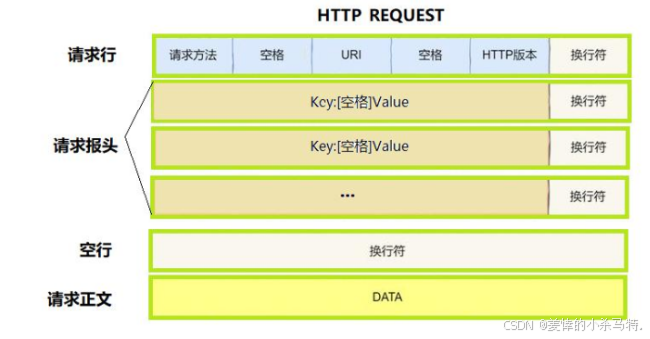
這里我們主要介紹的是POST和GET方法,代碼演示也是用他倆。
GET
- 用途: 用于請求 URL 指定的資源。
- 示例: GET /index.html HTTP/1.1。
- 特性: 指定資源經服務器端解析后返回響應內容。
- form 表單: https://www.runoob.com/html/html-forms.html。
代碼書寫也是先以get為例,簡單來說就是獲取對應資源!
POST
- 用途: 用于傳輸實體的主體, 通常用于提交表單數據。
- 示例: POST /submit.cgi HTTP/1.1。
- 特性: 可以發送大量的數據給服務器, 并且數據包含在請求體中。
- form 表單: https://www.runoob.com/html/html-forms.html。
當然了,還有PUT(推送數據到服務端) HEAD(只返回相應頭) DELETE (刪除服務端數據)OPTIONS(查詢URL指定資源)等,這些不常用,這里就不講解了。
陪一張圖:
認識URI
下面我們利用圖片通俗易懂來認識下:

輸入對應的web根目錄(/)

這個路徑就是uri,然后服務端就會對應位置找到資源,返回給我們:
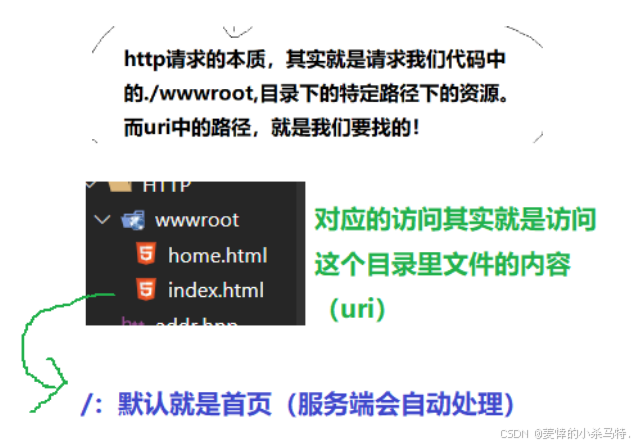
- 注意:
'/ '不是Linux 根目錄,是Linux服務器的一個web目錄(wwwroot),資源都放在這個目錄下(如果路徑不是/,服務器自動拼接首頁)。
因此:
- 我們在瀏覽器段請求的時候,
首頁作為站點的入口,一個網站就是一顆多叉樹,點擊鏈接的時候,瀏覽器會形成新的訪問地址,發起二次請求。
下面我們來驗證下:
- 我們先輸入網址進入網頁:
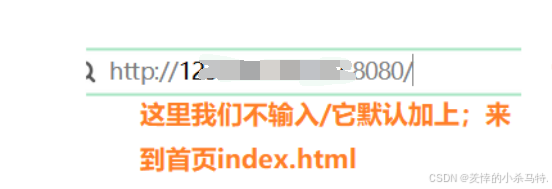
- 然后我們進行點擊,他就會訪問到我們web目錄(wwwroot)的home.html內容發給瀏覽器進行轉義,瀏覽器自動識別點擊處封裝的鏈接然后自動發送請求:
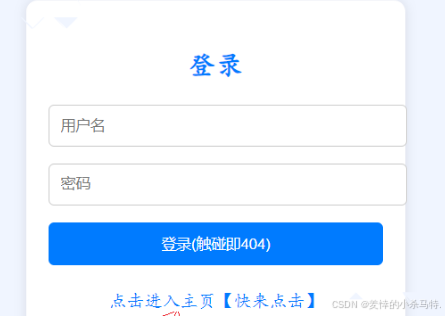
然后比如點擊了主頁:
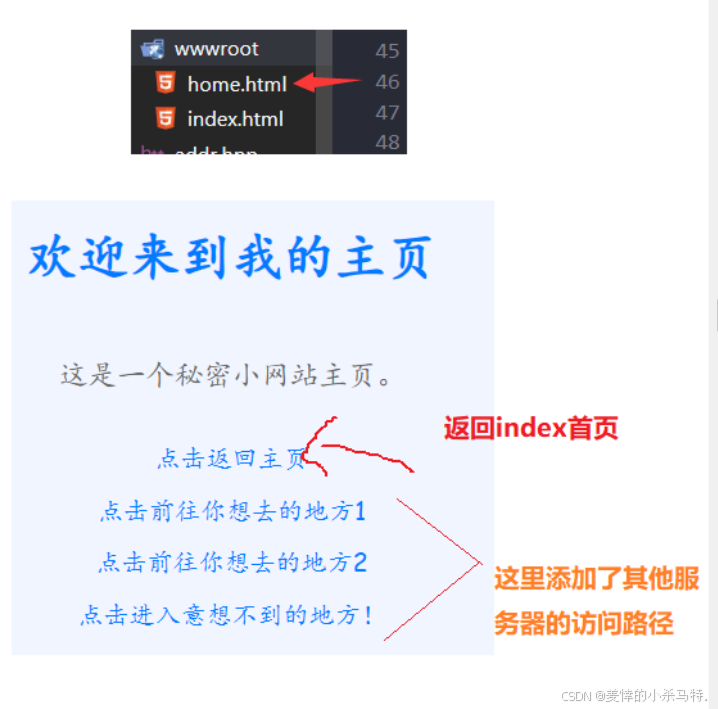
總結下:
- uri就是對應服務器的某一web目錄下的一個路徑;當發起一定請求;服務端就會根據uri(特定)配合request的正文進行內容提取;然后構成響應正文最后發給瀏覽器進行轉義!
認識HTTP版本
-
這里就簡單理解成你是什么版本然后告訴服務端給你提供什么版本的服務。
-
比如你是
微信低版本的客戶端;然后給服務端發起請求:服務端識別到你的http的版本是低的就提供給你低版本服務(這里對于一些app應用也可以理解成是被限制的瀏覽器,其實也是發送http的網頁請求)。
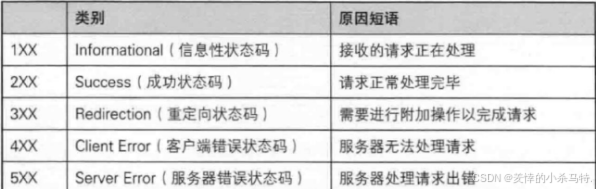
認識狀態碼描述
HTTP狀態碼:
詳細版:
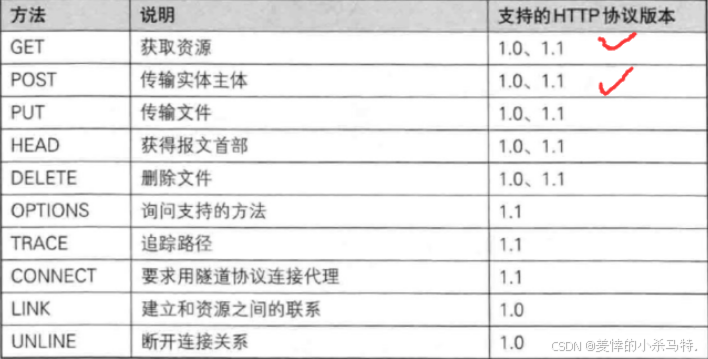
| 狀態碼 | 英文名稱 | 含義解釋 |
|---|---|---|
| 200 | OK | 請求成功,服務器返回對應數據 |
| 201 | Created | 請求成功且創建了新資源 |
| 204 | No Content | 請求成功,但無內容返回 |
| 301 | Moved Permanently | 資源永久重定向到新地址 |
| 302 | Found | 資源臨時重定向到新地址 |
| 304 | Not Modified | 資源未修改,可直接使用緩存 |
| 400 | Bad Request | 客戶端請求語法錯誤 |
| 401 | Unauthorized | 請求需要身份認證,未授權 |
| 403 | Forbidden | 服務器拒絕請求,無訪問權限 |
| 404 | Not Found | 服務器找不到請求的資源 |
| 500 | Internal Server Error | 服務器內部錯誤,處理請求失敗 |
| 502 | Bad Gateway | 網關錯誤,代理服務器獲取響應失敗 |
| 503 | Service Unavailable | 服務器暫時不可用,可能因維護或過載 |
- 最常見的狀態碼:
比如200(OK),404(NotFound),403(Forbidden),302(Redirect重定向), 504(Bad Gateway),我們暫時只需要了解這些即可。
認識HTTP 常見 Header
首先我們先認識下客戶端收到答復是如何解析的:

如何提取相應正文:
- 響應文也可以是無內容的,如果是有內容那么一定會在Content-length加上長度再給用戶的;因此用戶就找空格然后看對應的Content-length大小進行提取響應正文進行轉義即可。
陪一張header表:
| 字段名 | 含義 |
|---|---|
| Content-Type | 數據類型(如 text/html 等) |
| Content-Length | Body 的長度(單位為比特) |
| Host | 客戶端告知服務器,所請求的資源是在哪個主機的哪個端口上 |
| User-Agent | 聲明用戶的操作系統和瀏覽器版本信息 |
| referer | 當前頁面是從哪個頁面跳轉過來的 |
| Location | 搭配 3xx 狀態碼使用,告訴客戶端接下來要去哪里訪問 |
| Cookie | 用于在客戶端存儲少量信息,通常用于實現會話(session)的功能 |
下面我們就先來認識Content-Length,Content-type,Connection這幾個報頭為主來講解:
- Content-Type:數
據類型(text/html等)對應的后綴比如png mp4等都對應的有不同類型(這里我們直接截取后綴進行判斷添加即可)。 - Content-Length: Body 的長度這里可以考慮讀取文件的時候調用:
1·c++文件操作/2·系統自帶的stat函數。
那么下面我們根據這倆個報頭給我們之前寫的http答復添加上:
大致思路:
- 服務端收到答復通過解析獲得的路徑去讀取文件:如果讀到就構建響應正文+正確碼以及解釋+報頭之長度,正文類型等;如果失敗就把路徑修改成對應的404所在的文件,讓它作為正文被返回,同理報頭等那些也都是404對應相關的了。
注意:
- 讀文件的時候(有可能不都是文本,比如二進制的圖片之類的)進行二進制讀取,一口氣讀完。
// 讀取對應路徑下的html:static bool readfile(std::string &text, std::string tar){ // 1·文本讀取(比如讀取圖片等可能會遇到\n等符號導致讀取中斷直接換行等當前行后面內容就無法讀到,導致錯誤):// std::ifstream in(tar.c_str());// if (!in.is_open())// return false;// std::string line;// while (std::getline(in, line))// { // 使用getline讀取的時候每次會將line情況在讀取// text += line;// }// in.close();// return true;// 2·二進制讀取:std::ifstream in(tar.c_str());if (!in.is_open())return false;int size=filesize(tar);text.resize(size);in.read((char*)text.c_str(),size);//這里string不能強轉char*因此可先調用c_strreturn true;}
- 判斷文件大小的兩種方式:
static int filesize(string file){ //c++文件io方法:// ifstream in(file);// if (!in.is_open())// return 0;// in.seekg(0, in.end);// int size = in.tellg();// in.seekg(0, in.beg);// in.close();// return size;//系統調用:struct stat buff;int s = stat(file.c_str(), &buff);return buff.st_size;}
- 重點來了:
有個非常陰險的bug:
就是每次瀏覽器開一個新頁面就會先向對應的服務端請求(/favicon.ico 一個文件)里面是那個小圖標。

我們必須對它進行忽略處理:

比如我么我們第一次連接到主頁的時候:
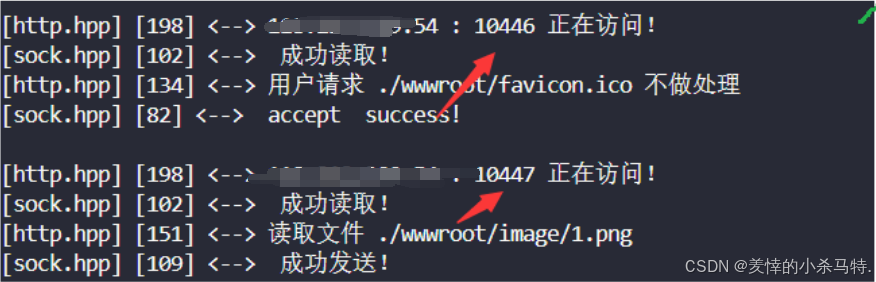
此外還建議,讀取的時候數組開大一點(因為這里我們是默認它可以把請求都讀上來的,忽略了其他情況)

解釋下原理:
瀏覽器會請求這個圖標也就是會也就是
Accept請求頭會有對應的關于/favicon.ico對應的類型;然后如果我們還是上面的邏輯找不到就404的話(之前就可以,但是現在我們報頭會返回類型這樣就導致類型不匹配了,因此會出現問題)那么請求如果是它,此時我們在答復的時候就必須返回對應的類型的響應正文以及對應的Content-type是image/x-icon這個類型,否則瀏覽器就會爆出類型不匹配從而出錯,因此問題就在于這個請求頭的Accept與答復的Content-type及響應正文之間的不匹配問題,故對于這個圖標的請求我們采取忽略不處理,“不理這個請求圖標的進程了!”
因此:
- 我們對服務端收到的uri為這個路徑的請求
直接忽略即可(這里瀏覽器多個請求訪問其實是多個多個不同進程去訪問的,也就是ip同port不同,因此服務端直接對發它的進程忽略不回復;接著對其他進程的請求再做答復即可)。
根據此處小結一下:
- 對于客戶端(瀏覽器)請求如果對應的報頭比如content-type等;是空的那么服務端返回的如果不是空是可以匹配的(客戶端默認)﹔但是如果客戶端發送的正文已知一些報頭的類型;但是服務端返回來的是不匹配的;客戶端直接報錯(瀏覽器無法解釋)。
下面我們根據我們制作的基于http的小網站的請求驗證一下:

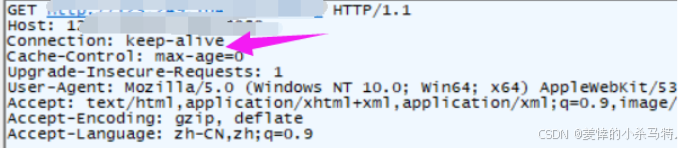
- 下面再說一下Connection報頭:
-
HTTP 中的 connection 字段是 HTTP 報文頭的一部分,它主要用于
控制和管理客戶端與服務器之間的連接狀態。 -
HTTP/1.1:在 HTTP/1.1協議中,默認使用持久連接。當客戶端和服務器都不明確指定關閉連接時,連接將保持打開狀態,以便后續的請求和響應可以復用同一個連接。 -
HTTP/1.0:在 HTTP/1.0 協議中,默認連接是非持久的。如果希望在HTTP/1.0上實現持久連接,需要在請求頭中顯式設置Connection:keep-alive。 -
如何使用的 :
Connection:keep-alive:表示希望保持連接以復用TCP 連接,Connection:close:表示請求/響應完成后,應該關閉TCP 連接。
這里就涉及到長短連接了:
-
長連接:就是只需要
connect和accept一次,客戶端和服務端就直接收發消息即可。
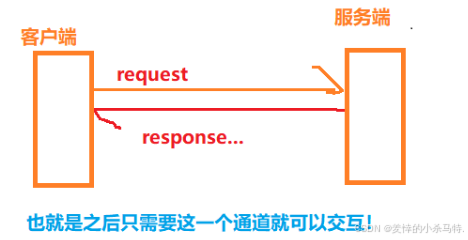
-
短連接:就是每次都要connect和accept(比如我們自己實現的那個簡單http服務器)。
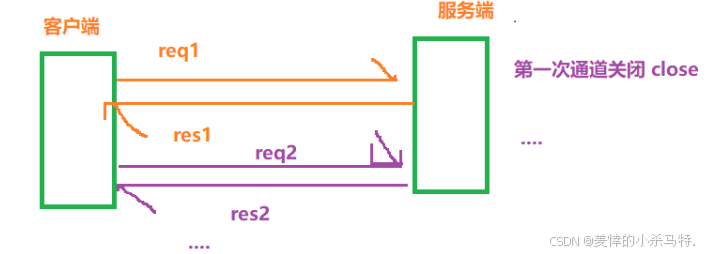
下面我們舉些例子來看一下:
我們自己寫的http服務器它就是短連接。
請求:
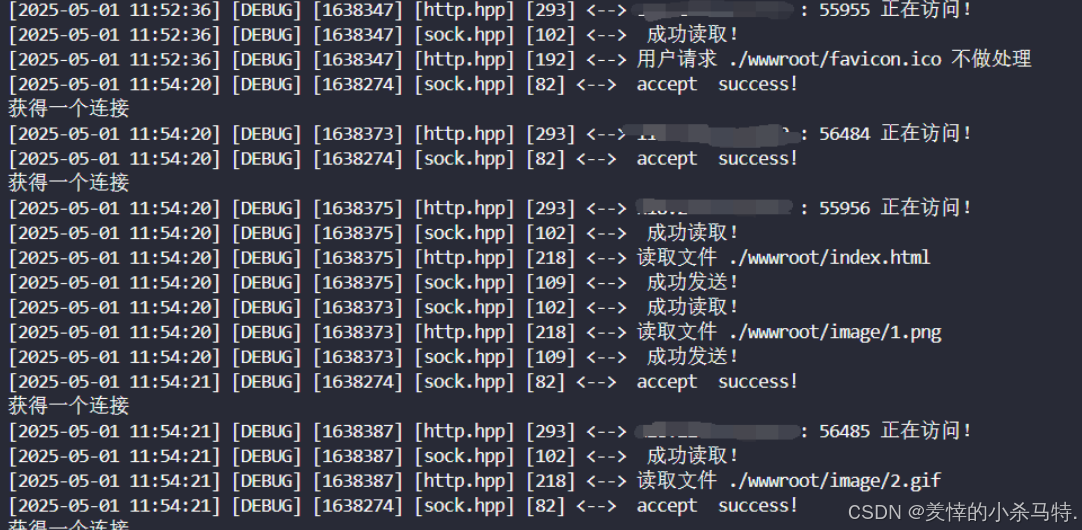
可以看到每次都要重新連接,故最后還是短連接!
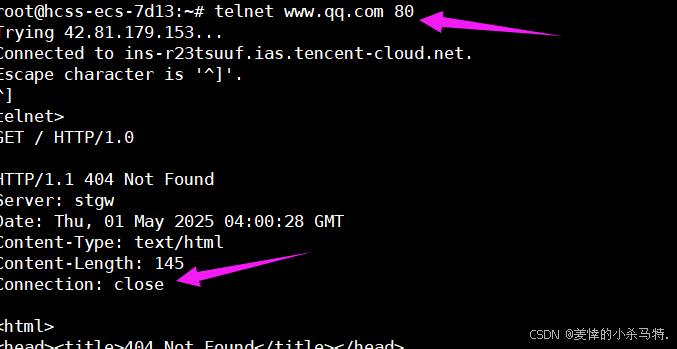
- 訪問qq新聞官網,使用1.0版本,就不支持長連接而且失敗,因為telnet只支持http但是訪問你的它是支持https:
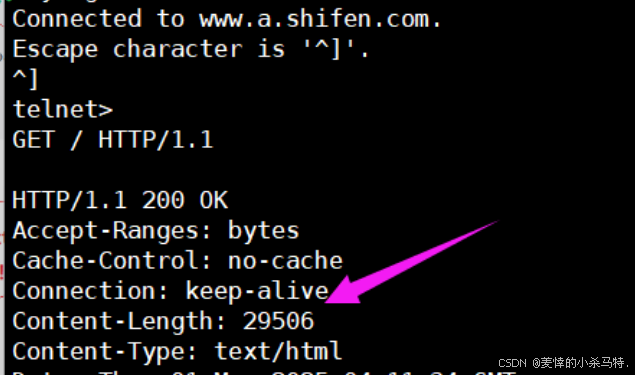
- 這里比如百度就支持了http;而且發送的1.1默認就是長連接,雙方達成協議:
總結下:
發送請求的時候,前提是客戶端(瀏覽器)要支持長連接,然后發送1.1,告訴服務端要進行長連接,
最后協商后才是長連接,否則就默認短連接了(這里注意互相支持的協議應該相同)。
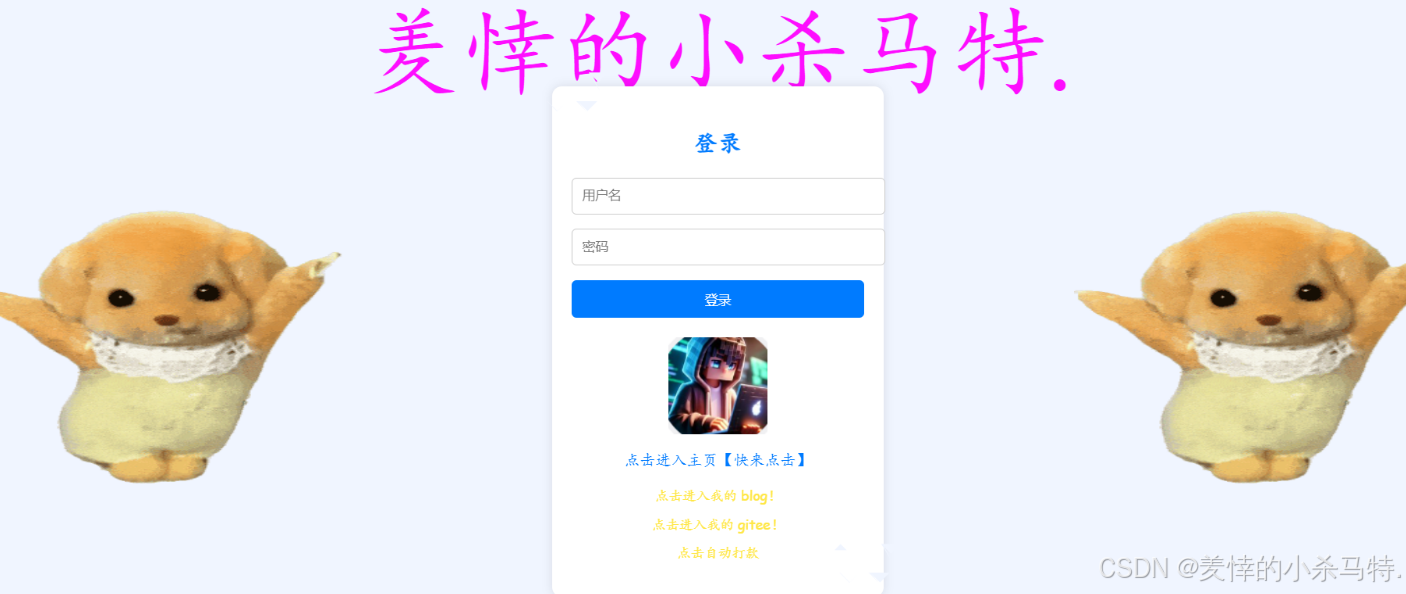
基于我們模擬實現的簡單的http服務器訪問與應答原理分析:
- 首先我們訪問對應的ip+8080默認進入我們的/:web的首頁也就是index:
- 下面看一下首頁對應的html:
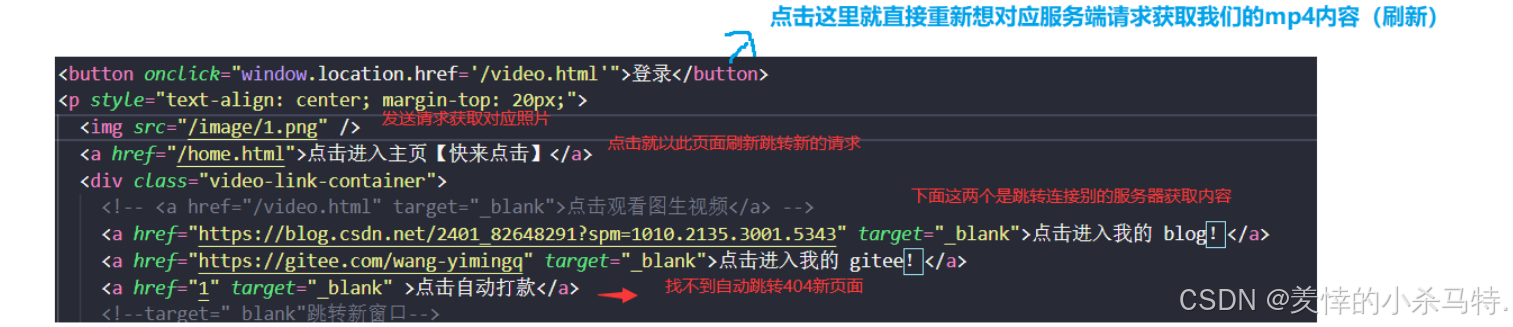
- 我們點擊就自然會進行一下頁面跳轉;比如點擊登錄,此時瀏覽器就會識別到然后重新給服務端發送對應的href對應的請求,訪問對應文件:
video頁面
- 下面比如說我們點擊了 自動打款這個選項:瀏覽器就會自動找對應web首頁的1文件;服務端解析后發現找不到就直接構建404文件返回給瀏覽器然后被它轉義,于是我們就看到了:

不過,目前我們訪問的資源全是以靜態資源形式呈現的(文件)。
小結一下:
給我們之前的http服務器簡單添加了兩個報頭分別是Content-type和Content-length;其次就是對于那個
小圖標特判一下,接著裁是理解不同htm文件里的的轉關系:其實就是瀏優差再次選一個進程向同一個服務端訪間;有的是直接在當前頁面展現出來,有的就是直接刷新當前頁面進行顯示(比如a標簽),還有的是跳轉新頁面進行展示–>歸根結底,還是瀏覽器重新構建請求發送給服務器而已! ! !
telnet與wget指令
telnet
使用telent前提是安裝后,把自己對應服務器的端口開放,防火墻關閉!
首先,我們需要知道:
-
首先如果沒有開放云服務器的端口的話拿公網的話,訪向云服務器會被拒絕;因此之前tcp/udp模擬拿的比如是本地環回就是本地通信不涉及網絡;如果是子網ip的話;是云服務器下發的ip(云服務器所在局域對應的內部ip),云服務器默認是接收的。
-
如果自己的云服務器開通端口后就允許外部的設備拿著對應的公網ip+port(對應自己云服務器主機標志)進行訪問,由于存在風險;故需要對應的云服務器開放對應端口來支持訪問才行。
-
因為我們開放了云服務器端口,因此被允許了,然后發送請求找到云服務器內執行的main程序,進行底層的tcp連接:成功后就可以進行發送請求,即基于tcp的通信了。
進行安裝telnet:
sudo apt install telnet
- 使用注意事項:使用的時候就是
telent ip port然后ctrl+]然后再回車即輸入訪問的網址或者請求即可,q為退出。
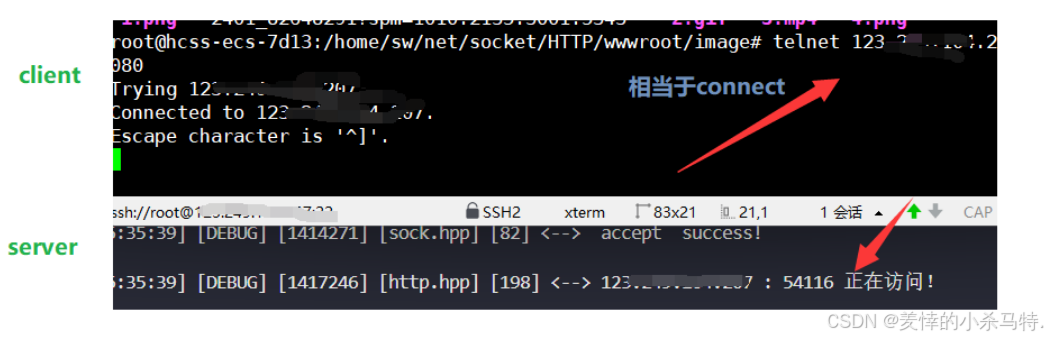
- 這里我們就用telnet進行連接我們的http服務器了。
- 進行訪問首頁:
client界面 :
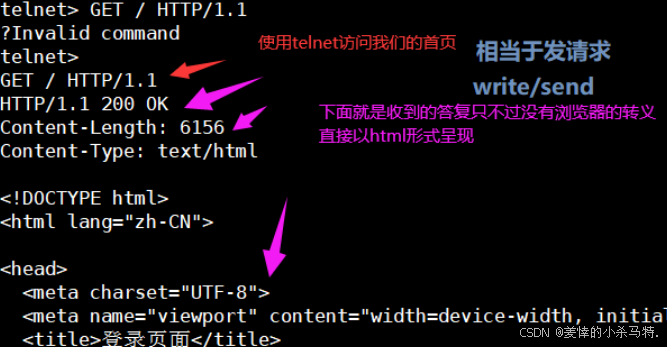
server界面:

- 下面我們試著訪問下百度的網頁:

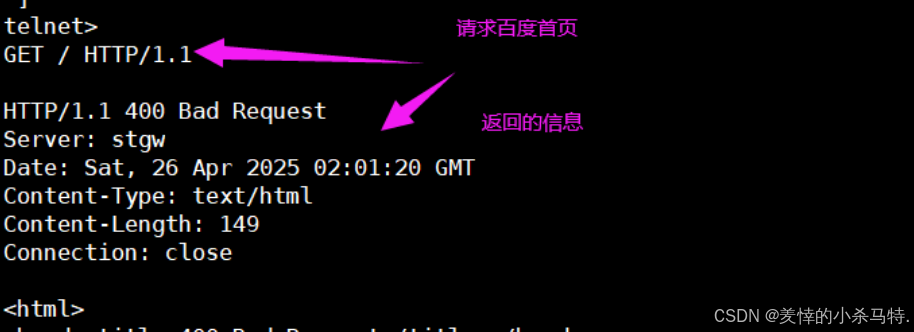
wget
-
解釋:獲取對應的網址對應的云服務器內的
web首頁里對應文件內容+名稱,下載到本地(爬蟲)一些網站有反爬機制明確禁止。 -
安裝指令:
sudo apt-get update
sudo apt-get install wget
演示效果:
下面我們抓取-下qq新聞頁面:
進行爬取:
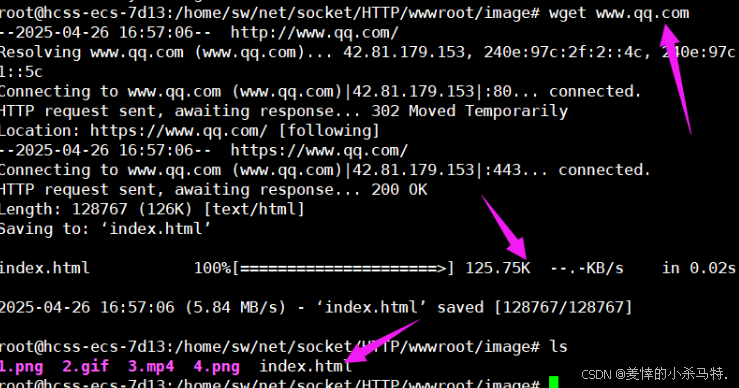
爬取結果:
再探狀態碼: 重定向之永久重定向(301)+臨時重定向(302)
- 舉個通俗易懂的例子:
比如學校南門開了個超市,但是超市臨時搬到了北門,因此就會在原來南門的位置搞個告示,這樣學生們就看到了直接去北門了–>(
臨時重定向)302+location!但是如果超市由于北門生意好,就搬到北門不回來了,因此它就會在原來南門的地方貼個告示說永久到北門–>(永久重定向)301+location!
- 下面我們畫個
client-server圖形象理解下:
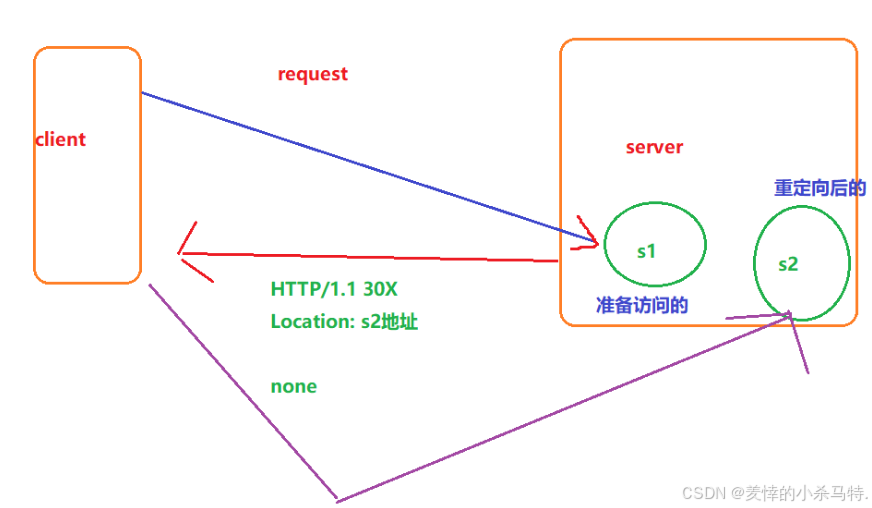
- 這里就是客戶(瀏覽器)給服務端發送訪問s1的請求;但是原先的位置的內容不存在(被服務端重定向了);因此當client訪問s1資源的時候,服務端判斷重定向返回對應的s2地址給client(然后client拿到后就去訪問),這樣就完成了重定向!
這里永久重定向主要是針對搜索引擎的,因為它要保證拿到對應公司網址的是最新的,因此需要記錄下來之前被重定向的資源的新地址!!!
- 比如這里我們
漢語搜索qq新聞,瀏覽器搜索引擎要能保證上面的這點,及時抓取對應的網址:
下面那我們實現的http網站演示下效果:
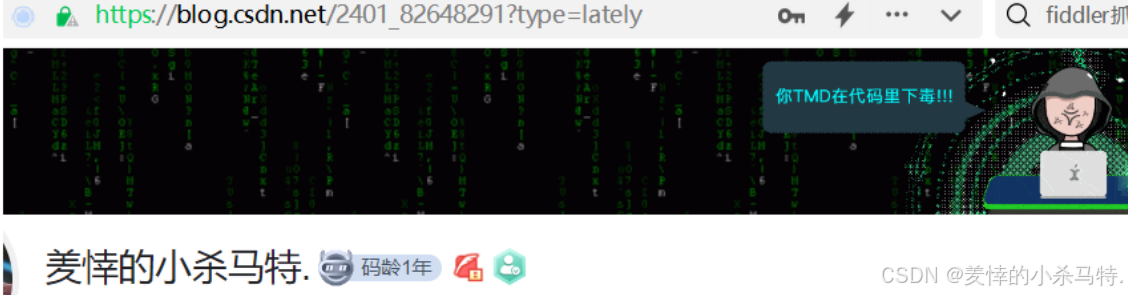
- 這里只要我們搜索這個路徑的資源就會被永久重定向:
301
if (_route == "./wwwroot/redirect"){setcode(301); // 永久重定向:第一次被瀏覽器記錄保存,剩下的再訪問就直接到location目的網址訪問setheader("Location", "https://blog.csdn.net/2401_82648291?type=lately");return true;}
- 對于
301的永久重定向也是一樣的,只不過這個瀏覽器不會記錄,但是永久的會記錄,到時候直接去那個地方即可(我們的屬于短連接,每次請求完畢都會斷開)效果不明顯。
效果:

被永久重定向了:
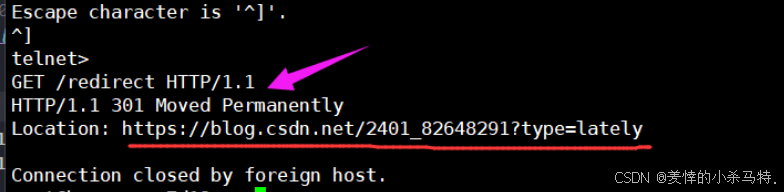
- telnet一下也發現被返回的location,然后瀏覽器拿著這個
location的新地址去訪問新的地方:
- 測試下
302:
if (!ans){ setcode(302); // 臨時重定向,每次訪問到指定網址就拿到對應的location里的網址進行訪問,瀏覽器不進行保存!setheader("Location""http://123.249.104.207:8080/404.html");}
- 我們訪問的我們自己服務端沒有的路徑文件,就會被返回302重定向:

- 被臨時重定向到404文件了:

telent查看:

因此總結下:
重定向就是在response的Location處放上對應的網址,還有些其他操作等等,沒有響應正文。
重識請求方法之GET與POST
- GET:
獲取資源(圖片,視頻,音頻,網頁… 靜態資源),這里也可以上傳類似post功能但是,uri是含參數的! - POST:
上傳資源,比如登錄的時候上傳賬號+密碼;然后服務端對應根據它進行相應的服務–>動態的(進行了交互)!
舉個例子:


- 這里就是我們登錄的首頁,我們輸入賬號和密碼就是上傳數據就會和服務端
進行交互,這里用的是post請求,服務端通過對應的正文拿到賬號和密碼,后執行login服務(服務端自己定義的),比如訪問對應賬號密碼下的資源。
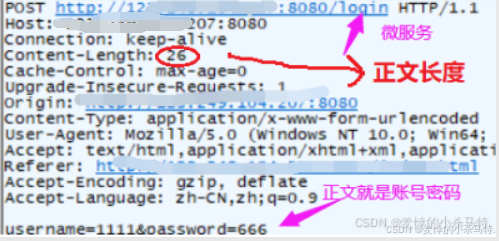
1· 下面我們看一下利用post的請求與應答:
請求:
應答:
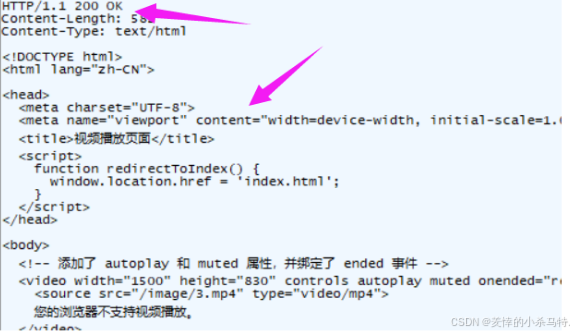
- 此時,瀏覽器會自動識別我們的輸入然后進行轉化成正文,構建請求發送,接著服務端收到后會執行login對應的服務然后返回正文。
下面看下我們的效果:
-
我們設置的這個服務是只要密碼正確就會進行視頻播放貢面,因此我們判斷到是post請求后直接提取正文把密碼拿到,然后進行對應
login服務(RESTful風格的網絡接口!)進行匹配構建應答即可! -
輸入密碼:
-
進行跳轉:
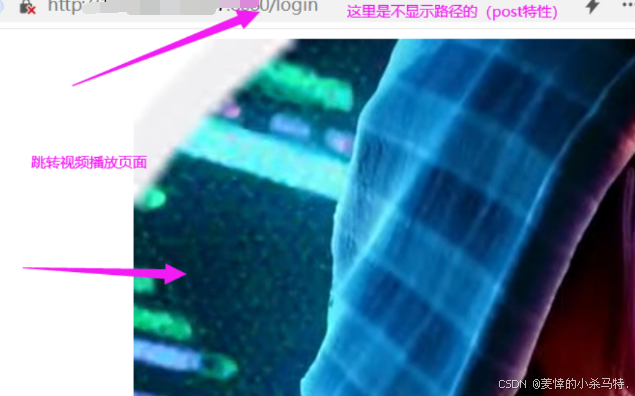
2·GET請求與應答驗證:
- 這里之前我們用的get都是靜態的(沒有交互的),也就是直接訪問對應路徑下的文件,但是下面我們就要給它對應的uri加上參數!
這里修改成get那么瀏覽器識別輸入后就會按照get請求構建請求:

- 這里也是同理我們從uri的參數中提取對應的賬號密碼傳給login服務,讓它匹配進行構建答復即可:
效果:
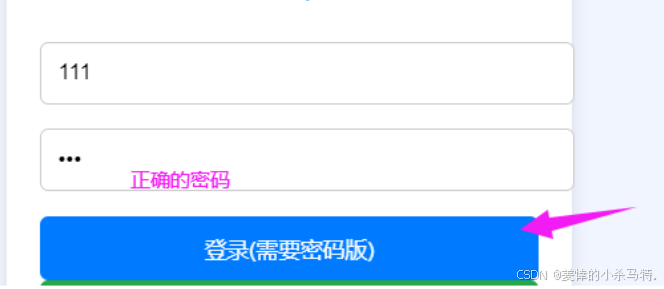
應答: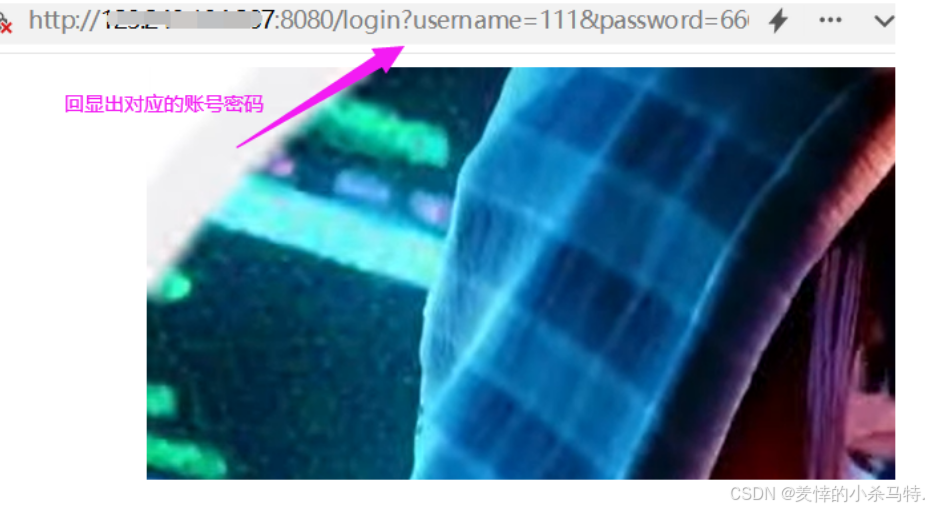
看一下我們抓包的結果:
請求:
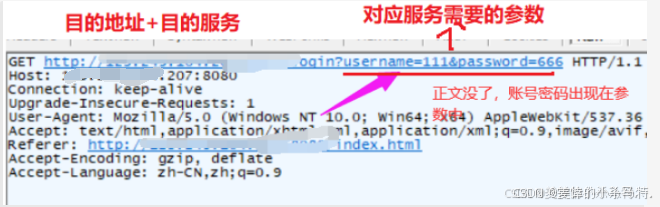
應答: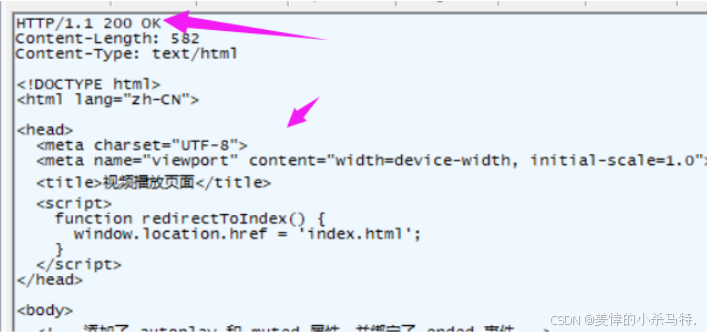
GET與POST特點總結:
GET:
- 獲得靜態網頁或者資源,加上參數可以獲取動態資源。
- 提交參數以uri形式提交。
- GET提交參數,不能過程,一般有長度限制。
- 參數會回顯(比如賬號密碼)。
POST:
- 獲得動態資源。
- 提交參數以正文形式提交。
- 正文傳遞,意味著長度可以很長。
- 不回顯,比較私密。
但是,它倆都不是安全的,以明文形式在網絡中傳遞,抓包就能獲取,其中,https(有加密)>post動態交互安全>get動態交互!
fiddler使用驗證GET與POST的不安全性
-
fiddler:一個抓取構建好的報文的軟件,fiddler抓到的報文,是已經被瀏覽器構建完畢的http請求,就是將來要發送到網絡中的。 -
下面我們模擬下這個過程:
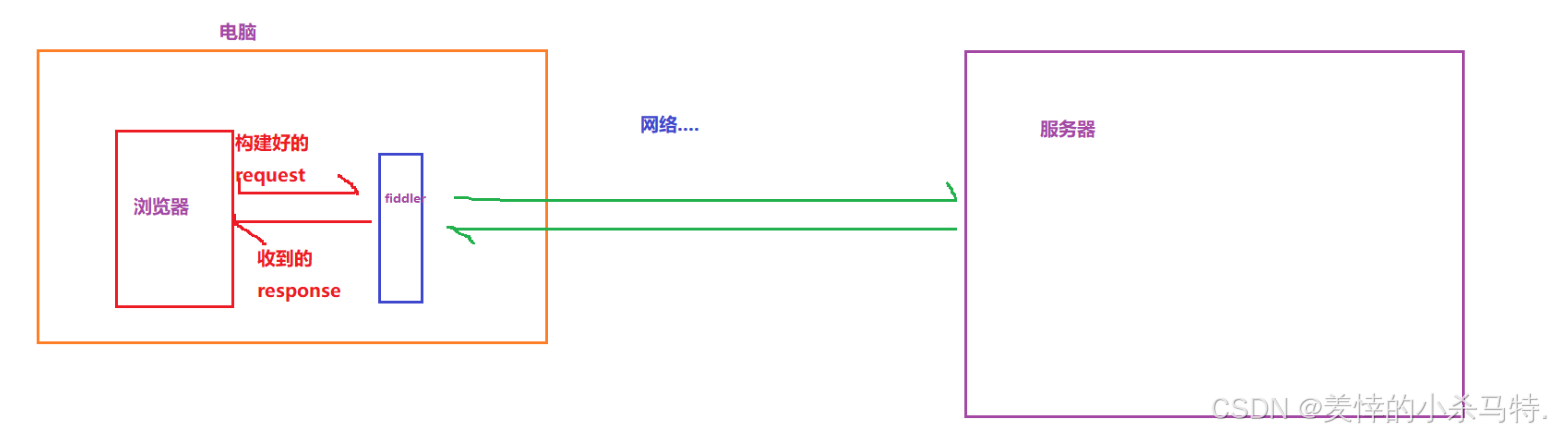
- 說自了就是這個fiddler帶著瀏覽器的請求以及服務器對應的應答在網絡中傳輸(相當于瀏覽器和服務器之間通信的“信使”)
它的存在不就暴露了某些信息嗎(尤其是post的比如登錄功能等)
使用流程:
- 首先,我們在官網安裝好
fiddler軟件,然后啟動: - 先進行清空,然后默認是可以抓取
http的包的!
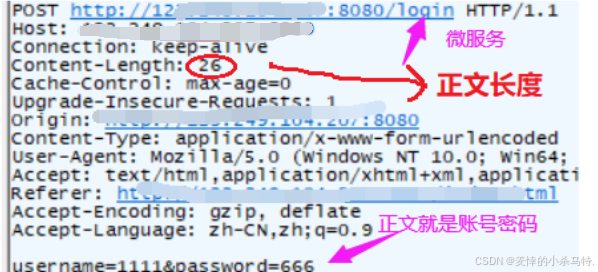
- 我們可以看到雖然post不會在網址欄回顯但是
這樣一抓取不就暴露密碼了嗎,因此說get和post都是不安全的(對http而言)!
一般這種密碼登錄類似功能在網絡中傳播都是被加密的–>用的是https,下面我們抓取下:
fiddler默認是只抓取http,對于https我們要自己設置:
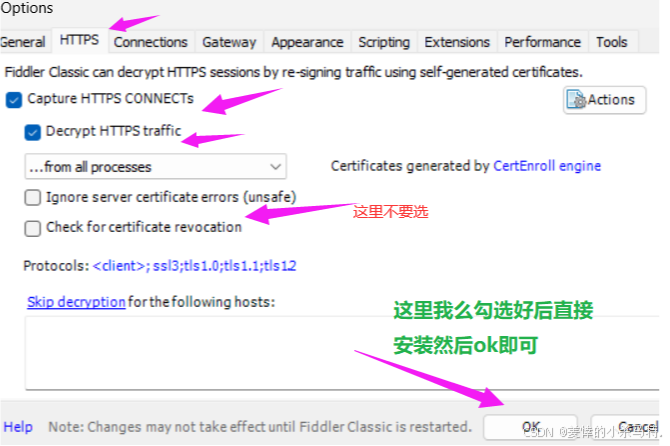
- 我們用用一個使用https協議發送請求的登錄頁面驗證下:
- 顯示抓包結果:
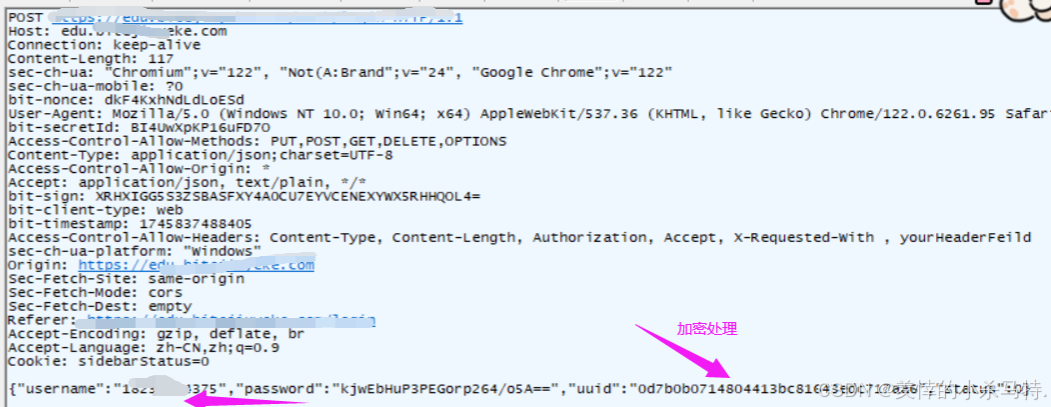
因此可以發現https是更加安全的!
重新認識HTTP
我們在上面說了這樣一句話:
HTTP 協議是一個無連接、 無狀態的協議, 即每次請求都需要建立新的連接, 且服務器不會保存客戶端的狀態信息。
1· 為什么說http是無連接?
可以理解成http位于應用層,是一個
應用層協議,底層的網絡層是基于tcp實現的,也就是tcp負責accept和connect,即對于長短連接是其底層tcp的說法,而它是只負責response和request的,即是沒有連接而言。
2· 為什么說http無狀態?
http本質就是一種“
文件”的服務器,比如每次我們請求它就是分析處理給我們找到對應文件然后發回來,自身是不會記錄任何數據的,更不會記錄客戶端的信息(比如登錄賬號訪問,那么你每次訪問都要登錄,但是這樣就造成了麻煩)。
淺淺認識cookie和session
cookie:
比如每次我們訪問網站看視頻都需要登錄,此時我們第一次登錄后,就可以看視頻了,但是下一次希望不在登錄就可以看,因此這就是
cookie機制(第一次登錄后,服務器驗證成功后,把對應的賬號密碼cookie返回瀏覽器儲存,然后下次繼續訪問網站看視頻,瀏覽器默認發送上對應的cookie,瀏覽器驗證后成功就直接重定向到視頻頁面而不是登錄頁面)!
如圖:
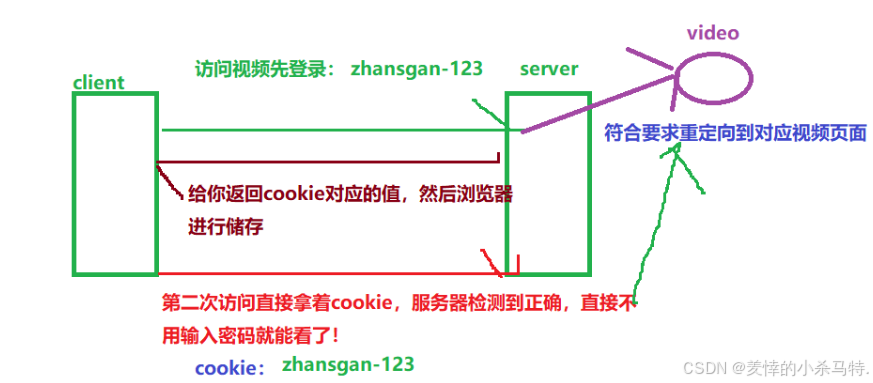
如何edge查找cookie信息:這里是儲存在文件里:
-
點開就能看到對應信息:
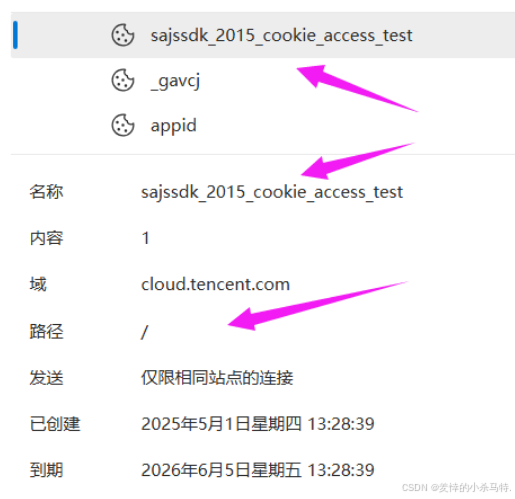
小結下: -
一般儲存在瀏覽器的文件或者內存中,但是文件中的可能性更大!
-
但是這樣有可能就會出現黑客盜取對應瀏覽器中的cookie信息,導致賬號密碼被盜!
-
因此下面session出現了。
session:
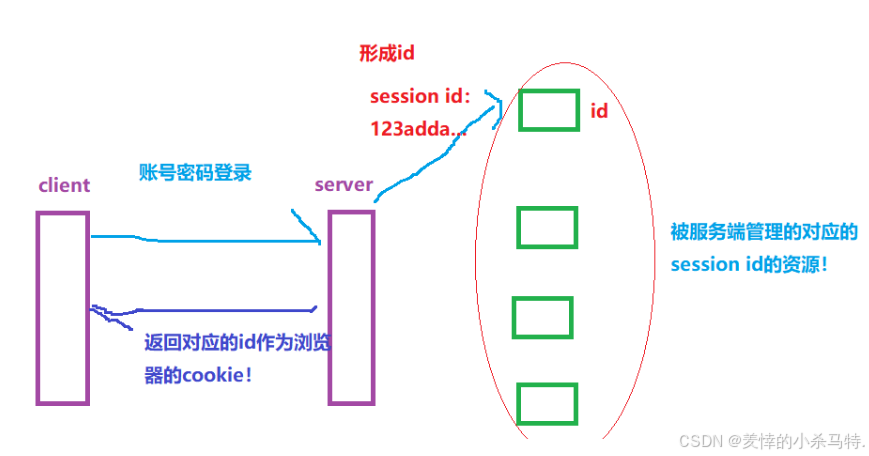
-
同理,再次訪問,瀏覽器會帶
上sessionid 去訪問某資源,當服務端看到這一資源的id或者沒有和對應cookie匹配,此時就重新登陸否則直接拿資源給它! -
此時就是,客戶端第一次請求服務端,服務端把客戶對應的賬號和密碼和一些其他信息進行一定編碼,然后
得到一個id,服務端拿著這個id給對應的用戶建立一個記錄(用戶訪問的一些資源),然后發給瀏覽器作為它的cookie,當下一次瀏覽器訪問這個服務器的時候,就會自動帶上這個id,然后服務器收到這個id就能找到對應的資源記錄了! -
比如用其他瀏覽器訪問這個服務器,cookie中沒有id就會自然重新建立了,但是如果是
被黑客盜取了,然后把這個id發給服務器,這樣它就能訪問之前用戶訪問的資源了,但是我們確實避免了黑客通過單純cookie盜號行為! -
這樣解決了黑客盜號問題,但是黑客還是可以訪問的,因此就是服務端的保護措施了:比如
過期時間,異常檢測,ip溯源,地址變更等!
-因此http引入的cookie與session就減低了它的無連接,無狀態的弊端!
如果想更深入了解cookie與session,有機會博主后再次更新專門一篇講解它倆!
二· 基于所學http相關概念實現簡單的http服務器
2.1 視頻效果展示
下面我們基于上面所敘述的http方面的知識來簡單實現的http版服務器,具有跳轉,重定向,動態交互等功能,然后在登錄頁面密碼只要是666就能正確登錄并跳轉視頻播放頁面,否則就404頁面!
簡單HTTP服務器功能測試效果
2.2 源碼

點擊這里進入my-gitee獲取對應源碼
三· 本篇小結
- 本篇學習了相關
http協議的內容,明白了它的概念,結構等等,以及自己手搓實現了簡單版的http服務器,當然前提還得是對http相關知識掌握牢固,其次就是考驗代碼能力了,博主在學習http專題時候歷經一個星期多,從學習到編寫對應代碼,也陷入過對應的幾個小時找bug環節,但是最終由于那份堅持還是完成了任務,此篇,博主通過自己整理的筆記再一次書寫成博客耗時半天,重溫了一遍知識就是很爽~,也希望對大家學習http有幫助!
苦盡甘來時,再講來時路!
沖沖沖!!!




】記錄一次在新服務器上使用docker的流程)







 乘法法則、全概率公式、貝葉斯定理)





)
