深度定制 LLM 知識,除了 RAC ,現在又有新技術
假設有一份200頁的產品手冊,你想讓 LLM 準確回答里面的相關問題,要實現這個目標,除了常用的檢索增強生成技術 rep ,現在有了新思路,緩存增強生成 CAG ,它是什么,何時使用.

RAG檢索增強是常規套路,CAG緩存增強是后起之秀讓我們來對比一下他們的優缺點. 我們先來了解一下,檢索增強生成 RAG 的工作流程
RAG檢索增強流程
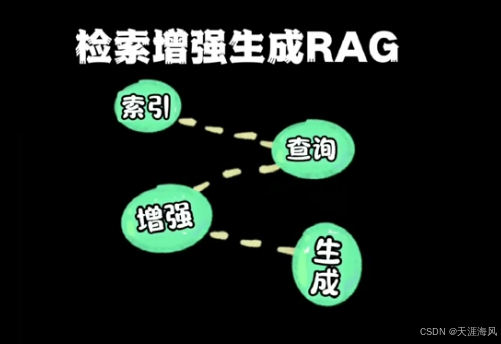
第一步 索引階段 這個步驟在提前處理的情況下 也允許動態加入
就像煮飯備料一樣
- RAG 會將文檔切成小塊
- 再轉換成向量
- 存入向量數據庫
第二步 查詢階段
用戶提問后
- 系統將問題轉為向量
- 在向量數據庫中檢索相似內容
第三步 增強階段
- 將檢索到的相關內容添加到提示詞中
第四步 生成階段
- LLM 基于增強后的提示詞生成回答
RAG工作流程缺點
了解過 RAG的工作流程,它的局限性大家可能也都猜到了
- 檢索存在延遲
- 檢索的質量和內容影響回答準確性
- 架構復雜,需要費心維護向量數據庫
CAG檢索增強流程
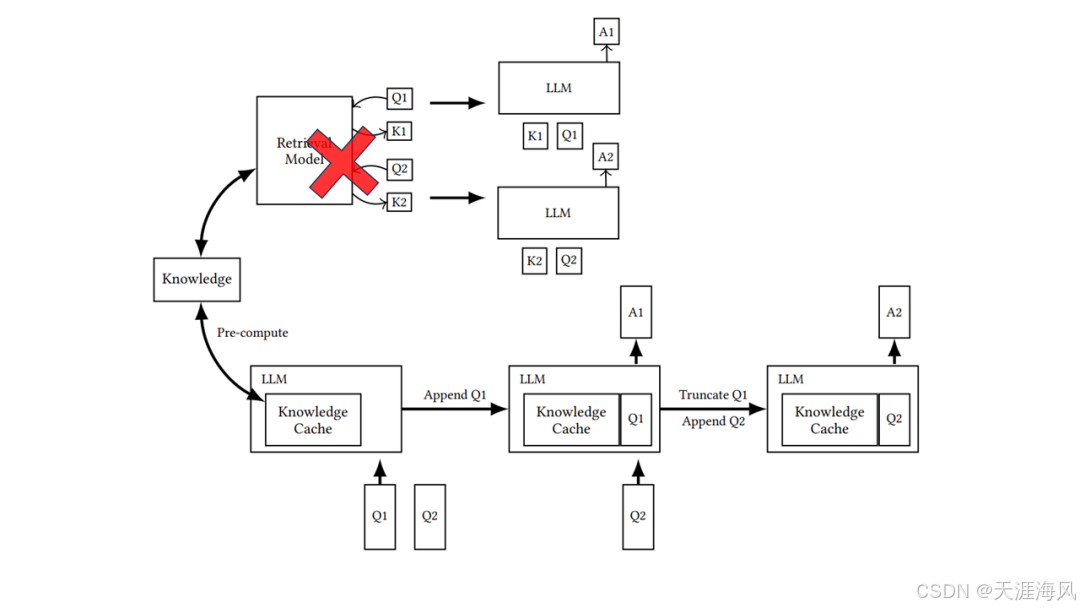
在 RAG 基礎上,CAG 提供了另一種解題思路, 它比 RAG 工作流程更短 主要包括兩個階段
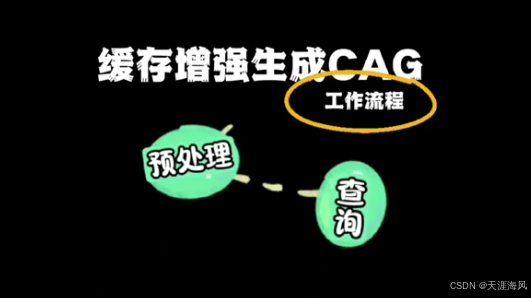
第一階段 預處理流程
- 對知識源進行處理,提取關鍵信息
- 接著將信息結構化
- 利用 LLM 將文檔轉化為鍵值對緩存
以一本書為例, 就是把它的關鍵內容, 組成對應關系進行緩存. 像
章節標題對應章節摘要、人物名稱對應人物描述、核心概對應概念解釋、常見問題對應答案
第二階段 查詢流程
- 初始階段,所有鍵值對都加載到緩存當中
- 把緩存加載到 LLM 的上下文窗口中
- 與用戶提問一起發送給 LLM
- LLM 直接從上下文的知識緩存中檢索, 并生成回答
CAG檢索增強流優勢
省略了檢索步驟使 CAG 擁有了明顯的優勢,
- 無檢索延遲,響應自然更快,
- LLM 直接加載所有緩存知識回答一致性更高,
- 無檢索系統架構更簡單,降低了維護的復雜性
最后我們來總結 一 RAG 和 CAG 到底何時用
何時使用 RAG的場景
- 有規模龐大的知識庫, 如超出 LLM 上下文窗口容量的,
- 更新頻繁的資料
- 面向開放領域的多樣化問題
- 需要精準引用原文出處的
何時使用 CAG 的場景
- 知識領域固定且規模適中的: 如書籍
- 看重響應速度 用 CAG 能快幾秒
- 需要全局理解和一致性: 如財務報表分析,
- 可以被有效提煉和結構化的知識
總結
RAG 和 CAG ,它們代表了兩種不同的知識增強范式一個動態檢索、一個預加載緩存
選擇哪種技術取決于你的 具體需求,知識規模和性能要求

文章:
https://blog.csdn.net/simoncool23/article/details/145224445







)











