背景意義
研究背景與意義
隨著全球食品產業的快速發展,食品安全和質量控制日益成為社會關注的焦點。食品分類與實例分割技術的應用,能夠有效提升食品識別的準確性和效率,為食品監管、營養分析以及智能餐飲等領域提供重要支持。傳統的食品識別方法多依賴于人工經驗,存在主觀性強、效率低下等問題,而基于深度學習的計算機視覺技術則為解決這些問題提供了新的思路。
YOLO(You Only Look Once)系列模型以其高效的實時檢測能力和較高的準確率,廣泛應用于目標檢測和實例分割任務。YOLOv11作為該系列的最新版本,進一步優化了模型結構和算法性能,具備更強的特征提取能力和更快的推理速度。通過對YOLOv11的改進,結合FOOD103數據集的豐富類別信息,能夠實現對多種食品的精準分類與實例分割,為食品行業的智能化轉型提供技術支持。
FOOD103數據集包含7100張圖像,涵蓋103種不同類型的食品,數據的多樣性和豐富性為模型的訓練提供了良好的基礎。該數據集不僅包含常見的水果、蔬菜、肉類等食品,還涵蓋了多種加工食品和調料,能夠有效提高模型的泛化能力和適應性。通過對該數據集的深入研究,可以推動食品圖像識別技術的發展,為食品安全監測、智能廚房、個性化飲食推薦等應用場景提供強有力的技術支撐。
總之,基于改進YOLOv11的食品分類與實例分割系統的研究,不僅具有重要的學術價值,還有助于推動食品行業的智能化發展,提升食品安全管理水平,促進人們健康飲食的實現。通過這一研究,期望能夠為未來的食品圖像識別技術奠定堅實的基礎,推動相關領域的進一步探索與應用。
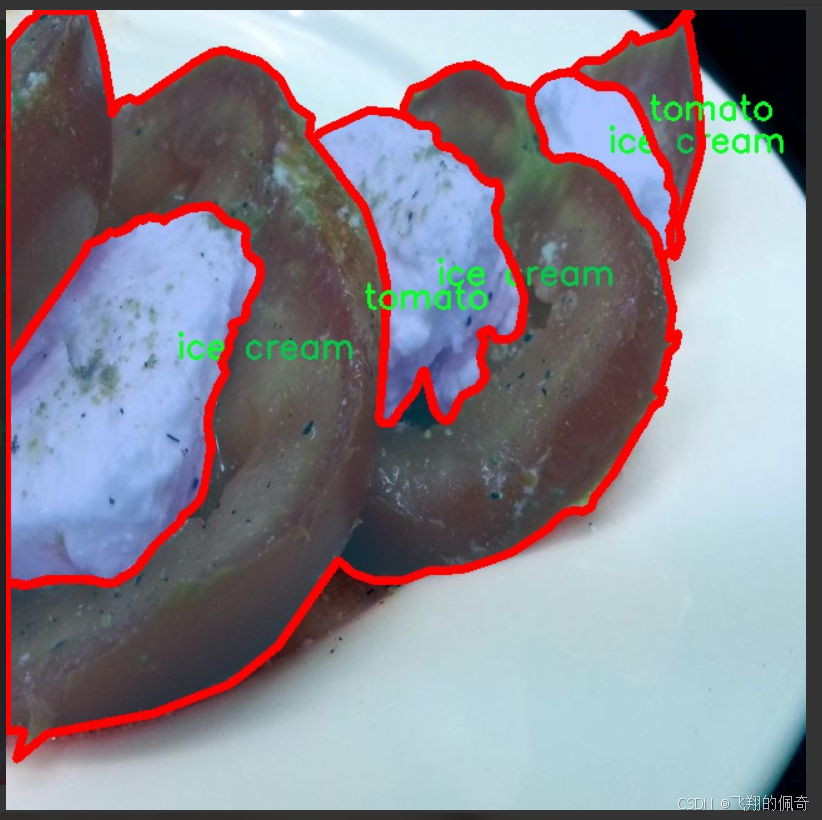
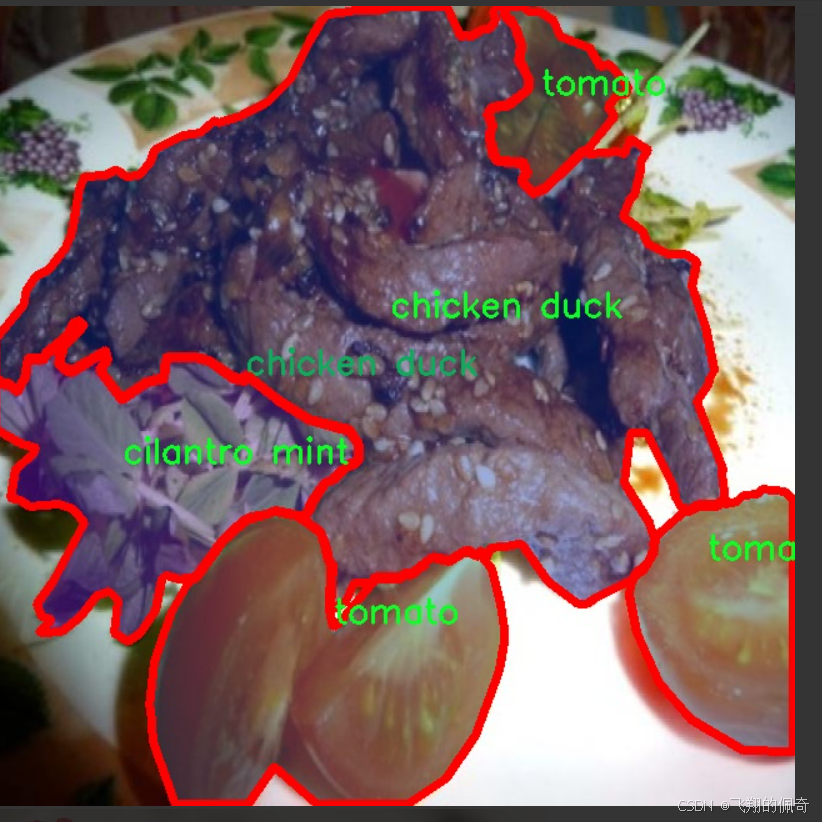
圖片效果
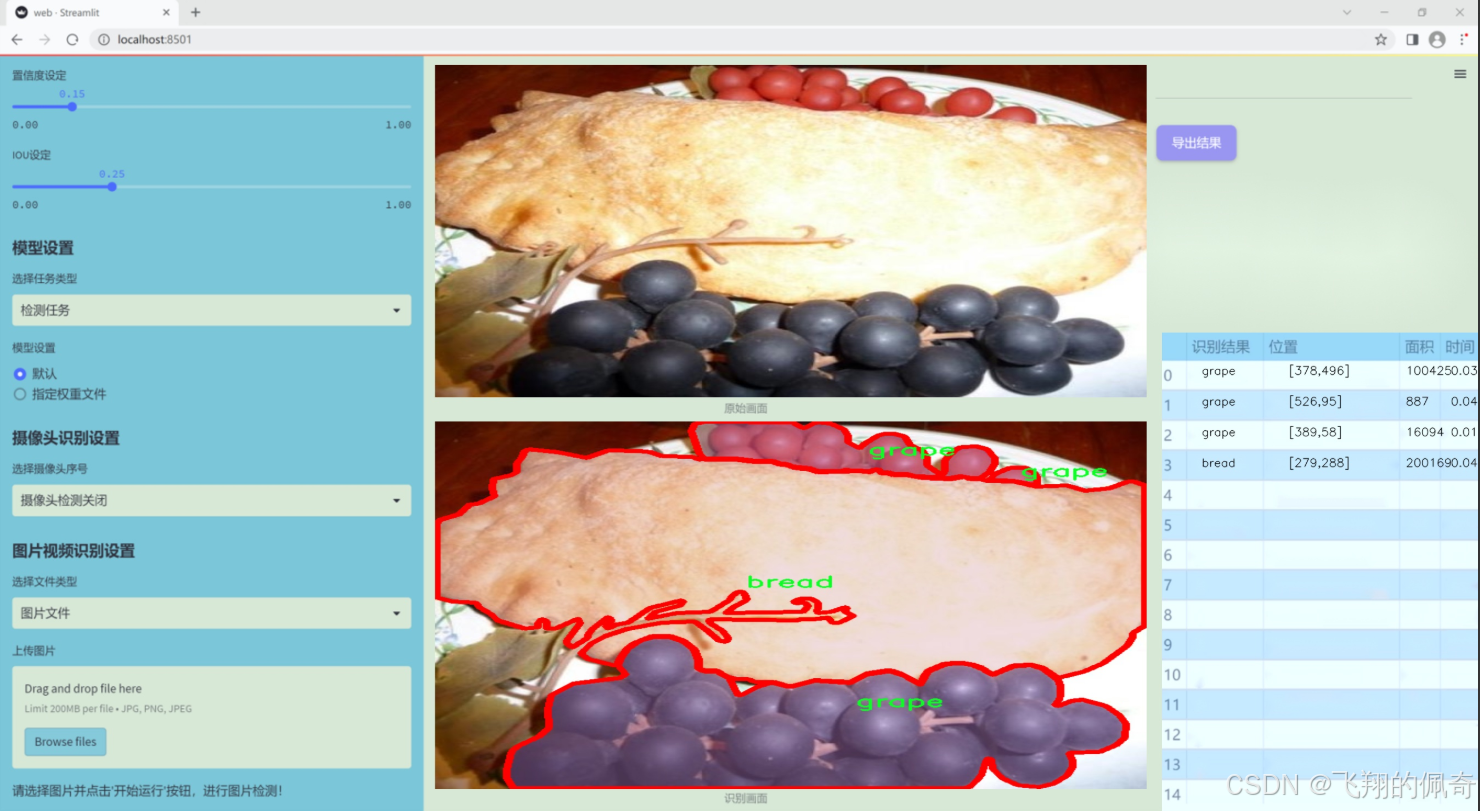
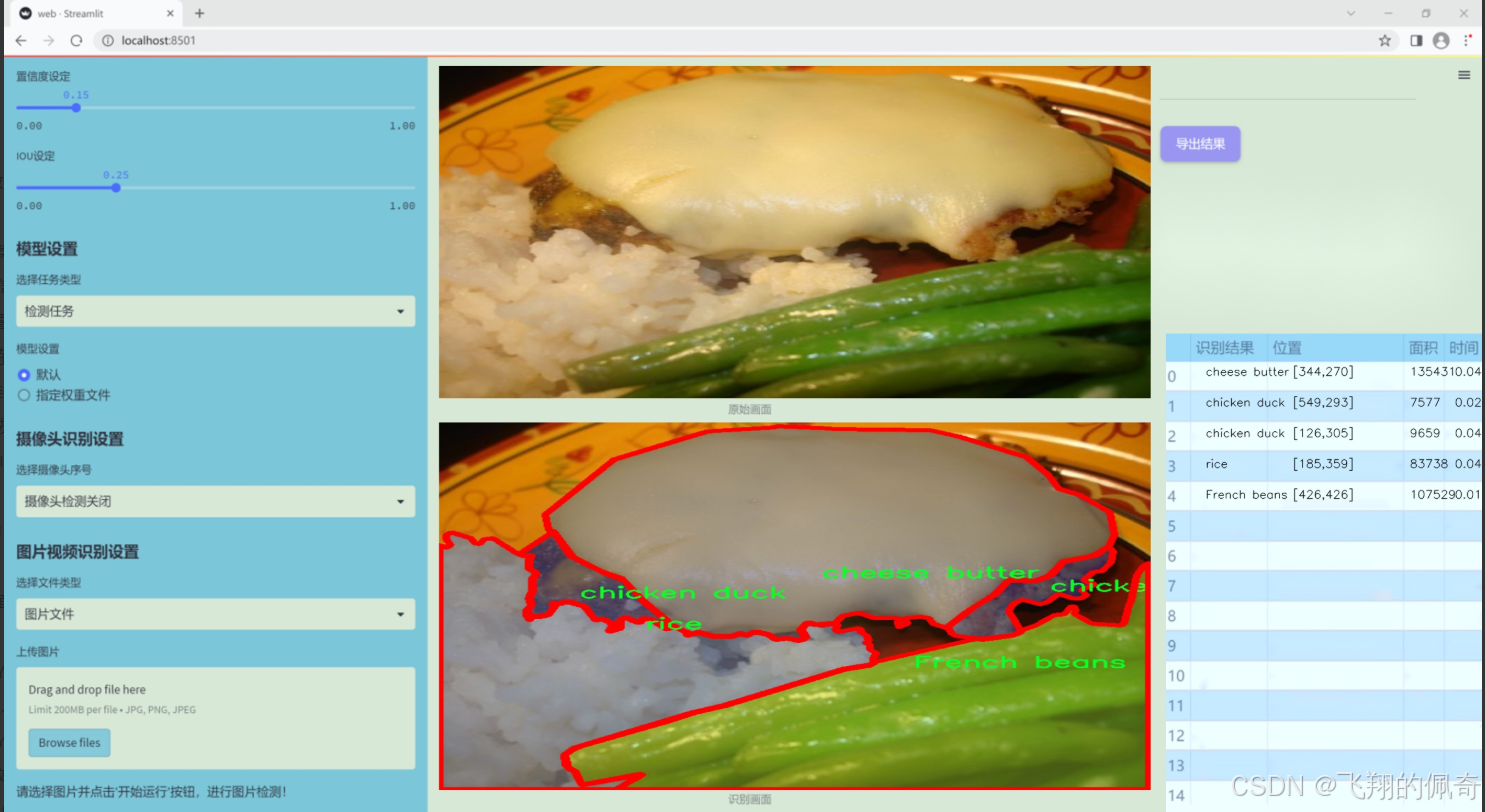
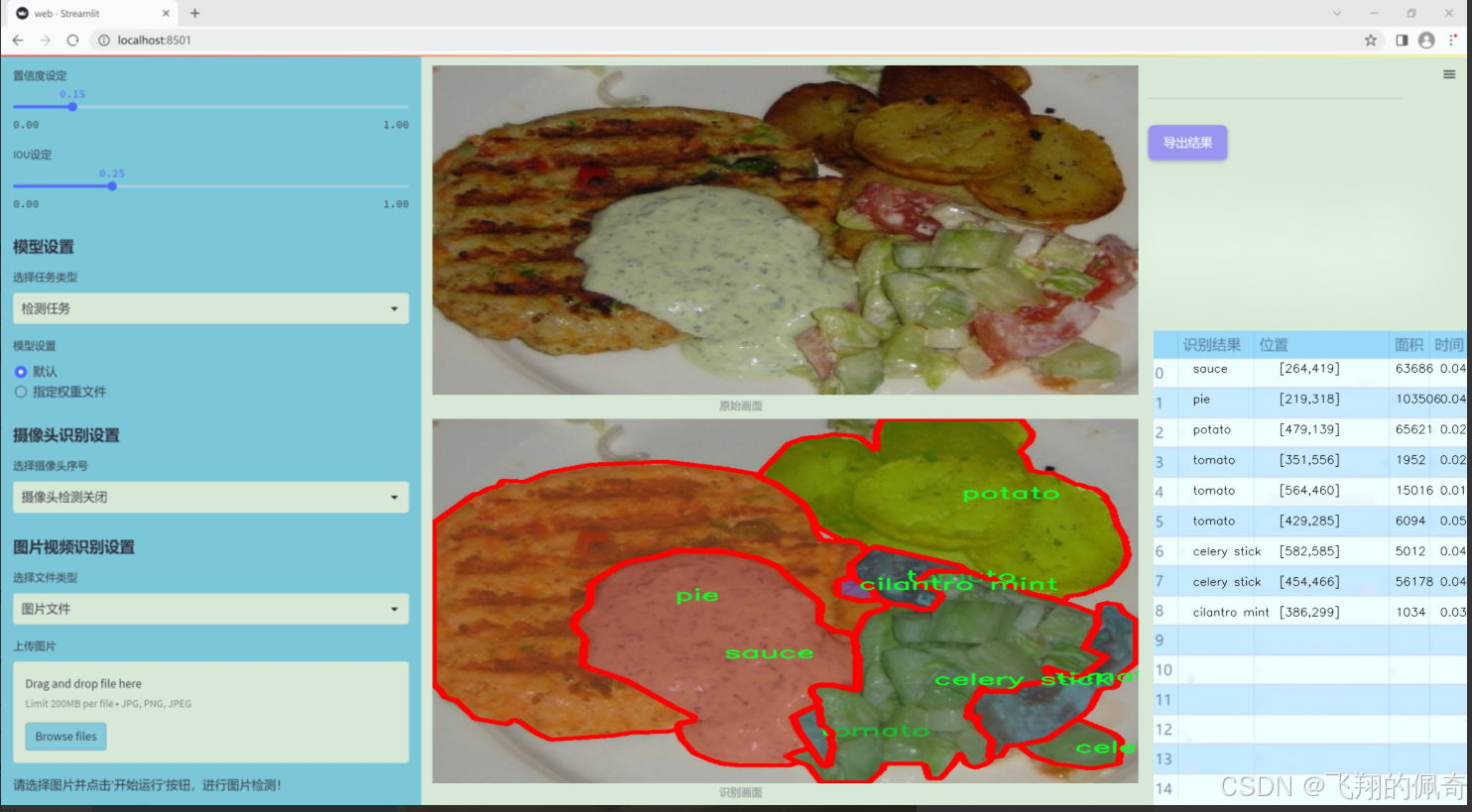
數據集信息
本項目數據集信息介紹
本項目采用的食品分類與實例分割數據集為“FOOD103”,該數據集專為改進YOLOv11模型而設計,旨在提升其在食品識別與分割任務中的性能。FOOD103數據集包含103個不同的食品類別,涵蓋了豐富多樣的食材與食品類型,從新鮮蔬菜到精致甜點,能夠為模型提供全面的訓練素材。這些類別包括但不限于法式豆、杏仁、蘋果、杏、蘆筍、鱷梨、竹筍、香蕉、豆芽、餅干、藍莓、面包、花椰菜、卷心菜、蛋糕、糖果、胡蘿卜、腰果、菜花、芹菜棒、奶酪黃油、櫻桃、雞鴨、巧克力、香菜薄荷、咖啡、玉米、螃蟹、黃瓜、棗、干蔓越莓、雞蛋、蛋撻、茄子、金針菇、無花果、魚、薯條、炸肉、大蒜、生姜、葡萄、青豆、漢堡、花卷、冰淇淋、果汁、海帶、杏鮑菇、獼猴桃、羊肉、檸檬、生菜、芒果、甜瓜、牛奶、奶昔、面條、秋葵、橄欖、洋蔥、橙子、其他配料、香菇、意大利面、桃子、花生、梨、辣椒、派、菠蘿、比薩、爆米花、豬肉、土豆、布丁、南瓜、油菜、覆盆子、紅豆、米飯、沙拉、醬料、香腸、海藻、貝類、香菇、蝦、雪豆、湯、豆類、蔥、牛排、草莓、茶、豆腐、西紅柿、核桃、西瓜、白蘑菇、白蘿卜、葡萄酒、餛飩等。通過對這些類別的系統性標注,FOOD103數據集為深度學習模型提供了豐富的上下文信息,使其能夠在復雜的食品場景中進行準確的分類與實例分割。
該數據集的多樣性和豐富性不僅有助于提高模型的泛化能力,還能增強其在實際應用中的實用性,尤其是在餐飲、食品安全和營養分析等領域。通過使用FOOD103數據集,研究人員能夠深入探索和優化YOLOv11模型的性能,推動食品識別技術的發展。
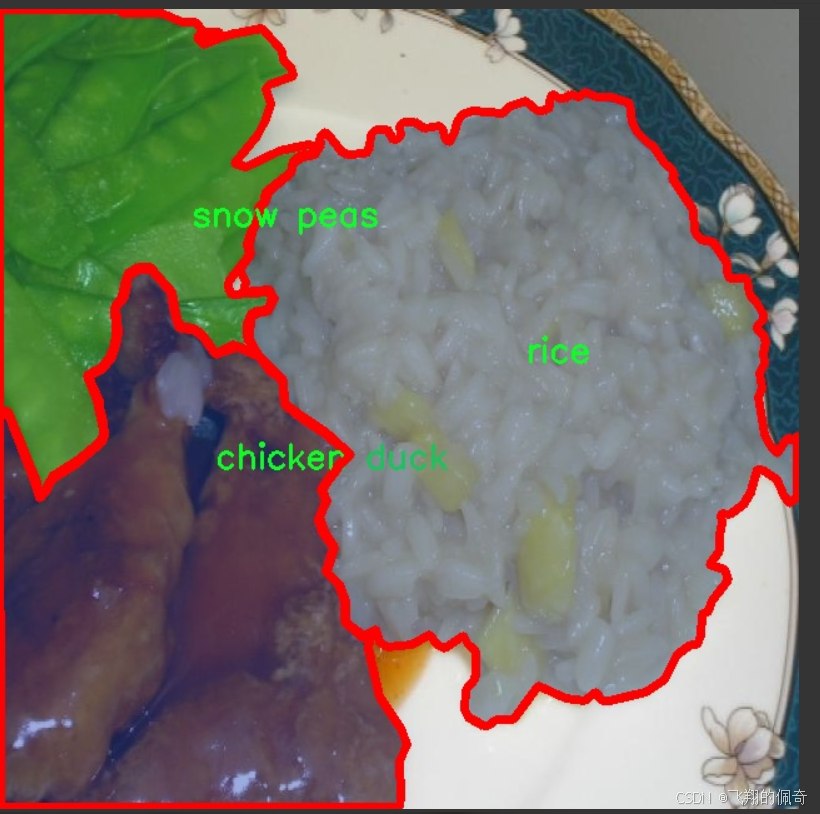


核心代碼
以下是代碼中最核心的部分,并附上詳細的中文注釋:
from functools import lru_cache
import torch
import torch.nn as nn
from torch.nn.functional import conv3d, conv2d, conv1d
class KALNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, conv_w_fun, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1, dropout: float = 0.0, ndim: int = 2):
super(KALNConvNDLayer, self).init()
# 初始化層的參數self.inputdim = input_dim # 輸入維度self.outdim = output_dim # 輸出維度self.degree = degree # 多項式的階數self.kernel_size = kernel_size # 卷積核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨脹self.groups = groups # 分組卷積的組數self.base_activation = nn.SiLU() # 基礎激活函數self.conv_w_fun = conv_w_fun # 卷積權重函數self.ndim = ndim # 數據的維度(1D, 2D, 3D)self.dropout = None # Dropout層初始化為None# 如果dropout大于0,則根據維度選擇合適的Dropout層if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 檢查分組參數的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 創建基礎卷積層和歸一化層self.base_conv = nn.ModuleList([conv_class(input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化多項式權重poly_shape = (groups, output_dim // groups, (input_dim // groups) * (degree + 1)) + tuple(kernel_size for _ in range(ndim))self.poly_weights = nn.Parameter(torch.randn(*poly_shape))# 使用Kaiming均勻分布初始化卷積層權重for conv_layer in self.base_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')nn.init.kaiming_uniform_(self.poly_weights, nonlinearity='linear')@lru_cache(maxsize=128) # 使用LRU緩存以避免重復計算Legendre多項式
def compute_legendre_polynomials(self, x, order):# 計算Legendre多項式P0 = x.new_ones(x.shape) # P0 = 1if order == 0:return P0.unsqueeze(-1)P1 = x # P1 = xlegendre_polys = [P0, P1]# 使用遞推公式計算更高階的多項式for n in range(1, order):Pn = ((2.0 * n + 1.0) * x * legendre_polys[-1] - n * legendre_polys[-2]) / (n + 1.0)legendre_polys.append(Pn)return torch.concatenate(legendre_polys, dim=1)def forward_kal(self, x, group_index):# 計算前向傳播base_output = self.base_conv[group_index](x) # 基礎卷積輸出# 將輸入x歸一化到[-1, 1]范圍x_normalized = 2 * (x - x.min()) / (x.max() - x.min()) - 1 if x.shape[0] > 0 else x# 如果存在Dropout,則應用Dropoutif self.dropout is not None:x_normalized = self.dropout(x_normalized)# 計算歸一化后的x的Legendre多項式legendre_basis = self.compute_legendre_polynomials(x_normalized, self.degree)# 使用多項式權重進行卷積計算poly_output = self.conv_w_fun(legendre_basis, self.poly_weights[group_index],stride=self.stride, dilation=self.dilation,padding=self.padding, groups=1)# 合并基礎輸出和多項式輸出x = base_output + poly_output# 進行層歸一化if isinstance(self.layer_norm[group_index], nn.LayerNorm):orig_shape = x.shapex = self.layer_norm[group_index](x.view(orig_shape[0], -1)).view(orig_shape)else:x = self.layer_norm[group_index](x)# 應用激活函數x = self.base_activation(x)return xdef forward(self, x):# 前向傳播,處理分組輸入split_x = torch.split(x, self.inputdim // self.groups, dim=1)output = []for group_ind, _x in enumerate(split_x):y = self.forward_kal(_x.clone(), group_ind) # 對每個組進行前向傳播output.append(y.clone())y = torch.cat(output, dim=1) # 合并所有組的輸出return y
代碼核心部分說明:
KALNConvNDLayer類:這是一個自定義的神經網絡層,支持任意維度的卷積操作。它結合了基礎卷積、歸一化和多項式卷積的特性。
構造函數:初始化層的參數,創建基礎卷積層和歸一化層,并初始化多項式權重。
compute_legendre_polynomials方法:計算Legendre多項式,使用遞推公式生成多項式序列,并利用LRU緩存提高效率。
forward_kal方法:實現了該層的前向傳播邏輯,計算基礎卷積輸出、歸一化輸入、計算Legendre多項式并結合基礎輸出和多項式輸出。
forward方法:處理輸入數據的分組,并對每個組調用forward_kal進行計算,最后合并輸出。
這個程序文件定義了一個名為 KALNConvNDLayer 的神經網絡層及其子類,旨在實現一種新的卷積操作,結合了多項式基函數(Legendre多項式)和標準卷積操作。該層可以處理不同維度的輸入(1D、2D、3D),并且具有可調的參數以適應不同的網絡結構。
在 KALNConvNDLayer 類的構造函數中,首先初始化了一些卷積層的參數,包括輸入和輸出維度、卷積核大小、步幅、填充、擴張率等。該類還接受一個 conv_class 參數,允許用戶指定使用的卷積類型(如 nn.Conv1d、nn.Conv2d 或 nn.Conv3d),以及一個歸一化層的類(如 nn.InstanceNorm1d、nn.InstanceNorm2d 或 nn.InstanceNorm3d)。此外,構造函數中還定義了一個用于生成多項式權重的參數 poly_weights,并使用 Kaiming 均勻分布初始化這些權重,以提高訓練的穩定性。
compute_legendre_polynomials 方法用于計算 Legendre 多項式,采用遞歸的方式生成指定階數的多項式,并使用 lru_cache 裝飾器來緩存計算結果,以避免重復計算。該方法返回的多項式將在前向傳播中使用。
在 forward_kal 方法中,首先對輸入進行基礎卷積操作,然后將輸入歸一化到 [-1, 1] 的范圍,以便于計算 Legendre 多項式。接著,調用 compute_legendre_polynomials 方法計算多項式基,并使用多項式權重進行線性變換。最后,將基礎卷積輸出和多項式輸出相加,并通過歸一化層和激活函數進行處理。
forward 方法負責處理整個輸入,首先將輸入按照組數進行分割,然后對每個組調用 forward_kal 方法進行處理,最后將所有組的輸出拼接在一起,形成最終的輸出。
此外,文件中還定義了三個子類 KALNConv3DLayer、KALNConv2DLayer 和 KALNConv1DLayer,分別用于處理三維、二維和一維數據。這些子類通過調用父類的構造函數來初始化特定的卷積和歸一化層。
總體而言,這個程序文件實現了一種靈活且強大的卷積層,能夠在不同維度上進行復雜的特征提取,并結合了多項式基函數的優勢,以提高模型的表達能力。
10.4 convnextv2.py
以下是代碼中最核心的部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
import torch.nn.functional as F
class LayerNorm(nn.Module):
“”" 自定義的層歸一化(Layer Normalization)類,支持兩種數據格式:channels_last(默認)和 channels_first。
channels_last 對應輸入形狀為 (batch_size, height, width, channels),
channels_first 對應輸入形狀為 (batch_size, channels, height, width)。
“”"
def init(self, normalized_shape, eps=1e-6, data_format=“channels_last”):
super().init()
# 權重和偏置參數
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps # 防止除零的微小值
self.data_format = data_format
if self.data_format not in [“channels_last”, “channels_first”]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):# 根據數據格式進行歸一化處理if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True) # 計算均值s = (x - u).pow(2).mean(1, keepdim=True) # 計算方差x = (x - u) / torch.sqrt(s + self.eps) # 標準化x = self.weight[:, None, None] * x + self.bias[:, None, None] # 應用權重和偏置return x
class Block(nn.Module):
“”" ConvNeXtV2中的基本模塊(Block)。
Args:dim (int): 輸入通道數。
"""
def __init__(self, dim):super().__init__()# 深度可分離卷積self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)self.norm = LayerNorm(dim, eps=1e-6) # 歸一化層self.pwconv1 = nn.Linear(dim, 4 * dim) # 1x1卷積(用線性層實現)self.act = nn.GELU() # 激活函數self.pwconv2 = nn.Linear(4 * dim, dim) # 1x1卷積(用線性層實現)def forward(self, x):input = x # 保存輸入以便后續殘差連接x = self.dwconv(x) # 深度卷積x = x.permute(0, 2, 3, 1) # 轉換維度順序x = self.norm(x) # 歸一化x = self.pwconv1(x) # 第一個1x1卷積x = self.act(x) # 激活x = self.pwconv2(x) # 第二個1x1卷積x = x.permute(0, 3, 1, 2) # 恢復維度順序x = input + x # 殘差連接return x
class ConvNeXtV2(nn.Module):
“”" ConvNeXt V2模型定義。
Args:in_chans (int): 輸入圖像的通道數。默認值:3num_classes (int): 分類頭的類別數。默認值:1000depths (tuple(int)): 每個階段的塊數。默認值:[3, 3, 9, 3]dims (int): 每個階段的特征維度。默認值:[96, 192, 384, 768]
"""
def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768]):super().__init__()self.downsample_layers = nn.ModuleList() # 下采樣層# Stem層stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)# 添加下采樣層for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 特征分辨率階段for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i]) for _ in range(depths[i])])self.stages.append(stage)self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # 最后的歸一化層self.head = nn.Linear(dims[-1], num_classes) # 分類頭def forward(self, x):res = [] # 存儲每個階段的輸出for i in range(4):x = self.downsample_layers[i](x) # 下采樣x = self.stages[i](x) # 通過當前階段res.append(x) # 保存輸出return res # 返回所有階段的輸出
代碼說明:
LayerNorm:實現了層歸一化,支持不同的通道格式,確保在不同的輸入格式下都能正常工作。
Block:ConvNeXtV2的基本構建塊,包含深度卷積、歸一化、激活和殘差連接。
ConvNeXtV2:整體模型的定義,包含多個下采樣層和多個階段,每個階段由多個Block組成,最終輸出分類結果。
這個程序文件實現了一個名為 ConvNeXt V2 的深度學習模型,主要用于圖像分類任務。該模型的設計靈感來源于卷積神經網絡(CNN),并結合了一些新的技術,如全局響應歸一化(GRN)和層歸一化(LayerNorm)。文件中包含多個類和函數,下面是對其主要內容的說明。
首先,文件導入了必要的庫,包括 PyTorch 和一些用于模型構建的模塊。接著,定義了一個名為 LayerNorm 的類,該類實現了層歸一化,支持兩種數據格式:通道優先(channels_first)和通道后置(channels_last)。在 forward 方法中,根據輸入數據的格式應用相應的歸一化操作。
接下來,定義了 GRN 類,它實現了全局響應歸一化層。該層通過計算輸入的 L2 范數并進行歸一化,來調整特征的響應。它使用兩個可學習的參數 gamma 和 beta 來控制輸出。
然后,定義了 Block 類,表示 ConvNeXt V2 的基本構建塊。每個塊包含一個深度可分離卷積層、層歸一化、點卷積層(通過線性層實現)、激活函數(GELU)、GRN 和另一個點卷積層。該塊還支持隨機深度(drop path)技術,以增強模型的泛化能力。
接著,定義了 ConvNeXtV2 類,這是整個模型的核心。構造函數中接受多個參數,包括輸入通道數、分類類別數、每個階段的塊數、特征維度、隨機深度率等。模型的構建包括一個初始卷積層和多個下采樣層,隨后是多個特征分辨率階段,每個階段由多個殘差塊組成。最后,模型包含一個層歸一化層和一個線性分類頭。
在模型的初始化過程中,使用 _init_weights 方法對卷積層和線性層的權重進行初始化,采用截斷正態分布的方法。
forward 方法定義了模型的前向傳播過程,輸入經過下采樣層和特征階段的處理,最終返回每個階段的輸出。
此外,文件還定義了一個 update_weight 函數,用于更新模型的權重。該函數會檢查權重字典中的每個鍵是否在模型字典中,并且形狀是否匹配,符合條件的權重會被更新。
最后,文件提供了多個函數(如 convnextv2_atto、convnextv2_femto 等),用于創建不同規模的 ConvNeXt V2 模型。這些函數接受權重文件路徑和其他參數,并在需要時加載預訓練的權重。
總體而言,這個文件實現了一個靈活且強大的圖像分類模型,結合了現代深度學習中的多種技術,適用于不同規模的任務。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式




![[Responsive theme color] 動態更新 | CSS變量+JS操控 | 移動端-漢堡菜單 | 實現平滑滾動](http://pic.xiahunao.cn/[Responsive theme color] 動態更新 | CSS變量+JS操控 | 移動端-漢堡菜單 | 實現平滑滾動)









——歷史點、數學方式推導點)




