
本文字數:2604字
預計閱讀時間:15分鐘
01
引言
在現有分布式系統中,面對增長迅速的業務數據,id生成一直是非常重要的一環。而分布式系統的id生成方案需要滿足幾個重要特性:容錯高可用、高性能高并發、全局唯一。
02
技術背景
經過測試,該方案每次生成分布式id的平均耗時為1.46毫秒,而跨機房獲取id的平均耗時為5.32毫秒。
這種讀數據庫方案的弊端就很明顯:
當qps過高時,數據庫的壓力就會大大增加;
跨機房讀的耗時也會明顯升高;
如果使用框架自帶的邏輯,如Hibernate的strategy = GenerationType.TABLE策略,要求sequence表和數據表同數據源,所以當進行分庫后,新庫對id的獲取就會很麻煩;
有很小的概率會在生成id讀寫數據庫時,導致死鎖,新增數據無法入庫,我們就遇到過一次 - -!!!
當然這種方案有一個最大的好處:產生的id嚴格遞增,對我們業務來說,這個特性非常重要。
03
現有分布式方案分析
分布式id生成這么重要,市面上當然有很多的解決方案。下邊簡單介紹一下幾種常見的方案:
UUID:
介紹:UUID是一個由32個十六進制數字組成,中間由橫杠分割(例:372f3ba5-6359-4f1f-9184-a938a4908072),java中可以直接調用UUID.randomUUID()實現,也可以使用特定算法生成。
優點:實現簡單,UUID的生成非常簡單,不需要依賴于任何外部資源;實際應用中基本不會遇到重復的情況。
缺點:UUID長度較長,占用的存儲空間較大,且可讀性差;算法實現復雜,經測試存在效率問題。在數據庫作為主鍵時,可能會影響寫入性能;不是遞增的。
雪花算法:
介紹:SnowFlake是 Twitter 開源的分布式 id 生成算法,可以不用依賴任何第三方工具進行自增的數字類型的id生成;雪花算法的核心邏輯是使用一個 64 bit 的 long 型的數字作為全局唯一id。
雪花算法生成的唯一ID均為正數,所以這 64 個 bit 中,其中 1 個 bit 是不用的(第一個 bit 默認都是 0),然后用 41 bit 作為毫秒數,用 10 bit 作為工作機器 id,12 bit 作為序列號。
優點:實現簡單,不依賴其他第三方庫;高效,雪花算法能以極高的速度生成ID,每秒可生成數百萬個,滿足高并發場景的需求。
缺點:時間回撥問題;生成的id長度比較長;機器碼不同,生成的id也不同,跟歷史id相比變化比較大;生成的id趨勢遞增。
百度uid-generator框架:
介紹:百度UidGenerator是基于snowflake算法思想實現的,但與原始算法不同的地方在于,UidGenerator支持自定義時間戳、工作機器id(workId)以及序列號等各個組成部分的位數,并且工作機器id采用用戶自定義的生成策略。百度uid-generator有兩種實現方式:DefaultUidGenerator和CachedUidGenerator。從性能和時間回撥問題考慮,一般都是考慮CachedUidGenerator類實現。
優點:性能好,每秒可生成數百萬個id;簡單易用,現成jar包直接接入,包括獲取當前時間戳、數據中心id和機器id。支持多種部署方式,包括單機模式和分布式模式。
缺點:默認接入mybatis框架,否則需要自己重寫dao層;生成的id趨勢遞增。
美團leaf框架:
介紹:美團的leaf框架有兩種模式。一種是雪花算法模式,也是基于雪花算法這里不再贅述。另一種模式是號段模式。號段模式:每次從數據庫中取一個號段的id值,號段由step步長決定。然后把號段放在內存中。當號碼使用到一定范圍時,則更新到下一號段。
優點:每次取一個號段的id,大大減少了對數據庫的讀寫,減輕了數據庫壓力;不同的機器存在不同的號段,放在內存中,速度快效率高,只需要考慮本機的線程安全問題。
缺點:如果有多臺機器提供服務,那么每臺機器生成的號段不同,只能保證趨勢遞增;如果有一臺服務器,對于業務請求量巨大時,單臺服務器可能會扛不住壓力,服務器宕機就會使獲取id服務不可用。
當然除了上述方案,還有其他的分布式id生成方案:比如zookeeper的順序節點,滴滴的Tinyid框架,這里就不一一列舉。
04
嚴格遞增的分布式id生成方案
方案介紹:
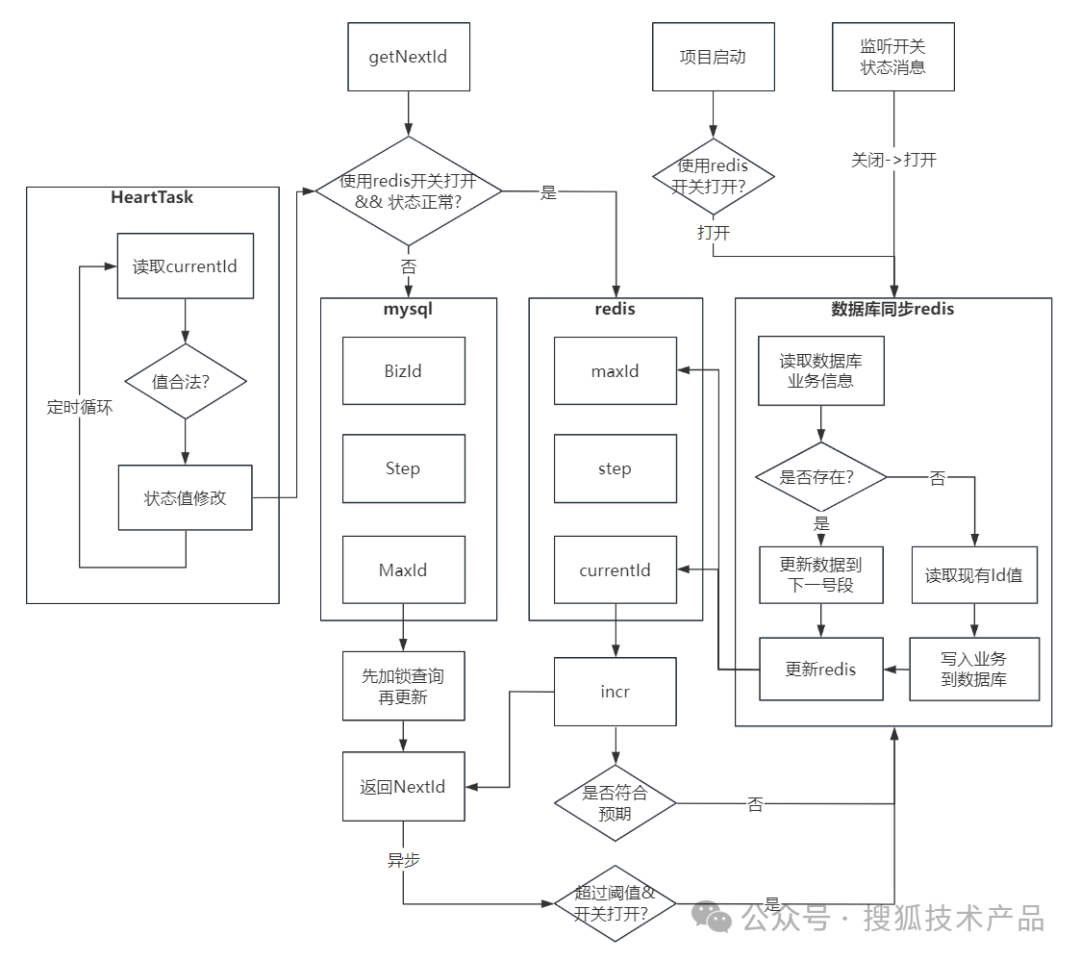
采用的是?數據庫號段模式?加?緩存?加?監聽?的方案,有兩種id生成模式:
使用緩存生成;
使用數據庫表生成。
具體工具可以自行選擇。這里使用的是mysql + redis + nacos。
mysql中創建一張sequence表,主要字段:bizId: 業務表示,區分不同業務的id;maxId:目前號段最大的Id值;step:步長,每個號段包含的id個數。
redis中也需要存儲三個key:currentId:當前已經使用到的id值;maxId:當前號段的最大id值,step:步長。
nacos開關的作用:控制是否id生成模式,打開:使用redis生成模式,關閉:使用數據庫表生成模式;同時監聽nacos開關,控制生成模式自動切換。
實現流程:
項目啟動時:如果nacos開關打開,檢測redis中是否存在當前業務id相關的key,如果沒有則讀取數據庫加載到redis中(注意先更新到下一號段)
當有新的寫入請求時:
首先判斷 redis心跳檢測正常 且 nacos開關打開,則是緩存生成模式:
直接讀取redis中對應currentId,通過incr()方法獲取到下一個id值;
此時檢查id時否合理,合理閾值可以自行設置。如果不合理則調用 數據庫同步redis流程(先把數據庫更新到下一號段,然后再更新redis中的值:currentId = 原maxId + step*0.1, 新maxId = 原maxId + step);
生成id后,異步線程判斷:當前id是否已經使用了當前號段的百分之30,如果超過則更新獲取下一號段。
否則:使用數據庫生成模式,直接讀取數據庫sequence表把maxId字段作為當前id使用,maxId字段先加鎖查詢,然后再更新加1。
當有特殊情況時:
redis集群不可用,通過心跳任務檢測出狀態不對,則直接調用api關閉開關。關閉后就是使用數據庫模式生成id,雖然耗時有所增加,但增加量不多且可以保證業務流程不阻塞;
處理好redis問題后,修改naocs開關,程序監聽到開關打開事件,則從數據庫模式改為緩存模式生成:先更新下一號段避免id重復,然后把新更新的值寫入redis中,下次請求就繼續開始使用redis生成id。
總結:
這個方案使用redis來生成Id,主要是因為redis作為強大的中間件基本所有項目都會用到,隨處可見,不用再引入新的第三方依賴;其次redis的自增自帶原子性,生成的id是嚴格遞增。
并且redis可以很好的抗住高QPS請求,經測試id的獲取絕大部分小于等于1毫秒。
為了防止redis集群抽瘋不可用,準備了數據庫生成方案:直接讀取數據庫中的sequence表,查詢并更新maxId字段加1。這樣可以保證業務的正常運行,耗時平均漲幾毫秒,屬于可接受范圍。在使用數據模式生成期間,就可以著手處理redis集群的問題,處理完后通過監聽開關打開事件,再重新切換到緩存生成模式,繼續生成嚴格遞增的分布式id。(為了防止重復,先更新數據庫到下一號段,把新值更新到redis中)
附流程圖:
05
結論
這個方案主要是通過redis的自增來高效生成嚴格遞增的id,可以用其他中間件代替。這個方案重要的是不只依賴于redis,還要對redis不可用的情況進行兜底檢測,形成一個自動切換的閉環。
經測試該方案性能,相比于之前直接查詢更新數據庫sequence表方案,同機房獲取id性能提升接近10倍,跨機房獲取id性能提升接近7倍。
同時該方案也解決了之前遇到過的數據庫sequence表死鎖,導致業務數據無法新增入庫的問題。
當然如果業務需求并不要求id嚴格遞增,那么上邊介紹的優秀的框架都可以使用。







)










EasyCaptcha驗證碼 超詳細)
