接上篇
在NVIDIA Orin上用TensorRT對YOLO12進行多路加速并行推理時內存泄漏(上)
通過上篇的分析,發現問題在采集數據到傳入GPU之前的階段。但隨著新一輪長時間測試發現,問題依然存在。
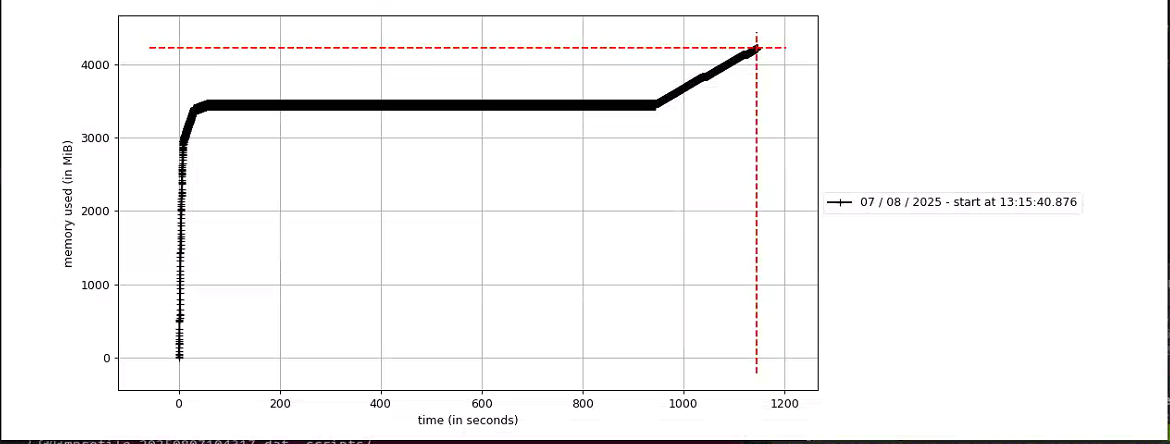
如上圖,在運行20多分鐘內存開始增長,這個增長只要一開始就會持續直到程序直接卡掉。于是又開啟新一輪的排查。
首先,控制變量,使用YOLO12s-DET的engine模型進行推理測試,內存增長情況如下圖:在7000s(近兩個小時的測試中),內存都在平穩無變化。
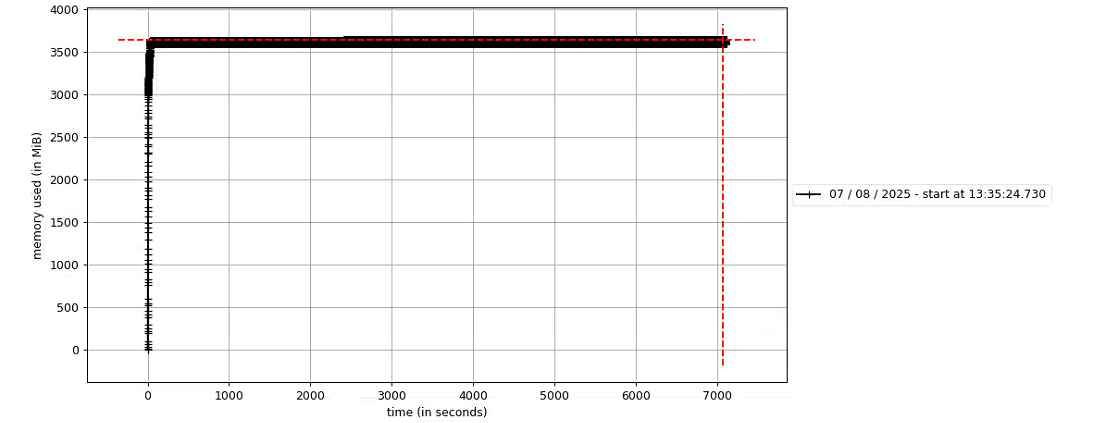
于是,繼續摸排問題,發現同樣的前處理,YOLO12-DET是沒有問題,再加上上圖的內存無變化情況,便排除前處理部分。
再次來到后處理及檢測結果轉換部分的內容,😓,饒了一圈再次回來。只能說抓住本質才是解決問題的唯一方法。
由于有之前的經驗,沒有再使用memory_profiler這個工具進行后處理各個部分的內存異常監測。這次我采用比較原始的方法,因為經過多次測試發現了一個內存開始增長的現象,就是只要程序一旦卡頓,內存就開始增長。
在這么做之前,把所有可能的結果都是嘗試了,結果無一解決這個問題。包括及時釋放變量內存、定時強制清理內存等等。
然后,把問題范圍縮小到當前的后處理代碼部分,以及避開內存監測工具。
現在就采用打斷電的方式,再次測試等到程序卡頓現象出現。打斷點就是在可以代碼前面加一行輸出。
print("this is fun1.")
def fun1print("this is fun2.")
def fun2等到程序停到這里不動的時候就可定定位到程序卡在哪一步了。
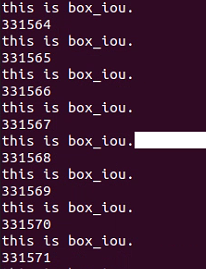
很快,程序很快就卡在bbox_iou這里了。程序在這里停住了,然后內存開始持續增長。
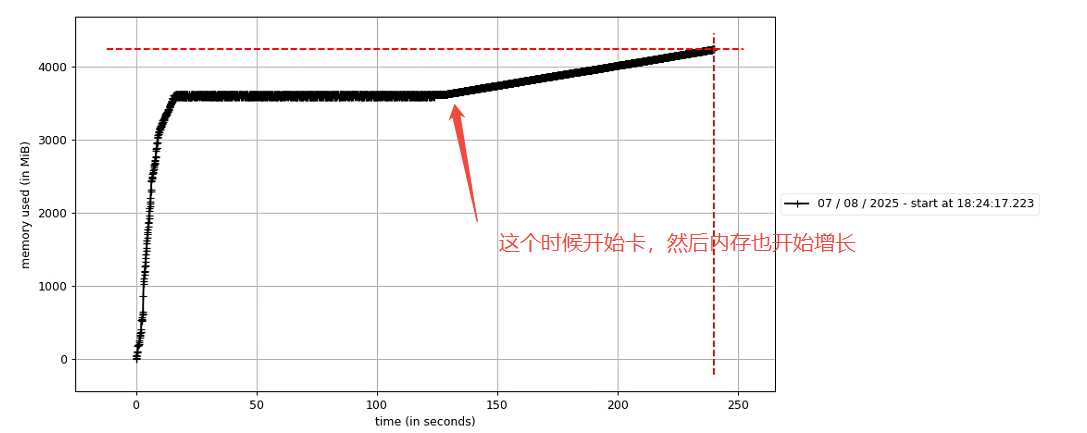
進一步打斷點,發現程序在bbox_iou的while循環里面空轉。
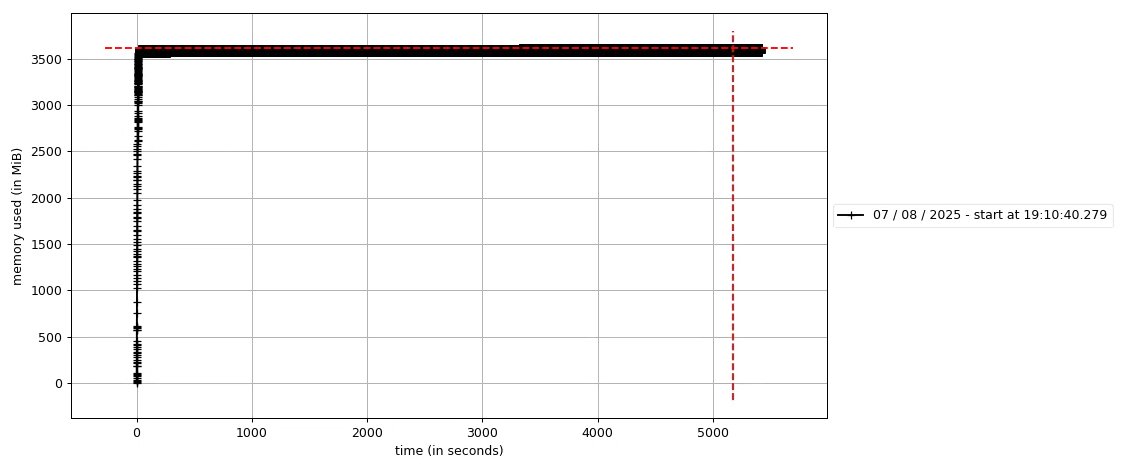
隨即對該死循環進行特殊處理,最新測試如下,5000s內無異常。至此該問題得到解決。
)

![[IOMMU]面向芯片/SoC驗證工程的IOMMU全景速覽](http://pic.xiahunao.cn/[IOMMU]面向芯片/SoC驗證工程的IOMMU全景速覽)

)

名稱空間的其他特性)







復制 的搭建)




