目錄
- CPU
- 1 概述
- 1.1 概念
- 1.2 馮諾依曼架構
- 1.3 常見參數(評估性能)
- 1.4 按指令集分類
- 2 CPU發展
- 2.1 發展史
- 2.2 行業產業鏈
- 2.3 英特爾 Xeon 至強處理器
- 2.4 AMD Zen架構
- 補充
- 1 寄存器、存儲器、內存、緩存、硬盤區別與聯系?
- 2 浮點單元
- 參考
本篇記錄和梳理服務器方面的知識,目前寫的還比較簡略,后續會逐步補充。
CPU
1 概述
1.1 概念
CPU(Central Processing Unit,中央處理器)是計算機系統的運算和控制核心,是信息處理、程序運行的最終執行單元。
(后面提到的馮諾依曼結構的運算器和控制器組成計算機的CPU)
CPU的工作流程:獲取指令→指令譯碼→執行指令→獲取數據→寫回數據
1.2 馮諾依曼架構
-
三個基本原則
數字計算機的數制采用二進制;
計算機應該按照程序/指令順序執行;
計算機由五個部分組成。 -
五個基本部分
運算器:用于完成各種算術運算、邏輯運算和數據傳輸等數據加工處理;
控制器:用于控制程序的執行,是計算機的大腦。控制器具有判斷能力,能夠根據計算結果選擇不同的工作流程。
存儲器:用于記憶程序和數據,如內存。程序和數據以二進制代碼形式不加區別地存放在存儲器中,存放位置由地址確定。
輸入設備:將數據或程序輸入到計算機中。
輸出設備:將數據或程序的處理結果展示給用戶。 -
基本功能
將需要的程序和數據送入計算機;
具有長期記憶程序、數據、中間結果以及最終運算結果的能力;
能夠完成各種算術運算、邏輯運算和數據傳輸等數據加工處理的能力;
能夠根據需要控制程序走向,并根據指令控制機器的各部件協調操作;
能夠按照要求將處理結果輸出給用戶。
1.3 常見參數(評估性能)
一般在市面上購買CPU時所看到的參數一般是以(主頻\前端總線\二級緩存)為格式的。例如Intel P6670的就是(2.16GHz\800MHz\2MB)。
- 主頻
CPU的時鐘頻率,指每秒CPU能夠運算的次數,主頻越高,CPU速度越快,直接決定了CPU性能。
超頻:通過提高CPU主頻獲得更高的性能。
降頻:節能模式下,系統CPU進行降頻,增強續航。
主頻=外頻×倍頻。
外頻:CPU的外部時鐘頻率,指CPU與主板連接的速度(與數字脈沖信號震蕩速度有關)。主板可調外頻越多、越高越好,對超頻有用。
倍頻:外頻與主頻相差的倍數。其作用是能夠使總線工作在相對較低的頻率上,而CPU速度無限提升。
-
核數
表示CPU的并行處理能力,核數越多,并行處理速度越快。 -
線程
指處理器的邏輯線程數量,一般一個核數對應一個線程。
超線程:一個物理核對應多個線程,即一個核心分為多個小的核心進行并行計算,實現單核可以并行處理多個事務。 -
緩存
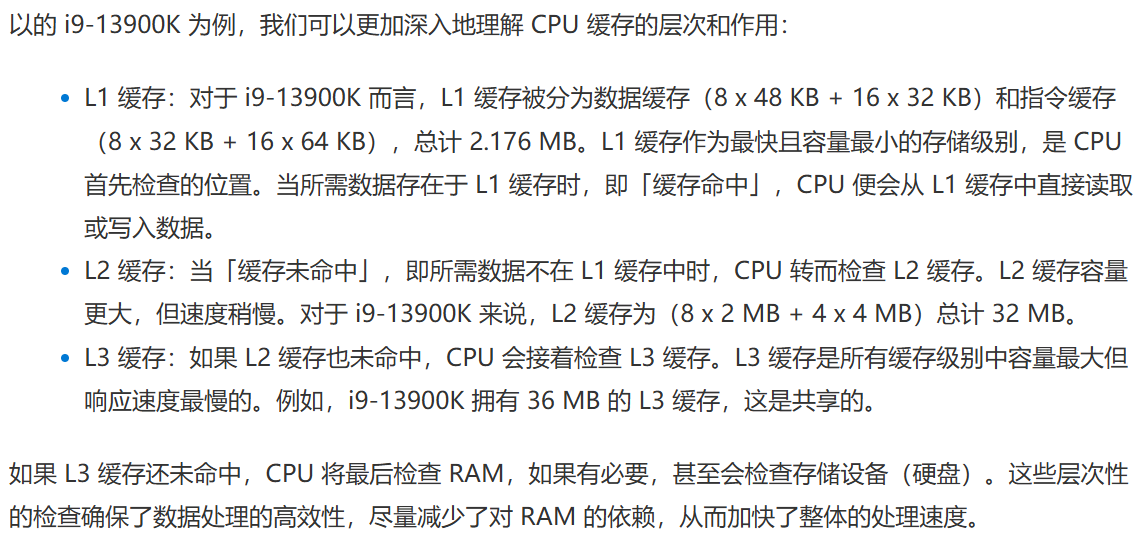
緩存是位于CPU內部的高速存儲器,用于臨時存放頻繁訪問的數據和指令,減少從主內存讀取數據的時間,加快處理速度。較大的緩存有助于提高性能。
目前由L1、L2、L3等不同級別的緩存,不同級別的緩存在緩存大小、響應速度(延遲)和數據命中率之間找到最佳平衡。
L1緩存:最快但容量最小,通常每個核心分配。容量范圍在128KB到2MB之間。
L2緩存:響應速度和容量居中,可以為核心獨有,也可以是共享的,容量范圍在256KB到32MB之間。
L3緩存:響應速度最慢但容量最大,通常是共享的,容量范圍在1MB到128MB之間。
舉例說明:
圖源:揭秘 CPU 緩存:L1、L2 和 L3 的性能秘密
-
FSB前端總線
表示了CPU和外界數據傳輸的速度。 -
TDP熱設計功耗
當芯片達到最大負荷時熱量釋放的指標,是電腦的冷卻系統必須有能力驅散熱量的最大限度。
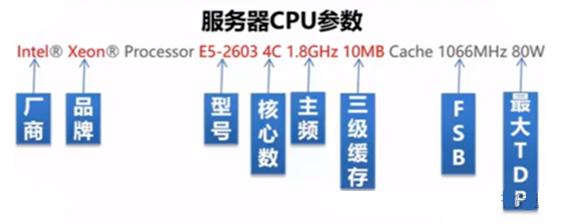
圖源:服務器內部細節:CPU、內存、硬盤等
1.4 按指令集分類
- 指令集是什么?
存儲在CPU內部,對CPU運算進行指導和優化的硬程序,用來引導CPU進行加減運算和控制計算機操作系統的一系列指令集合。
預先存儲的指令越多,CPU就越“聰明”。可以做的“動作”越多。預先存儲的指令越先進,CPU就越高級。
其實指令集就是一組匯編指令的集合,不同的CPU使用的指令集不同。
- RISC 與 CISC
RISC 全稱Reduced Instruction Set Compute,精簡指令集計算機。
CISC 全稱Complex Instruction Set Computers,復雜指令集計算機。
CISC既有簡單指令也有復雜指令,早期的CPU全部都是CISC架構。
后來人們發現典型程序中80%的語句都是使用計算機中20%的指令,而這20%的指令都屬于簡單指令;因此花再多時間去研究復雜指令,也僅僅只有20%的使用概率,并且復雜指令會影響計算機的執行速度。既然典型程序的80%都是使用簡單指令完成,那剩下的20%語句用簡單語句來重新組合一下模擬這些復雜指令就行了,而不需要使用這些復雜指令,于是RISC就出現了。
2 CPU發展
2.1 發展史
CPU從4位到8位、16位、32位處理器,最后到64位處理器,從各廠商互不兼容到不同指令集架構規范的出現,CPU 自誕生以來一直在飛速發展。
CPU的發展通常被分為六個階段。
① 第一階段1971-1973,4位和8位低檔微處理器時代,代表產品Inter 4004處理器。
1971年,Intel生產的4004微處理器將運算器和控制器集成在一個芯片上,標志著CPU的誕生;
1978年,8086處理器的出現奠定了X86指令集架構, 隨后8086系列處理器被廣泛應用于個人計算機終端、高性能服務器以及云服務器中。
② 第二階段1974-1977,8位中高檔微處理器時代,代表產品Inter 8080。
③ 第三階段1978-1984,16位微處理器時代,代表產品Inter 8086。
④ 第四階段1985-1992,32位微處理器時代,代表產品是Intel 80386。已經可以勝任多任務、多用戶的作業。
1989 年發布的80486處理器實現了5級標量流水線,標志著CPU的初步成熟,也標志著傳統處理器發展階段的結束。
⑤ 第五階段1993-2005,奔騰系列微處理器時代,1995 年11 月,Intel發布了Pentium處理器,該處理器首次采用超標量指令流水結構,引入了指令的亂序執行和分支預測技術,大大提高了處理器的性能, 因此,超標量指令流水線結構一直被后續出現的現代處理器,如AMD的銳龍、Intel的酷睿系列等所采用。
⑥ 第六階段2005至今,處理器逐漸向更多核心,更高并行度發展。典型的代表有英特爾的酷睿系列處理器和AMD的銳龍系列處理器。為了滿足操作系統的上層工作需求,現代處理器進一步引入了諸如并行化、多核化、虛擬化以及遠程管理系統等功能,不斷推動著上層信息系統向前發展。
注1:CPU執行一條指令需要經過以下階段:取指->譯碼->地址生成->取操作數->執行->寫回,每個階段都要消耗一個時鐘周期,同時每個階段的計算結果在周期結束以前都要發送到階段之間的鎖存器上,以供下一個階段使用。
注2:流水線技術是一種將每條指令分解為多步,并讓各步操作重疊,從而實現幾條指令并行處理的技術。
程序中的指令仍是一條條順序執行,但可以預先取若干條指令,并在當前指令尚未執行完時,提前啟動后續指令的另一些操作步驟。這樣顯然可加速一段程序的運行過程。超流水線:以增加流水線級數的方法來縮短機器周期,相同的時間內超級流水線執行了更多的機器指令(以時間換空間)。
超標量:在CPU中有一條以上的流水線,并且每時鐘周期內可以完成一條以上的指令(以空間換時間)。
超標量處理器執行指令的方式包括順序執行(in-order)和亂序執行(out-of-order)。
順序執行是指指令的執行必須遵循程序中指定的順序;
亂序執行是指指令在流水線中不遵循程序中指定的順序執行,一旦某條指令的操作數準備好就可以進行執行。
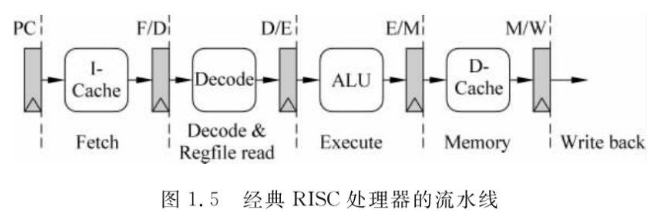
注3:經典RISC處理器的流水線
1 Fetch 取指令:PC寄存器值作為地址,從I-Cache中取址并存儲到指令寄存器。
2 Decode 譯碼:將指令解碼,并根據結果讀取寄存器堆,得到指令的源操作數。
3 Execute 執行:根據指令完成計算任務。
4 Memory 訪存:訪問D-Cache,不訪問存儲器的指令此階段不做任何事情。
5 Write Back 回填:如果指令存在目的寄存器,將指令結果寫入目的寄存器。
注4:流水線冒險,即在下一個時鐘周期中的下一條指令無法執行。分為結構冒險、數據冒險和控制冒險。
數據冒險(數據相關性):當指令在流水線中重疊執行,后面指令需要前面指令的執行結果,而前面的指令尚未寫回導致的沖突。
數據相關性的三種情況:RAW read after write 先寫后讀,WAW write after write 先寫后寫,WAR write after read 先讀后寫。
舉例:RAW,如果②指令在①指令前,引起邏輯錯誤。
① R1=R2+R3
② R5=R1+R4
解決方法:處理器核按順序派遣、順序寫回,則不可能發生WAR相關性造成的數據沖突。
舉例:WAW,如果②指令在①指令前,引起邏輯錯誤。
① R1=R2+R3
② R1=R5+R4
解決方法:采用outstanding instruction track fifo(OITF)模塊。
舉例:WAR,如果②指令在①指令前,引起邏輯錯誤。
① R1=R2+R3
② R2=R5+R4
解決方法:采用outstanding instruction track fifo(OITF)模塊。
結構冒險(資源沖突):當一條指令需要的硬件部分還在為之前的指令工作,無法為這條指令服務導致的沖突。
同時讀寫存儲器
解決方法:①流水線停頓stall。②設置單獨的指令高速緩存和數據高速緩存。
同時讀寫寄存器
解決方法:前半個周期寫,后半個周期讀,并且設置獨立的讀寫端口。
控制冒險:如果想要執行某條指令,是由之前指令的運行結果決定,而現在那條之前的指令結果還沒產生,導致了控制冒險。
解決方法:流水線停頓;縮短分支延遲;延遲轉移。
詳見:關于流水線的三種冒險
2.2 行業產業鏈
行業產業鏈上游為半導體材料和設備供應環節,主要包括硅晶圓、電子特氣、光刻膠、靶材等半導體材料,以及單晶爐、PVD、光刻機、檢測設備等半導體設備。
產業鏈中游為CPU芯片設計、制造及封裝測試環節,代表廠商有韋爾股份、紫光展銳、華大半導體、炬芯科技、國民技術、北京君正、龍芯中科、全志科技、國科微、紫光國微、國芯科技等。
產業鏈下游為CPU芯片應用領域,主要包括PC、平板電腦、通信及智能手機、智能穿戴、汽車電子、工業、醫療等。
2.3 英特爾 Xeon 至強處理器
英特爾 Xeon是英特爾生產的面向服務器和工作站的處理器,其特點是低頻多核,多線程運行強,功耗低相對穩定。
Purley平臺:Sky Lake 第一代,Cascade Lake 第二代;
Whitley平臺:Cooper Lake、Ice Lake 第三代;
Eagle Stream平臺:Sapphire Rapids 第四代、Emerald Rapids 第五代
Birch Stream平臺:Granite Rapids、Sierra Forest 第六代
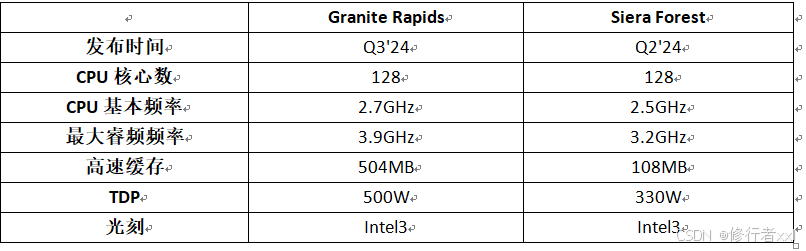
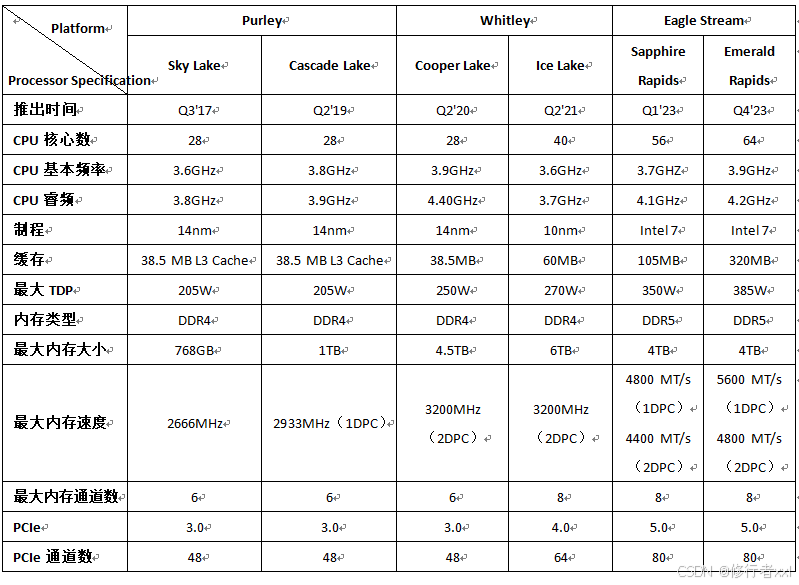
圖源:Intel Xeon(至強) 服務器 CPU
由圖可見,從第一代到第六代,CPU核數變化較大,從28到128。
注:TDP(Thermal Design Power,散熱設計功耗),對應系列CPU在滿負荷(CPU 利用率為100%的理論上)可能會達到的最高散熱熱量,散熱器必須保證在處理器TDP最大的時候,處理器的溫度仍然在設計范圍之內。
TDP設定越大,性能表現越強,但表明CPU在工作時會產生的熱量越大。TDP也可以看做是功耗墻,當主板檢測到當前處理器功耗達到設定值時,就會進行降頻等行為以保障系統整體的穩定性。
對于散熱系統來說,就需要將TDP作為散熱能力設計的最低指標/基本指標。
以Core i7-8700K處理器為例,它的TDP是95W,指的就是散熱器需要提供不低于95W的散熱能力。需要注意的是,TDP是熱設計功耗,不等于處理器功耗,是處理器損耗的熱功耗,英特爾特別強調它不是處理器的最大功耗。
TDP功耗測試不僅是跑基礎頻率,還不會涉及處理器的 AVX 浮點測試,而浮點單元現在是CPU功耗的大頭,跑不同的應用功耗差距極大就是這個因素導致的。盡管TDP不等于實際耗電功率,但它確實提供了一個參考點來估計CPU的功耗水平。
對于高性能CPU,尤其是在高負載情況下,實際耗電功率可能會接近甚至超過TDP值。在低負載或空閑狀態下,CPU的實際耗電功率通常遠低于其TDP。核心層面的處理器功耗分布:如果不涉及浮點運算,那么處理器中Cache緩存部分消耗了45%的功耗,OOO亂序執行/預測單元消耗21%的功耗,檢測網站是否被劫持,再次就是TLB單元了。但是運算要是涉及到了FP浮點單元,情況就不一樣了,FP浮點單元的功耗能占到75%,剩下的部分才是緩存、OOO以及TLB等等。
芯片層面的功耗分布:FP浮點單元依然是大頭,占比達到了45%,Uncore非核心部分的功耗占比達到了40%,整數單元、OOO、預讀、TLB之類的單元就更微不足道了。
英特爾Xeon可擴展處理器編號由4位數字組成:
第一個數字表示處理器級別:8、9表示鉑金Platinum,6、5表示金Gold,4表示銀Silver,3表示青銅Bronze。
第二個數字表示處理器代次。
鉑金Platinum:適用于計算性能和數據處理能力要求高的應用場景:大規模數據中心、高性能計算、企業級數據庫。
金Gold:適用于中高端企業級應用,性價比較高。
銀Silver:適用于中小型企業或部門級部署:輕量級虛擬化、入門級服務器。
銅Bronze:面向預算有限、性能要求不高:邊緣計算節點、個人工作站、基礎網絡服務。
詳見官網:了解可擴展處理器英特爾? 至強?:數字和后綴
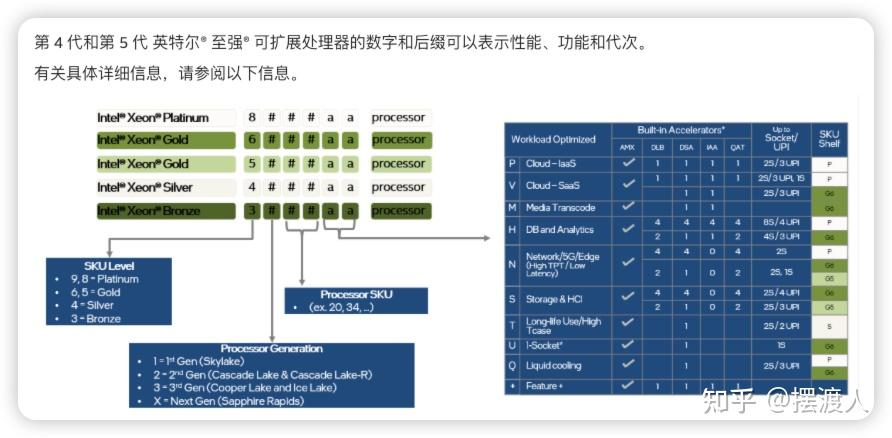
下圖為第五代Xeon產品
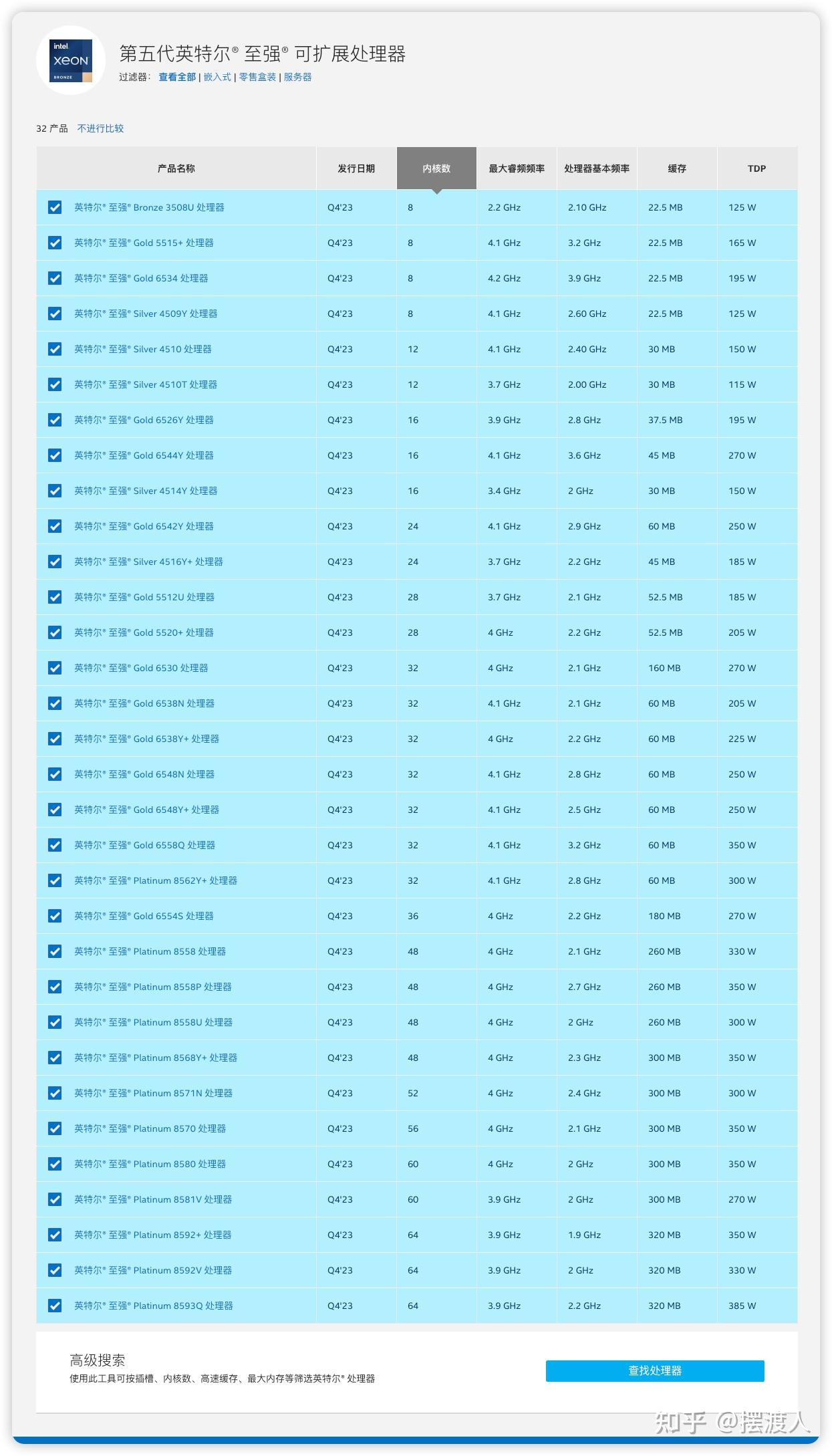
圖源:Inter至強處理器命名規則-【學習筆記】
2.4 AMD Zen架構
AMD在2017年正式推出了基于Zen微架構的Ryzen消費端處理器,體現IPC、頻率、功耗以及面積四者的平衡。
【處理器與AI芯片】AMD-Zen架構
補充
1 寄存器、存儲器、內存、緩存、硬盤區別與聯系?
寄存器用于即時計算;緩存用于加速對內存的訪問;內存用于運行中的程序和數據;SSD/HDD用于長期數據存儲。
數據通常按照“硬盤 -> 內存 -> 緩存 -> 寄存器”的路徑被加載到CPU進行處理。這種層次結構的設計旨在優化系統性能,通過將常用數據盡可能靠近CPU來加快處理速度。

CPU內部存在的存儲器叫做寄存器,用來暫時存放數據或指令。
內存是CPU能夠直接尋址訪問的存儲空間(不在CPU內部),是CPU與外存通信的橋梁。
RAM,Random Access Memory,隨機訪問存儲器。可讀取、可寫入,斷電后數據消失。
DRAM,動態隨機存儲。存儲單元是由電容和相關元件組成的,電容存在漏電現象,電荷不足會導致存儲單元數據出錯,所以DRAM需要周期性刷新,以保持電荷狀態。DRAM結構較簡單且集成度高,通常用于制造內存條中的存儲芯片。
SRAM,靜態隨機存儲。存儲單元是由晶體管和相關元件做成的鎖存器,每個存儲單元具有鎖存“0”和“1”信號的功能。它速度快且不需要刷新操作,但集成度差和功耗較大,通常用于制造容量小但效率高的CPU緩存。
ROM,Read Only Memory,只讀存儲器。只能讀入,不能寫入。即使處于停電狀態,這些信息也不會丟失。ROM一般用于存放計算機的基本程序和數據,如BIOS芯片。
Cache,高速緩沖存儲器。介于CPU與內存之間,是一個讀寫速度比內存更快的存儲器,用來臨時存放最近或最頻繁訪問的數據和指令。
當CPU向內存讀取或者存入數據時,這些數據也會被存儲進Cache中。當CPU再次需要訪問這些數據時,CPU就從Cache中讀取數據,而不是去訪問速度較慢的內存,當然了,如果Cache中沒有需要的數據,CPU會去訪問內存,讀取需要的數據。
內存包括由CLK(時鐘clock)驅動的寄存器;由SRAM制成的高速緩沖緩存器
電腦開機的時候CPU直接讀取BIOS指令,BIOS芯片也是ROM。
2 浮點單元
浮點處理單元(floating point unit,FPU)是運行浮點運算的結構。
FPU通常與CPU集成在一起,用于提供高效的浮點運算能力。
通過使用浮點計算單元,計算機能夠在處理需要高精度浮點數運算的應用程序中,如科學計算、圖形處理、物理模擬等,提供更加高效和精確的計算能力。
參考
[1] 一文介紹CPU(定義、分類、發展歷史、工作原理、應用、國產化)
[2] 馮諾依曼體系
[3] 服務器內部細節:CPU、內存、硬盤等
[4] 中央處理器
[5] (計算機組成原理)RISC與CISC的區別
[6] CPU的發展歷史和工作原理
[7] 超標量處理器流水線
[8] 關于流水線的三種冒險
[9] 主存、輔存、內存、外存、存儲器是什么?還傻傻分不清楚?看完這一篇就夠了
[10] 計算機中CPU、內存、緩存的關系
[11] Inter至強處理器命名規則-【學習筆記】
[12] TDP是什么 CPU TDP和最大功率的關系(轉)

)
















——MariaDB使用)
