作者:來自 Elastic?Gilad Gal

探索 Elasticsearch 的向量搜索如何以更快的速度、更低的成本提供更優結果。
試用向量搜索:使用這套自定進度的 Search AI 實操學習課程,親自體驗向量搜索。你可以開始免費云試用,或立即在本地機器上試用 Elastic。
在由 AI 驅動的搜索世界里,有三件事最重要:查詢速度、排序準確性,以及實現這些所需的資源成本。在 Elastic,我們持續在這三個方面突破極限。我很高興分享 Elasticsearch 9.1 中的兩項密集向量搜索新進展:一項名為 ACORN 的新算法,用于更快的過濾向量搜索;以及新證據表明,我們默認的量化方法 BBQ 不僅能降低成本,還可以提升排序質量。
ACORN:更智能的過濾搜索路徑
現實世界的搜索很少是簡單的“幫我找類似這個的東西”。它常常是 “幫我找尺碼合適的類似產品” 或 “幫我找和上個季度類似的文檔”。即使是避開已刪除文檔,也是一種過濾,因此實際中,過濾搜索非常常見。
讓過濾向量搜索既快速又不損失準確性,是一個深層的技術挑戰。 HNSW 算法基于圖搜索,圖中的節點表示向量。圖是在索引時構建的,而不是查詢時構建的。當支持預過濾時,為了得到準確結果(就像 Elasticsearch 所做的那樣),最直接的方法是在圖中遍歷,只收集通過過濾的節點。問題在于,這種方法仍然會評估未通過過濾的節點,以便繼續搜索它們的鄰居和整個圖,導致搜索變慢。當過濾條件較嚴格,大多數文檔不通過過濾時,這個問題尤其明顯。之前我們已有部分解決方案,但我們認為可以做得更好。
我們選擇使用 ACORN-1(ANN Constraint-Optimized Retrieval Network),這是一篇 2024 年學術論文中描述的新算法,用于執行過濾 k 近鄰(kNN)搜索。 ACORN 通過將過濾過程直接集成到 HNSW 圖遍歷中實現這一目標。使用 ACORN-1 時,只評估通過過濾的節點,但為了避免遺漏相關部分,會同時評估二級鄰居(即鄰居的鄰居),前提是它們也通過過濾。 Elasticsearch 使用的 Lucene 實現中還包含一些啟發式方法,進一步優化結果(詳見博客)。
在選擇具體算法和實現時,我們還探索了其他理論上可能進一步優化延遲的替代方案,但決定不采用它們,因為這些方法要求用戶在索引前聲明用于過濾的字段。而我們重視在文檔導入后仍可靈活定義過濾字段的能力,因為現實中的索引是不斷演變的。潛在的輕微性能提升不足以抵消靈活性喪失,我們也可以通過其他手段獲得性能,例如 BBQ(見下文)。
結果是性能的大幅提升。我們測得典型加速為 5 倍,在某些高選擇性過濾下提升更大。這對復雜的現實查詢是一項巨大增強。要使用 ACORN-1,只需在 Elasticsearch 中執行過濾向量查詢即可。
BBQ:更優排序的意外超能力
降低向量的內存占用對于構建可擴展、具成本效益的 AI 系統至關重要。我們的 Better Binary Quantization( BBQ )方法通過將高維 float 向量壓縮約 32 倍來實現這一目標。我們之前在 Search Labs 博客中已經討論過, BBQ 在召回率、延遲和成本方面優于諸如 Product Quantization 的其他技術:
-
Better Binary Quantization( BBQ )在 Lucene 和 Elasticsearch 中的應用
-
如何將 Better Binary Quantization( BBQ )應用于你的使用場景,以及為什么要這么做
-
Better Binary Quantization( BBQ ) vs. Product Quantization
不過,直觀的假設是,這種極大幅度、有損壓縮必然會犧牲排序質量。然而我們近期的大規模基準測試顯示,通過擴大圖遍歷范圍并重新排序,我們完全可以彌補這一點,不僅在成本和性能上實現提升,還能提高相關性排序的質量。
BBQ 不僅僅是壓縮技巧;它是一個復雜的兩階段搜索過程:
-
廣泛掃描:首先,使用體積極小的壓縮向量快速掃描數據集,識別出一組排名靠前的文檔。該集合的大小超過用戶請求的前 N 個結果(即超采樣)。
-
精確重排:然后,從初始掃描中選出頂級候選項,使用它們原始的高精度 float32 向量進行重排,確定最終順序。
這種超采樣加重排的過程是一種強大的校正機制,常常能發現純 float32 HNSW 搜索在其較有限圖遍歷中可能遺漏的高相關結果。
排序結果證明一切
為了衡量效果,我們使用了 NDCG@10(歸一化折扣累計增益@10),這是一項評估前 10 條搜索結果質量的標準指標。 NDCG 分數越高,說明相關性更高的文檔排名越靠前。你可以在我們的排序評估 API 文檔中了解更多信息。
我們在 BEIR 數據集中的 10 個公開數據集上運行了多項基準測試,比較了傳統 BM25 搜索、使用 e5-small 模型的向量搜索( float32 向量),以及同一模型結合 BBQ 的向量搜索。我們選擇 e5-small,是因為根據之前的基準測試, BBQ 在高維向量上表現最佳,而我們希望在其挑戰較大的場景下測試 BBQ —— 比如 e5-small 生成的低維向量。我們使用 NDCG@10 進行測量,這是一個考慮結果順序的排序質量指標。下面是我們觀察到的結果的代表性示例。
| Data set | BM25 | e5-small float32 | e5-small BBQ with defaults |
|---|---|---|---|
| Climate-FEVER | 0.143 | 0.1998 | 0.2059 |
| DBPedia | 0.306 | 0.3143 | 0.3414 |
| FiQA-2018 | 0.251 | 0.3002 | 0.3136 |
| Natural Questions | 0.292 | 0.4899 | 0.5251 |
| NFCorpus | 0.321 | 0.2928 | 0.3067 |
| Quora | 0.808 | 0.8593 | 0.8765 |
| SCIDOCS | 0.155 | 0.1351 | 0.1381 |
| SciFact | 0.683 | 0.6569 | 0.677 |
| Touché-2020 | 0.337 | 0.2096 | 0.2089 |
| TREC-COVID | 0.615 | 0.7122 | 0.7189 |
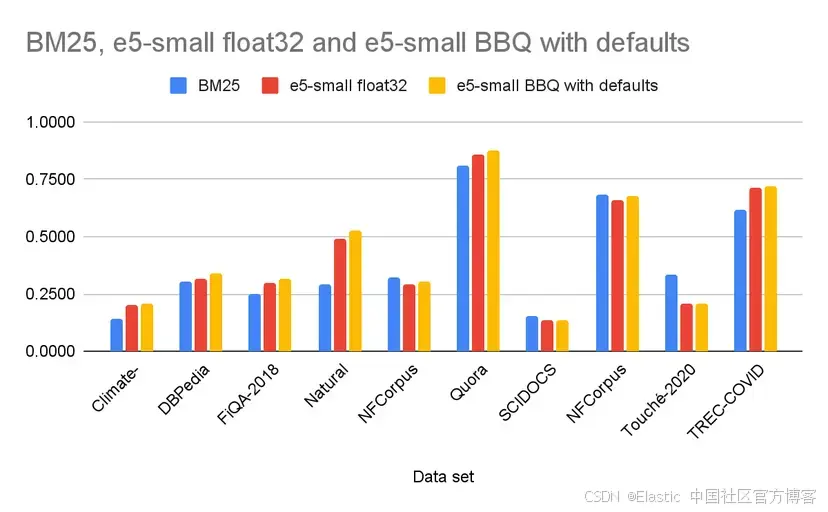
結果令人震撼。在 10 個數據集中, BBQ 在其中 9 個的排序質量優于純 float32 搜索。即便在唯一的例外中,差異也可以忽略不計。此外,在這 10 個數據集中, BBQ 是整體表現最好的方法之一,在 6 個數據集中排名第一。順帶一提,最佳排序結果通常是通過將 BM25 與向量查詢結合使用,并融合其他因素如距離、時間和熱度來獲得的,而 Elasticsearch 在這種類型的查詢中表現出色。
有人可能會問: BBQ 是有損壓縮,為什么它的排序會優于 float32?確實,在 BBQ 中我們進行超采樣并用 float32 向量進行重排,但理論上使用 float32 時,我們應該可以直接用 float32 向量為所有文檔排序。那么為什么 BBQ 排序反而更好?
答案在于:在 HNSW 中,我們每個分片只評估一部分向量,這由一個參數 num_candidates 決定。默認情況下,在未使用量化時, num_candidates = 1.5 * k,其中 k 是返回給用戶的結果數量。你可以在這里閱讀我們為確定該默認值所進行的基準測試。
而當我們使用 BBQ 進行量化時,向量比較速度更快,因此我們可以使用更大的 num_candidates,同時還降低了延遲。經過基準測試,我們將 BBQ 的默認 num_candidates 設置為 max(1.5 * k, oversample * k)。
對于上面的基準測試,我們使用默認設置,其中 k = 10,因此 num_candidates 的計算如下:
- Float32: 1.5*k = 1.5*10 = 15
- BBQ: max(1.5*k, oversample*k) = max(1.5*10, 3*10) = 30
由于 num_candidates 的不同,使用 BBQ 時我們掃描了更大范圍的 HNSW 圖,并在前 30 個候選中獲得了更優的結果,這些候選隨后由 float32 重排。這也解釋了 BBQ 如何帶來更好的排序質量。你可以根據自己的需求設置 num_candidates(例如見此),或者像大多數用戶一樣,信任我們的基準測試并使用默認值。
這也回答了我曾被咨詢的一個問題:“是用 e5-large 搭配 BBQ 更好,還是用 e5-small 搭配 float32 更好?”答案現在非常明確。使用更強大的模型 e5-large 搭配 BBQ,能夠兼得所有優勢:
-
更優排序:來自更強大的 e5-large 模型,再通過 BBQ 進一步增強。
-
更低延遲:得益于極高效率的 BBQ 搜索流程。
-
更低成本:由于內存縮減 32 倍。
這是一種三贏的局面,證明你無需在質量和成本之間做取舍。
正因為 BBQ 的優勢已經得到驗證,我們在 Elasticsearch 9.1 中將 BBQ 設為默認的量化方法,適用于維度 ≥ 384 的密集向量。我們推薦大多數現代嵌入模型使用該方法,這些模型通常能很好地在向量空間中分布,使其非常適合 BBQ 的方式。
今天就開始吧
ACORN 和 BBQ 的這些進展讓你能夠在 Elastic 上構建更強大、可擴展且具成本效益的 AI 應用。你可以以高速執行復雜的過濾查詢,同時提升排序相關性并大幅降低內存成本。
升級到 Elasticsearch 9.1,享受這些新功能。
- 在我們的文檔中了解更多關于 kNN 搜索和向量量化的內容。
- 通過我們的排序評估 API 深入了解排序質量。
我們幫你處理復雜性,讓你專注于打造出色的搜索體驗。祝搜索愉快。
原文:Elasticsearch now with BBQ by default & ACORN for filtered vector search - Elasticsearch Labs














——MariaDB使用)



)
