索引? 事務? JDBC~
目錄
一、MySQL索引
1.0 概述
2.0 相關操作
3.0 注意?
4.0 索引背后的原理的理解
二、 事務
1.0 原子性
2.0 隔離性
(1)并發執行
(2) 出現的問題
3.0 使用
三、JDBC編程
1.0 概述
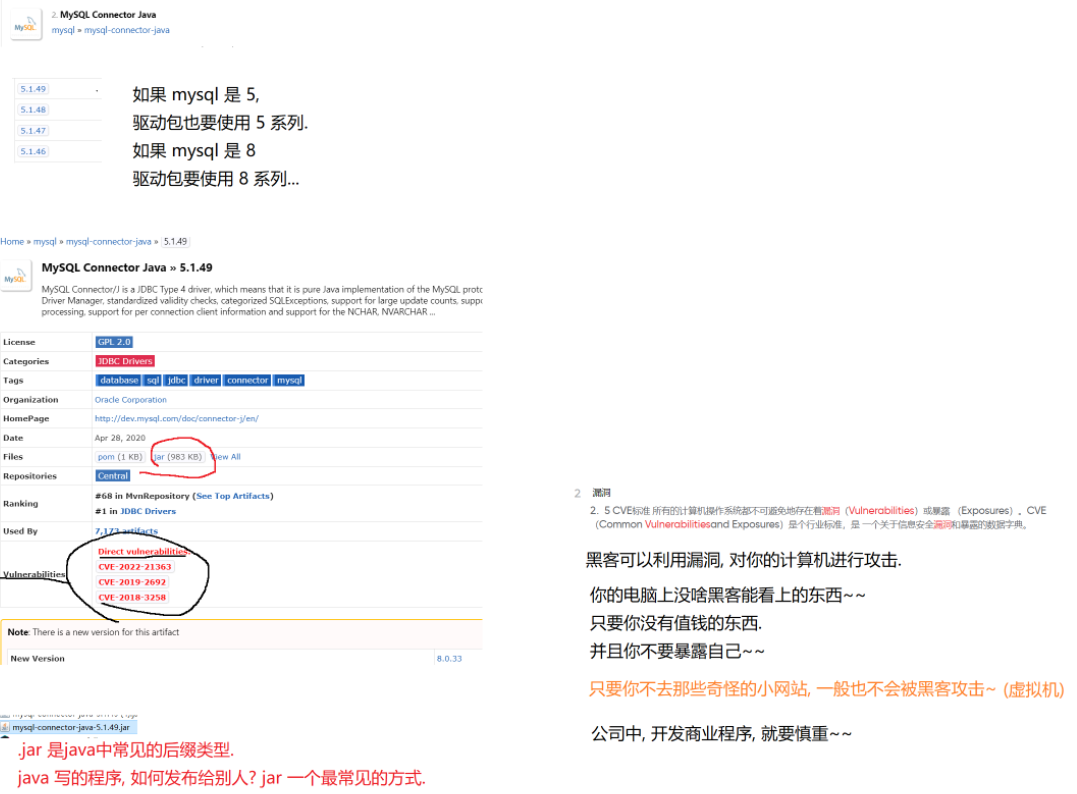
2.0 如何下載驅動包
3.0 jar如何引入到項目之中
4.0? ?jdbc編寫流程??
一、MySQL索引
mysql面試中考察的重點!
1.0 概述
索引(index)? ?當作一本書的目錄? 是用來加快查詢機制
select查詢查詢的時候 先要遍歷表? 如果表非常大 這樣的遍歷成本將會非常大 至少是O(N)
數據庫的數據存在硬盤上,每次讀取一個數據,都需要讀取硬盤,這個開銷本身就很大
在內存里面速度快 但是在硬盤中不是這樣的?
索引就產生了~
通過索引來加快查詢的速度,避免針對表進行遍歷
代價:占用更多的空間,生成索引,是需要一系列的數據結構,以及一系列額外的數據,來存儲到硬盤空間中的
可能降低插入 修改? 刪除的速度 (需要更新索引)
2.0 相關操作
(1) 查看索引? ? show index from 表名 ;?
??(2)? 創建索引? ? ?create index 索引名字? on? 表名(列名) ;
(3)刪除索引? ? drop index 索引名? on? ?表名;?
主鍵 unique? 外鍵 都會自動生成索引? (這些都是要求不能重復的? 自己引入索引這個時候根據索引就不需要遍歷了)??

手動創建的索引,可以手動刪除? 如果自動創建的索引,是不能刪除的!
一個索引是針對一個列來指定的? 只有針對這一列進行條件查詢的時候,查詢速度才能被索引優化
一本書可以有多個目錄,一個表也可以有多個索引
3.0 注意?
創建索引 也是一個危險操作 創建索引的時候,需要針對現有的數據,進行大規模的重新整理
刪除索引? 也是一個危險的操作
如果你當前是一個空表或者數據不多? 創建索引都沒有問題
如果這個表本來就很大,創建索引,有很容易就把數據庫服務器給卡住
一般來說,創建索引,都是在創建表的時候就規劃好了,一旦表已經使用很久了,有很多數據,需要修改索引,就要慎重了~
非要創建也不是不行 就需要一些其他的小技巧
一個做法是? 另外再搞一臺機器 部署服務器? 也創建同樣的表? 并且把表上面的索引創建好
再把之前的機器上的數據給導入到新的mysql服務器上面,導入數據的過程中就可以控制節奏
多花點時間沒事,補藥影響到原來的服務器正常的運轉就行
當所有的數據都導入完畢,就可以使用新的數據庫,替換舊的數據庫~~
數據庫和數據太重要了? 我們得萬分小心 避免數據損失或者丟失? ?
4.0 索引背后的原理的理解
索引也是通過一定的數據結構來實現的 .
紅黑樹? ?可以精準匹配? 也能范圍查詢? 也能模糊匹配
數據庫引入的索引是一個改進的樹形結構? B+ 樹? (N叉搜索樹)
(樹的內容之后迭代)? B+樹的優點?
mysql索引實現? 也是有一些變數的? 不是只有B+樹這一情況的
二、 事務
比較經典的面試題
事務的性質:原子性? ?一致性? ?持久性? 隔離性
原子性:回滾的方式? 保證這一系列操作? 都能執行正確? 或者恢復如初
一致性:事務執行之前? 和 之后? 數據都不能離譜(約束 一系列的檢查機制)
持久性:事務做出的修改 都是在硬盤上面持久保存的? 重啟服務器,數據仍然是存在的
隔離性:數據庫并發執行多個事務的時候 涉及到的問題
1.0 原子性
開發中經常會涉及到一些場景,需要’一氣呵成‘ 的完成一些操作
例如:張三給李四轉賬500? ? 張三的賬戶減500給李四
如果執行一半? 數據庫崩潰了或者斷電了? 這個時候怎么辦呢?
此時的數據就會出現不上不下的狀態? 非常明顯的bug??
引入事務就是為了避免上述問題~? ?事務就可以把多個sql打包成為一個整體
保證這些sql要么全部執行正確? 要么看起來一個都不執行
? 關鍵操作:翻新~~~? ?數據庫中稱為回滾? ?也就是回退機制? ? 沒有執行成功 回退回來
2.0 隔離性
數據庫并發執行多個事務的時候,涉及到的問題~~~
面試的時候 可能會考察 事務性質中比較復雜的一個性質
(1)并發執行
mysql是一個客戶端服務器結構的程序??
一個服務器可以給多個客戶端提供服務? ? 每個客戶端都會讓數據庫執行事務~~~
很有可能,客戶端1提交的事務1 執行了一半,客戶端2提交的事務也過來了
數據庫服務器就需要同時處理這兩個事務,并發執行(非常 常見的)?
如果我們希望數據庫服務器執行效率高,就希望提高并發程度,但是提高了并發程度之后,可能會存在一些問題~~~ 導致數據出現一些‘’ 錯誤 ‘’ 的情況
數據正確和效率之間做權衡: 往往提升了效率,就會犧牲正確性,提升了正確性就會犧牲效率
(2) 出現的問題
并發執行的時候會出現什么問題呢?
臟讀問題: 一個事務A正在寫數據的過程中,另一個事務B讀取了同一個數據
接下來事務A又修改了數據? 導致B之前讀到的數據是一個無效的(過時的) 數據
解決臟讀問題,核心思路,是針對寫操作加鎖??
(和別人約好,等我確認寫完了,提交到碼云上面,你從我的碼云上來看)?
這樣并發程度就降低了~~ 隔離性提高了? 效率降低了? 數據準確性提高了
不可重復讀問題:并發執行事務過程中,如果事務A在內部多次讀取同一個數據的時候,出現不同的情況,這種就是不可重復讀,事務A在兩次讀的之間,有一個事務B修改了數據并提交了事務
解決不可重復讀問題,核心思路,就是給讀操作加鎖 (約定同學們讀的時候,我也不能寫)?
這樣并發程度又進一步降低了 隔離性也提高了? 效率低了 數據的準確性又提高了
幻讀問題:一個事務A執行過程中,兩次的讀取操作,數據內容雖然沒有改變,但是結果集變了
約定了讀加鎖和寫加鎖? 我在寫代碼的時候,大家不能讀,只能讀碼云上提交的版本
大家在讀的時候 我也不能寫? ?此時已經解決了臟讀和不可重復讀問題
但是? 你們看A的時候 我寫B的代碼啊? 這樣可以保證,同學們在讀的時候,我可以干點啥,不至于完全閑著 此時 雖然我這邊沒有修改A代碼? 但是同學們突然發現,碼云上一下蹦出來個B代碼
數據雖然沒有改變 但是結果集變了
通過引入串行化的方式,解決幻讀,保持絕對的串行執行事務,此時完全沒有并發了? ? 根本上解決
此時的效率是最低的? 數據是最準確的? 效率是最低的? 數據是最準確的
(3)總結
效率和正確性? => 不同的需求場景就有不同的要求
mysql服務器也提供了? 隔離級別? 讓我們針對隔離程度進行設置
應付不同的需求場景情況? 有的場景追求是正確性? 效率是其次? 例如是充值轉賬一系列相關的場景
有的場景追求的是效率性? 正確性是其次? ?短視頻 點贊 投幣 轉發 評論?
隔離文件中? 可以直接在mysql配置文件中,修改數據庫的隔離級別? ?滿足不同的需求
(4) 隔離級別
四種隔離級別? 對應上述的問題
可重復讀是默認的隔離級別
臟讀? read uncommitted(讀未提交)? 并發程度最高,速度最快,隔離性最低,準確性最低
不可重復讀 read committed(讀已提交) 引入了寫加鎖? 只能讀 寫完之后提交的版本 xxxxxx
repeatable read (可重復讀)? ?引入寫加鎖和讀加鎖? 寫的時候不能讀? 讀的時候 不能寫?
幻讀? serializable(串行化)? ?嚴格的按照穿行的方式 一個一個的執行事務?
3.0 使用
事務的使用,其實是沒啥可說~~ 更主要的是要關注事務 背后的一些原理性質的內容
這個部分會考察面試題
start transaction? ?開啟事務,單獨執行的每個sql 都是自成一個體系
此時這些sql之間是沒有原子性的
/commit? 事務結束了
rollback 主動觸發回滾? ? 一般是要搭配一些條件判斷邏輯來使用的
sql里也能支持 條件 循環? 變量? 函數? 但是日常開發一般不會這么寫
更多的是搭配其他的編程語言
三、JDBC編程
通過Java代碼操作mysql數據庫
工作中一般不會直接使用idbc? ?面試也一般不考jdbc
jdbc這套api使用起來是比較繁瑣的? 因此有一些大佬把jdbc的api又進一步封裝,成了一些操作數據庫的框架(比如Mybatis ,jpa..........)
1.0 概述
數據庫編程,是需要數據庫服務器,提供一些API? 共程序猿調用的
API:?應用程序編程接口? ? 就是有一組類和函數? 提供給程序員調用
各種數據庫都有API 提供的api不同? ?即使有些api功能類似,細節上也會有差異
(這樣的做法苦了廣大程序員,增加了程序員的學習成本,非常的不友好,這個時候需要有分量的大佬站出來一統江湖? ? ?這個大佬就是? Java)
Java設計出了一套api的規范? ?你們提供的api都要和我這邊對接上~~~
程序員只要了解一套api,就可以操作各種數據數據庫了? 倒逼其他數據庫創建了對應的接口
而Java的這套接口就是? JDBC? (隔壁C++的程序員又饞哭了? C++官方不給力,各種開源混戰)
注意理解? 連接的東西就像是轉接頭一樣
2.0 如何下載驅動包
要想在程序中操作mysql 就需要安裝mysql的驅動包? ?并把驅動包引入到項目里
?(中央倉庫是一個很好的途徑)推薦一個:mvnrepository.com
3.0 jar如何引入到項目之中
先把jar包復制到項目目錄中? ? ? 目錄標記標記成為庫
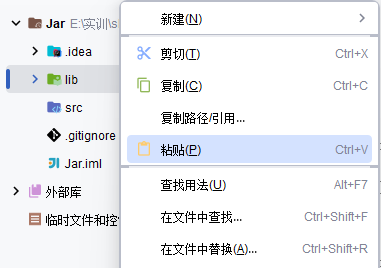
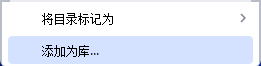
?每次創建工程都需要將這個jar包導入? ?補藥嫌麻煩
實際開發中,一兩年都沒機會創建項目
準備工作完成? 開始編寫代碼(demo? example tutor 翻譯過來都為? 例子)
4.0? ?jdbc編寫流程??
這一套代碼都是固定流程? ?一下子涌入新鮮的類 新鮮的方法 會覺得眼花繚亂
下來之后 把這些代碼動手多敲幾遍? 就會發現這個就是固定的流程? 比較簡單
(1)創建datasource 數據源
數據源? 表示數據的源頭? 數據庫服務器所在的位置
url? 表示網絡上的資源位置
ip:地址? ? 端口:電話號? ?127.0.0.1環回? ?自己把數據發送給自己
根據dataSorce 創建一個datasorce對象調用里面的方法
送快遞給xxx地址xxx人? ??
上面是一個準備工作? 沒有和真正的mysql服務器進行真正的連接
(2)和數據庫服務器建立連接
Connection connection = dataSource.getConnection();
即使是使用代碼操作數據庫? 仍然是依賴sql完成的
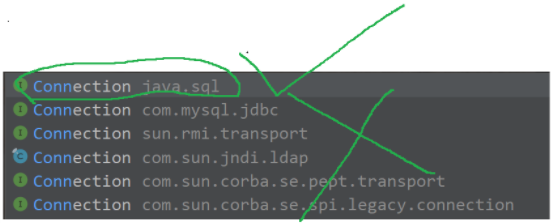
前面學過的各種sql? 在這里都是同樣適用的?
要注意的點是? 選擇的是 java.sql??
(3) 構造sql? ?發送給服務器
構造一個sql字符串? String sql = "insert into student values ( 1, '張三' ) " ;
prepared 準備好的/預處理的? ? ?statement 語句??
PreparedStatement statement = connection.prepareStatement(sql) ;?
(4)把sql語句發送給服務器? 執行sql
statement.executeUpdate();
excuteQuery()? ?select 讀操作
exectedUpdate()? ?insert 寫操作
(5) 釋放資源 關閉連接
statement.close();
connection.close()
執行完畢之后,最后一個步驟
程序通過代碼和服務器進行通信? ?是需要消耗一定的硬件/軟件資源的
在程序結束的時候,就需要告知服務器,釋放這些資源/客戶端也需要釋放資源
完整的代碼流程示例:
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;public class Demo1 {public static void main(String[] args) throws SQLException {//1.0 先創建一個數據源 描述數據源頭 數據庫服務器所在的位置DataSource dataSource = new MysqlDataSource();((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3307/java109?characterEncoding=utf8&useSSL=false");((MysqlDataSource)dataSource).setUser("root");((MysqlDataSource)dataSource).setPassword("1234");//2.0 和數據庫服務器建立連接 進行響應和交互操Connection connection = dataSource.getConnection();//3.0 構造sql 發給服務器String sql = "insert into student values(1,'張三') " ;//先構造出字符串的sqlPreparedStatement statement = connection.prepareStatement(sql);//準備好的/預處理的 語句//4.0 把sql發給服務器 返回一個整數 表示影響到的行數int n = statement.executeUpdate();System.out.println("n="+n);//5.0 執行完畢,最后一個步驟 釋放資源 關閉連接statement.close();connection.close();}
}
修改和刪除,代碼寫法和插入是非常類似的
從idea獲取輸入:
String sql = "insert into student values(?,?)";? 使用?作為占位符
PreparedStatement? statement? = connection.prepareStatement(sql) ;
statement.setInt(1,id);? 替換第幾個? 從1開始
statement,serString(2,name);
(6)使用jdbc執行查詢操作
和前面插入不同的地方:
4.0 執行sql?
ResultSet? resultSet? = statement.excuteQuery();
resultSet? 就表示查詢的結果集合(臨死表) 此處需要針對表進行遍歷
5.0 遍歷結果集合? 通過next方法就可以獲取到臨時表中的每一行數據
while(resultSet.next()){ }? //針對這一行進行處理? ?相當于在臨時表內部,有一個光標
取出列的數據? ?
int id = resultSet.getInt("id") ;
String? name = resultSet.getString("name");
System.out.println("id="+id +",name="+name);? ? ?多了一個遍歷結果集的過程
技術表層包含著很多想法、情緒、身體反應以及現實利益等
希望大家客觀的認識到這些部之后 迭代自己答案
至此 Mysql基礎內容迭代完畢? ? ?后續還有Mysql的進階部分
感謝大家的支持

更多內容還在加載中...........![]()
如有問題歡迎批評指正,祝大家生活愉快、學習順利!!!

:Dify 的核心組件 —— 從節點到 RAG 管道)


)






簡介與簡單示例)



)

![[python刷題模板] LogTrick](http://pic.xiahunao.cn/[python刷題模板] LogTrick)

![[2025CVPR-圖象分類方向]CATANet:用于輕量級圖像超分辨率的高效內容感知標記聚合](http://pic.xiahunao.cn/[2025CVPR-圖象分類方向]CATANet:用于輕量級圖像超分辨率的高效內容感知標記聚合)