研究方向:Image Captioning
論文全名:《Reason-before-Retrieve: One-Stage Reflective Chain-of-Thoughts for Training-Free Zero-Shot Composed Image Retrieval》
1. 論文介紹
組合圖像檢索(CIR)旨在檢索與參考圖像密切相似的目標圖像,同時整合用戶指定的文本修改,從而更準確地捕捉用戶意圖。
本文提出了一種新穎的無訓練的單階段方法,用于零樣本組合圖像檢索(ZS-CIR)的單階段反思思維鏈推理(OSrCIR),該方法采用多模態大型語言模型來保留必要的視覺信息在單階段推理過程中進行改進,消除了兩階段方法中的信息丟失。我們的反思思維鏈框架通過將操縱意圖與參考圖像的上下文線索對齊來進一步提高解釋準確性。
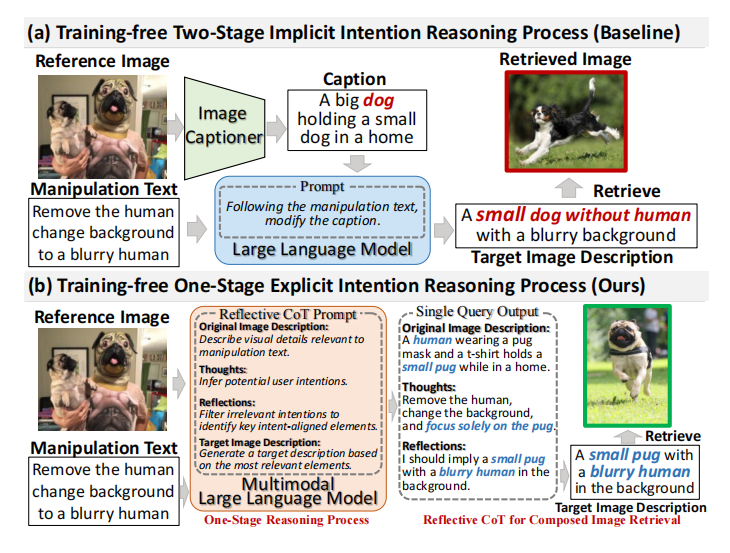
2. 方法介紹
給定一個參考圖像?和一個操作文本?
,ZS-CIR從圖像數據庫?
中檢索出與
在視覺上相似的圖像,同時結合
中指定的修改。
我們將目標圖像描述作為基于多模態大型語言模型(MLLM)
的組合查詢進行推理,為了確保?
以人類可理解的方式推理?
,我們引入了一個反思思維鏈提示
?。然后使用獲得的目標圖像描述
通過CLIP進行圖像檢索,并使用預訓練文本編碼器
將目標圖像描述
和候選圖像
嵌入到一個共享的、可搜索的空間中。用余弦相似度計算?
匹配分數。
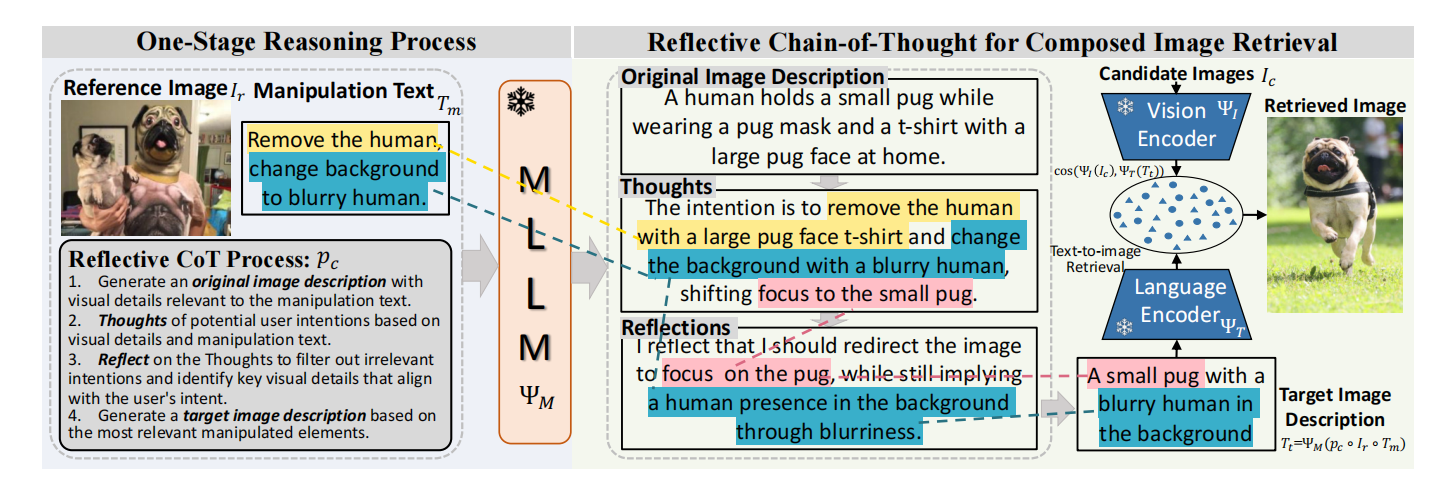
2.1 單階段推理過程
給定一個多語言語言模型??,我們按如下方式生成包含用戶對參考圖像
的操作意圖
的目標圖像描述
:
2.2 反思思維鏈用于ZS-CIR
反思CoT提示指導以下逐步推理步驟:
原始圖像描述:原始圖像描述步驟突出顯示參考圖像中與用戶意圖相關的視覺細節。
思考:思維步驟捕捉用戶的意圖和對可能被操縱的視覺元素的推理。
反思:進一步評估這些元素以識別那些最符合用戶意圖的內容。
目標圖像描述:基于與目標檢索最相關的視覺修改生成精煉的描述。
語境中的語言引導視覺學習:單純為反思性CoT過程提供指導對于大型語言模型理解每一步驟所需的CoT過程是不足夠的。我們利用在語境中學習的方法,該方法通過提供一些預期的大型語言模型輸出的文本示例,而不需要參考圖像,來指導大型語言模型在每個步驟中的推理過程。
組合圖像檢索:給定目標圖像描述?,我們的模型使用一個凍結的預訓練CLIP對圖像搜索數據庫?
?和
進行編碼。重新檢索到的目標圖像
確定如下:
其中選定的目標圖像是與生成的目標圖像描述最相似的一個。

)
)





——光照渲染Froxelizer實現分析)






)
:LangChain + LlamaIndex 實現)


