溫馨提示:
本篇文章已同步至"AI專題精講" Idefics2:構建視覺-語言模型時,什么是重要的
摘要
隨著large language models和vision transformers的進步,視覺-語言模型(VLMs)受到了越來越多的關注。盡管關于該主題的文獻非常豐富,我們觀察到在VLMs設計中的關鍵決策往往缺乏充分的論證。我們認為,這些未經支持的決策阻礙了該領域的進展,因為它們使得很難判斷哪些選擇能夠真正提升模型性能。為了解決這個問題,我們圍繞預訓練模型、架構選擇、數據和訓練方法進行了大量實驗。我們對研究結果的整合促成了Idefics2的開發——一個高效的、擁有80億參數的基礎VLM。Idefics2在多個多模態基準測試中,在同尺寸模型中達到了state-of-the-art的性能,并且常常能與體量大四倍的模型相媲美。我們發布了該模型(base、instructed和chat版本),以及為其訓練所創建的數據集。
1 引言
視覺-語言模型(VLMs)以圖像和文本作為輸入并輸出文本,可應用于許多任務,例如檢索掃描PDF中的信息(Hu et al., 2024)、解釋圖表或示意圖(Carbune et al., 2024)、識別圖像中的文字(Blecher et al., 2023)、統計圖片中的物體數量(Goyal et al., 2017),或將網頁截圖轉換為代碼(Lauren?on et al., 2024)。強大的開放large language models(Touvron et al., 2023;Jiang et al., 2023;Google, 2024b)與image encoders(Zhai et al., 2023;Sun et al., 2023;Radford et al., 2021)的發展,使研究者能夠基于這些單模態預訓練模型構建先進的VLMs,從而以更高精度解決上述問題(Dai et al., 2023;Liu et al., 2023;Bai et al., 2023;Lin et al., 2024, 2023;Li et al., 2024;Wang et al., 2024)。盡管該領域取得了顯著進展,但已有文獻中存在大量不同的設計選擇,這些選擇通常未經過充分實驗證明,或僅有非常簡略的描述。
這種情況使得我們很難判斷哪些決策真正決定了模型性能,從而也阻礙了整個社區在該方向上取得有依據的實質性進步。例如,(Alayrac et al., 2022;Lauren?on et al., 2023)使用交錯的基于Transformer的cross-attention模塊將圖像信息融合到language model中,而(Li et al., 2023;Liu et al., 2023)則將圖像hidden states的序列與文本embedding的序列拼接,并將拼接后的序列輸入language model。據我們所知,這種選擇尚未經過充分的消融實驗,其在計算效率、數據效率以及性能方面的權衡也尚不明確。本文旨在對這些核心設計選擇進行實證澄清,并提出一個關鍵問題:構建視覺-語言模型時,哪些因素很重要?
我們識別出兩個方面,不同工作通常會做出不同設計選擇:(a)模型架構,尤其是融合vision和text模態的connector模塊,以及它們對推理效率的影響;(b)多模態訓練過程及其對訓練穩定性的影響。針對這兩個方面,我們在受控環境中嚴格比較了不同的設計選擇,并提取了實證結論。我們特別發現:(a)VLMs的進展在很大程度上受益于單模態預訓練backbone的進步;(b)較新的全自回歸架構相較于cross-attention架構性能更優,但需要對優化過程進行調整以確保訓練穩定;(c)對預訓練vision backbone及連接text和vision模態的模塊進行調整,能在保證下游性能的前提下,一方面提高推理時的效率,另一方面支持圖像以原始比例和尺寸輸入;(d)圖像處理方式的修改可用于在推理成本與下游性能之間進行權衡。
我們的研究結果與(Karamcheti et al., 2024;McKinzie et al., 2024;Lin et al., 2024)中的發現互為補充,這些工作探討了多階段訓練、預訓練backbone的選擇性解凍、數據重復使用、訓練混合比對zero-shot和few-shot性能的影響。我們特別深入探討了此前尚未充分研究的方面,如模型架構、訓練方法、穩定性及推理效率的提升。
基于上述洞見,我們訓練了Idefics2——一個具有80億參數的基礎VLM。Idefics2在多個基準測試中,在其參數規模范圍內達到了state-of-the-art的性能,同時在推理效率方面表現更優,無論是base版本還是經過微調的版本。在某些視覺-語言基準上,其性能可與參數量大四倍的state-of-the-art模型媲美,并在部分挑戰性基準上達到了與Gemini 1.5 Pro相當的表現。我們公開了Idefics2的base、instructed和chat版本,以及用于訓練該模型的數據集,供VLM社區使用。
2 術語
我們首先確立用于討論不同設計選擇的統一術語。訓練VLMs通常需要將一個預訓練vision backbone與一個預訓練language backbone連接起來,方法是初始化新的參數以連接這兩個模態。這些新參數的訓練發生在預訓練階段。該階段通常使用大型多模態數據集(如圖文對)進行訓練。我們注意到,盡管從兩個單獨的單模態預訓練backbone出發是最常見的做法,但這兩個backbone的參數也可以共享并從頭開始初始化,如(Bavishi et al., 2023)所做的那樣。與large language models的文獻類似,預訓練階段之后通常還會進行instruction fine-tuning階段,在此階段中模型通過面向任務的樣本進行學習。
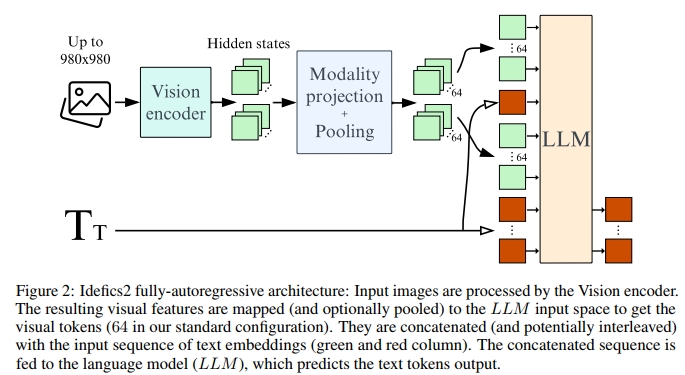
近期工作主要探索兩種將視覺輸入與文本輸入結合的方式。在cross-attention架構中(Alayrac et al., 2022;Lauren?on et al., 2023;Awadalla et al., 2023),通過vision backbone編碼的圖像信息被注入language model的不同層中,方式是交錯插入cross-attention模塊,其中文本對圖像的hidden states進行cross-attend。相比之下,在全自回歸架構中(Koh et al., 2023;Driess et al., 2023;Liu et al., 2023),vision encoder的輸出會被直接拼接到文本embedding的序列上,并將整個序列作為language model的輸入。因此,language model的輸入序列是視覺token和文本token的拼接。視覺token的序列可以選擇性地進行pooling,生成一個更短的序列以提升計算效率。我們將把vision hidden space映射到text hidden space的層稱為modality projection layers。圖2展示了我們最終在Idefics2中使用的全自回歸架構。
3 探索視覺語言模型的設計空間
在本節中,我們比較了視覺-語言模型文獻中常見的設計選擇,并指出相應的發現。除非另有說明,我們對每項消融實驗運行 6,000 步,并報告在 4 個下游基準任務上的 4-shot 平均性能,這些基準任務用于衡量不同的能力:VQAv2(Goyal et al., 2017)用于通用視覺問答,TextVQA(Singh et al., 2019)用于 OCR 能力,OKVQA(Marino et al., 2019)用于外部知識,COCO(Lin et al., 2014)用于圖像描述。
3.1 所有預訓練骨干網絡對于視覺語言模型(VLM)是否是等效的?
大多數近期的視覺-語言模型都基于預訓練的單模態 backbone。那么,backbone(視覺和文本)的選擇如何影響最終 VLM 的性能?
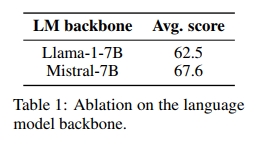
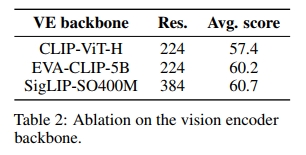
我們固定了預訓練 backbone 的大小、用于多模態預訓練的數據和訓練更新的次數。在交叉注意力架構下,我們觀察到在視覺-語言基準測試中的最大性能提升來自于更換語言模型。具體來說,替換 LLaMA-1-7B(Touvron et al., 2023)(在 MMLU(Hendrycks et al., 2021)上的得分為 35.1%)為 Mistral-7B(Jiang et al., 2023)(在 MMLU 上的得分為 60.1%)帶來了 5.1 的提升(見表 1)。此外,將視覺編碼器從 CLIP-ViT-H(Radford et al., 2021)(在 ImageNet(Deng et al., 2009)上的得分為 78.0%)更換為 SigLIP-SO400M(Zhai et al., 2023)(在 ImageNet 上的得分為 83.2%)帶來了基準測試性能的 3.3 提升(見表 2)。關于更好的視覺 backbone 的結果與(Karamcheti et al., 2024)中的觀察一致。我們注意到,Chen 和 Wang(2022)報告了通過擴展視覺編碼器的規模比擴展語言模型規模所帶來的性能提升更強,盡管擴展視覺編碼器會導致參數量的增加較小。盡管 EVA-CLIP-5B(Sun et al., 2023)在參數量上是 SigLIP-SO400M(Zhai et al., 2023)的十倍,但我們在四個基準上的表現相似,這表明 EVA-CLIP-5B 可能沒有得到充分訓練,我們也承認開放的 VLM 社區缺少一個經過良好訓練的大型視覺編碼器。
發現 1. 在固定參數數量的情況下,語言模型 backbone 的質量對最終 VLM 性能的影響大于視覺模型 backbone 的質量。
3.2 完全自回歸架構與交叉注意力架構如何比較?
據我們所知,目前沒有對完全自回歸架構和交叉注意力架構進行充分的比較。我們旨在填補這一空白,通過考慮它們的權衡,具體包括性能、參數量和推理成本。
根據 (Alayrac et al., 2022) 的研究,我們首先通過凍結單模態 backbone 并僅訓練新初始化的參數(交叉注意力架構一側,模態投影及學習的池化架構另一側)來比較這兩種架構,同時固定訓練數據的數量。Alayrac et al.(2022)表明,交叉注意力模塊與語言模型層交錯的頻率越高,視覺-語言性能就越好。因此,我們注意到,在這種設置下,交叉注意力架構的可訓練參數比完全自回歸架構多 13 億(總共 20 億可訓練參數)。此外,在推理時,前者比后者多使用 10% 的浮點運算量。在這些條件下,我們觀察到,交叉注意力架構在表 3 中的性能比完全自回歸架構高 7 個點。
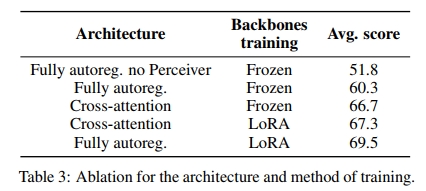
在總參數數量中,完全自回歸架構大約有 15% 的參數被訓練,而交叉注意力架構有 25% 的參數被訓練。我們假設這個低比例限制了訓練的表達能力,從而影響了性能。為了驗證這一假設,我們通過解凍所有參數(包括新初始化的參數和預訓練的單模態 backbone 參數)來比較這兩種架構。在這些條件下,訓練完全自回歸架構會導致損失發散,即使通過大幅降低學習率或逐步解凍不同組件,我們也未能成功穩定訓練。為了克服這一穩定性挑戰,我們利用了低秩適配(Low-Rank Adaptation,Hu et al., 2022)來適配預訓練的參數,同時對新初始化的參數使用標準的完全微調。
這種設置大大提高了訓練的穩定性,更重要的是,我們觀察到在完全自回歸架構下性能提高了 12.9 個點,而在交叉注意力架構下提高了 0.6 個點。雖然交叉注意力架構在凍結的 backbone 上表現優于完全自回歸架構,但當我們為預訓練的 backbone 提供更多自由度時,交叉注意力架構的表現變差。此外,使用 LoRA 使得訓練單模態 backbone 的 GPU 內存成本僅為完全微調的極小一部分,并且 LoRA 層可以合并回原始的線性層,在推理時不增加額外的成本。因此,我們在本研究的其余部分選擇了完全自回歸架構。
有趣的是,這一發現與 (Karamcheti et al., 2024) 中的結果相矛盾,該研究中作者觀察到解凍預訓練的視覺 backbone 會顯著降低性能。我們假設,使用參數高效的微調方法是關鍵區別。
發現 2:當單模態預訓練 backbone 保持凍結時,交叉注意力架構的表現優于完全自回歸架構。然而,當訓練單模態 backbone 時,完全自回歸架構超越了交叉注意力架構,盡管后者具有更多參數。
發現 3:在完全自回歸架構下解凍預訓練的 backbone 可能導致訓練發散。利用 LoRA 方法仍然能為訓練增加表達能力并穩定訓練過程。
3.3 效率提升在哪里?
視覺標記的數量
最近的視覺語言模型(VLMs)通常將視覺編碼器的整個隱藏狀態序列直接傳遞到模態投影層,然后輸入到語言模型中,而不進行池化。這一做法的動機來自于先前的研究,其中發現添加池化策略(例如平均池化)會導致性能下降(Vallaeys et al., 2024)。這種做法的結果是每個圖像的視覺標記數量較高,從 DeepSeek-VL(Lu et al., 2024)的 576 到 SPHINX-2k(Lin et al., 2023)的 2890 不等。由于生成的序列長度較大,訓練計算開銷較大,并且交替的圖像和文本的上下文學習也變得具有挑戰性,因為它需要對語言模型進行修改以處理非常大的上下文窗口。
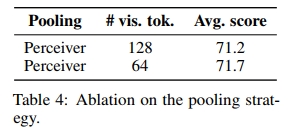
我們通過使用感知器重采樣器(Jaegle et al., 2021;Alayrac et al., 2022;Bai et al., 2023)作為一種可訓練的 Transformer 形式池化,減少了每個圖像隱藏狀態的序列長度。查詢數量(也稱為潛在變量)對應于池化后每個圖像的視覺標記數量。我們觀察到學習池化在兩方面都很有效:它平均提高了 8.5 個點的性能,并且將每個圖像所需的視覺標記數量從 729 降至 64(見表 3)。
與(Vallaeys et al., 2024;McKinzie et al., 2024)發現的更多視覺標記提高性能的結果不同,我們觀察到當使用超過 64 個視覺標記時,性能沒有提高。我們假設在無限訓練和無限數據的假設情境下,性能可能最終會提高,但這會導致訓練時間延長。對 Perceiver 架構的其他變體(Ma?as et al., 2023;Darcet et al., 2024;Vallaeys et al., 2024)則導致了性能下降。
Finding 4. 使用學習池化減少視覺標記數量顯著提高了訓練和推理的計算效率,同時提升了下游任務的性能。
保持原始縱橫比和圖像分辨率
視覺編碼器,如 SigLIP,通常在固定大小的正方形圖像上進行訓練。調整圖像大小會改變其原始縱橫比,這在需要讀取長文本的任務中尤為問題明顯。此外,訓練僅基于單一分辨率大小會固有地帶來局限性:低分辨率會遺漏重要的視覺細節,而高分辨率則會導致訓練和推理效率的低下。允許模型在不同分辨率下對圖像進行編碼,使用戶能夠根據需要決定每張圖像所花費的計算量。

根據 Lee et al. (2023) 和 Dehghani et al. (2023) 的方法,我們將圖像補丁傳遞給視覺編碼器,而不調整圖像大小或修改其縱橫比。鑒于 SigLIP 是在固定大小的低分辨率正方形圖像上進行訓練的,我們對預訓練的位置信息進行插值,以允許使用更高的分辨率,并使用 LoRA 參數訓練視覺編碼器以適應這些修改。我們的研究結果表明,保持縱橫比的策略在下游任務上保持了性能水平,同時在訓練和推理過程中解鎖了計算靈活性(見表 5)。特別是,無需將圖像調整為相同的高分辨率,可以節省 GPU 內存,并處理圖像所需的分辨率。
Finding 5. 將預訓練于固定大小正方形圖像的視覺編碼器調整為保持圖像原始縱橫比和分辨率,不僅不會降低性能,還能加速訓練和推理,并減少內存使用。
3.4 如何在性能和計算之間進行權衡?
(Lin et al., 2023; Li et al., 2024; Liu et al., 2024; McKinzie et al., 2024) 提出,通過將圖像分割為子圖像,可以在不改變模型結構的情況下提升下游性能。圖像被分解為子圖像(例如,4個相等的子圖像),然后與原始圖像拼接,形成一個由5個圖像組成的序列。此外,子圖像會被調整為與原始圖像相同的大小。然而,這一策略的代價是顯著增加了需要編碼的視覺標記數量。
我們在指令微調階段采用了這一策略。每個圖像變成5個圖像的列表:4個裁剪圖像和原始圖像。這樣,在推理時,模型既能處理獨立的圖像(每個圖像64個視覺標記),也能處理經過人工增強的圖像(每個圖像總共320個視覺標記)。我們注意到,這一策略對像TextVQA和DocVQA這樣的基準任務特別有用,這些任務需要足夠高的分辨率來提取圖像中的文本(見表9)。
此外,當我們僅對50%的訓練樣本應用圖像分割(而不是對100%的樣本進行分割)時,我們發現這并不會影響圖像分割所帶來的性能提升。令人驚訝的是,我們在評估時發現,增加子圖像(以及獨立圖像)的分辨率相比于單獨的圖像分割,帶來的性能提升僅為微小:將子圖像的分辨率提高到最大值時,TextVQA驗證集上的準確率為73.6%,而僅通過圖像分割時為73.0%;而在DocVQA驗證集上,分別為72.7和72.9的ANLS(見表9)。
Finding 6. 在訓練過程中將圖像分割為子圖像可以在推理時通過計算效率換取更多的性能。性能的提升在涉及圖像中文本讀取的任務中尤為明顯。
溫馨提示:
閱讀全文請訪問"AI深語解構" Idefics2:構建視覺-語言模型時,什么是重要的
)
)





——光照渲染Froxelizer實現分析)






)
:LangChain + LlamaIndex 實現)



)