溫馨提示:
本篇文章已同步至"AI專題精講" DeepSpeed-FastGen:通過 MII 和 DeepSpeed-Inference 實現大語言模型的高吞吐文本生成
摘要
隨著大語言模型(LLM)被廣泛應用,其部署與擴展變得至關重要,用戶對高吞吐量與低延遲的推理服務系統提出了更高的要求。現有的推理框架在應對長提示詞任務時難以兼顧這兩方面的需求。本文提出 DeepSpeed-FastGen,一個使用全新提示與生成階段融合策略 —— Dynamic SplitFuse 的系統,相較于最先進的系統(如 vLLM),其實現了最多 2.3 倍的有效吞吐量提升、平均 2 倍的延遲降低,以及最多 3.7 倍的 token 級尾部延遲降低。該系統結合了 DeepSpeed-MII與 DeepSpeed-Inference 的優勢,為 LLM 提供了高效且易于使用的推理服務平臺。
DeepSpeed-FastGen 擁有先進的實現機制,支持多種模型,提供持久化與非持久化兩種部署方式,適用于從交互式會話到長時間運行的各種場景。我們提出了詳細的基準評估方法,通過 延遲-吞吐曲線 進行性能分析,并從 負載均衡 的角度探討了系統的可擴展性。實驗表明,在不同模型與硬件配置下,DeepSpeed-FastGen 在吞吐量與延遲方面均有顯著改進。我們還討論了未來的發展計劃,包括支持更多模型與新型硬件后端。DeepSpeed-FastGen 的代碼已開放,鼓勵社區使用與貢獻。
1 引言
大型語言模型(LLM)如 GPT-4 [1] 和 LLaMA [2] 已成為廣泛應用中的主要算力負載。在從通用聊天模型、文檔摘要,到自動駕駛及軟件棧各層的 AI 助手等場景中,這類模型的部署與服務需求呈爆發式增長。雖然 DeepSpeed、PyTorch [3] 等框架在 LLM 訓練期間通常能夠實現較高的硬件利用率,但在推理階段,尤其是涉及開放式文本生成任務時,由于計算強度較低,交互式應用的本質反而成為吞吐性能的瓶頸。
為此,諸如基于 PagedAttention 的 vLLM [4] 和研究系統 Orca [5] 等框架已經大幅提升了 LLM 推理性能。然而,這些系統仍難以為長提示任務提供穩定的服務質量。隨著越來越多的模型(如 MPT-StoryWriter [6])和系統(如 DeepSpeed Ulysses [7])支持擴展到數萬個 token 的上下文窗口,長提示任務正變得日益重要。
為了更好地理解問題空間,本文展示了文本生成過程的兩個關鍵階段:提示處理(prompt processing) 與 生成(generation)。當系統將這兩個階段分別處理時,生成過程會被提示階段中斷,從而有可能破壞服務級別協議(SLA)。
對此,本文提出 DeepSpeed-FastGen,該系統通過所提出的 Dynamic SplitFuse 技術克服上述限制,帶來了最高 2.3 倍吞吐提升、2 倍延遲下降,以及 3.7 倍 token 級尾延遲降低,超越了現有最先進系統如 vLLM。DeepSpeed-FastGen 結合 DeepSpeed-MII 與 DeepSpeed-Inference,提供一個易于部署、性能卓越的 LLM 服務平臺。
2 相關文獻中的 LLM 服務技術
一個文本生成任務通常包括兩個階段:
1)提示處理(prompt processing):將用戶提供的文本處理為一個 token 批次,并構建注意力機制所需的 key-value(KV)緩存;
2)token 生成(token generation):每次向 KV 緩存添加一個 token,同時生成下一個 token。
在完整生成一個文本序列的過程中,模型會進行多次前向調用,以逐步生成完整序列。已有文獻與系統提出了兩類主要技術,以應對這兩個階段中可能出現的各種瓶頸與限制。
2.1 分塊 KV 緩存
vLLM 指出,傳統 LLM 服務系統使用的大型連續 KV 緩存會導致顯著的內存碎片問題,從而嚴重影響并發性能。為了解決這一問題,vLLM 提出了 PagedAttention [8],使緩存可以為非連續的,從而提高系統總吞吐量。
具體來說,PagedAttention 不再為每個請求分配一個可變大小的連續內存塊,而是采用固定大小的塊(page)進行存儲。通過這種“分塊 KV 緩存”方式,消除了因 KV 緩存造成的內存碎片,從而顯著提升了系統能夠同時服務的序列數量。
非連續 KV 緩存的實現也已在 HuggingFace TGI [9] 和 NVIDIA TensorRT-LLM [10] 中得到采用。
2.2 持續批處理
在早期,為提升 GPU 利用率,系統通常采用 動態批處理(dynamic batching):服務器會等待多個請求到達并同步處理。然而,這種方式存在明顯缺陷 —— 要么需要對輸入進行填充(pad)使其長度一致,要么會為了組建大批次而阻塞系統。
近期的 LLM 推理研究更注重細粒度調度與內存效率的優化。例如,Orca 提出了 迭代級調度(iteration-level scheduling),也稱為 持續批處理(continuous batching),在模型的每次前向調用中都進行獨立的調度決策。這種方式允許請求按需加入/離開批次,避免了填充輸入的需要,從而提升整體吞吐量。
除了 Orca,NVIDIA TRT-LLM、HuggingFace TGI 和 vLLM 等系統也實現了持續批處理。
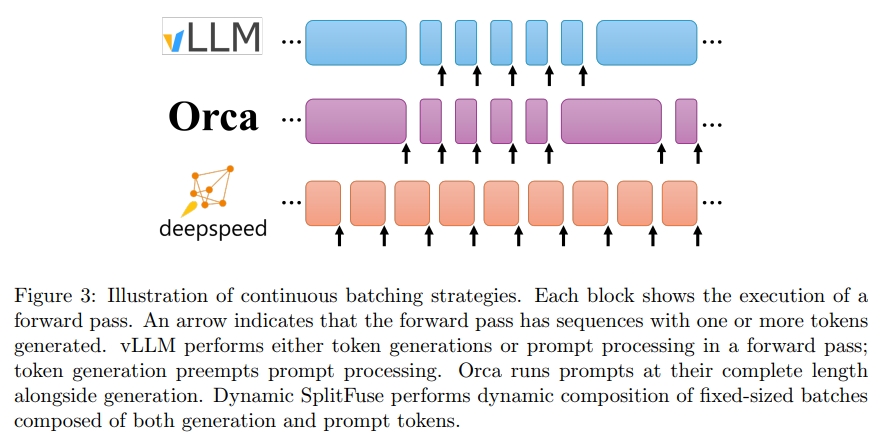
目前的系統中,持續批處理主要有兩種實現方式:
- 在 TGI 與 vLLM 中,生成階段可能會被中斷以處理提示(在 TGI 中稱為 infill),之后才繼續生成;
- 在 Orca 中,不再區分提示處理與生成階段,只要總序列數未超過預設上限,系統就可將新的提示加入正在運行的批次。
這些策略不同程度上都需要 暫停生成過程 來處理長提示(見第 3.2 節)。
為此,我們提出了一種全新的提示與生成融合策略 —— Dynamic SplitFuse,將在下一節詳細討論。
3 Dynamic SplitFuse:一種新穎的提示與生成融合策略
DeepSpeed-FastGen 構建于 持續批處理(continuous batching) 與 非連續 KV 緩存(non-contiguous KV caches)的基礎之上,旨在提升 LLM 在數據中心中的并發率與響應能力,類似于 TRT-LLM、TGI 和 vLLM 等框架。為了在此基礎上進一步提升性能,DeepSpeed-FastGen 引入了 SplitFuse 技術,它通過 動態提示與生成的拆解與融合(decomposition and unification),進一步優化持續批處理機制并提升系統吞吐能力。
3.1 三個性能洞察
在介紹 Dynamic SplitFuse 之前,我們先回答三個關鍵的性能問題,這些問題共同構成了其設計動機。
3.1.1 哪些因素會影響單次前向傳遞的性能?
為了實現有效的調度,有必要理解調度循環應控制哪些關鍵的獨立變量。我們的觀察表明,在一次前向傳遞中,序列的組成(即序列的 batch size)對性能的影響可以忽略不計,相比之下,前向傳遞中總的 token 數量才是決定性因素。這意味著,一個高效的調度器只需圍繞“前向傳遞中的 token 數量”這一單一信號進行設計即可。
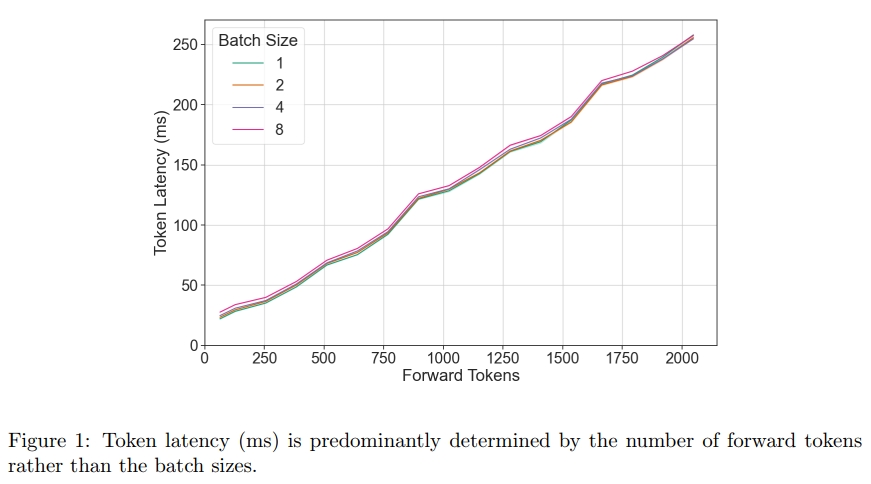
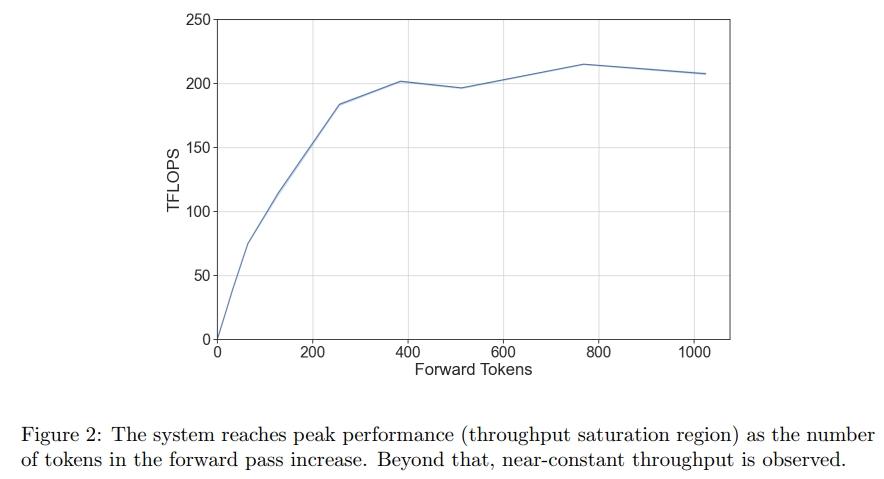
3.1.2 模型的吞吐量如何隨著前向傳遞中 token 數量的變化而變化?
一個大型語言模型(LLM)在運行中存在兩個主要的性能區域,并且它們之間的過渡相對陡峭:
- 當 token 數量較少 時,GPU 的瓶頸主要是從內存中讀取模型參數,因此吞吐量會隨著 token 數量的增加而線性提升;
- 當 token 數量較多 時,模型的瓶頸轉為 計算資源,此時吞吐量趨于飽和,基本保持恒定。
因此,如果所有前向傳遞操作都處于吞吐量飽和區間,模型就能以極高的效率運行。
3.1.3 應如何在多個前向傳遞中調度一組 token?
我們在上文中觀察到,對于對齊良好的輸入,其 token 吞吐曲線是凹形的,這意味著二階導數小于或等于 0。舉例來說,設 f(x)f(x)f(x) 是一個模型從延遲到吞吐量的凹函數。對于凹函數 f(x)f(x)f(x),以下性質成立:
0≥lim?h→0f(x+h)?2f(x)+f(x?h)h20≥f(x+h)?2f(x)+f(x?h)2f(x)≥f(x+h)+f(x?h)\begin{array} { c } { 0 \geq \displaystyle \operatorname* { l i m } _ { h \to 0 } \frac { f ( x + h ) - 2 f ( x ) + f ( x - h ) } { h ^ { 2 } } } \\ { 0 \geq f ( x + h ) - 2 f ( x ) + f ( x - h ) } \\ { 2 f ( x ) \geq f ( x + h ) + f ( x - h ) } \end{array} 0≥h→0lim?h2f(x+h)?2f(x)+f(x?h)?0≥f(x+h)?2f(x)+f(x?h)2f(x)≥f(x+h)+f(x?h)?
這表明,對于給定的 2x 個 token,如果希望最大化吞吐量,最優的方式是將它們平均分配到兩個 batch 中。更一般地說,在一個系統需要在 F 次前向傳遞中處理總共 P 個 token 的情況下,理想的劃分策略是將這些 token 盡可能平均地分配。
3.2 Dynamic SplitFuse
Dynamic SplitFuse 是一種用于 prompt 處理與 token 生成的新型 token 組合策略。DeepSpeed-FastGen 利用 Dynamic SplitFuse 的策略,在每次前向傳播中保持一致的 token 數量,具體方法是將 prompt 中的一部分 token 與生成部分組合在一起處理,從而實現統一的前向尺寸。類似的做法曾在 Sarathi [11] 中被提出,它將 prompt 拆分成更小的塊,以便將更多的 token 生成與 prompt 處理結合起來,從而使前向傳播保持一致的 batch 大小。
具體而言,Dynamic SplitFuse 執行以下兩個關鍵行為:
- 將長 prompt 拆分為更小的塊,并分配到多個前向傳播(迭代)中,僅在最后一次前向傳播中執行生成。
- 將短 prompt 組合起來以恰好填滿目標 token 配額。即使是短 prompt,也可能被拆分,以確保 token 配額被精確滿足,從而實現良好的前向對齊。
這兩種技術結合在一起,為用戶體驗帶來了如下顯著優勢:
- 更好的響應性:由于長 prompt 不再需要一次性進行極長的前向傳播,模型響應客戶請求的延遲降低,在同一時間窗口內可以完成更多的前向傳播。
- 更高的效率:將短 prompt 融合以達到更大的 token 配額,使模型始終運行在高吞吐率的狀態下。
- 更低的方差與更強的一致性:由于前向傳播的 token 數量保持一致,而前向尺寸是性能的主要決定因素,因此每次前向傳播的延遲比其他系統更加穩定,同時生成頻率也更可預測。系統中不存在像其他系統中那樣的中斷或長時間運行的 prompt,從而不會導致延遲激增。正如我們在第 4 節所展示的,這種設計可將生成的 P95 延遲最多降低 3.7 倍。
因此,DeepSpeed-FastGen 會以一種既能快速持續生成,又能增加系統利用率的速率消耗來自輸入 prompt 的 tokens,從而相比其他先進的服務系統,為所有客戶端提供更低延遲和更高吞吐量的流式生成。
溫馨提示:
閱讀全文請訪問"AI深語解構" DeepSpeed-FastGen:通過 MII 和 DeepSpeed-Inference 實現大語言模型的高吞吐文本生成
)



)




)

)




)

![[C++]string::substr](http://pic.xiahunao.cn/[C++]string::substr)
