1.引言
????????在項目中會遇到各種各樣的慢查詢的問題,對于千萬級的表,如果使用比較笨的查詢方式,查詢一條SQL可能需要幾秒甚至幾十秒,如果將索引設置的比較合理,可以將查詢變得仍然非常快。
2.索引的本質
????????索引:幫助MySQL高效獲取數據的排好序的數據結構。
????????索引的數據結構:
????????1.二叉樹
????????2.紅黑樹
????????3.Hash表
????????4.B-Tree
????????如果表中沒有索引,檢索數據的時候就需要一行一行的去找,消耗的時間非常大。
????????每個數據在存儲的時候,存儲在磁盤上是,看起來是挨在一起的,但是其實不是挨在一起的,這個需要注意!!!
????????從磁盤中讀取一次數據,被稱之為磁盤IO,一次磁盤IO的性能是比較低的,如果我們對磁盤上的某一個數據進行查詢的時候,順序從表中查詢數據,每次拿一個進行比對一次,這樣整體來看是比較消耗性能的,整體的性能是不高的。
????????我們可以通過建立索引,將查詢(磁盤IO)的次數控制在一定量內,就可以大大提升性能了。
????????為什么不選擇使用搜索二叉樹?
????????搜索二叉樹并沒有自平衡的功能,很有可能退化為鏈表結構。
????????為什么不選擇使用平衡搜索二叉樹?如紅黑樹,AVL樹?
????????在平時生產環境使用數據庫的時候,單表數據量常常會達到百萬級,千萬級,假設單表數據量為500萬,即使使用紅黑樹,樹的高度也會達到22,那么即使使用索引查詢數據,也要可能進行22次磁盤IO操作,這個性能消耗對于MySQL來說也是比較大的。
????????為什么B-Tree更加合適?
????????1.B-Tree的特點:
????????葉節點具有相同的深度,葉節點的指針為空。
????????所有索引元素不重復。
????????節點中的數據索引從左到右遞增排列。
????????2.B-Tree的數據結構:
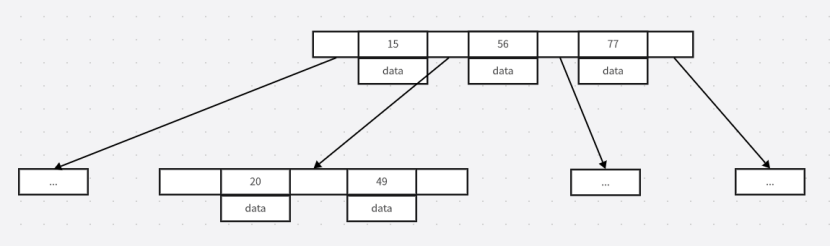
????????每個節點都會存儲多個key-value結構,key存儲的是索引值,data存儲的是索引所在行數據的硬盤地址。
????????為什么MySQL索引最終決定選擇使用B+Tree(B-Tree的變種)?
????????1.B+Tree的特點:
????????非葉子節點不存粗data,只存儲索引(做一個數據冗余),可以存放更多的索引數據。
????????葉子節點包含所有的索引字段。
????????葉子節點用指針連接,提高區間訪問的性能。
????????2.B+Tree的數據結構:
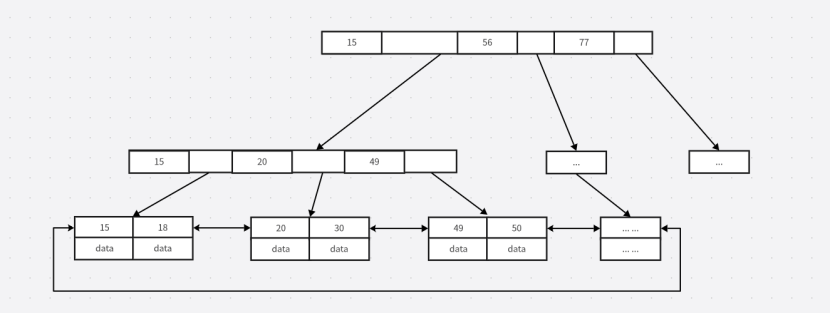
????????MySQL中默認設定的一個節點可以存儲的索引數據是16kb,可以使用SHOW GLOBAL STATUS like 'Innodb_page_size'查看“:
SHOW GLOBAL STATUS like 'Innodb_page_size';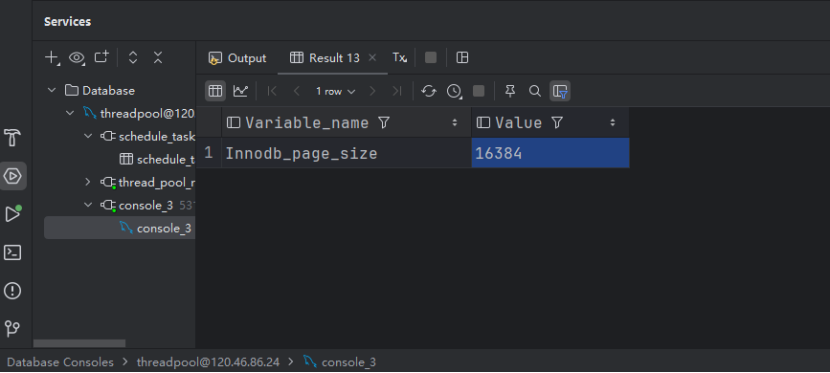
????????這是MySQL設置的默認值,不建議去修改,這是MySQL官方進行了大量測試得出的結果,多方考量了各種情況。
????????現在舉例展示定位數據的整體過程:
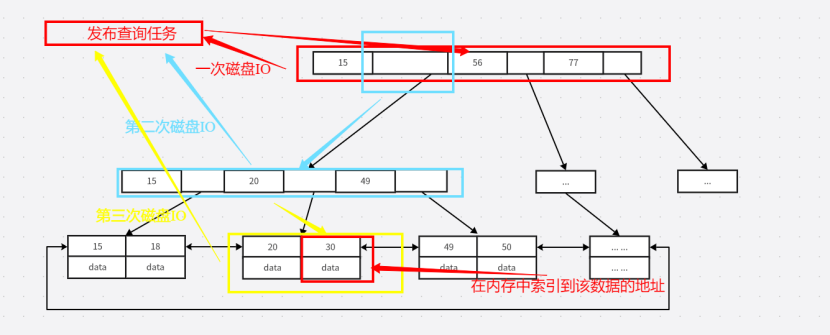
????????整個查詢30這個索引對應的數據的過程花費的消耗是三次磁盤IO和一次內存IO,相對來說內存的速度是極快的,對于磁盤IO消耗的時間是可以忽略不計的,所以這次查詢消耗也就是三次網絡IO。
????????那為什么MySQL不直接干脆在一個節點上存儲所有索引呢?這樣只需要一次磁盤IO呀。
????????答案:在系統中,內存是有限的,生產環境下一個表存儲的數據可能會達到百萬級,千萬級,一次磁盤IO將所有的索引數據和數據查詢到內存中,數據量相對來說是巨大的,直接將內存干爆了,設計的不合理。而且這樣不就又變成了順序查找數據了嗎?這樣整體查詢數據的速度也不會很快的。
????????MySQL選擇16kb作為節點的存儲空間,可以存儲多少數據呢?
????????答案:這里以索引是bigint類型的作例子,bigint = 8byte,數據地址在MySQL底層C語言中是占用了6byte,16kb / (8 + 6)byte,一個節點即可以存儲1170個元素。假設data的數據是1kb,一個葉節點也是可以存儲16個元素的。
????????使用B+Tree對樹高度進行削減的效果?
????????假設表中有2000萬的數據,使用索引建立的B+Tree的高度也只有3而已,也就是說最多三次磁盤IO就可以找到相對應的數據了。
????????MySQL對于索引B+Tree節點常駐內存的操作。
????????在MySQL低版本中,會將根節點常駐到內存中,在MySQL高版本中,會將所有的非葉子節點進行常駐內存,也就是說對于千萬級數據量的表來說,查詢數據的時間成本消耗只有查詢葉節點中數據這一次的磁盤IO而已,可見查詢速度是相當快的。
????????面試題:對于B-Tree和B+Tree,為什么MySQL最終決定選擇使用B+Tree?
????????影響樹查詢的關鍵是什么?是樹的高度,樹越高需要進行的磁盤IO的次數就越多,2000萬級別的數據表的索引使用B+Tree進行構建出來的樹的高度僅有3,但是如果使用的是B-Tree,由于B-Tree的特性,構建起來整個樹的高度絕對是大于3的,而且也不能做內存常駐等優化手段。
3.不同存儲引擎索引實現
????????首先先明確一個點:存儲引擎的概念相對的是數據表,并不是相對的數據庫,一個數據庫中的多個數據表是可以分別使用不同的存儲引擎的。
3.1MylSAM存儲引擎
????????MySQL數據庫中的數據都是存儲在磁盤中的,如果數據表采用的是MyISAM存儲引擎,數據表在硬盤中對應存儲的是以下三個文件:
????????1.數據表名稱.frm:數據表結構存儲文件。
????????2.數據表名稱.MYD:數據表數據存儲文件。
????????3.數據表名稱.MYI:數據表索引存儲文件。
????????即MyISAM存儲引擎,數據存儲和索引存儲文件是分離存儲的。
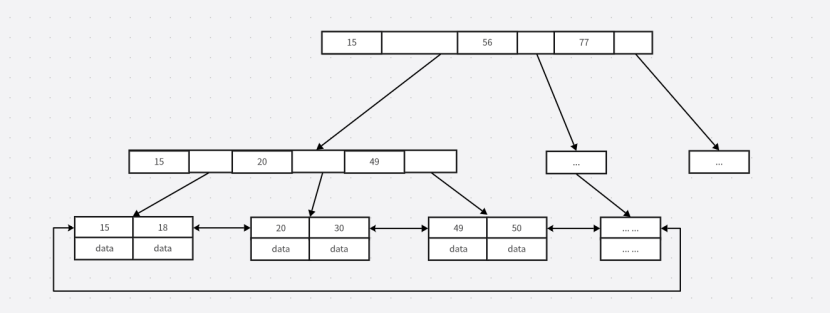
????????在MYI索引文件中,存儲的其實就是數據表構建的這一棵B+樹,葉節點中的data數據是磁盤數據的地址,即當數據表采用的是MyISAM存儲引擎的時候,通過索引去查詢數據的時候,會根據B+Tree查詢到數據的地址,然后再去MYD文件中查詢真正的數據。
3.2InnoDB存儲引擎
????????如果數據表采用的InnoDB存儲引擎,數據表在硬盤中對應存儲的是以下兩個文件:
????????1.數據表名稱.frm:數據表結構存儲文件。
????????2.數據表名稱.ibd:數據表索引+數據存儲文件。
????????即InnoDB存儲引擎,數據存儲和索引存儲文件是聚焦存儲的。
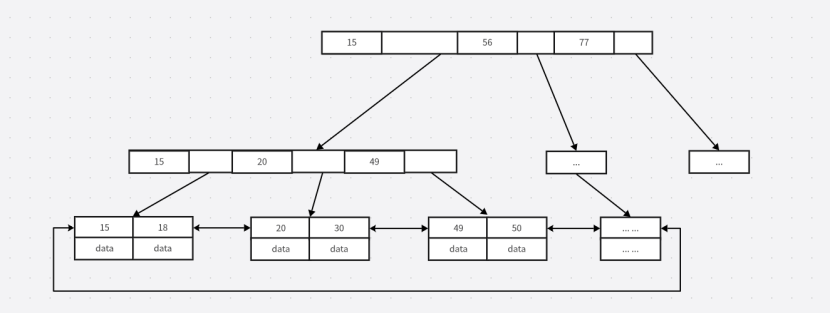
????????在InnoDB存儲引擎中,通過索引字段查詢到的Data是數據表中的數據,即數據表中的其他數據是和索引字段存儲在一起的,即存儲在B+Tree的葉節點中。
3.3聚集索引和非聚集索引
????????非聚集索引:MyISAM存儲引擎本身建立的索引就是非聚集索引,B+Tree葉節點的索引對應的Data是數據的地址,不是數據本身,即葉節點索引和數據是分開的,便是非聚集索引。
????????聚集索引:InnoDB存儲引擎本身建立的索引就是聚集索引,B+Tree葉節點的索引對應的Data是數據本身,即葉節點索引和數據是黏合在一起的,便是聚集索引。
????????面試題:為什么建議InnoDB表必須建立主鍵,并且推薦使用整型的自增主鍵。
3.4面試題探究
3.4.1為什么InnoDB必須建立主鍵?
????????之所以InnoDB必須建立主鍵,這與以InnoDB為存儲引擎的數據表密切相關,InnoDB引擎的數據表中數據和索引是附著在一起的,所以數據表中一定必須要有一個索引,一般情況下,我們都是使用主鍵作為索引進行搭建B+Tree數據存儲結構。
????????如果發現數據表有主鍵,就會使用主鍵索引結合數據建立B+Tree結構存儲相關數據。
????????如果數據表沒有主鍵,就會去數據表中從前向后去尋找一個所有數據都不重復的一列數據,借助該列數據作為索引去構建B+Tree。
????????如果數據表沒有主鍵,且沒有從數據表中找到任何一列數據不一樣,那么MySQL就會單獨創建一個隱形的一列,去作為索引維護B+Tree。
????????雖然MySQL最后還是可以幫助我們建立起主鍵索引,但是不建議將這種工作要求給MySQL去完成。
3.4.2為什么索引建議使用整形數據列
????????前面提到過索引使用數據列中的數據建立的,并且每一層的整體元素都是以索引數據遞增建立的索引節點,假設索引列中數據是整形,那么索引節點之間進行比較會非常簡單,很容易就能比較成功,將整棵B+Tree建立起來。
????????但是如果索引數據不是整形數據,而是字符串數據之類的,比較大小就會比較耗費性能,整形數字容易比較,性能較高,所以建議索引建立走整形數據列。
3.4.3為什么索引建立使用自增整形數據列
????????前面已經介紹了為什么建議使用整形數據列,主要的目的就是為了提升索引樹構建時的比較性能。
????????其實索引元素選擇為自增的元素也是為了提高索引樹構建的整體性能。
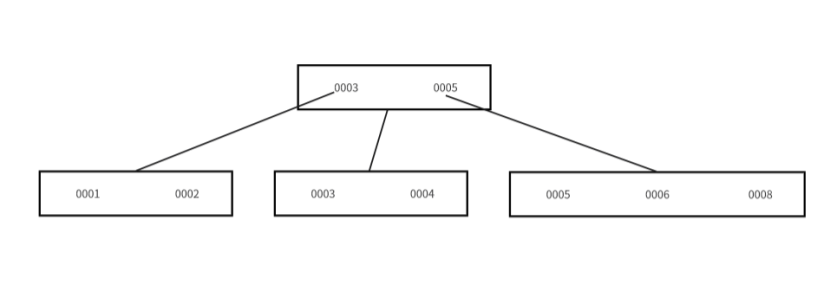
????????設定B+Tree中單節點設定為最多可以有四個元素,現在B+Tree中有七個元素,分別是1,2,3,4,5,6,8,那么建立起來的B+Tree就會如下所示:
????????但是如果現在不遵循自增原則,現在插入一個0007元素進去,會將元素插入到0006和0007之間:
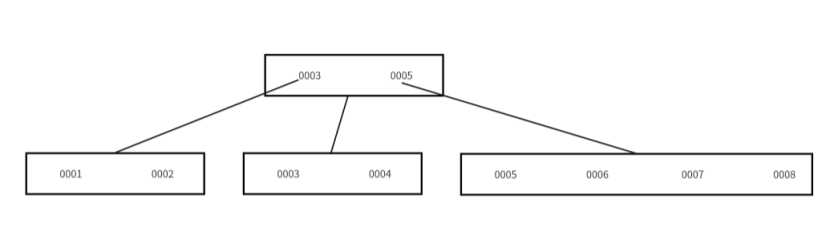
????????但是現在最右側的節點已經達到了最大元素數量,所以會進行分裂為兩個節點,分裂為兩個節點之后就會如下所示:
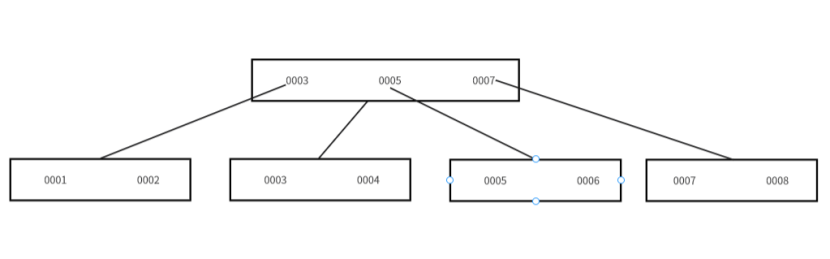
????????可以發現除了進行節點分裂操作以外,還進行了自平衡操作,整個過程的時間成本損耗是比較大的,所以建議建立索引的時候是整形自增的。
4.聚簇索引和非聚簇索引
????????在MySQL中索引被劃分為兩種,一種是聚簇索引另一種是非聚簇索引。
????????其中聚簇索引的意思是索引葉節點對應的數據是原始數據(即真數據),非聚簇索引的意思是索引葉節點對應的數據是數據的地址。
????????接下來就從存儲引擎和索引類型兩個方面去區分講解。
4.1存儲引擎
????????MyISAM存儲引擎使用的索引是非聚簇索引,即索引B+Tree的葉節點對應的數據是數據的地址,不是真實的數據。
????????InnoDB存儲引擎使用的一級索引(即主鍵索引)是聚簇索引,二級索引是非聚簇索引,下一步詳細講一下為什么要如此劃分。
4.2索引類型
????????這里主要是介紹InnoDB存儲引擎的索引類型。
????????索引類型分為主鍵索引和二級索引,主鍵索引顧名思義就是該字段既是主鍵又是索引,二級索引就是主鍵之外的字段建立的索引。
????????主鍵索引的B+Tree索引樹葉節點對應的數據是真實數據,所以主鍵索引被稱之為聚簇索引。
????????二級索引的B+Tree索引樹葉節點對應的數據是數據的地址,所以二級索引被稱之為非聚簇索引,二級索引之所以被設計為是非聚簇索引是因為為了達到節省空間的效果。
????????二級索引都需要進行一次回表操作,通過回表操作查詢真實的數據。
5.Hash索引
????????InnoDB存儲引擎的數據表,除了可以建立以B+Tree為存儲數據結構的索引以外,還可以建立起以Hash為存儲結構的索引。
????????Hash索引不支持范圍查找但是如果只是進行等值/IN查找速度會非常快,可以在項目中靈活使用(IO查詢次數邵),因為對索引的key進行一次查詢就可以定位到數據。
????????Hash索引的索引對應的數據都是數據的地址,屬于非聚簇索引。
6.聯合索引(多字段索引)
6.1概念
????????KEY idx_name_age_position (name age position) USING BTREE
????????這條語句的意思是建立一個使用B+Tree結構構建的聯合索引idx_name_age_position,該聯合索引涉及到多個字段,分別是name,age,position字段。
????????構建出的B+Tree如下:
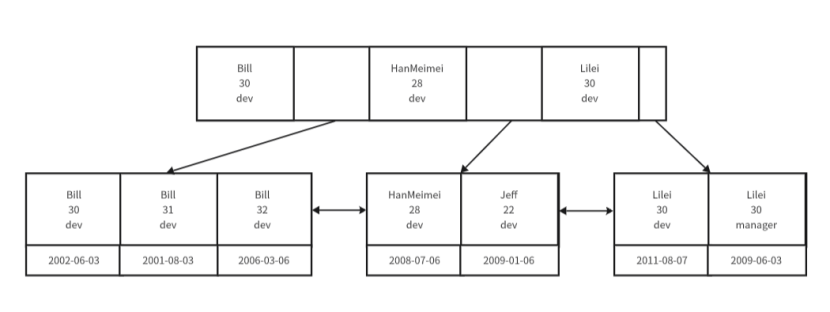
????????其中數據進行排序的時候,是先按照name排序,再按照age排序,再按照position進行排序。
????????如果聯合索引建立的是聯合主鍵索引,葉節點對應的數據就是主鍵索引,通過聯合索引查詢到數據后,就會先獲取到主鍵索引數據,再去回表查詢主鍵索引對應的真實數據。
????????如果是輔助索引,
6.2最左前綴原則
????????最左前綴原則保證了,聯合索引只在SELECT查詢語句使用時,有最左字段時才會生效使用,否則索引不會生效。
????????解釋一下為什么不會生效,還是看剛剛建立的索引樹:
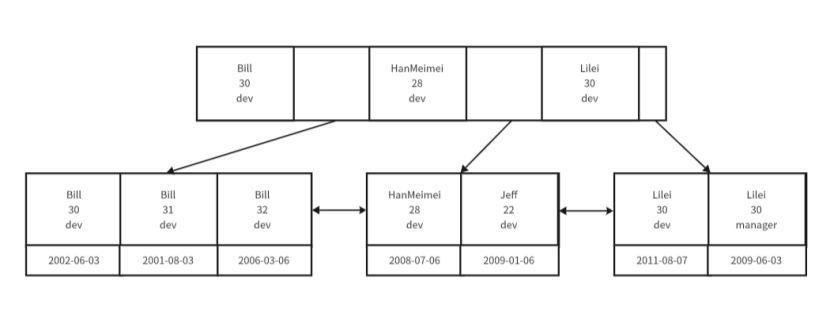
????????查詢語句1:SELECT * FROM table WHERE name = Bill AND age = 30
????????執行該SQL語句時,會先通過name定位到節點,然后查詢到最左邊的數據時,發現該數據是最后一個30,又由于數據組織是排好序的,所以就不會繼續向下找了,該索引樹起到了輔助快速查詢的作用。
????????查詢語句2:SELECT * FROM table WHERE age = 30。
????????如果是這樣就無法進行正常定位了,因為無法age只能在確定的name里是小范圍有序的,如果放到全局來看,age是亂序的,所以此時聯合索引會失效,就不會走聯合索引了。
- 商品列表頁模塊)
















![《P4092 [HEOI2016/TJOI2016] 樹》](http://pic.xiahunao.cn/《P4092 [HEOI2016/TJOI2016] 樹》)

(Java實現))