目錄
位圖:
引入
位圖實現:
?位圖的結構
插入數據(標記數據)?
刪除數據(重置數據)
查找數據
位圖完整代碼:
位圖的優缺點:
布隆過濾器:
引入
布隆過濾器實現:
?布隆過濾器的結構:
插入數據(標記數據)
查找數據
刪除數據(重置數據)
面試題:如何實現布隆過濾器的刪除?
構造函數(開辟容量)
哈希函數?
布隆過濾器完整代碼:
布隆過濾器的優缺點:
面試題:
位圖:?
給定100億個整數,設計算法找到只出現一次的整數?
給兩個文件,分別有100億個整數,我們只有1G內存,如何找到兩個文件交集?
1個文件有100億個int,1G內存,設計算法找到出現次數不超過2次的所有整數
布隆過濾器:
給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?給出近似算法
哈希切割:
給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?給出精確算法
哈希切分:?
給一個超過100G大小的log file(日志),log中存著IP地址,設計算法找到出現次數最多的IP地址?如何找到top K的IP?
一致性哈希
位圖:
本篇建立在已經熟悉哈希表直接定址法的基礎上,有興趣的讀者可以看這篇文章
【數據結構】哈希——閉散列/開散列模擬實現(C++)-CSDN博客![]() https://blog.csdn.net/suimingtao/article/details/149002209
https://blog.csdn.net/suimingtao/article/details/149002209
引入
先來看一道騰訊的面試題,
題目:給40億個不重復的無符號整數,沒排過序。給一個無符號整數,如何快速判斷一個數是否在這40億個數中。
很明顯,這道題可以用哈希來解決,而又因為題目上已經明確指出40億個數據中不會重復,那么直接定址法是最好選擇,但即使是這樣,還有一個難題:要怎么存進這40億整型數據?
一個Int占4個字節,40億個int大約占16G,難道要把這16G數據都存在內存中嗎?
顯然,這才是騰訊這道面試題考察的地方
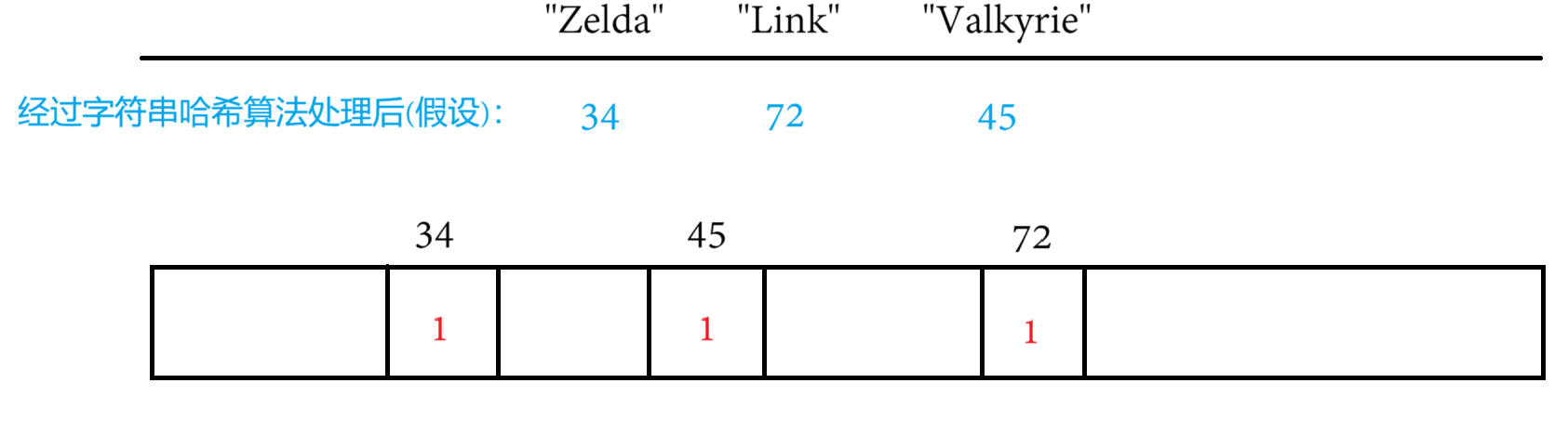
我們可以不用存數據本身,既然是直接定址法,只要在對應位置標記一下就可以。假如這道題目是100個不重復的無符號整數,且范圍是0~99,那我們就可以開辟100個空間,要插入哪個值,就在對應的下標位置標位1,否則為0。既然只需要標記0或1,那1個二進制位足以。
這就是位圖——即用每一位來存放某種狀態,適用于海量數據,數據無重復的場景。通常是用來判斷某個數據存不存在的。
騰訊這道題用位圖法,只需要開辟約500M的空間就可以把這40多億的數據全存進去
位圖實現:
?位圖的結構
思路我們有了,但要怎么開辟空間呢?
C++中可以定義的最小的數據單位就是1字節,而1字節是8個位,不可能直接按照位來開辟數組
那我們可以用內置類型來代替開辟位:例如,如果要開辟100個位的空間,可以開上100/32+1(向上取整)個int,也可以開辟100/8+1個char,這里理論來說用char能更節省空間浪費,但就那么幾十個位的破空間,其實都無所謂,這里編主就用int來實現
#pragma once
#include <vector>class bitset//位圖
{
public:bitset(size_t n)//構造函數:_num(0){_bits.resize(n / 32 + 1,0);//標記默認為0}private:std::vector<int> _bits;//存數據的數組(準確來說是標記數據)size_t _num = 0;//有效數據的個數
};插入數據(標記數據)?
插入數據時,需要先找到該數據在數組的第幾個int中,再確定到具體的該int的第幾位,置1即可
可以直接將數據除以32,以得到該數據在第幾個Int,將數據模除32,以得到該數據在int中的第幾位?
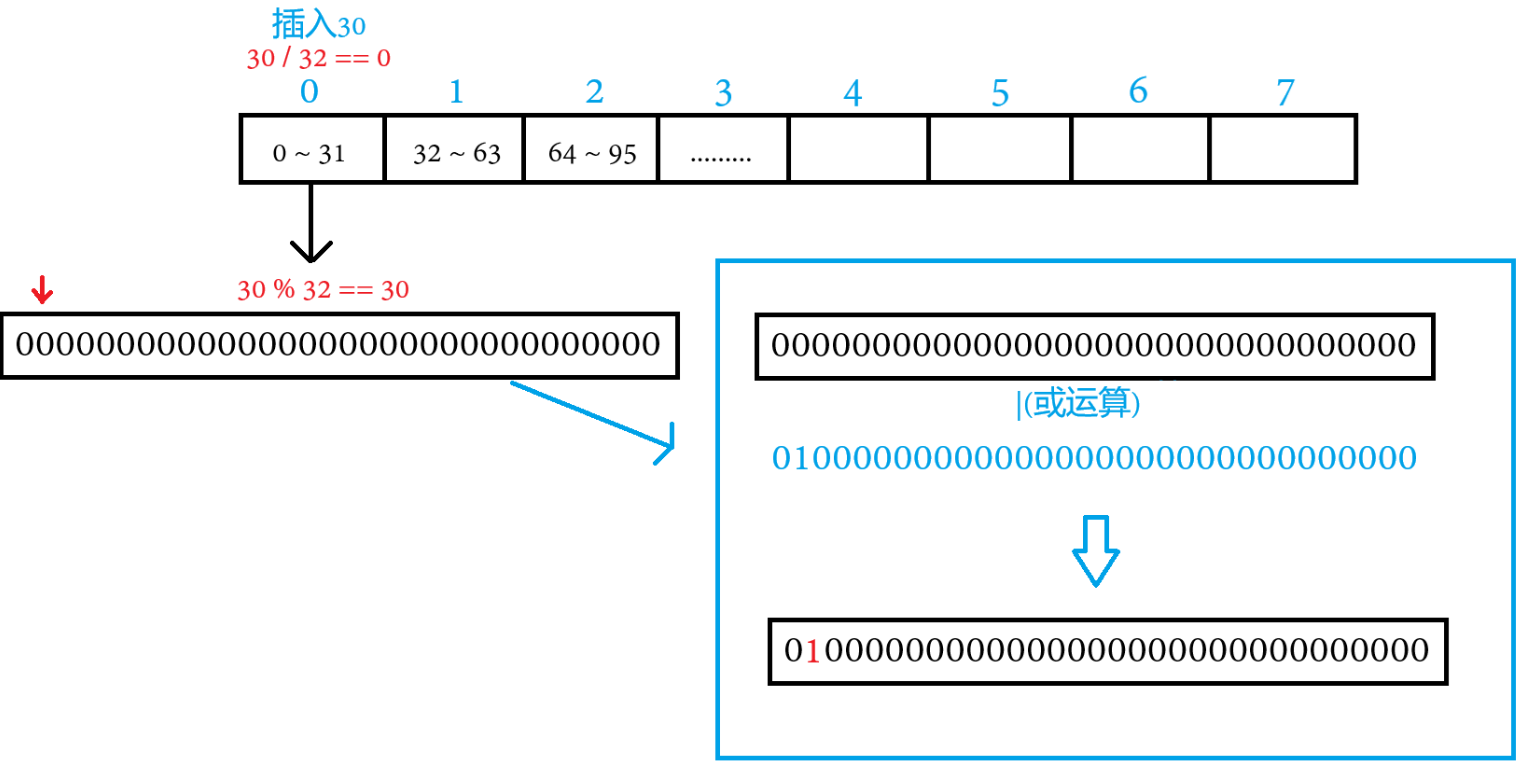
為什么要用|(或運算)?
如果用&(與運算)的話,int中別的位的標記也會被改動,因此要用|(或運算)
void set(size_t data)//標記數據(插入數據)
{size_t index = data / 32;//找到該數據在哪個整型中size_t pos = data % 32;//該數據在整型的第幾位_bits[index] |= (1 << pos);//將該整型的第pos位標記成功_num++;//有效數據+1
}刪除數據(重置數據)
刪除數據時,只需要把該數據所在位,置0即可,和插入時相似
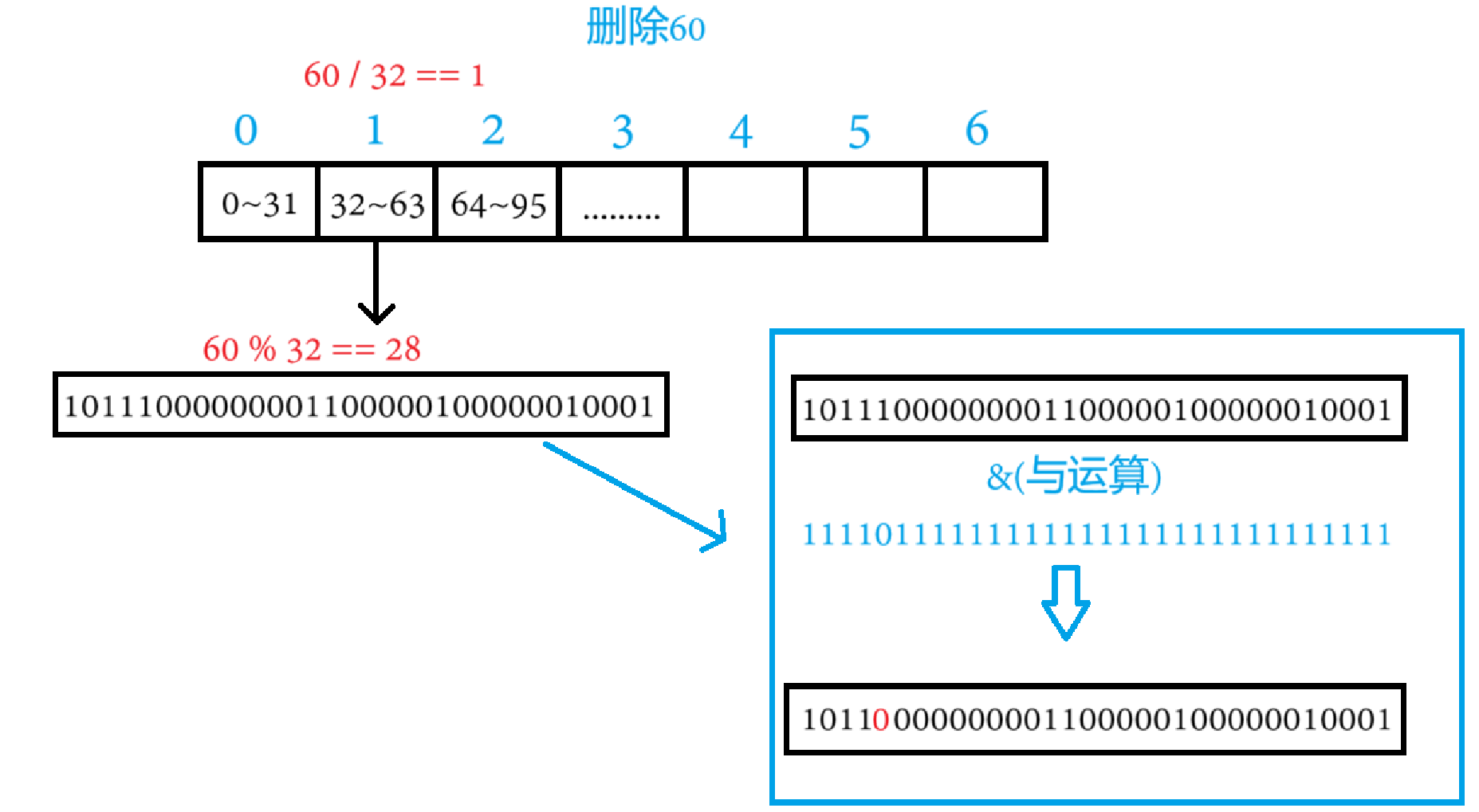
?將1 << pos再取反,就能得到除了一位是0,其他位全是1的數據,再將這個數據和原數據與運算,除了是0的那位之外,原來是1的數據就還是1,原來是0的數據還是0,不會改變
void reset(const size_t data)//重置數據(刪除數據)
{size_t index = data / 32;//找到該數據在哪個整型中size_t pos = data % 32;//該數據在整型的第幾位_bits[index] &= ~(1 << pos);//將該整型的第pos位標記刪除_num--;//有效數據-1
}查找數據
查找數據的思路也和前面大差不差
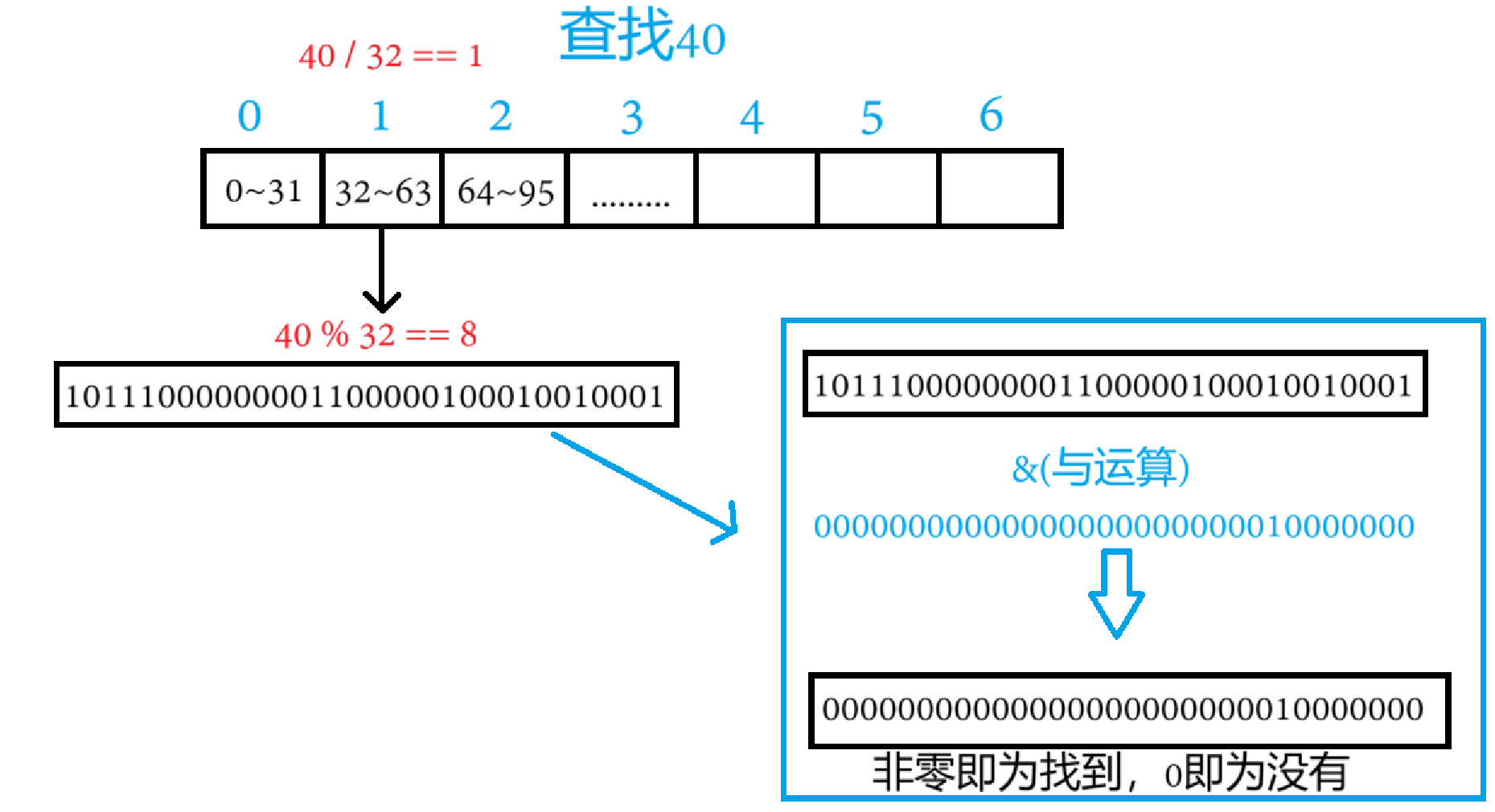
但此時就不能 &= 了,如果等于,會破壞本來原本的數據,只需要返回這個&之后的數據即可,只要是非0,就為找到,0就為找不到
bool test(const size_t data)//查找數據
{size_t index = data / 32;//找到該數據在哪個整型中size_t pos = data % 32;//該數據在整型的第幾位return _bits[index] & (1 << pos);//若該位置有標記,就會返回非0
}其實在STL中也有bitset

雖然接口很多,但主要的還是這三個
位圖完整代碼:
#pragma once
#include <vector>
class bitset//位圖
{
public:bitset(size_t n)//構造函數:_num(0){_bits.resize(n / 32 + 1,0);//標記默認為0}void set(const size_t data)//標記數據(插入數據){size_t index = data / 32;//找到該數據在哪個整型中size_t pos = data % 32;//該數據在整型的第幾位_bits[index] |= (1 << pos);//將該整型的第pos位標記成功_num++;//有效數據+1}void reset(const size_t data)//重置數據(刪除數據){size_t index = data / 32;//找到該數據在哪個整型中size_t pos = data % 32;//該數據在整型的第幾位_bits[index] &= ~(1 << pos);//將該整型的第pos位標記刪除_num--;//有效數據-1}bool test(const size_t data)//查找數據{size_t index = data / 32;//找到該數據在哪個整型中size_t pos = data % 32;//該數據在整型的第幾位return _bits[index] & (1 << pos);//若該位置有標記,就會返回非0}private:std::vector<int> _bits;//存數據的數組(準確來說是標記數據)size_t _num = 0;//有效數據的個數
};位圖的優缺點:
優點:節省空間,效率高
缺點:只能處理整型(由于位圖用的是直接定址法,因此只能處理整型)?
布隆過濾器:
引入
我們在使用新聞客戶端看新聞時,它會給我們不停地推薦新的內容,它每次推薦時要去重,去掉那些已經看過的內容。問題來了,新聞客戶端推薦系統如何實現推送去重的? 用服務器記錄了用戶看過的所有歷史記錄,當推薦系統推薦新聞時會從每個用戶的歷史記錄里進行篩選,過濾掉那些已經存在的記錄。 如何快速查找呢?
?這時就不能用位圖了,因為記錄一般是字符串類型,但用哈希表來處理的話,當記錄過多時,空間占用就會很大
還是可以用位圖時采用的方法——即把某個位標記為1
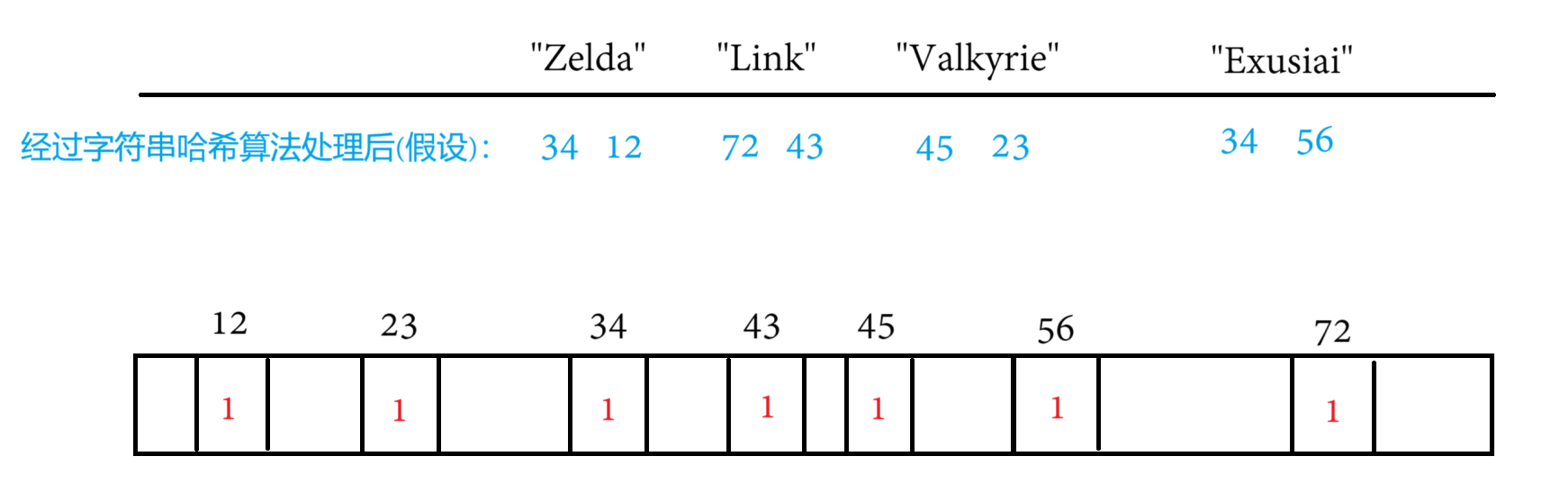
但再怎么樣的字符串哈希算法,都只是降低重復的概率,如果還是有一個字符串與其他字符串轉換成整型后重復了怎么辦??放在題目上說就是本來這個題目沒給你推薦過,但還是被誤判成推薦過了怎么辦?

哈希沖突是不可避免的,但可以減少它出現的概率,即減少誤判的概率,既然只有一個值很容易重復,那存多個值呢?即一個值映射多個位置
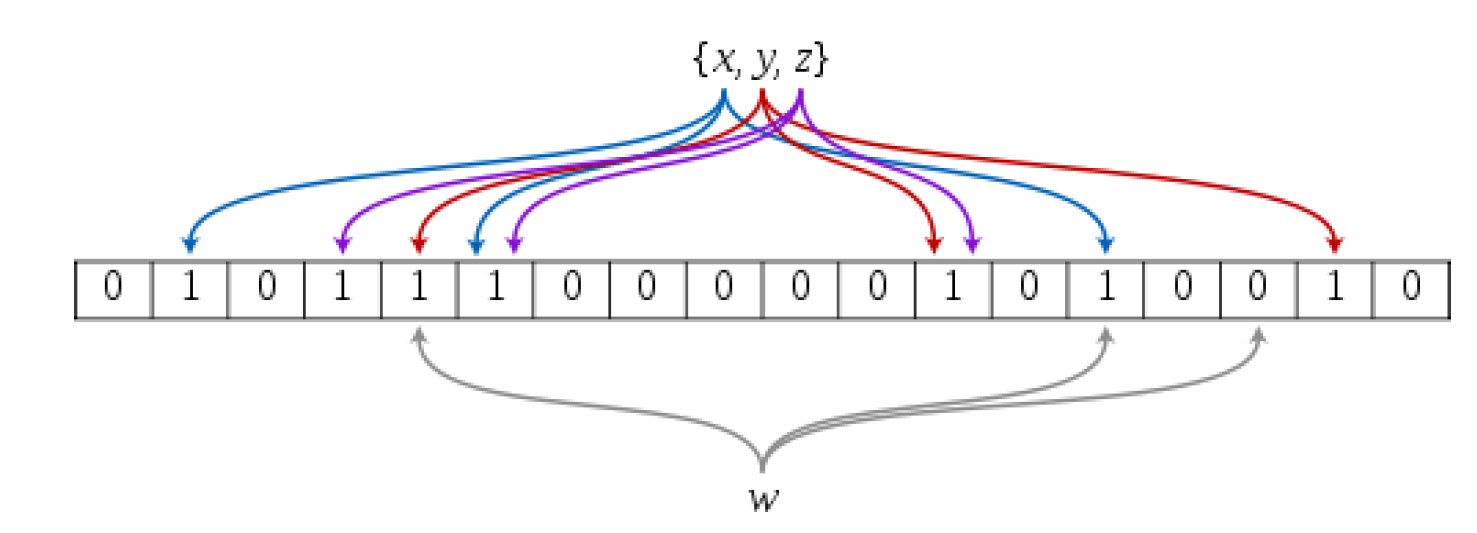
?此時再發生哈希沖突,即誤判的概率會大幅度降低,存的位置越多,哈希沖突概率越小
而這就是布隆過濾器——它是用多個哈希函數,將一個數據映射到位圖結構中。此種方式不僅可以提升查詢效率,也可以節省大量的內存空間。
布隆過濾器實現:
?布隆過濾器的結構:
由于布隆過濾器也是用位圖實現的,因此可以在里面直接實例化一個位圖對象,再定義一個容量,用于后面進行除留余數法
模板參數中,首先是該布隆過濾器存儲數據的類型(因為除了string還有可能是結構體,類等等自定義類型),再根據一個值映射幾個位置,就定義幾個不同的哈希函數(這里編主選擇一個值映射3個位置)
template<class K,//插入數據的類型class Hash1,//三個可以將K類型轉為整型的不同哈希函數class Hash2,class Hash3>
class boolmfilter//布隆過濾器
{private:bitset _bs;//位圖size_t _size;//開辟的位數
};插入數據(標記數據)
由于使用布隆過濾器的類型都不是整數,因此要先將該值轉換成整型,為了降低哈希沖突的概率,就需要用三種不同的轉換方法,分別將一個值轉成3個不同的值,再將這3個不同的值插入位圖中即可
void set(const K& key)
{size_t index1 = Hash1()(key) % _size;//通過三個哈希函數算出不一樣的三個值size_t index2 = Hash2()(key) % _size;//這里的Hash()是匿名對象size_t index3 = Hash3()(key) % _size;_bs.set(index1);//三個位存1個整數_bs.set(index2);_bs.set(index3);
}上圖中我們給每個轉換后的值都模除了位圖的容量,而位圖的實現中我們沒有%容量,這是因為位圖用于表示某個固定范圍內的整數是否出現(例如,統計?0~1000000?的整數是否出現),可以直接用整數本身作為索引。但布隆過濾器精確判斷范圍,因此需要模除容量。至于開辟多大容量,后面將構造函數時再說
查找數據
?查找數據時,只有當三個哈希函數算出來的整數值都有標記,才可以確認為有。但前面也說過,這樣只能降低出現哈希沖突的概率,還是有可能出現“一個值沒有被插入過,但算出來的三個整數值都被標記”的情況,但只要是插入過的數據,是肯定能找到的
由此可以得出,布隆過濾器查找不在的數據,是準確的;布隆過濾器查找在的數據,是不準確的(哈希沖突時就是不準確的)?
bool test(const K& key)//查找數據
{size_t index1 = Hash1()(key) % _size;//用三種不同方式將K類型轉換為整型if (_bs.test(index1) == false)return false;size_t index2 = Hash2()(key) % _size;if (_bs.test(index2) == false)return false;size_t index3 = Hash3()(key) % _size;if (_bs.test(index3) == false)return false;return true;//如果都找到了就返回真
}刪除數據(重置數據)
布隆過濾器應該有刪除數據的接口嗎?
下圖中,插入了兩個數據,綠色和紅色各代表一個數據,并且綠色和紅色數據有一個重復的標記

如果此時要刪除綠色,就需要把三個綠色標記都重置

那此時紅色的一個標記也被重置,也就會將紅色數據誤刪
因此,一般布隆過濾器不支持刪除
面試題:如何實現布隆過濾器的刪除?
?如果非要讓布隆過濾器可以刪除元素,需要怎么處理?
可以將每個位都標記成計數器,當前位每次被標記,都讓計數器+1
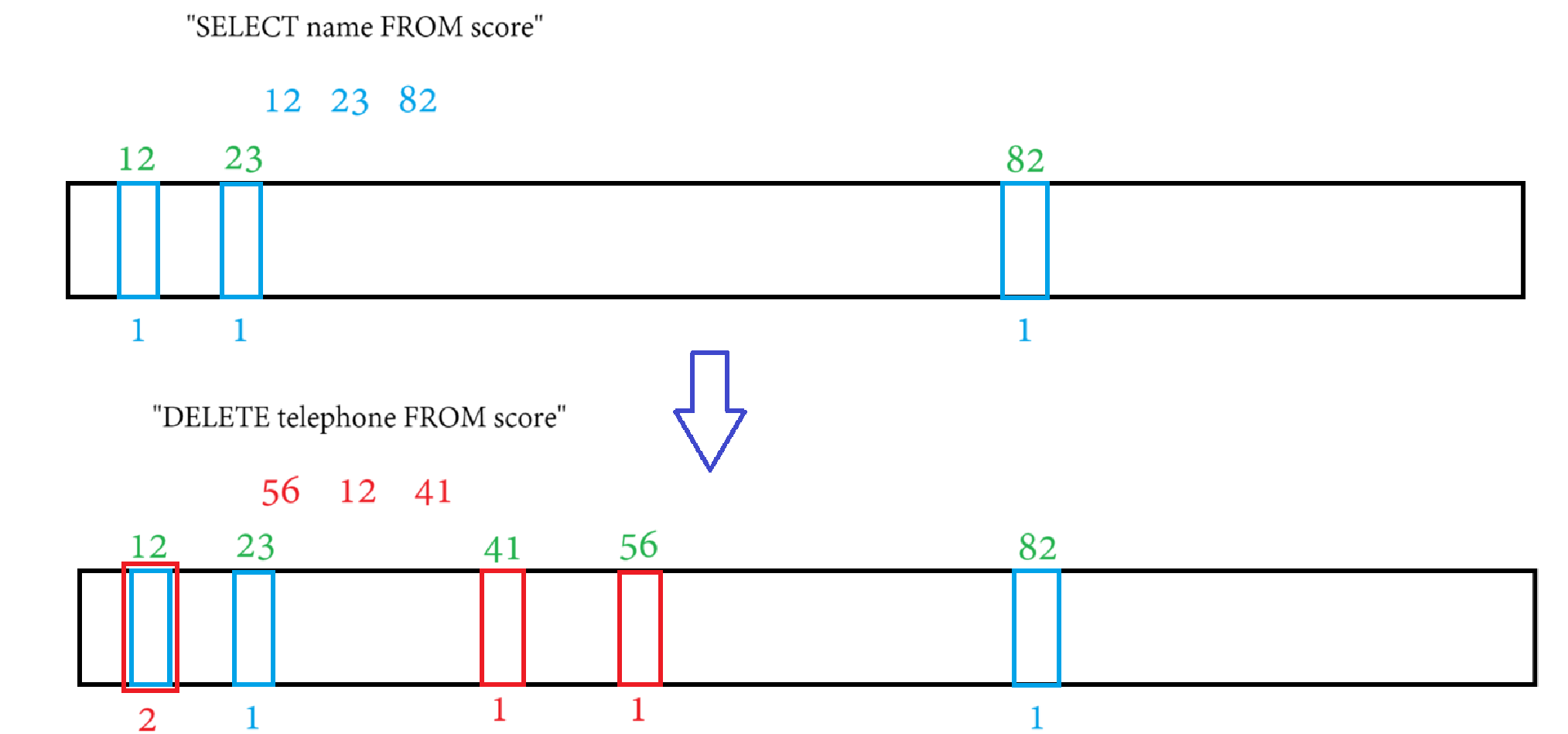
此時就算刪除紅色數據,也只會將三個哈希函數得出的整數位都-1,減完后“12”位中還有1,不影響藍色數據
但這樣做也有缺陷:一個位的計數器要給多少bit?如果bit給少了,多個值映射到一個位置就導致計數器溢出;但如果使用了更多bit映射一個位置,那么空間消耗就大了,不要忘了布隆過濾器的特點就是節省空間。并且這樣就允許插入重復值了,去重操作將需要重新實現
構造函數(開辟容量)
?構造函數需要完成布隆過濾器空間的開辟,那么到底開辟多少空間合適呢?
位圖開辟空間只需要開辟整數的范圍即可,但非整型可無法知道范圍。
過小的布隆過濾器很快所有的 bit 位均為 1,那么查詢任何值都會返回“可能存在”,起不到過濾的目的了。布隆過濾器的長度會直接影響誤報率,布隆過濾器越長其誤報率越小。
另外,哈希函數的個數也需要權衡,個數越多則布隆過濾器 bit 位置 置1 的速度越快,且布隆過濾器的效率越低;但是如果太少的話,那我們的誤報率會變高。?
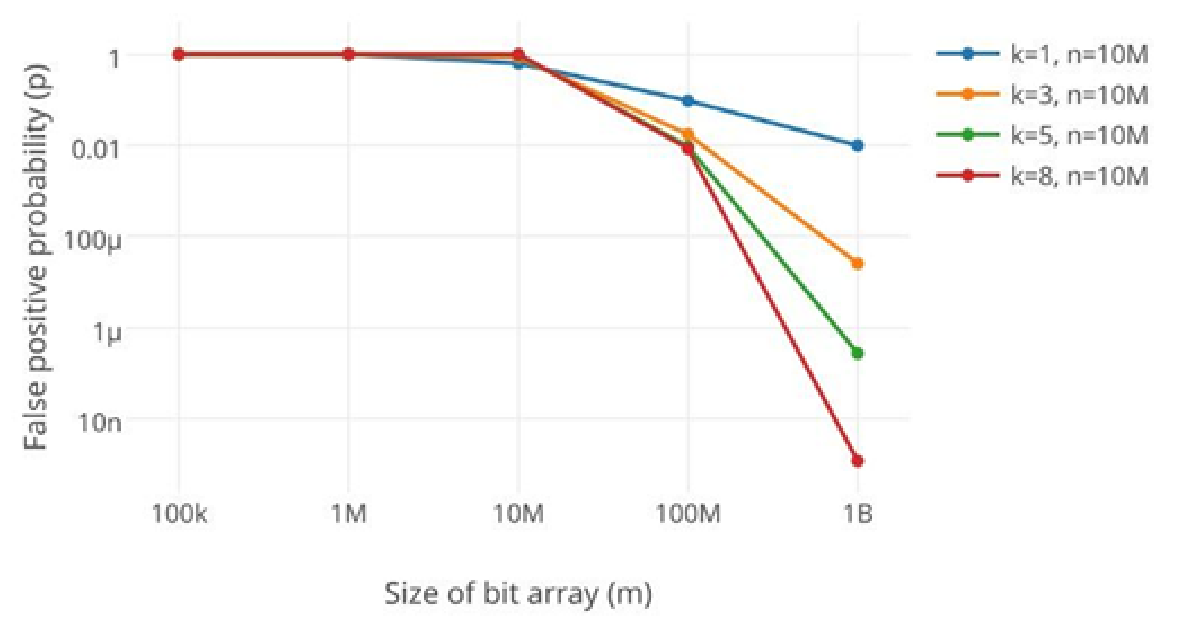
(ps:k 為哈希函數個數,m 為布隆過濾器長度,n 為插入的元素個數,p 為誤報率)?
這里有一個參考公式:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
?
?(圖和參考公式來自于這篇文章:詳解布隆過濾器的原理,使用場景和注意事項 - 知乎)
?由此可得出在哈希函數為3個的情況下,m 約等于 4.3(倍),這里就按5倍來看
boolmfilter(size_t num)//構造函數:_bs(num*5)//在哈希函數為3個的情況下,開辟空間為4.3倍為最佳,這里就按5倍算(公式所得),_size(num*5)
{ }哈希函數?
?模板中的三個哈希函數還沒有實現,這里就默認為處理的類型是string,那么就是要定義3個字符串哈希函數
各種字符串Hash函數 - clq - 博客園![]() https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html?這篇文章整理了很多字符串哈希函數,這里就選擇前三個用(相對來說沖突率最低的三個)
https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html?這篇文章整理了很多字符串哈希函數,這里就選擇前三個用(相對來說沖突率最低的三個)
struct BKDRHash
{size_t operator()(const std::string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++)hash = hash * 131 + s[i];return hash;}
};struct RSHash
{size_t operator()(const std::string& s){size_t hash = 0;size_t magic = 63689; for (size_t i = 0; i < s.size(); i++){hash = hash * magic + s[i];magic *= 378551;}return hash;}
};struct SDBMHash
{size_t operator()(const std::string& s){size_t index = 0;for (size_t i = 0; i < s.size(); i++)index = index * 65599 + s[i];return index;}
};STL庫中沒有布隆過濾器,只有位圖!!?
布隆過濾器完整代碼:
#pragma once
#include "bitset.h"
#include <string>
struct BKDRHash
{size_t operator()(const std::string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++)hash = hash * 131 + s[i];return hash;}
};struct RSHash
{size_t operator()(const std::string& s){size_t hash = 0;size_t magic = 63689; for (size_t i = 0; i < s.size(); i++){hash = hash * magic + s[i];magic *= 378551;}return hash;}
};struct SDBMHash
{size_t operator()(const std::string& s){size_t index = 0;for (size_t i = 0; i < s.size(); i++)index = index * 65599 + s[i];return index;}
};template<class K = std::string,//插入數據的類型class Hash1 = BKDRHash,//三個可以將K類型轉為整型的不同哈希函數class Hash2 = SDBMHash,class Hash3 = RSHash>
class boolmfilter//布隆過濾器
{
public:boolmfilter(size_t num)//構造函數:_bs(num*5)//在哈希函數為3個的情況下,開辟空間為4.3倍為最佳,這里就按5倍算(公式所得),_size(num*5){ }void set(const K& key)//標記數據{size_t index1 = Hash1()(key) % _size;//通過三個哈希函數算出不一樣的三個值size_t index2 = Hash2()(key) % _size;//這里的Hash()是匿名對象size_t index3 = Hash3()(key) % _size;_bs.set(index1);//三個位存1個整數_bs.set(index2);_bs.set(index3);}bool test(const K& key)//查找數據{size_t index1 = Hash1()(key) % _size;//用三種不同方式將K類型轉換為整型if (_bs.test(index1) == false)return false;size_t index2 = Hash2()(key) % _size;if (_bs.test(index2) == false)return false;size_t index3 = Hash3()(key) % _size;if (_bs.test(index3) == false)return false;return true;//如果都找到了就返回真}private:bitset _bs;//位圖size_t _size;//開辟的位數
};布隆過濾器的優缺點:
優點:節省空間,效率高,可以標記存儲任意類型
缺點:存在誤判(判斷一個數據不在布隆過濾器中是準確的,判斷一個數據在布隆過濾器中是不準確的),不支持刪除
面試題:
位圖:?
給定100億個整數,設計算法找到只出現一次的整數?
?這道題可以用改進后的位圖來解決。
上面我們實現的位圖,一個數據只有一位,一位只能表示0或1,但如果一個數據用兩位來表示呢?
00代表出現0次,01代表出現1次,10代表出現2次及以上,查找只出現一次的整數,只需要查找出兩位為01的數據即可。可以實例化兩個位圖對象,第一個位圖對象代表第一位,第二個位圖對代表第二位
下面給出一部分代碼,目的是為了讓大家更理解思路?
class solution
{
public:void set(size_t data){if (_bs1.test(data) == 0 && _bs2.test(data) == 0)//00,出現0次時{_bs2.set(data);//變成01,出現1次}else if (_bs1.test(data) == 0 && _bs2.test(data) == 1)//01,出現1次時{_bs1.set(data);_bs2.reset(data);//變成10,出現2次及以上}}
private:bitset _bs1;//第一位bitset _bs2;//第二位
};給兩個文件,分別有100億個整數,我們只有1G內存,如何找到兩個文件交集?
方案一:可以定義兩個位圖,將文件1的整數映射到位圖1中,將文件2的整數映射到位圖2中,再將位圖1和位圖2 &(按位與),結果就是交集
方案2:將其中一個文件映射到位圖中,再讀取另一個文件中的數據,判斷在不在位圖,在就是交集
1個文件有100億個int,1G內存,設計算法找到出現次數不超過2次的所有整數
本題思路和第一題一樣,只不過有了第四位,即11表示出現三次及以上,這里也只實現一個set
class solution
{
public:void set(size_t data){if (_bs1.test(data) == false && _bs2.test(data) == false)//00,即出現0次時{_bs2.set(data);//01,即出現一次}else if(_bs1.test(data) == false && _bs2.test(data) == true)//01,即出現一次時{_bs1.set(data);_bs2.reset(data);//10,即出現2次}else if (_bs1.test(data) == true && _bs2.test(data) == false){_bs2.set(data);//11,即出現3次及以上}}
private:bitset _bs1;//映射位圖1的數據bitset _bs2;//映射位圖2的數據
};布隆過濾器:
給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?給出近似算法
?query可以理解為查詢,也就是SQL語句,一條SQL查詢語句大約在30~60B,100億query就是300~600G。我們可以將文件1的數據都映射到布隆過濾器中,再讀取文件2數據,判斷在不在不用過濾器中,再就是交集。
但前面說過,布隆過濾器對于查找不在的數據是準確的,查找在的數據有可能會誤判(某個值的多個哈希函數結果有可能在布隆過濾器中都有標記)。因此,這個方法的缺陷:交集中有些數據不準確,有些非交集的數據也可能因為映射的多個哈希函數值相同而誤判為在交集
哈希切割:
給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?給出精確算法
?上面這道題是給出的近似算法,這里來實現一下不會存在誤判的精確算法
?既然一個文件太大,放不到內存中,那么我們可以把文件切分成多個小文件,將小文件一個一個加載到內存中,即平均切分
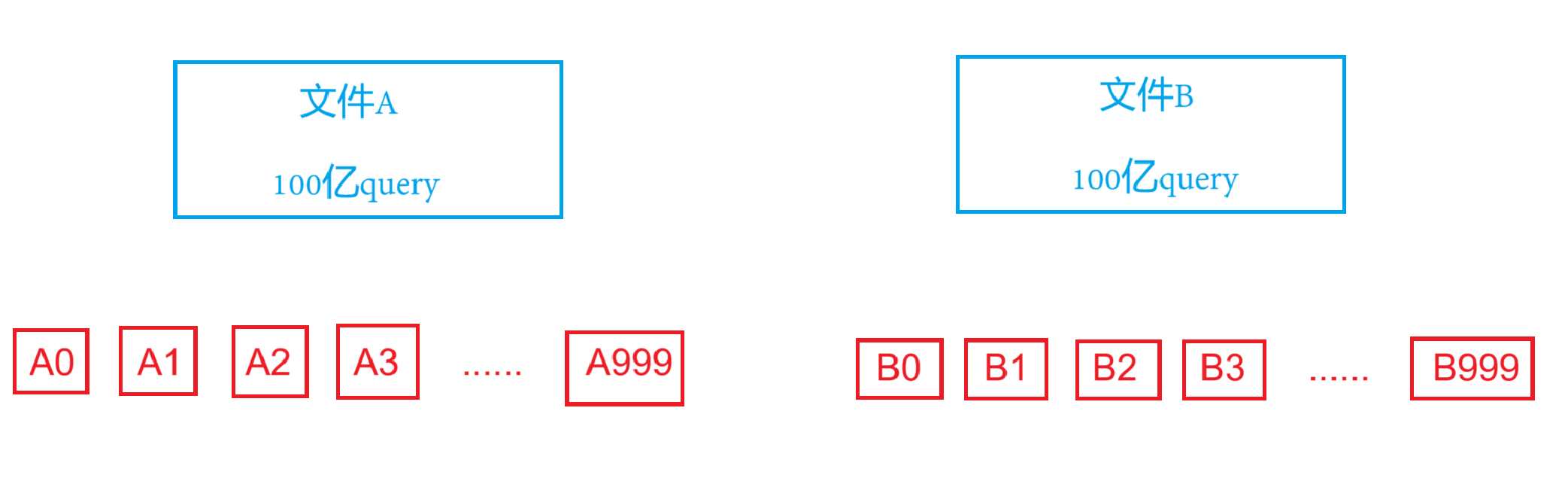
一個小文件具體的大小取決于內存,該題目說只有1G內存,就代表兩個小文件的大小加起來不能超過1G,因此拆分成1000份,這樣一份小文件就只有300~600M,兩個小文件在1G左右
如果是平均切分,那就代表A0中是交集的數據可能在B0,也可能在B1、B2等等。因此A0放到內存中后,需要和B的1000個文件都比較一遍,以此類推,A1放到內存中也需要和B的1000個文件都比較一遍
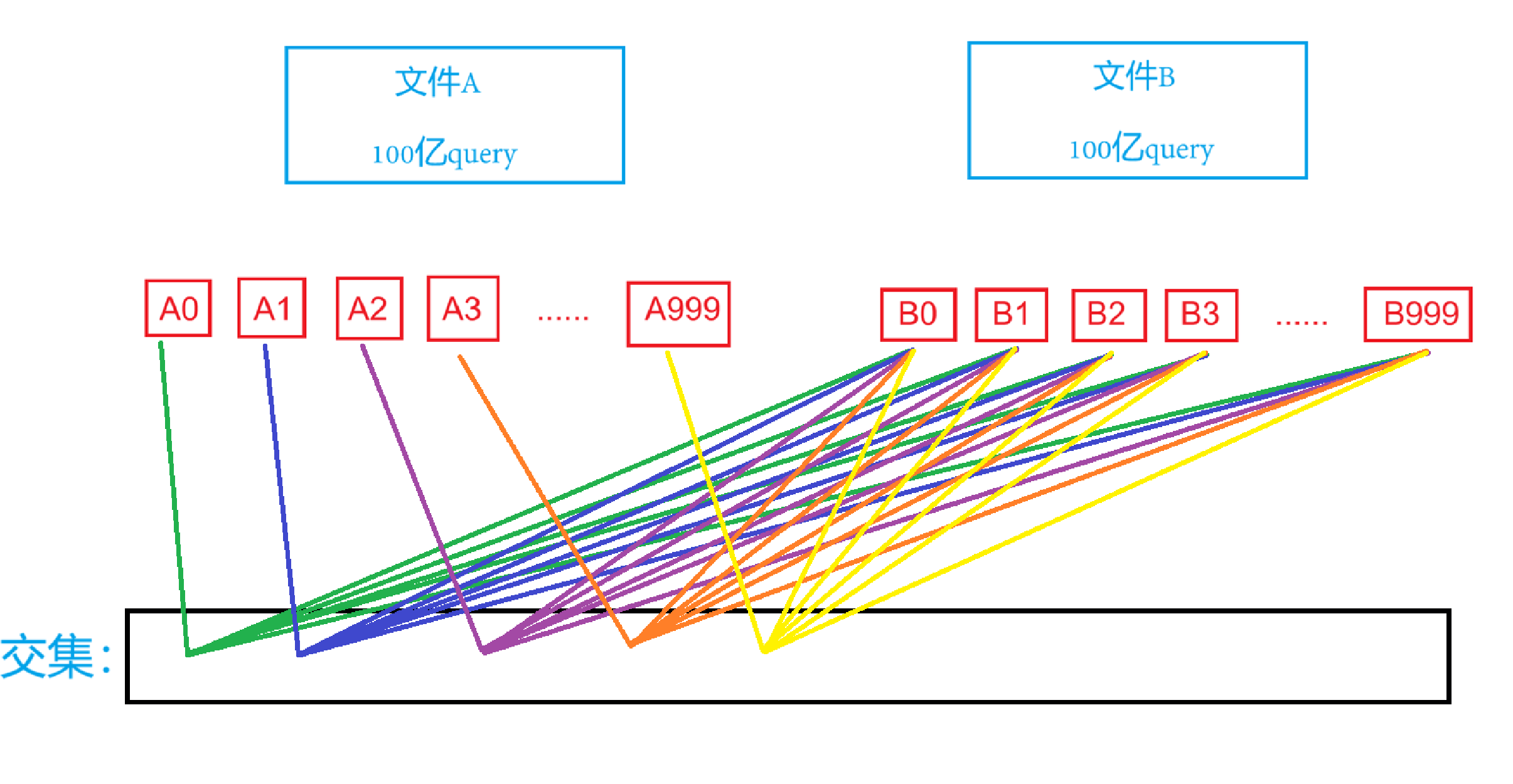
看著好像是O(N^2)的時間復雜度,但其實比較的效率還是高的,因為Ax的小文件放在set中,在set中查找數據還是很快的。
哈希切分:?
但有沒有更快的辦法?
上面用的方法叫做平均切分,缺點是每個小文件中都有可能存著交集的數據。
我們可以結合哈希表的思想,同樣將每個文件分成1000個大文件,但數據不再平均切分,而是哈希切分——根據文件中的query的哈希值來判斷應該放進哪個小文件中

?哈希切分好后,因為相同的值哈希值必然相同,所以交集的值肯定都在相同的小文件中了
那么A0就只需要和B0比較,A1只需要和B1比較,以此類推。
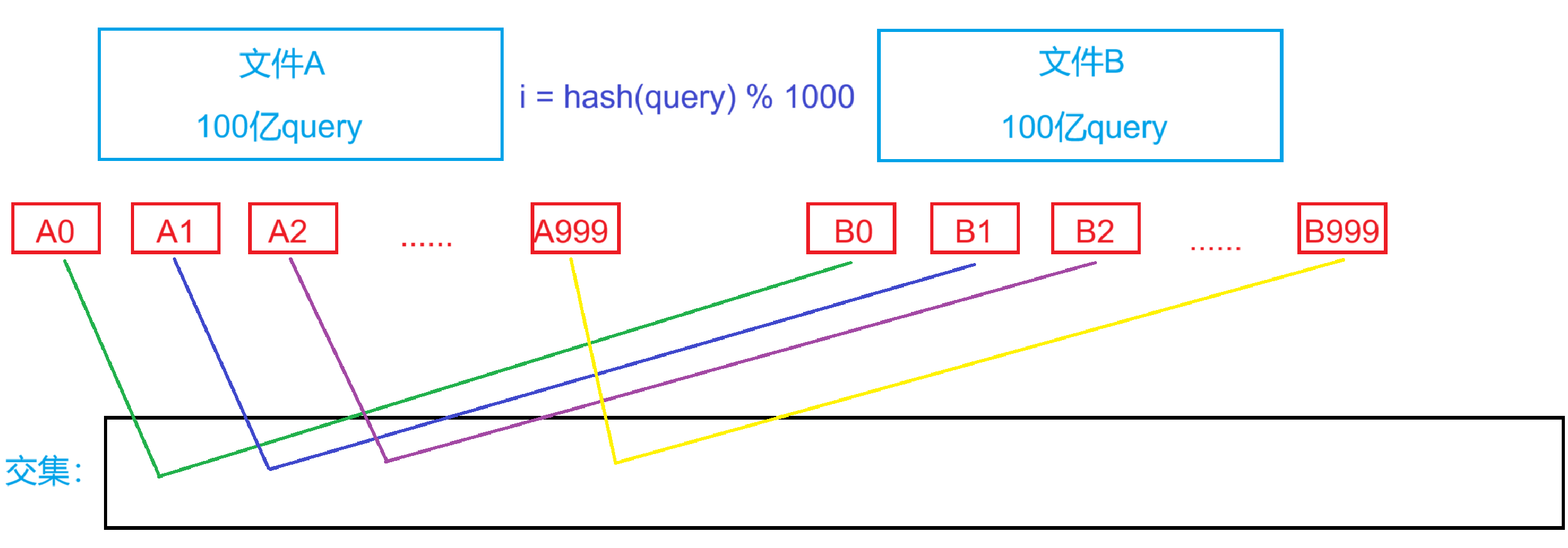
將Ai小文件的數據放到一個set中,選取對應的Bi小文件中的query,如果在Ai中,就是交集
給一個超過100G大小的log file(日志),log中存著IP地址,設計算法找到出現次數最多的IP地址?如何找到top K的IP?
?首先,這道題要做的是統計次數,統計次數我們一般用map解決,但這里的問題是有100G數據,放不到內存中
這道題還是可以用哈希切割,也就是將這個100G大文件切分成1000份小文件(這里還是1000份,是因為哈希切分并不是平均切分,有可能出現某個小文件很小,某個小文件很大的情況,為了讓很大的情況可以放下,因此要多開點),讀取IP計算出 i = hash(IP) % 1000,i是多少,IP就進入對應編號的Ai小文件,這樣相同IP一定都在一個小文件中
再創建一個map<string,int> cnt;讀取Ai中的數據統計次數,讀取完后用一個pair<string,int> max;來存取該小文件中出現次數最多的IP,再cnt.clear()清除當前map中的數據后讀取下一個小文件的數據
至于topK問題,可以建K個元素的小堆,把前幾個數據放進去,后續只要有比堆頂次數多的,就替換堆頂數據并向下調整(topK問題細講在這里:【基礎算法】堆排序與TopK問題(C語言)_c#面試題 topk算法-CSDN博客)
一致性哈希
拿微信來舉例,如果現在需要存每個用戶的微信號和朋友圈信息,并且要方便快速查找
很明顯,可以創建一個map<微信號,朋友圈>來存儲
但真正需要考慮的是服務器存儲數據的問題,因為微信有14億用戶,假設平均一個用戶的信息是100M,那么大概需要? 14億 * 100M ≈?130PB? ,按一個服務器1TB來算,大約需要13w臺服務器來存儲數據(多機存儲)
假如,此時用戶valkyrie發了一條朋友圈,那這條朋友圈會存到那臺機器?瀏覽和刪朋友圈時又會怎么查找?
還是可以用到上面的哈希切割,將用戶信息和存儲的機器做一個映射關系
比如valkyrie的朋友圈信息,i = hash("valkyrie") % 13w ,結果的i就代表valkyrie的朋友圈信息要存到編號為多少的服務器上(實際中需要用一臺額外機器存儲機器編號和IP的映射關系,這樣才能通過編號找到對應IP的服務器)
但這種方法有個缺陷:當數據存滿時,需要加裝服務器,那么之前的13w臺機器上的數據映射關系就不對了,就需要重新計算位置遷移數據
這時候就要用到這個問題的主角——一致性哈希
我們可以將模除的值從13w改成2^32(選這個值是因為這是整型的最大值,實際中也可以是50億,100億等等),即i = hash(用戶名) % 2^32,之后再一段范圍去映射一個服務器(例如0~10w映射第一個服務器,10w~20w映射第二個服務器),這樣可以讓0~2^32范圍內的值都映射到現有的13w服務器上
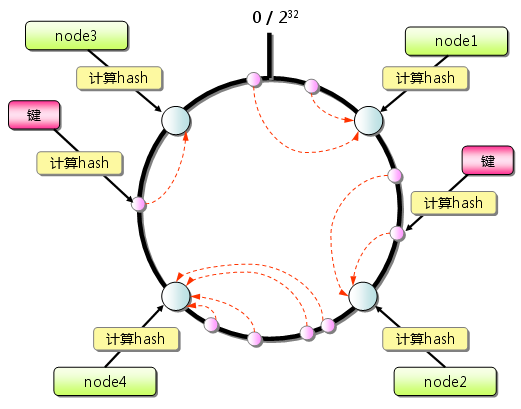
當數據存滿時,也就是當新增服務器時,?會先找到目前數據比較多的范圍,分一半給新服務器。例如,在新增服務器之前,30w~40w的服務器中的值是最多的,那就把它拆成30w~35w和35w~40w,一半還是在原來的服務器,另一半到新服務器上,這樣只需要遷移極小部分數據
總結:一致性哈希就是給一個特別大的除數,那么增加機器也不需要重新計算遷移,它是一段范圍映射一臺機器<x1~x2,ip>,那么增加機器只需要改變映射范圍且遷移小部分數據即可

矢量數據)

![[CH582M入門第十步]藍牙從機](http://pic.xiahunao.cn/[CH582M入門第十步]藍牙從機)
 ——輪轉數組(C語言))
)












![[3-02-02].第04節:開發應用 - RequestMapping注解的屬性2](http://pic.xiahunao.cn/[3-02-02].第04節:開發應用 - RequestMapping注解的屬性2)
