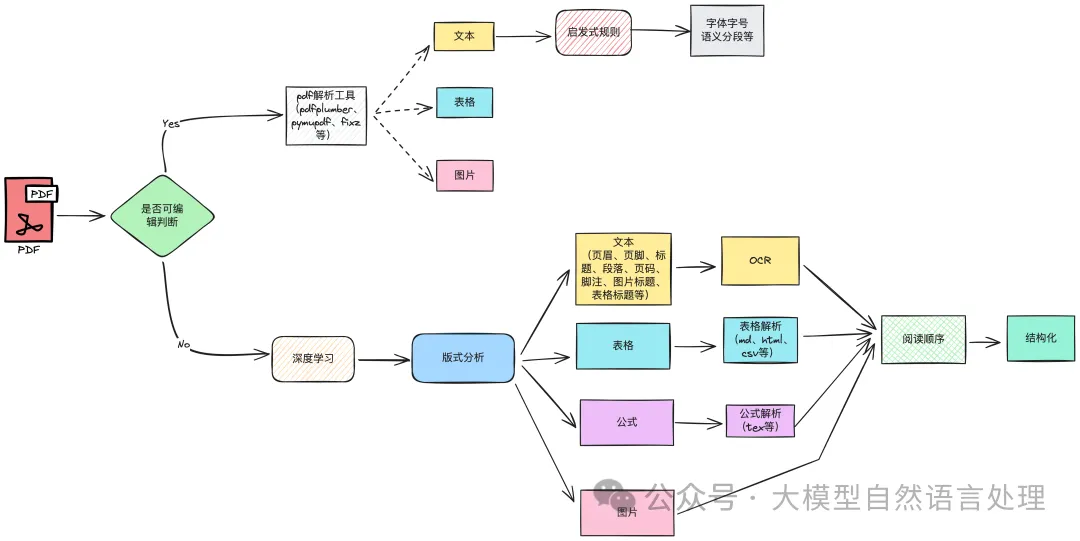
前期《文檔智能》專欄詳細中介紹了文檔智能解析詳細pipline鏈路技術方案,如下圖:
現在來看一個新思路,指出pipline鏈路依賴大量標注數據、并且會出現錯誤傳播問題,導致解析效果不佳,故提出一個基于布局強化學習(layoutRL)的多模態大模型的端到端的解析框架,通過強化學習(GRPO)的方式訓練模型的布局感知能力。(ps:筆者看來,在通用場景下解析效果也能并不會有文中評價的那么好,但這個數據合成思路及強化學習的訓練方式可以參考。)
方法
如下圖所示,方法分兩步走:數據合成和GRPO強化學習訓練多模態文檔解析模型。

1、數據集構建

為了構建Infinity-Doc-55K,設計了一個雙管道框架,結合了合成和真實世界文檔生成。數據細節如上圖:數據集涵蓋了七個不同的文檔領域(ps:說實話,這個場景數量還不夠多)。
1.1、真實世界數據

這一個還是聯合了pipline解析流程中的專家小模型,收集了來自金融報告、醫療記錄、學術論文、書籍、雜志和網頁等多樣化的掃描文檔。為了生成標注數據,其中專業模型處理不同的結構元素,如布局塊、文本、公式和表格。
- 布局分析:使用視覺布局模型分析整體布局。
- 公式識別:使用專門的公式識別模型處理公式區域。
- 表格解析:使用基于Transformer的表格提取器解析表格。
然后通過交叉驗證機制,比較專家模型和VLM的輸出,過濾掉不一致的結果,只保留跨模型預測一致的區域的注釋作為高置信度的偽GT。
1.2、合成數據
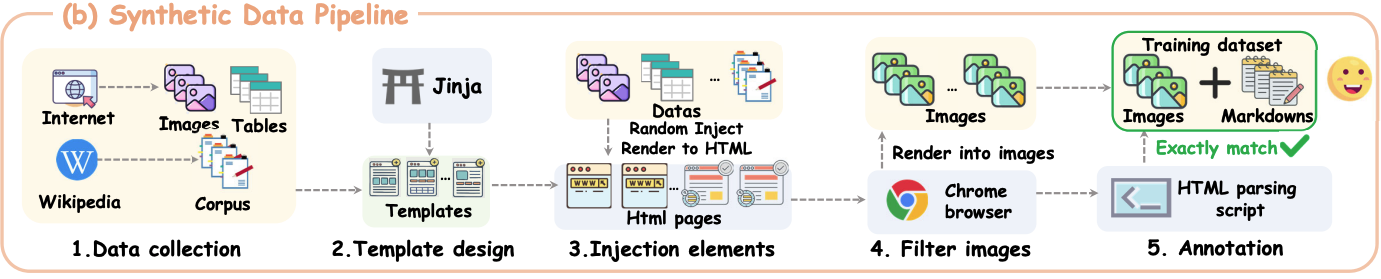
合成數據構建管道通過將采樣內容注入預定義的單列、雙列或三列HTML布局中,使用Jinja模板從維基百科、網絡爬蟲和在線語料庫中收集文本和圖像。這些頁面使用瀏覽器引擎渲染成掃描文檔,隨后自動過濾掉低質量或重疊的圖像。通過解析原始HTML生成對齊的Markdown表示作為真實注釋。
2、采用布局感知的強化學習
布局感知的強化學習框架(layoutRL),通過優化多方面的獎勵函數來訓練模型,使其能夠更好地理解和解析文檔的布局結構。使用GRPO方法,通過從基于規則的獎勵信號中學習訓練架構如下:
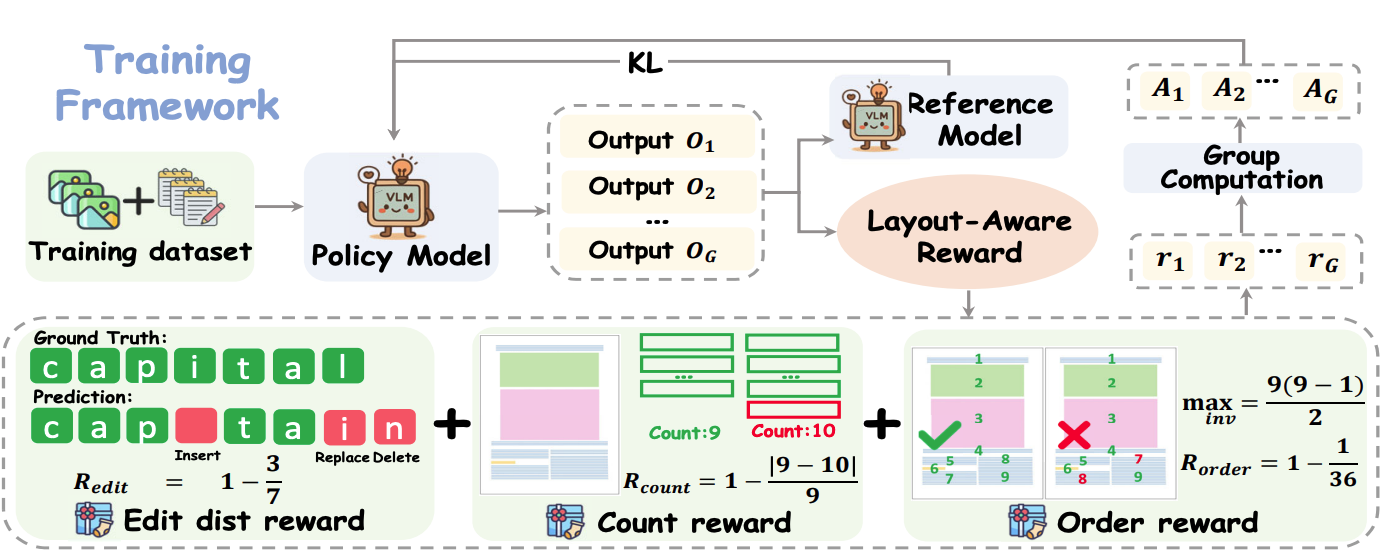
那么這一部分的核心就是獎勵函數的設計了。主要分三部分:
2.1、編輯距離獎勵
編輯距離獎勵基于預測輸出與參考輸出之間的歸一化Levenshtein距離。該獎勵通過計算將預測輸出轉換為參考輸出所需的最小插入、刪除或替換操作的數量來衡量預測的準確性。
R d i s t = 1 ? D ( y , y ^ ) max ? ( N , M ) R_{dist}=1-\frac{D(y,\hat{y})}{\max(N,M)} Rdist?=1?max(N,M)D(y,y^?)?
其中, N N N 和 M M M 分別是參考和預測序列的長度, D ( y , y ^ ) D(y,\hat{y}) D(y,y^?) 是Levenshtein距離。該獎勵的范圍在[0,1]之間,值越高表示預測與參考的對齊程度越好。
2.2、段落計數獎勵
目的是鼓勵模型準確地分割段落。該獎勵通過比較預測段落數量與參考段落數量的差異來計算:
R c o u n t = 1 ? ∣ N Y ? N Y ^ ∣ N Y R_{count}=1-\frac{\left|N_{Y}-N_{\hat{Y}}\right|}{N_{Y}} Rcount?=1?NY? ?NY??NY^? ??
其中, N Y N_Y NY? 和 N Y ^ N_{\hat{Y}} NY^? 分別是參考和預測的段落數量。該獎勵懲罰缺失或多余的段落。
2.3、順序獎勵
通過計算預測段落與參考段落之間的順序反轉次數來衡量閱讀順序的保真度。公式如下:
R o r d e r = 1 ? D o r d e r max ? i n v R_{order}=1-\frac{D_{order}}{\max_{inv}} Rorder?=1?maxinv?Dorder??
其中, D o r d e r D_{order} Dorder? 是順序反轉次數, max ? i n v \max_{inv} maxinv? 是最大可能的反轉次數。該獎勵鼓勵模型保持原始的閱讀順序。
- 最終獎勵計算
最終的獎勵是上述三個部分的加權和,通過匈牙利算法確定預測與參考段落之間的最佳匹配,然后計算每個匹配對的編輯相似性、段落數量和順序保真度。公式如下:
R M u l t i ? A s p e c t = R d i s t + R c o u n t + R o r d e r R_{Multi-Aspect}=R_{dist}+R_{count}+R_{order} RMulti?Aspect?=Rdist?+Rcount?+Rorder?
該設計平衡了內容保真度與結構正確性和順序保真度,為端到端的文檔解析提供監督。
實驗評估
-
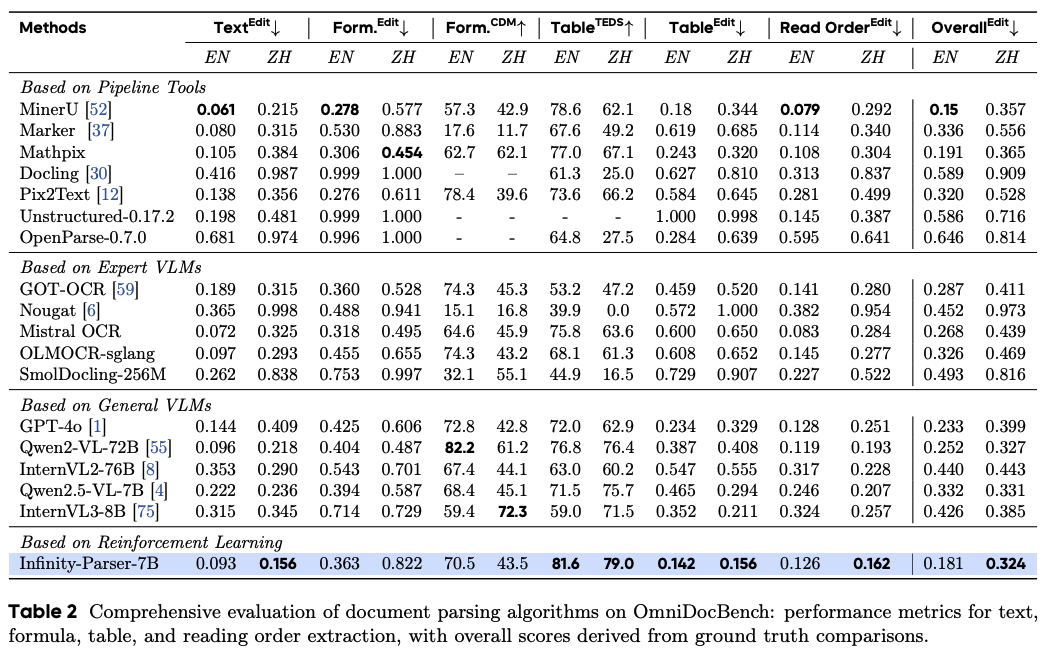
OmniDocBench評估:在OmniDocBench基準上,Infinity-Parser-7B在所有子任務中表現均衡
-
表格識別評估
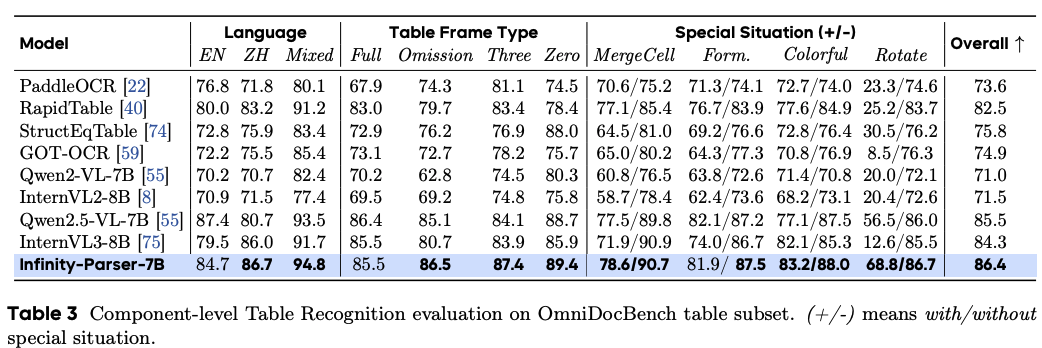
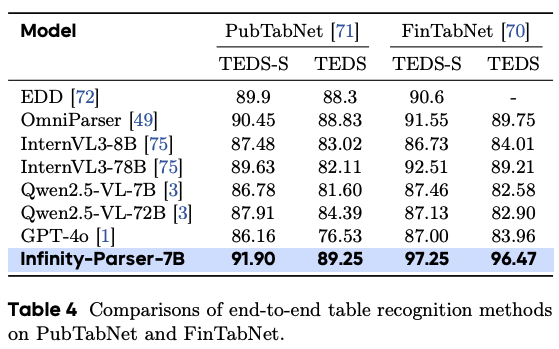
-
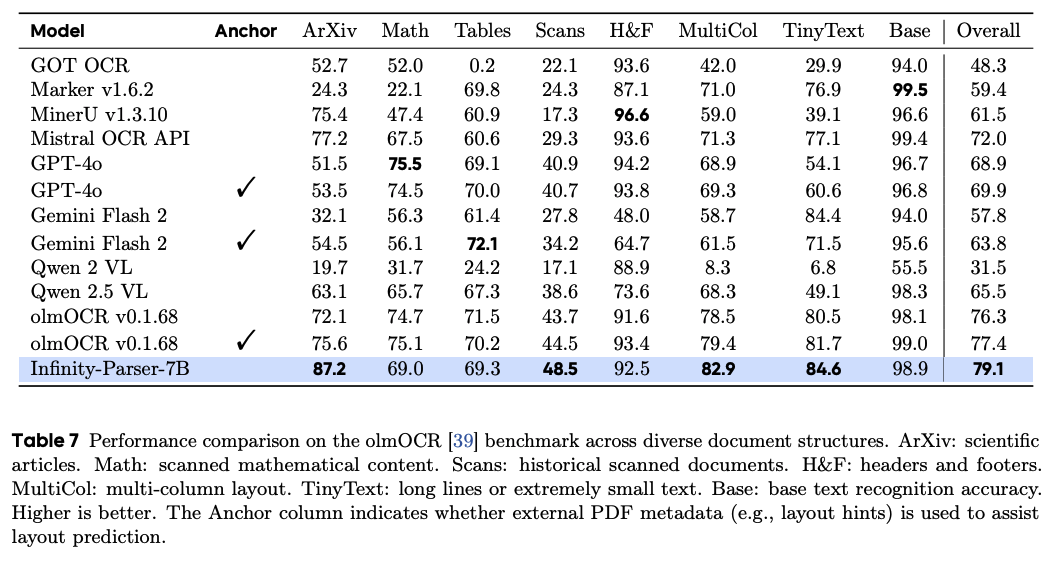
文檔級OCR評估
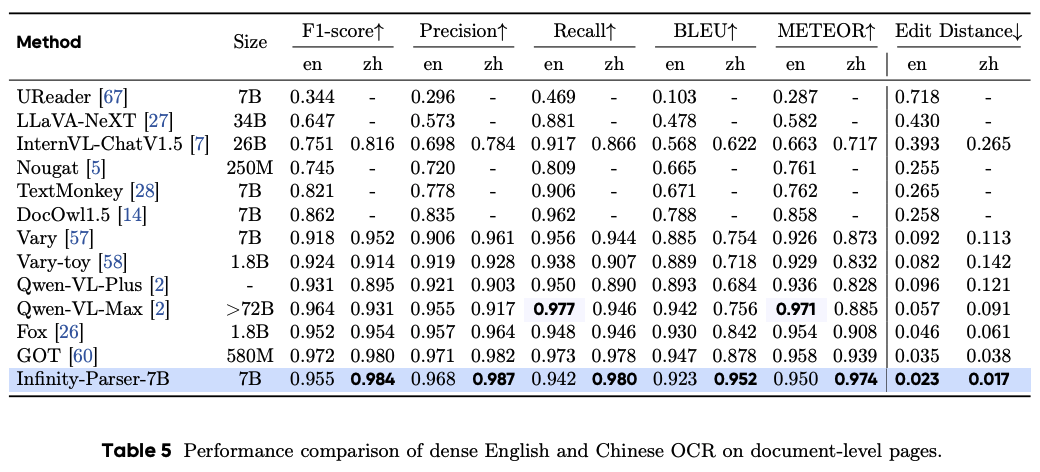
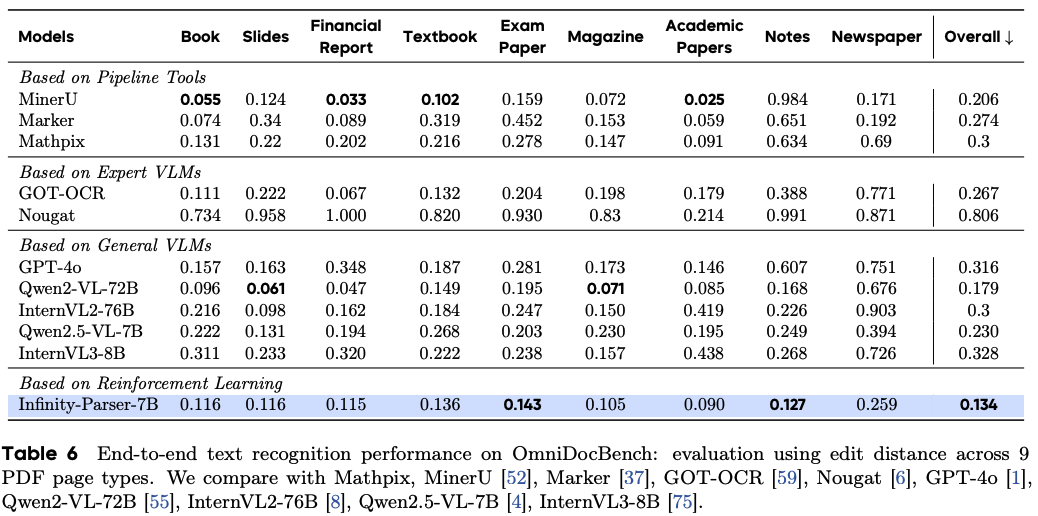

參考文獻:Infinity-Parser: Layout-Aware Reinforcement Learning
for Scanned Document Parsing,https://arxiv.org/pdf/2506.03197
repo:https://github.com/infly-ai/INF-MLLM/tree/main/Infinity-Parser
)
)

的原理與用法)












)


