神經網絡調參指南
知識點回顧:
- 隨機種子
- 內參的初始化
- 神經網絡調參指南
- 參數的分類
- 調參的順序
- 各部分參數的調整心得
作業:對于day'41的簡單cnn,看看是否可以借助調參指南進一步提高精度。
 用“燒水調溫”的日常場景來打比方:
用“燒水調溫”的日常場景來打比方:
每個神經元就像一個“燒水的爐子”,你的目標是把水燒到合適的溫度(比如80℃)。
- 輸入數據是“初始水溫”(比如水管里流進來的水是20℃);
- 權重(w)是“爐子的初始火力”(比如你第一次開爐子時調的火力大小);
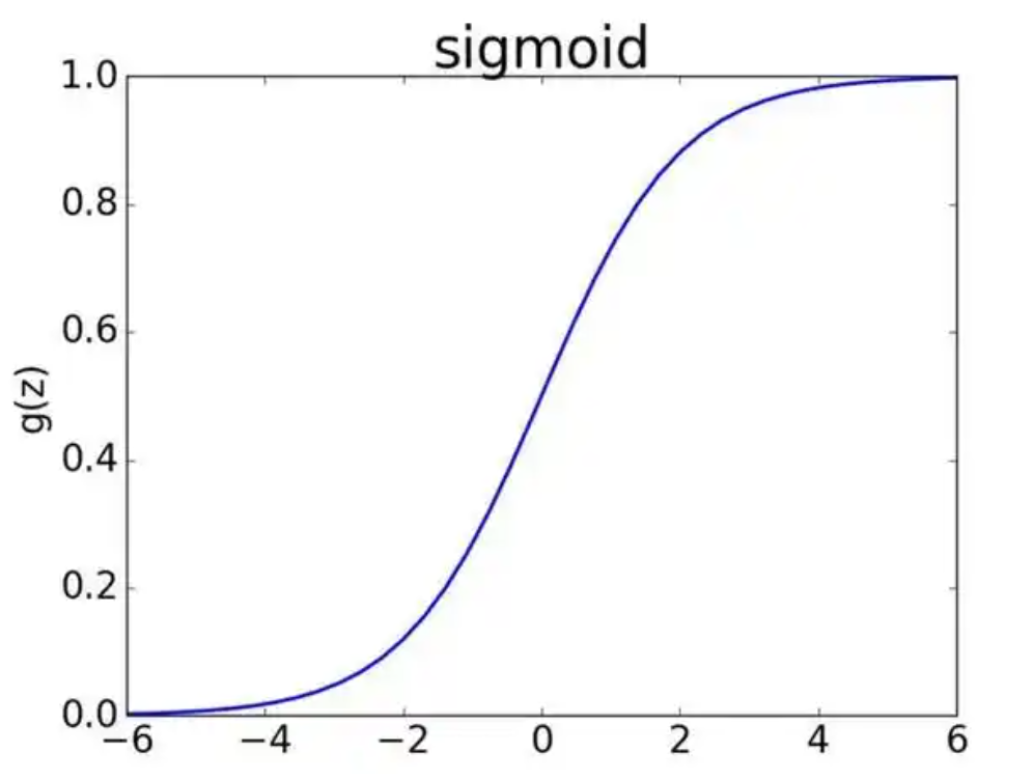
- 激活函數(比如sigmoid)是“水溫上升的規律”——它規定了“火力大小”和“最終水溫”的關系。
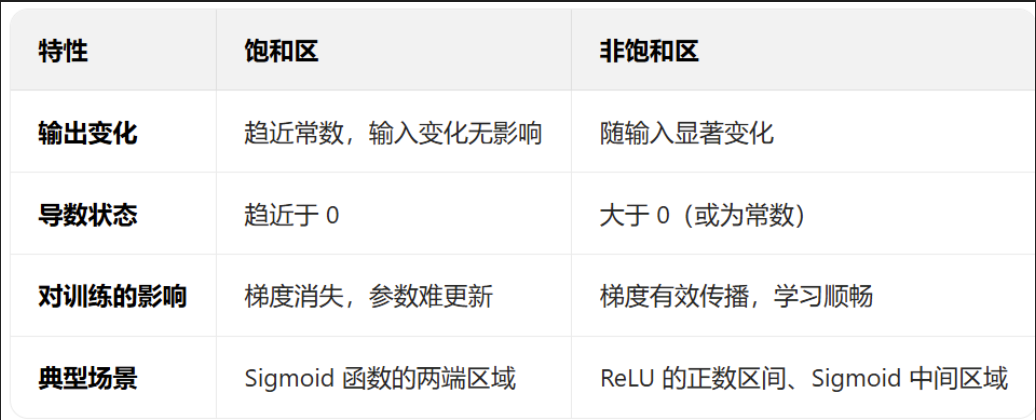
為什么初始火力不能開太大?(對應sigmoid的飽和區)
sigmoid這個“水溫規律”有個特點:
- 當“實際加熱量”(x = w·初始水溫 + 基礎加熱)比較小時(比如在20-80℃之間),水溫對火力變化非常敏感——你稍微調大一點火力,水溫就明顯上升(對應導數大,梯度大)。這時候你能快速調整火力,讓水溫接近目標(權重容易更新)。
- 但如果初始火力(w)開得太大,第一次加熱時“實際加熱量”就會猛增(比如直接燒到95℃),這時候水溫進入“飽和區”——不管你怎么調火力(調大或調小),水溫上升的速度都幾乎不變(對應導數接近0,梯度消失)。就像水已經快燒開了,你再加大火力,水也不會更快變熱,這時候你根本沒法通過調火力來精準控制水溫(權重無法更新)。
深層網絡的“串聯燒水”問題
深層網絡就像多個爐子排著隊燒水:第一個爐子燒完的水傳給第二個,第二個傳給第三個……如果第一個爐子的火力開太大,水燒到95℃后傳給第二個爐子,第二個爐子即使調火力,水最多只能燒到98℃(變化很小);傳到第三個爐子時,水溫幾乎不再變化……最終,第一個爐子的火力(底層參數)根本沒法調整——因為后面的爐子根本“感受不到”它的變化(梯度消失)。
總結
初始火力調小(比如在“小火”檔位),就像讓水一開始在“敏感升溫區”(20-80℃)。這時候你調火力(更新權重)能明顯改變水溫(梯度大),所有串聯的爐子(深層網絡)都能有效傳遞溫度變化,最終讓整排爐子的水溫(模型輸出)精準達到目標(模型收斂)。

 ?
?
?
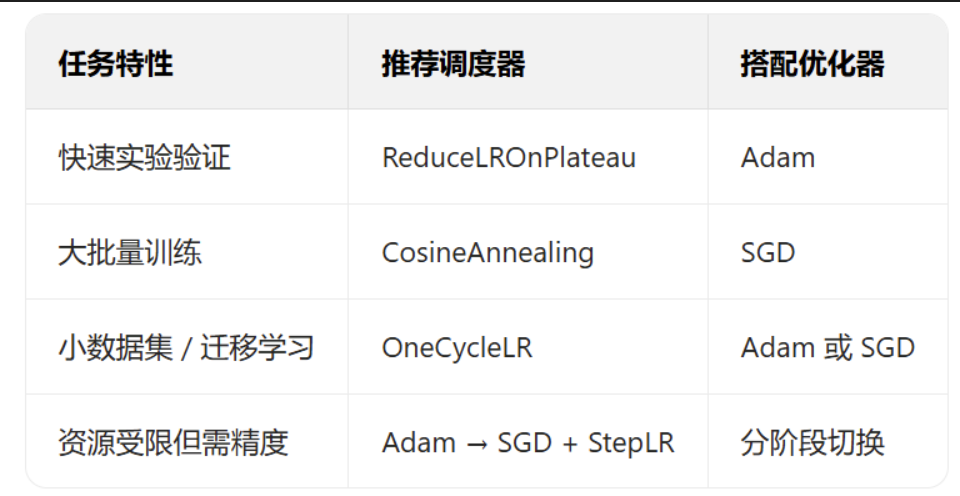
?簡單cnn 借助調參指南進一步提高精度
基礎CNN模型代碼
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical# 加載數據
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()# 數據預處理
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)# 基礎CNN模型
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])history = model.fit(train_images, train_labels, epochs=10, batch_size=64,validation_data=(test_images, test_labels))改進方法
增加模型復雜度
model = models.Sequential([layers.Conv2D(64, (3, 3), activation='relu', input_shape=(32, 32, 3), padding='same'),layers.BatchNormalization(),layers.Conv2D(64, (3, 3), activation='relu', padding='same'),layers.BatchNormalization(),layers.MaxPooling2D((2, 2)),layers.Dropout(0.25),layers.Conv2D(128, (3, 3), activation='relu', padding='same'),layers.BatchNormalization(),layers.Conv2D(128, (3, 3), activation='relu', padding='same'),layers.BatchNormalization(),layers.MaxPooling2D((2, 2)),layers.Dropout(0.25),layers.Conv2D(256, (3, 3), activation='relu', padding='same'),layers.BatchNormalization(),layers.Conv2D(256, (3, 3), activation='relu', padding='same'),layers.BatchNormalization(),layers.MaxPooling2D((2, 2)),layers.Dropout(0.25),layers.Flatten(),layers.Dense(512, activation='relu'),layers.BatchNormalization(),layers.Dropout(0.5),layers.Dense(10, activation='softmax')
])優化器調參
from tensorflow.keras.optimizers import Adamoptimizer = Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07)
model.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])數據增強
from tensorflow.keras.preprocessing.image import ImageDataGeneratordatagen = ImageDataGenerator(rotation_range=15,width_shift_range=0.1,height_shift_range=0.1,horizontal_flip=True,zoom_range=0.1
)
datagen.fit(train_images)history = model.fit(datagen.flow(train_images, train_labels, batch_size=64),epochs=50,validation_data=(test_images, test_labels))早停和模型檢查點
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpointcallbacks = [EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True),ModelCheckpoint('best_model.h5', monitor='val_accuracy', save_best_only=True)
]history = model.fit(..., callbacks=callbacks, epochs=100)?@浙大疏錦行


)

基于Pytorch手搓RNN參考)



)


模式與AP(Access Point)模式)







