Redis線程IO模型
總結:在redis5.0及之前,redis線程io模型是單線程。那么Redis單線程如何處理那么多的并發客戶端連接的?原因兩點:1)非阻塞io 2)多路復用(事件輪詢)
以下,我就針對上面的總結來展開說說redis線程io模型。
1、客戶端與redis服務器的通信過程
當客戶端執行redis.set(“key”,“value”)命令時,
- 客戶端通過操作系統創建一個套接字。
- 這個套接字會連接到運行 Redis 服務器的機器地址和端口(通常是 6379)。
- 一旦連接建立成功,你的程序就可以通過這個套接字向 Redis 服務器發送數據
- 客戶端將命令通過
write()進入 內核寫緩沖區。 - 內核寫緩存區的數據會從網卡 → redis服務端的內核讀緩沖區。
- redis服務端通過多路復用(epoll)得知內核讀緩存區有命令需要執行。
- 執行之后的響應數據進入Redis服務器的 內核寫緩沖區
- 接著內核寫緩存區的數據又會從網卡 → redis客戶端的內核讀緩沖區。
- 客戶端通過
read()獲取響應數據。
當客戶端執行redis.get(“key”)命令時,
- 客戶端將命令通過
write()進入 內核寫緩沖區。 - 內核寫緩存區的數據會從網卡 → redis服務端的內核讀緩沖區。
- redis服務端通過多路復用(epoll)得知內核讀緩存區有命令需要執行。
- 執行之后的響應數據進入Redis服務器的 內核寫緩沖區
- 接著內核寫緩存區的數據又會從網卡 → redis客戶端的內核讀緩沖區。
- 客戶端通過
read()獲取響應數據。
GET 命令全流程:
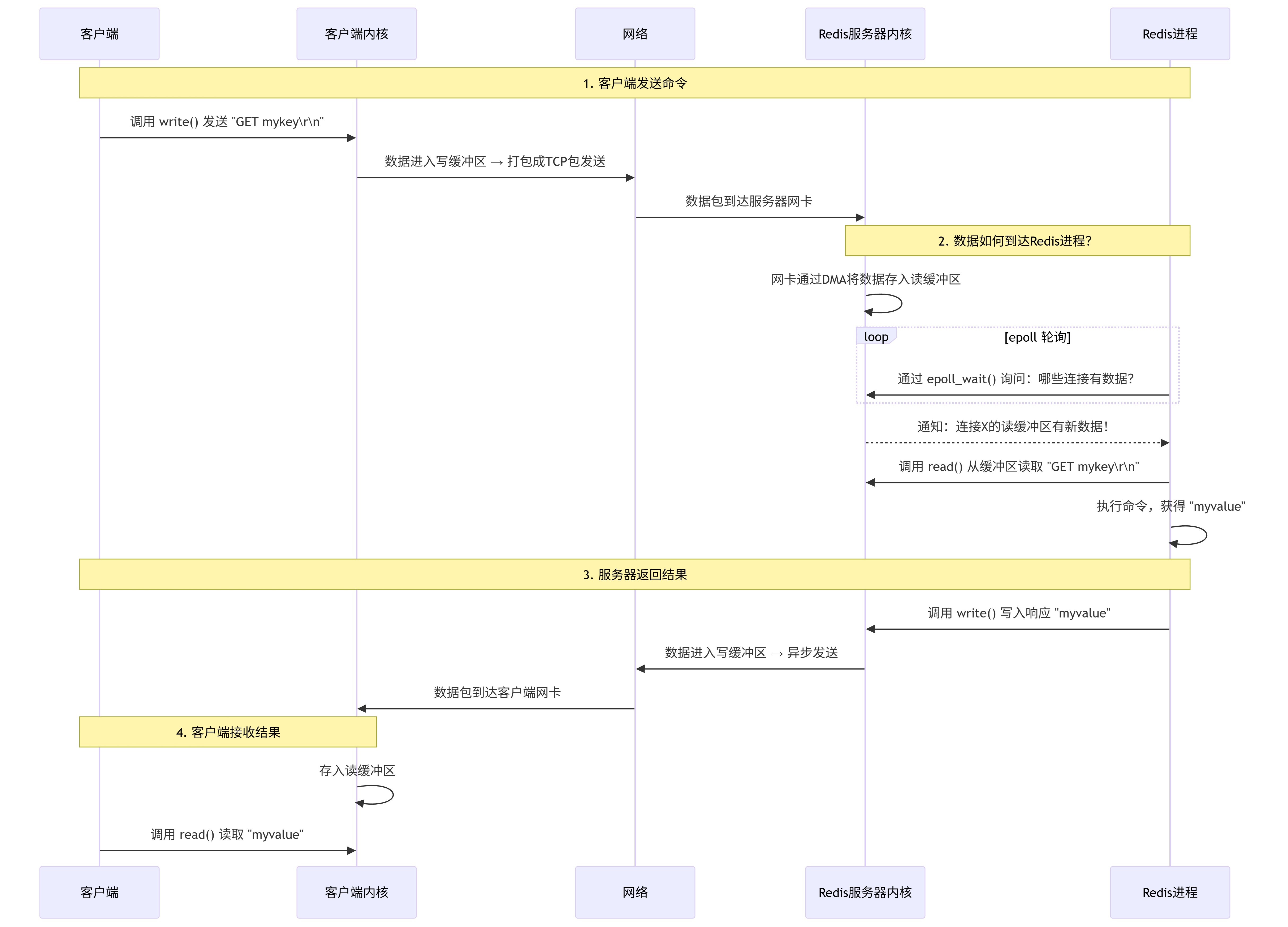
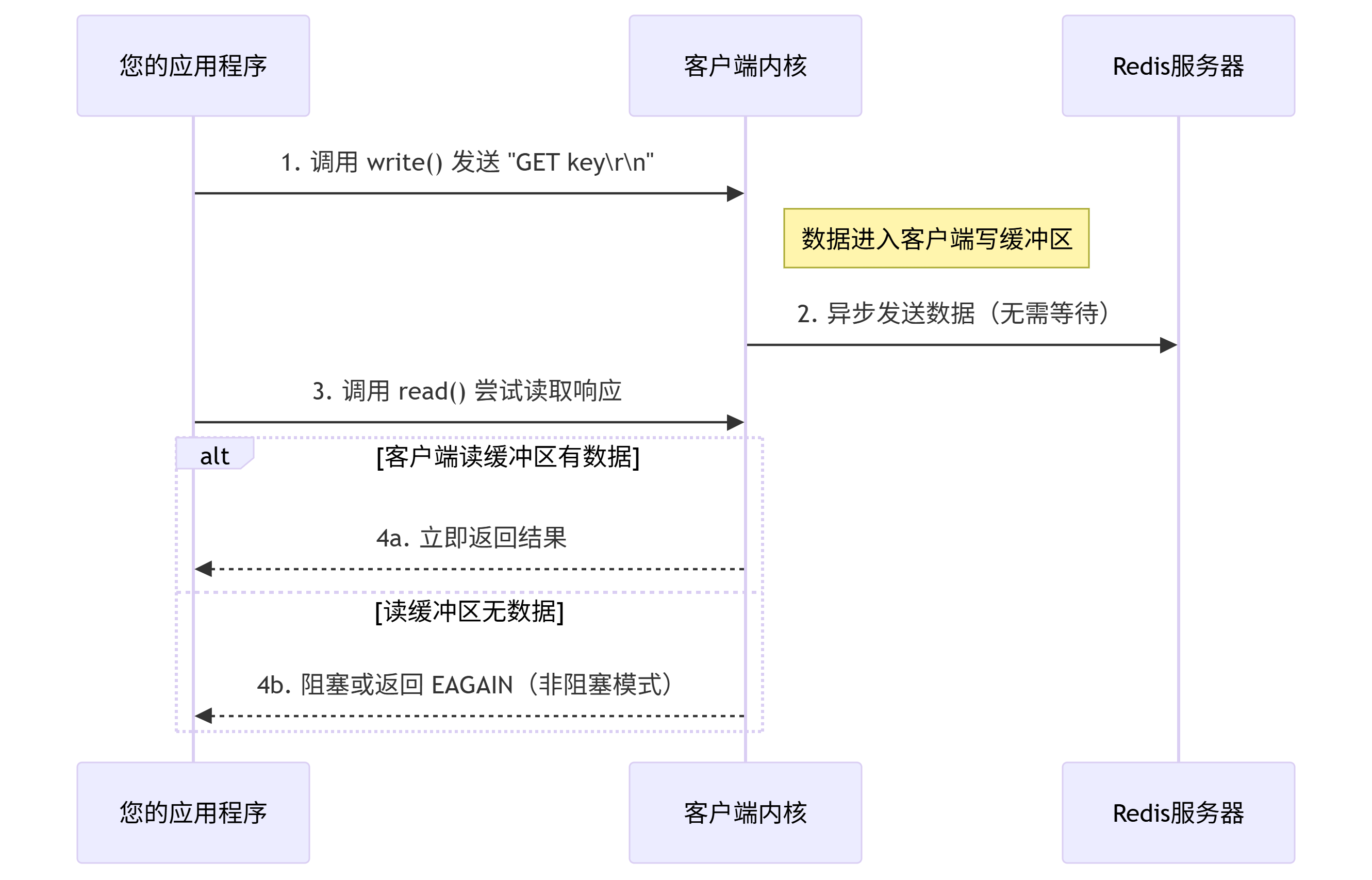
客戶端詳細視角:
服務端詳細視角:
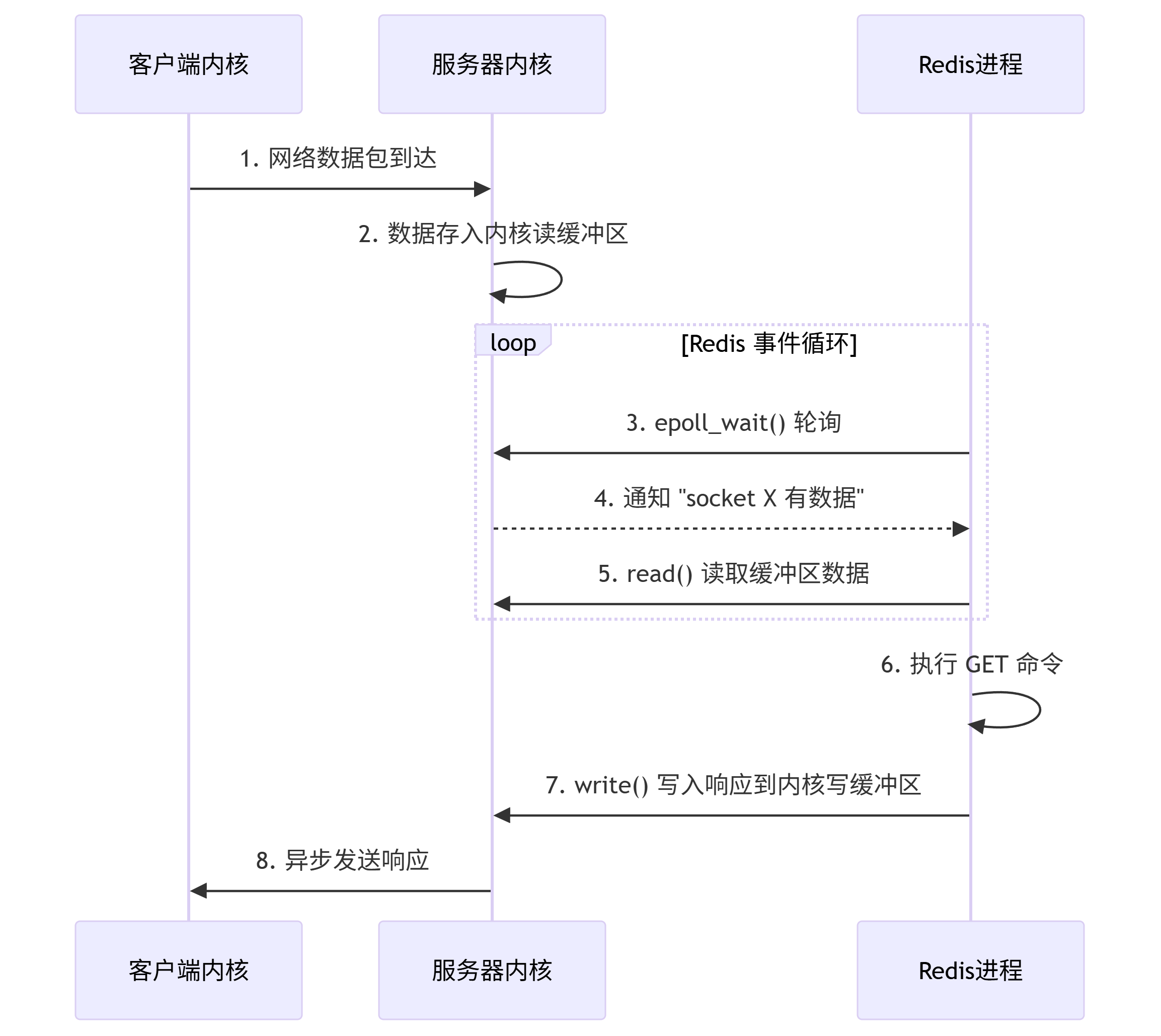
redis服務端視角就能體現Redis高性能的核心:
通過非阻塞IO + 多路復用(epoll/kqueue)單線程監聽所有連接的緩沖區狀態:
- 當某連接的讀緩沖區有數據 → 觸發Redis讀取命令
- 當某連接的寫緩沖區有空閑 → 觸發Redis發送響應
此時你可能還不了解非阻塞IO和多路復用究竟是什么?沒事,繼續看下去。
這里要特別注意,**這里的非阻塞IO是指redis服務器,而非客戶端。**因此下面將對比介紹阻塞IO和非阻塞IO,以及多路復用(事件循環)。
2、非阻塞IO & 阻塞IO
阻塞IO:典型的例子就是Java 的 Jedis(同步阻塞客戶端)。
jedis.get(“key”) :
-
觸發 write():客戶端將
GET key命令寫入內核寫緩沖區 → 通常瞬間完成- 緩沖區未滿:寫入數據
- 緩沖區滿了:線程卡在
write()調用(阻塞)
-
觸發read():客戶端嘗試從內核讀緩沖區讀取 Redis 的響應(如
"value")-
有數據:立即返回結果 → 線程繼續執行
-
無數據:線程卡在
read()調用(阻塞)
-
非阻塞IO:典型的例子就是Redis 服務器內部
Redis 將 socket 設置為 Non_Blocking,
- 調用
read()時無數據,也會立刻返回EAGAIN錯誤而非阻塞。 - 調用
write()時無空間,也會立刻返回EAGAIN錯誤而非阻塞。
這邊想要再擴展一個非阻塞IO的例子:
支持非阻塞的客戶端庫(如 Lettuce)
commands.get()將命令寫入內核寫緩沖區(非阻塞寫)。- 客戶端庫 注冊回調函數 并立即返回。
- 庫內部用 Selector 輪詢 內核讀緩沖區 → 數據到達后調用回調。
其實,redis只有在感知到內核讀緩沖區有數據時,才會調用 read() 去讀取數據。
那么redis是怎么感知到內核讀緩沖區有數據的?當緩沖區滿了,又是怎么知道要什么時候能繼續寫入數據?答案就是通過多路復用(epoll)。
3、多路復用(epoll)
// Redis 事件循環偽代碼
void eventLoop() {while(server.running) {// 0. 計算超時時間(動態值,假設為200ms)timeout = calculate_timeout(); // 1. 獲取待處理事件(核心:epoll_wait 在此等待,最多只會阻塞等待timeout時間,如果在這個超時時間內有數據了就會恢復運行態,如果在這個超時時間內依然沒有數據,那么就會去處理其他事件,比如時間事件)events = epoll_wait(epoll_fd, events, MAX_EVENTS, timeout); // 2. 處理文件事件(網絡請求,處理命令)for each event in events:if event.is_readable: // 可讀事件 → 執行客戶端命令readQueryFromClient()if event.is_writable: // 可寫事件 → 發送響應writeReplyToClient()// 3. 處理時間事件(定時任務,如RDB備份、Key過期)processTimeEvents()}
}
流程圖如下:
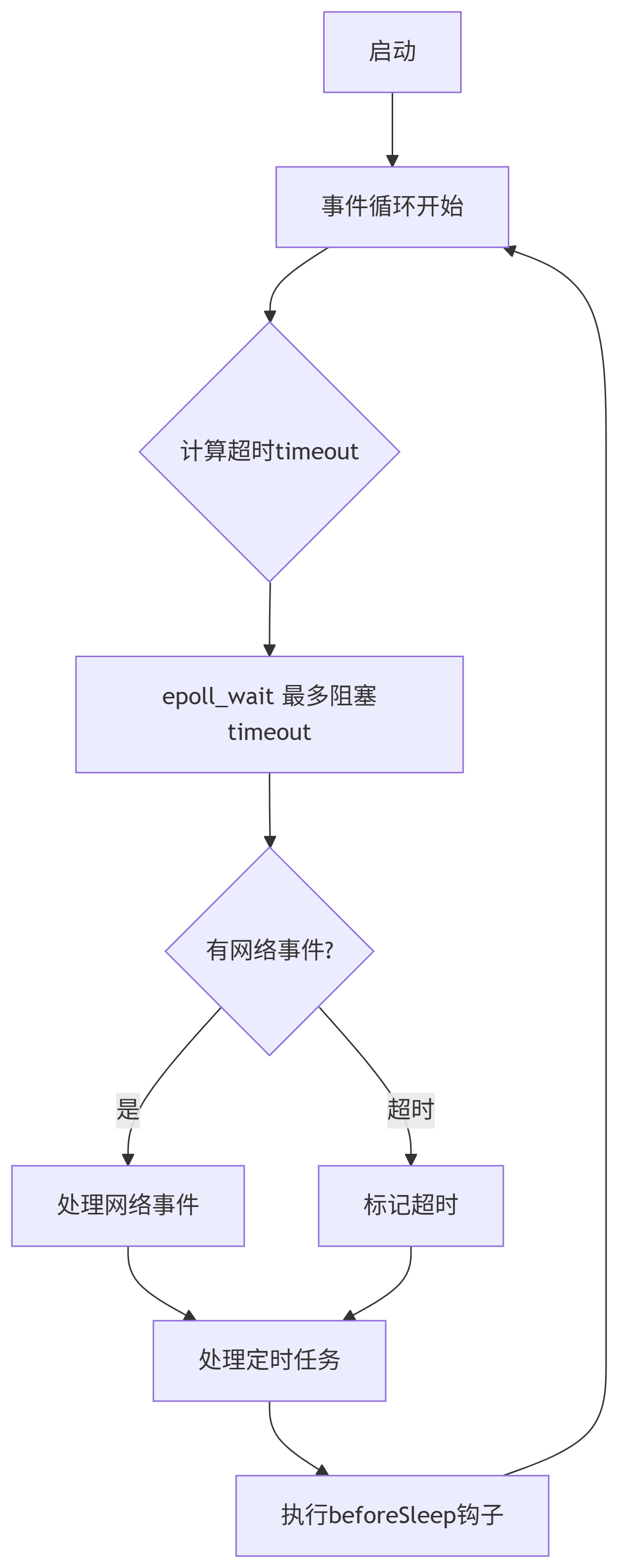
以上代碼,基本可以說明redis單線程都在干什么了:
一個永不停止的循環(while(1)),用 單線程 同時監聽 所有客戶端連接 + 定時任務 + 內部任務,通過事件分發處理請求。
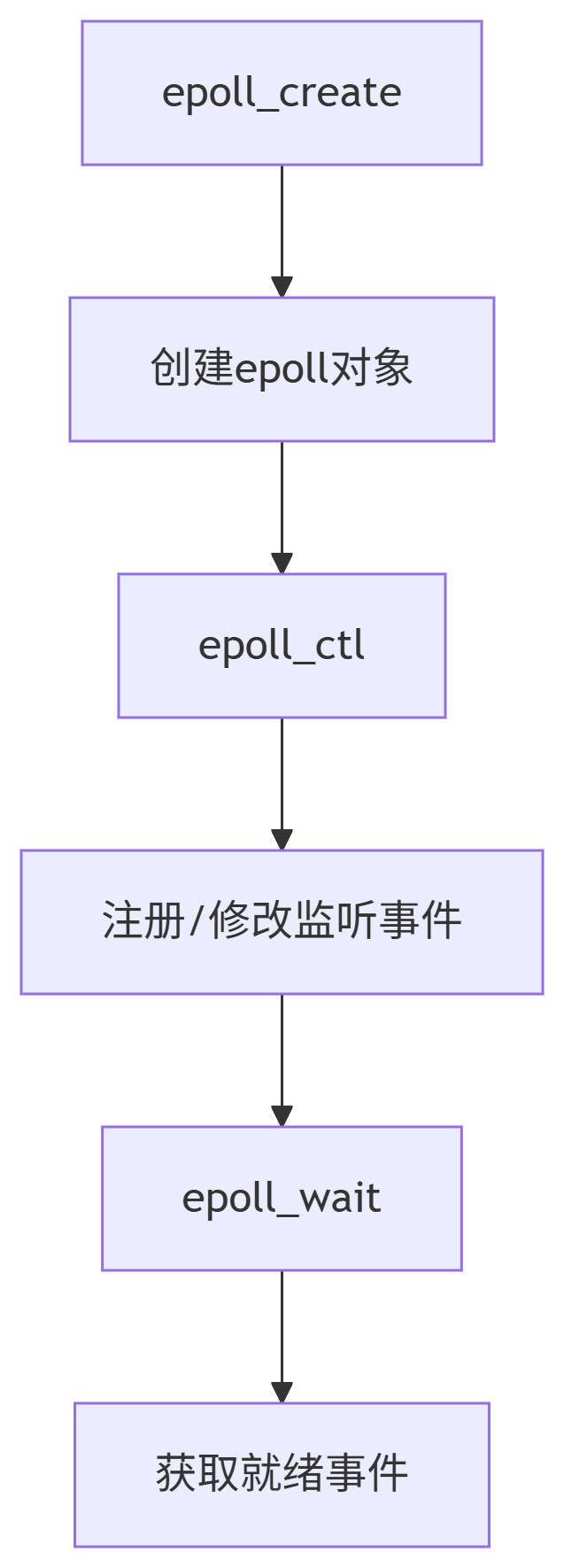
這里具體介紹epoll機制:
// Redis 僅通過 epoll 做一件事:
int num_events = epoll_wait(epoll_fd, events, MAX_EVENTS, timeout);
- 監聽對象:所有客戶端連接的 socket
- 監聽事件:
EPOLLIN:內核讀緩沖區有數據可讀(客戶端命令到達)EPOLLOUT:內核寫緩沖區有空閑空間(可發送響應)
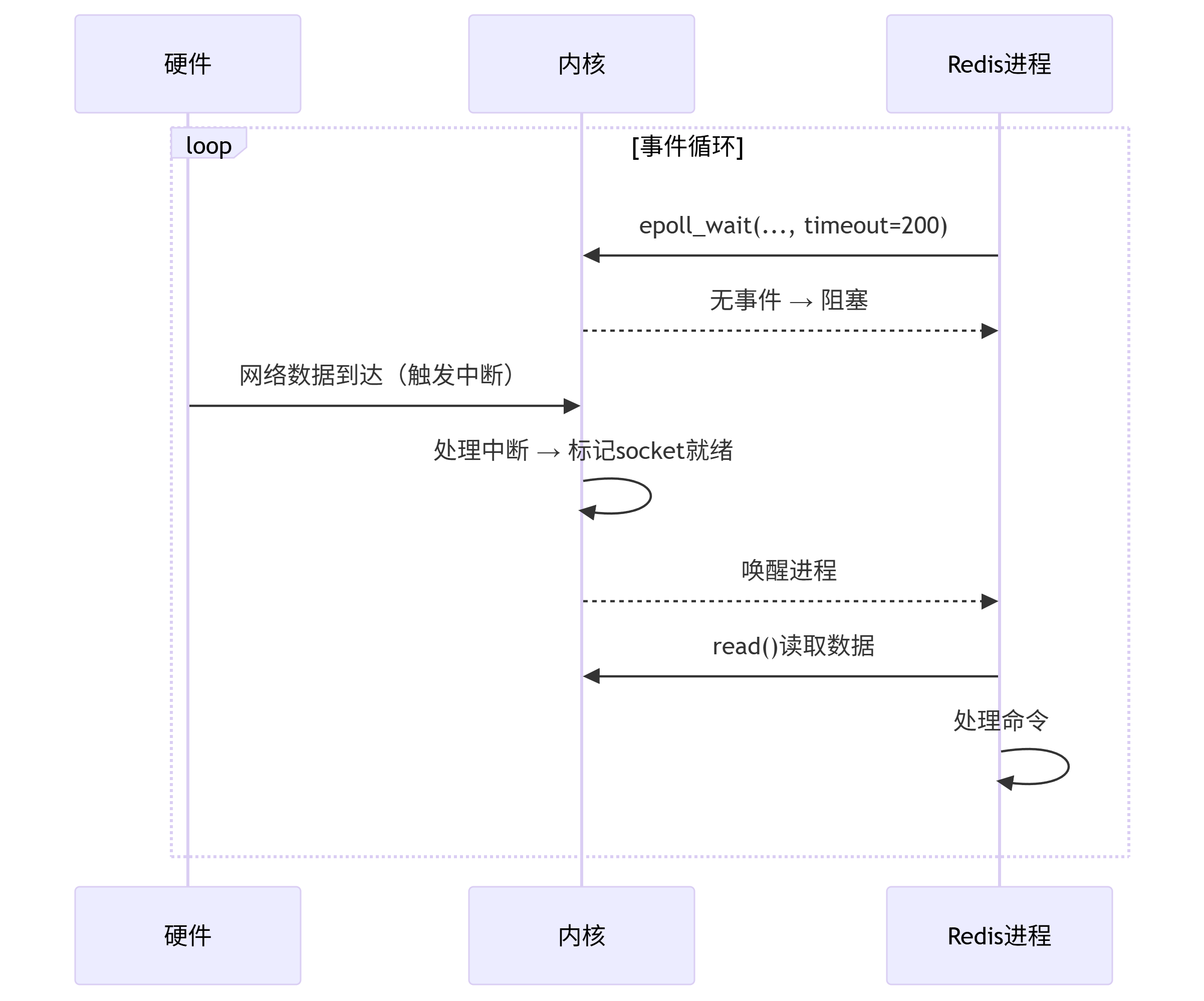
epoll 感知事件的底層原理是全程無CPU輪詢!依賴硬件中斷。
// 系統調用流程
int epoll_wait() {// 1. 檢查就緒隊列(快速路徑)if (!list_empty(rdllist)) return events; // 立即返回// 2. 無事件時:讓出CPUset_current_state(TASK_INTERRUPTIBLE); // 標記為阻塞態schedule(); // 主動讓出CPU → 其他進程運行
}
也就是說,進入epoll_wait方法,該redis單線程是處于阻塞態的,不占cpu的任何消耗。
這里我還想補充一點,就是之前我學的,redis的rdb持久化以及aof重寫過程中會fork一個子進程、aof是開啟后臺線程刷屏、以及redis4.0出現的懶惰刪除也是在后臺線程進行的。以上三種情況與redis的單線程又是什么關系呢?
可以這樣理解:Redis的「單線程」本質上是對命令執行模型的核心描述,但整個系統確實存在多線程/多進程協作。
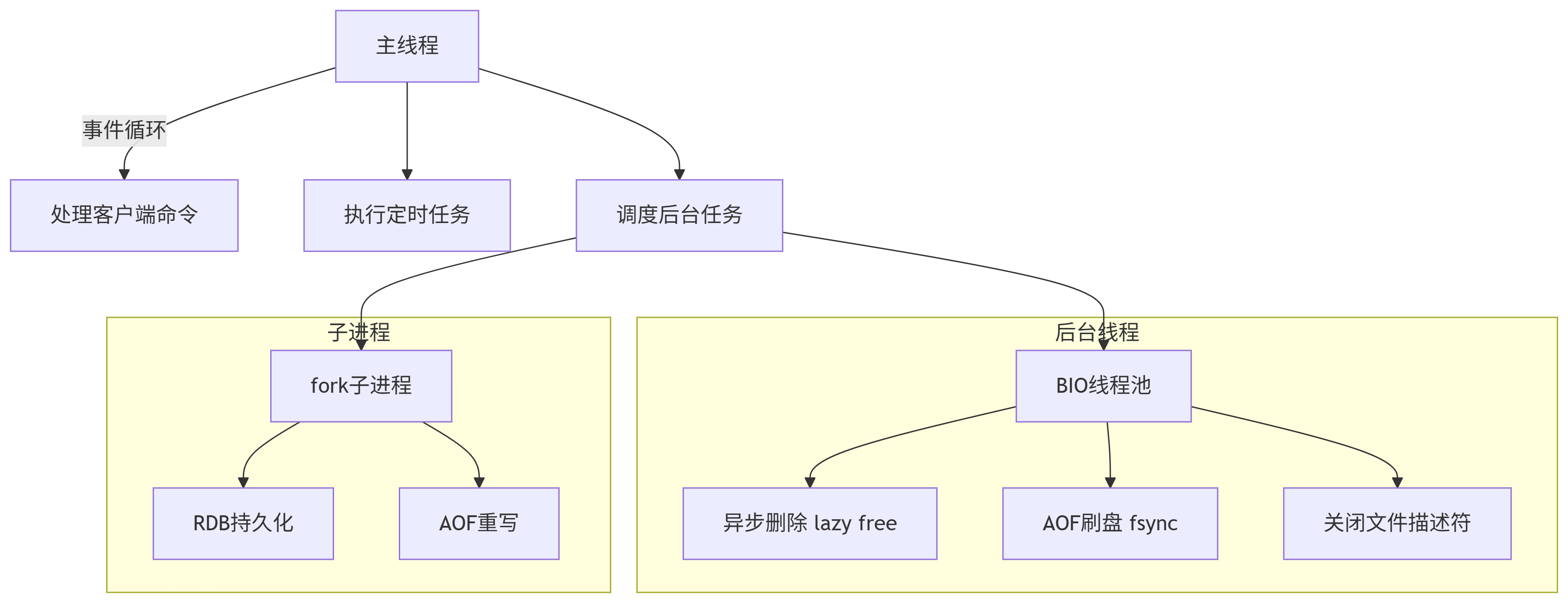
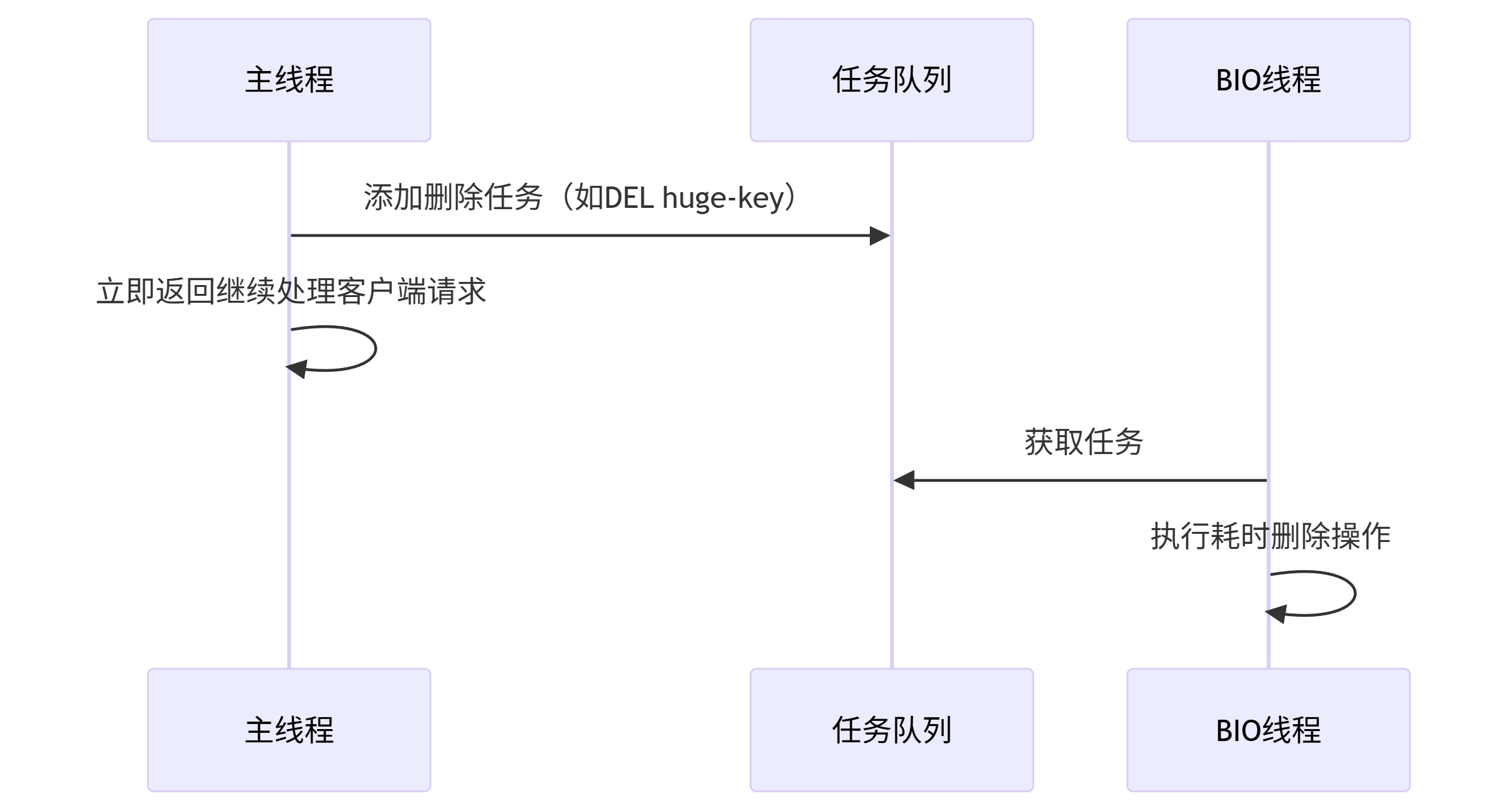
BIO后臺線程(Background I/O Threads):
- AOF fsync :將AOF緩沖數據刷盤,因為
fsync()可能阻塞30ms+ - lazy free :異步刪除大Key,避免主線程阻塞數秒。(BIO線程刪除Key時,主線程已將該Key標記為邏輯刪除(移除key的指針的指針引用),BIO只是物理釋放內存)
子進程(Child Process):
- AOF重寫 觸發
BGREWRITEAOF,fork子進程,父子進程共享內存頁,Copy-On-Write 寫時復制 - RDB持久化 執行
SAVE/ 定時保存,fork子進程,父子進程共享內存頁,Copy-On-Write 寫時復制
總結:主線程獨占寫操作(100%),而子進程是只讀數據,而BIO線程只處理非數據操作。
- AOF重寫 觸發
BGREWRITEAOF,fork子進程,父子進程共享內存頁,Copy-On-Write 寫時復制 - RDB持久化 執行
SAVE/ 定時保存,fork子進程,父子進程共享內存頁,Copy-On-Write 寫時復制
總結:主線程獨占寫操作(100%),而子進程是只讀數據,而BIO線程只處理非數據操作。
:Linux進程信號深度解析)








自動化測試工具:如何讓我的開發效率提升300%并保證代碼質量?)





)



