1.二叉樹,紅黑樹,B 樹,B+樹
二叉樹:就是每個節點最多只能有兩個子節點的樹;
紅黑樹:就是自平衡二叉搜索樹,紅黑樹通過一下五個規則構建:
1.節點只能是紅色或黑色;
2.根節點只能是黑色;
3.不能有連續的紅色節點;
4.葉子節點為黑色;
5.從任意節點到其所有葉子節點的路徑上,黑色節點數相同,黑稿平衡
B 樹:多路平衡搜索樹,所有節點都存儲數據;
B+樹:非葉子節點只存鍵,數據全部存在葉子節點;
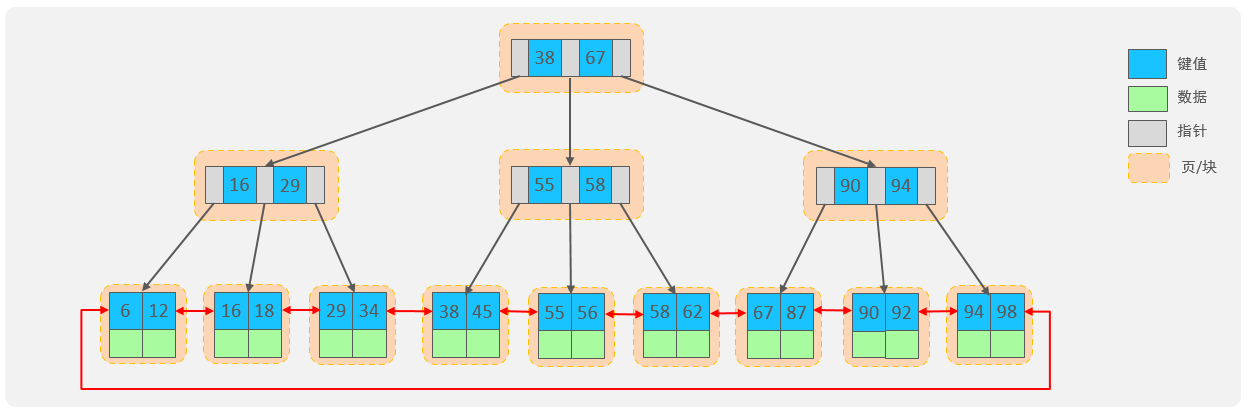
2.索引的底層數據結構了解過嘛 ?
索引的底層數據結構采用了 B+樹加雙向鏈表的形式實現,N 階 B 樹其實就是每個節點最多存儲 N - 1 個鍵值對和 N 個指針,指向某個鍵值對的一邊,而 N 階 B+ 樹其實就是每個節點最多存儲 N - 1 個鍵和 N 個指針 ,只有葉子節點才存儲鍵值,一旦一個節點存儲的 Key 大于 N,中間元素會向上分裂;
而在索引中的 B+ 樹就是在葉子節點之間構成一個雙向鏈表,用于范圍查詢。
3.什么是聚簇索引什么是非聚簇索引 ?
聚簇索引:一個表只能有一個聚簇索引,聚簇索引的葉子節點直接存儲行數據,主鍵默認是聚簇索引,如果沒有主鍵則隱式構建 ROWID,優點是通過索引就可以獲取到數據,避免了回表查詢,缺點是插入速度依賴主鍵順序;
非聚簇索引:就是索引的葉子節點只存主鍵值,而非完整的數據,一個表可以有多個非聚簇索引,通過索引找到主鍵后,需要回到聚簇索引獲取完整數據。
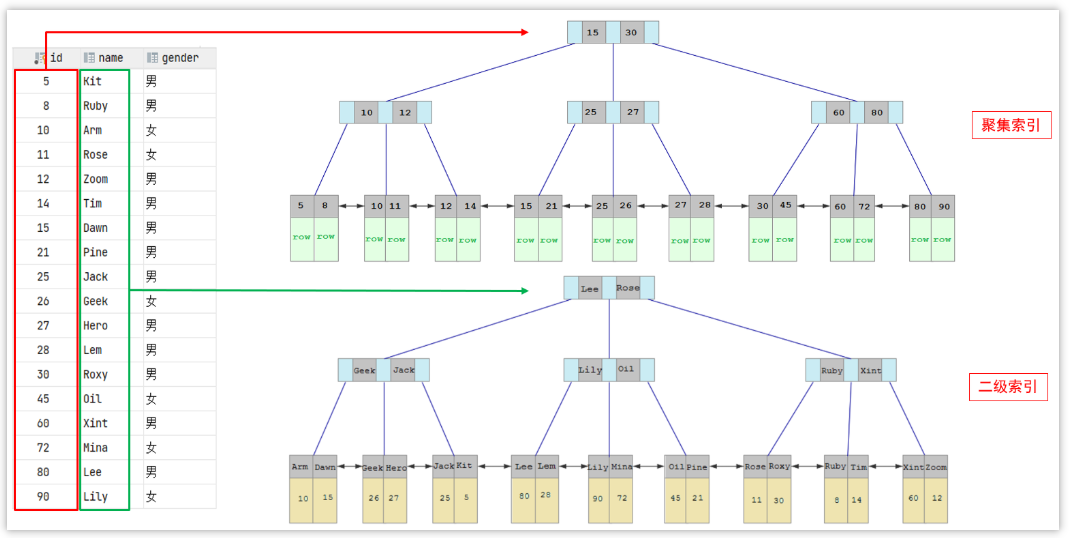
4.知道什么是回表查詢嘛 ?
回表查詢是查詢數據時通過非聚簇索引進行查詢,查詢出來的只是數據的主鍵,還需要通過主鍵去查詢聚簇索引,才能得到完整的數據。
5.索引創建原則有哪些?
1.高頻查詢字段:where,on,order by,group by 等高頻使用的字段;
2.高區分度字段:使用由高區分度的字段,ID,身份證而不是性別;
3.短字段優先:使用整型而不是 VARCHAR;
4.覆蓋索引優化:高頻查詢字段,可以建立聯合索引覆蓋查詢字段,達到不用回表查詢的目的;
5.范圍查詢字段放最后:將范圍查詢字段放最后,避免索引失效;
6.最左前綴匹配原則:只能最左前綴匹配,避免中間斷開;
6.知道什么是左前綴原則嘛 ?
如果索引了多列(聯合索引),要遵守最左前綴法則。最左前綴法則指的是查詢
從索引的最左列開始,并且不跳過索引中的列。如果跳躍某一列,索引將會部分
失效(后面的字段索引失效)。
7.知道什么叫覆蓋索引嘛 ?
覆蓋索引是指查詢使用了索引,并且需要返回的列,在該索引中已經全部能夠找到 。
8.索引是越多越好嘛? 什么樣的字段需要建索引, 什么樣的字段不需要?
索引并不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率。針對于數據量較大,且查詢比較頻繁的表建立索引。
針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索引。
不適合創建索引的字段:
-
-
- 更新頻繁字段不適合創建索引
- 若是不能有效區分數據的列不適合做索引列(如性別,男女未知,最多也就三種,區分度實在太低)
- 對于那些查詢中很少涉及的列,重復值比較多的列不要建立索引。比如省會,城市、月份
- 對于定義為text、image和bit的數據類型的列不要建立索引
-




)



Linux性能優化-CPU-性能優化)




![[安卓按鍵精靈輔助工具]一些安卓端可以用的雷電模擬器adb命令](http://pic.xiahunao.cn/[安卓按鍵精靈輔助工具]一些安卓端可以用的雷電模擬器adb命令)





