PP-OCRv4 文本框檢測
1. 模型介紹
如有需要可以前往我們的倉庫進行查看 凌智視覺模塊
PP-OCRv4在PP-OCRv3的基礎上進一步升級。整體的框架圖保持了與PP-OCRv3相同的pipeline,針對檢測模型和識別模型進行了數據、網絡結構、訓練策略等多個模塊的優化。
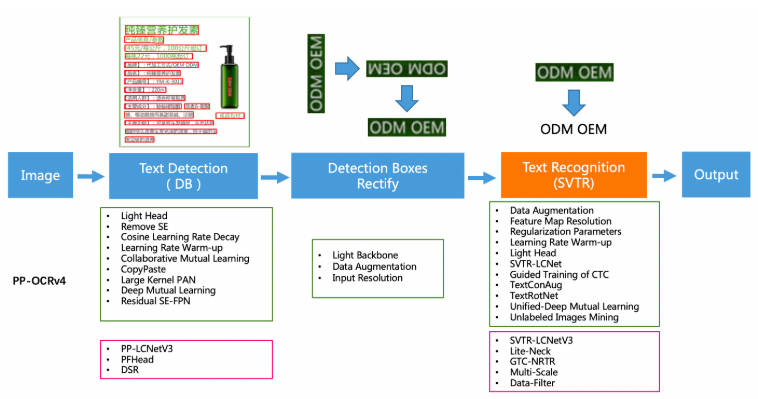
從算法改進思路上看,分別針對檢測和識別模型,進行以下方面的改進:
檢測模塊:
- LCNetV3:精度更高的骨干網絡
- PFHead:并行head分支融合結構
- DSR: 訓練中動態增加shrink ratio
- CML:添加Student和Teacher網絡輸出的KL div loss
原理可前往PPOCR技術報告查看:https://paddlepaddle.github.io/PaddleOCR/v2.9/ppocr/blog/PP-OCRv4_introduction.html#1pfheadhead
2. 模型轉換
參考RKNN Model ZOO將 PPOCRv4 的文本檢測模型轉化成 RKNN 模型。
import sys
from rknn.api import RKNNDATASET_PATH = '../../../../datasets/PPOCR/imgs/dataset_20.txt'
DEFAULT_RKNN_PATH = '../model/ppocrv4_det.rknn'
DEFAULT_QUANT = Truedef parse_arg():if len(sys.argv) < 3:print("Usage: python3 {} onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]".format(sys.argv[0]));print(" platform choose from [rk3562, rk3566, rk3568, rk3576, rk3588, rv1126b, rv1109, rv1126, rk1808]")print(" dtype choose from [i8, fp] for [rk3562, rk3566, rk3568, rk3576, rk3588, rv1126b]")print(" dtype choose from [u8, fp] for [rv1109, rv1126, rk1808]")exit(1)model_path = sys.argv[1]platform = sys.argv[2]do_quant = DEFAULT_QUANTif len(sys.argv) > 3:model_type = sys.argv[3]if model_type not in ['i8', 'u8', 'fp']:print("ERROR: Invalid model type: {}".format(model_type))exit(1)elif model_type in ['i8', 'u8']:do_quant = Trueelse:do_quant = Falseif len(sys.argv) > 4:output_path = sys.argv[4]else:output_path = DEFAULT_RKNN_PATHreturn model_path, platform, do_quant, output_pathif __name__ == '__main__':model_path, platform, do_quant, output_path = parse_arg()# Create RKNN objectrknn = RKNN(verbose=False)# Pre-process configprint('--> Config model')rknn.config(mean_values=[[123.675, 116.28, 103.53]], std_values=[[58.395, 57.12, 57.375]], target_platform=platform)print('done')# Load modelprint('--> Loading model')ret = rknn.load_onnx(model=model_path)if ret != 0:print('Load model failed!')exit(ret)print('done')# Build modelprint('--> Building model')ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)if ret != 0:print('Build model failed!')exit(ret)print('done')# Export rknn modelprint('--> Export rknn model')ret = rknn.export_rknn(output_path)if ret != 0:print('Export rknn model failed!')exit(ret)print('done')# Releaserknn.release()
根據目標平臺,完成參數配置,運行程序完成轉換。在完成模型轉換后可以查看 rv1106 的算子支持手冊,確保所有的算子是可以使用的,避免白忙活。
3. 模型部署
#include <iostream>
#include <cmath>
#include <opencv2/opencv.hpp>
#include "rknpu2_backend/rknpu2_backend.h"
#include <cstdlib>
#include <ctime>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include "postprocess.h"
#include <lockzhiner_vision_module/edit/edit.h>
#include <lockzhiner_vision_module/vision/utils/visualize.h>// 用于計時的頭文件
#include <chrono>using namespace std::chrono;int main(int argc, char *argv[])
{if (argc != 2){std::cerr << "Usage: " << argv[0] << " <model_path>" << std::endl;return 1;}const std::string model_path = argv[1];// 初始化RKNN后端lockzhiner_vision_module::vision::RKNPU2Backend backend;if (!backend.Initialize(model_path)){std::cerr << "Failed to initialize RKNN backend" << std::endl;return -1;}lockzhiner_vision_module::edit::Edit edit;if (!edit.StartAndAcceptConnection()){std::cerr << "Error: Failed to start and accept connection." << std::endl;return EXIT_FAILURE;}std::cout << "Device connected successfully." << std::endl;// 打開攝像頭cv::VideoCapture cap;cap.set(cv::CAP_PROP_FRAME_WIDTH, 640);cap.set(cv::CAP_PROP_FRAME_HEIGHT, 480);cap.open(0);if (!cap.isOpened()){std::cerr << "Error: Could not open camera." << std::endl;return 1;}cv::Mat image;int frame_count = 0; // 幀計數器while (true){cap >> image;if (image.empty())continue;frame_count++;// 每隔3幀處理一次(即每4幀處理1次)if (frame_count % 4 == 1){// 獲取輸入Tensor的信息auto input_tensor = backend.GetInputTensor(0);std::vector<size_t> input_dims = input_tensor.GetDims();float input_scale = input_tensor.GetScale();int input_zp = input_tensor.GetZp();// 預處理cv::Mat preprocessed = preprocess(image, input_dims, input_scale, input_zp);if (preprocessed.empty()){std::cerr << "Preprocessing failed" << std::endl;goto skip_inference;}// 驗證輸入數據尺寸size_t expected_input_size = input_tensor.GetElemsBytes();size_t actual_input_size = preprocessed.total() * preprocessed.elemSize();if (expected_input_size != actual_input_size){std::cerr << "Input size mismatch! Expected: " << expected_input_size<< ", Actual: " << actual_input_size << std::endl;goto skip_inference;}// 拷貝輸入數據void *input_data = input_tensor.GetData();memcpy(input_data, preprocessed.data, actual_input_size);// 開始計時auto start = high_resolution_clock::now();// 推理if (!backend.Run()){std::cerr << "Inference failed!" << std::endl;free(input_data);goto skip_inference;}// 結束計時auto end = high_resolution_clock::now();auto duration_ms = duration_cast<milliseconds>(end - start).count();std::cout << "Inference time: " << duration_ms << " ms" << std::endl;// 獲取輸出結果const auto &output_tensor = backend.GetOutputTensor(0);std::vector<size_t> output_dims = output_tensor.GetDims();float output_zp = output_tensor.GetZp();float output_scale = output_tensor.GetScale();const int8_t *output_data_int8 = static_cast<const int8_t *>(output_tensor.GetData());// 轉換為浮點型std::vector<float> output_data_float(output_tensor.GetNumElems());for (size_t i = 0; i < output_tensor.GetNumElems(); ++i){output_data_float[i] = (output_data_int8[i] - output_zp) * output_scale;}// 獲取原始圖像寬高int original_width = image.cols;int original_height = image.rows;float scale_w = (float)original_width / 480;float scale_h = (float)original_height / 480;// 后處理ppocr_det_result results = {0};dbnet_postprocess(output_data_float.data(),output_dims[2], output_dims[3],0.5, 0.3, true, "slow", 2.0, "quad",scale_w, scale_h, &results);// 繪制檢測框draw_boxes(&image, results);}skip_inference:// 顯示當前幀(無論是否進行了推理)edit.Print(image);// 按下 ESC 鍵退出if (cv::waitKey(1) == 27){break;}}cap.release();return 0;
}
4. 編譯程序
使用 Docker Destop 打開 LockzhinerVisionModule 容器并執行以下命令來編譯項目
# 進入Demo所在目錄
cd /LockzhinerVisionModuleWorkSpace/LockzhinerVisionModule/Cpp_example/D11_PPOCRv4-Det
# 創建編譯目錄
rm -rf build && mkdir build && cd build
# 配置交叉編譯工具鏈
export TOOLCHAIN_ROOT_PATH="/LockzhinerVisionModuleWorkSpace/arm-rockchip830-linux-uclibcgnueabihf"
# 使用cmake配置項目
cmake ..
# 執行編譯項目
make -j8
在執行完上述命令后,會在build目錄下生成可執行文件。
5. 執行結果
5.1 運行前準備
- 請確保你已經下載了 凌智視覺模塊字符檢測模型權重文件
5.2 運行過程
chmod 777 Test-ppocrv4
./Test-ppocrv4 ppocrv4_det.rknn
5.3 運行效果
5.3.1 ppocrv4字符識別
- 測試結果
- 測試時間
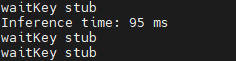
瓶頸分析,雖然 ppocrv4 的文本檢測模型的推理時間為 90ms 左右,但是在實際使用時建議使用跳幀檢測,不每一幀都進行推理,可以有效降低卡頓。
5.3.2 注意事項
由于本章節只部署了一個 PPOCRv4 的文字識別模型,并沒有訓練檢測模型,如需訓練自己的數據集,可使用 paddleOCR 訓練檢測模型。


![[Spring]-AOP](http://pic.xiahunao.cn/[Spring]-AOP)




)










)
 服務器:管理功能)