【AI大模型入門指南】概念與專有名詞詳解 (二)
一 、前言
當你和聊天機器人聊得天花亂墜時,當你用文字讓AI生成精美圖片時,當手機相冊自動幫你分類照片時 —— 這些看似智能的操作背后,都藏著 AI 大模型的身影。
本文將用最接地氣的比喻和案例,帶新手穿透專業術語的迷霧:從大模型家族,再到模型調教的核心邏輯(如何給模型喂數據、怎么讓它瘦身提速)。
無論你是對 AI 好奇的小白,還是想梳理知識框架的學習者,都可以有所收獲。
二、大模型專有名詞解釋
(一)模型家族成員
| 模型名稱 | 核心架構/特點 | 通俗比喻 | 典型應用場景 | 代表作/說明 |
|---|---|---|---|---|
| 大語言模型(LLM) | 采用Transformer架構,在海量文本數據中訓練 | 自然語言處理領域的“大佬” | 寫文章、做翻譯、回答問題等 | GPT系列、文心一言 |
| 循環神經網絡(RNN) | 擅長處理序列數據,但長距離理解能力較弱 | 像記憶力不好的人,讀長句子易“斷片” | 自然語言處理中的序列數據處理 | / |
| 長短期記憶網絡(LSTM) | RNN的改進版,增加特殊門控機制 | RNN的“加強版”,解決了記憶問題 | 更擅長處理長文本 | / |
| 卷積神經網絡(CNN) | 通過卷積、池化操作提取圖像特征 | 圖像識別的“主力軍” | 計算機視覺領域的圖像識別等任務 | / |
| 混合專家模型(MoE) | 包含多個“專家”,根據任務選擇合適“專家”處理并整合結果 | 有多個“專家”分工協作 | 處理大規模數據 | / |
| 圖神經網絡(GNN) | 專門處理圖形結構數據 | 圖形結構數據處理的“專家” | 社交網絡分析、分子結構研究等 | / |
(二)訓練那些事兒
1、預訓練:讓模型在海量無標注數據上“自學”,掌握通用知識,為后續學習打基礎。
2、微調:在預訓練基礎上,用特定領域少量有標注數據“開小灶”,讓模型適應具體任務,比如讓通用語言模型學會醫療術語。
3、監督微調(SFT):微調的一種,用標注好的“標準答案”數據訓練,讓模型在特定任務上表現更出色。
4、少樣本學習:只給模型看少量示例,它就能快速學會新任務,靠的是之前預訓練積累的“知識”。
5、 零樣本學習:模型沒見過相關數據也能推理,比如沒見過獨角獸,也能根據已有概念和描述回答相關問題。
6、對抗訓練:生成器和判別器“互相對抗”,生成器生成“假數據”,判別器分辨真假,讓模型更抗干擾,更魯棒。
7、 超參數調優:超參數是訓練前要設置的“學習參數”,像學習率、批量大小等,通過各種方法找到最佳組合,讓模型學習效果更好。
(三)其他重要概念
1、注意力機制:讓模型在處理數據時,能重點關注關鍵部分,就像看書時用熒光筆標記重點內容。
2、位置編碼:給Transformer模型“補課”,讓它記住數據的順序,不然模型容易“分不清先后”。
3、激活函數:給神經網絡增加“靈活性”,引入非線性因素,讓模型能學習復雜模式,ReLU函數就是常見的“得力助手”。
4、嵌入層:把離散數據(如單詞)轉換成連續向量,讓模型能理解單詞的語義,還能計算單詞相似度。
三、AI大模型的調教步驟
1、模型架構:Transformer——大模型的“黃金骨架”
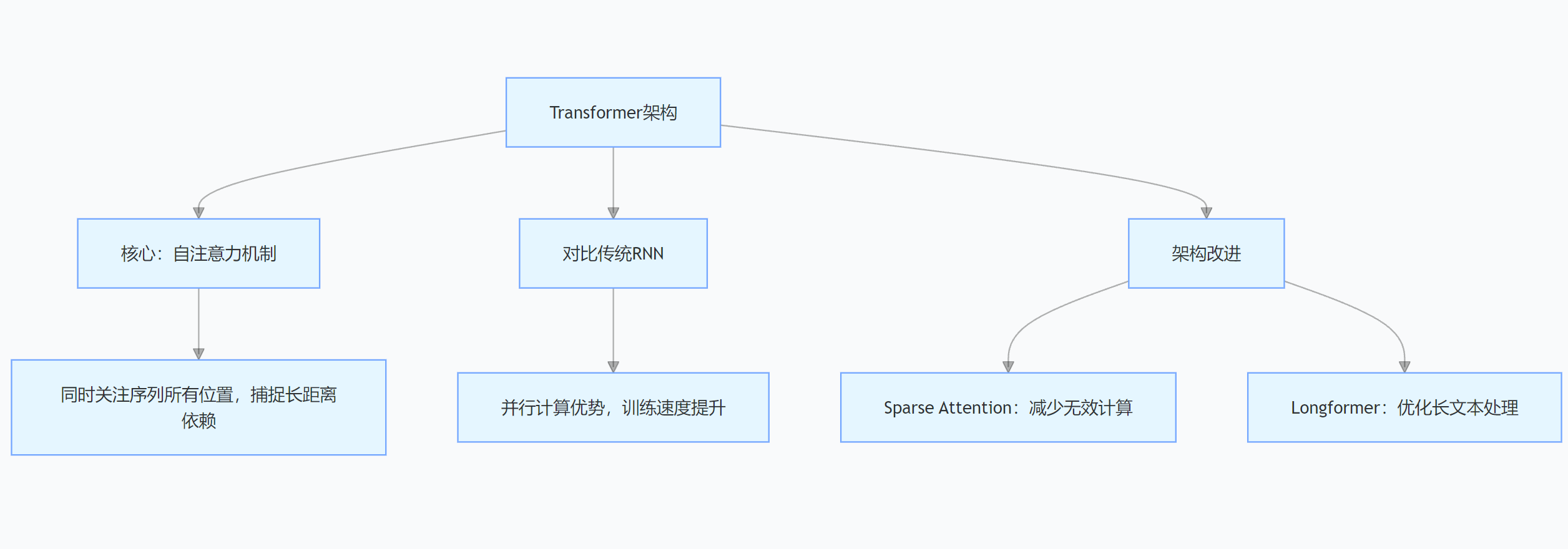
Transformer架構是大模型的“黃金骨架”,它的核心自注意力機制,就像給模型裝上了“鷹眼”,在處理文本等序列數據時,能同時關注每個位置,輕松捕捉長距離依賴關系。
和傳統RNN相比,Transformer在并行計算上優勢巨大,訓練速度就像坐了火箭。在機器翻譯中,它能精準理解源語言句子里詞匯的關系,翻譯出更流暢的譯文。
還有很多對Transformer的改進,比如Sparse Attention減少不必要計算,Longformer專為長文本優化,讓大模型處理數據更高效。
2、數據處理與預訓練:大模型的“營養餐”
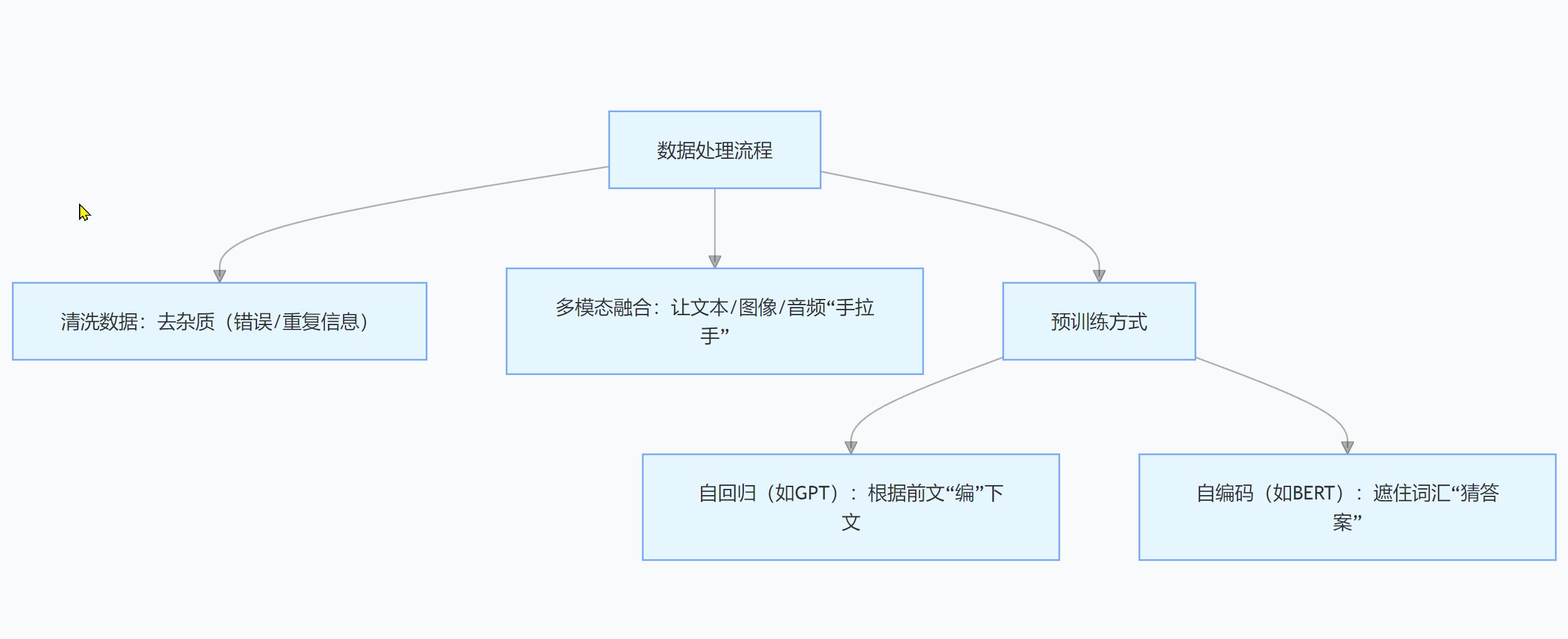
訓練大模型前,要先給它準備“營養餐”——處理海量數據。得先把數據里的“雜質”(錯誤、重復、無關信息)去掉,比如處理文本時要刪掉拼寫錯誤。
對于多模態數據,還得想辦法把不同形式的數據“融合”在一起,讓模型學習它們之間的聯系。
預訓練有兩種主要方式:自回歸,像GPT,根據前文預測下一個單詞,一點點“編”出文本;自編碼,像BERT,遮住部分輸入讓模型猜,以此學習文本語義和語法。
3、模型訓練與優化:大模型的“高效學習法”
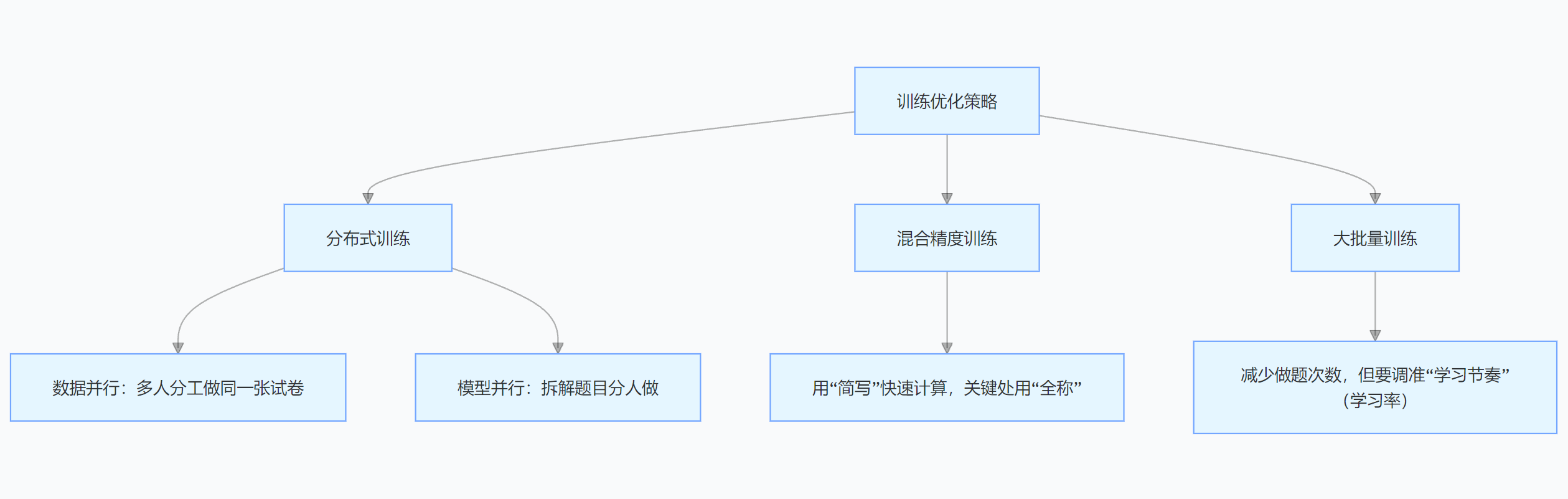
大模型參數太多,訓練起來超費時間和資源,所以要用分布式訓練。數據并行就像一群人分工合作,每個設備處理一部分數據,最后匯總結果;模型并行則是把模型拆分到不同設備上計算,大家齊心協力加快訓練速度。
還有混合精度訓練,就像靈活切換學習工具,用低精度數據快速計算,關鍵地方再用高精度數據保證準確,既能提速又能省顯存。
大批量訓練可以減少訓練次數,但得調整好學習率等參數,不然模型容易“學歪”。
4、模型壓縮:給大模型“瘦身”
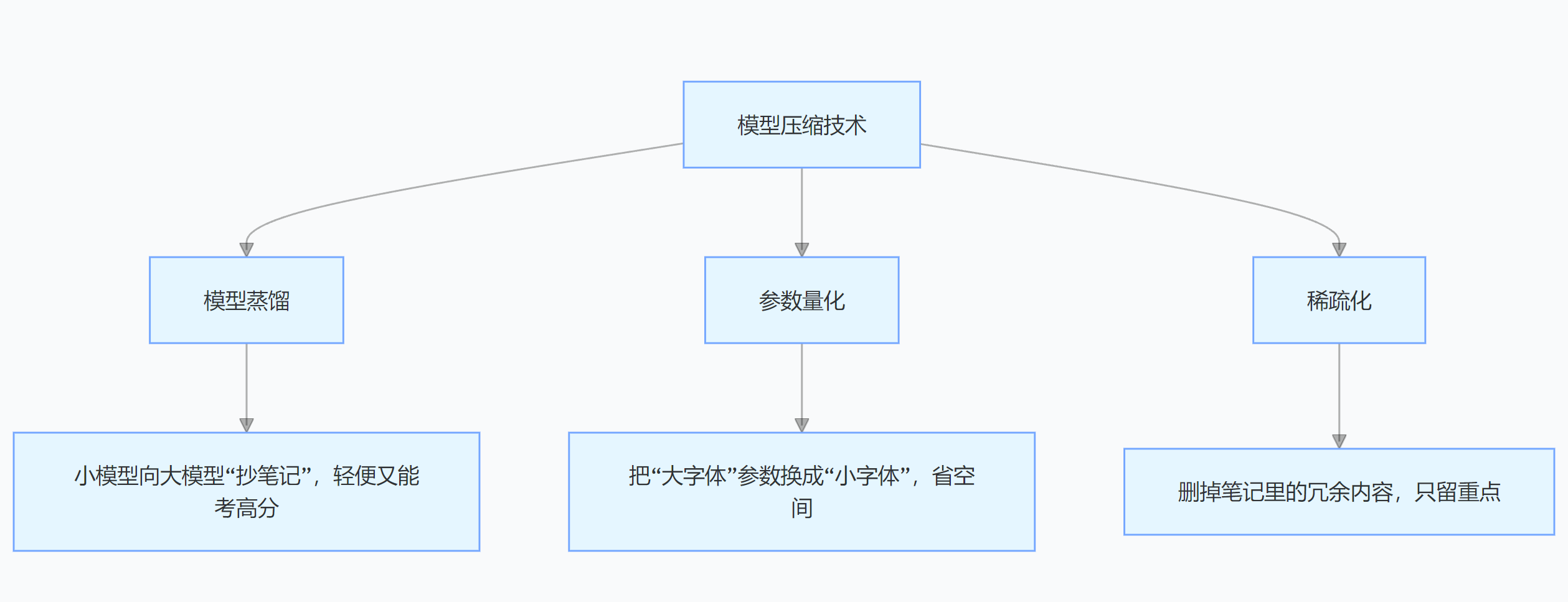
大模型訓練好后“體型龐大”,部署起來成本高,所以要“瘦身”。
模型蒸餾是讓小模型向大模型“拜師學藝”,小模型學到大模型的知識后,性能不錯還更輕便;參數量化降低權重精度,就像把書里的字變小,不影響理解還省空間。稀疏化去掉冗余參數,讓模型更簡潔高效。
 服務器:管理功能)



)












)
/pop()/數組方法_shift()/unshift())
:OpenBCI_GUI:從環境搭建到數據可視化(下))