
本文主要分享一個開源的 GPU 虛擬化方案:HAMi,包括如何安裝、配置以及使用。
相比于上一篇分享的 TimeSlicing 方案,HAMi 除了 GPU 共享之外還可以實現 GPU core、memory 得限制,保證共享同一 GPU 的各個 Pod 都能拿到足夠的資源。
1.為什么需要 GPU 共享、切分等方案?
開始之前我們先思考一個問題,為什么需要 GPU 共享、切分等方案?
或者說是另外一個問題:明明直接在裸機環境使用,都可以多個進程共享 GPU,怎么到 k8s 環境就不行了。
推薦閱讀前面幾篇文章:這兩篇分享了如何在各個環境中使用 GPU,在 k8s 環境則推薦使用 NVIDIA 提供的 gpu-operator 快速部署環境。
GPU 環境搭建指南:如何在裸機、Docker、K8s 等環境中使用 GPU
GPU 環境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 環境搭建
這兩篇則分析了 device-plugin 原理以及在 K8s 中創建一個申請 GPU 的 Pod 后的一些列動作,最終該 Pod 是如何使用到 GPU 的。
Kubernetes教程(二一)—自定義資源支持:K8s Device Plugin 從原理到實現
Kubernetes教程(二二)—在 K8S 中創建 Pod 是如何使用到 GPU 的:device plugin&nvidia-container-toolkit 源碼分析
看完之后,大家應該就大致明白了。
資源感知
首先在 k8s 中資源是和節點綁定的,對于 GPU 資源,我們使用 NVIDIA 提供的 device-plugin 進行感知,并上報到 kube-apiserver,這樣我們就能在 Node 對象上看到對應的資源了。
就像這樣:
root@liqivm:~# k describe node gpu01|grep Capacity -A 7
Capacity:cpu: 128ephemeral-storage: 879000896Kihugepages-1Gi: 0hugepages-2Mi: 0memory: 1056457696Kinvidia.com/gpu: 8pods: 110
可以看到,該節點除了基礎的 cpu、memory 之外,還有一個nvidia.com/gpu: 8 信息,表示該節點上有 8 個 GPU。
資源申請
然后我們就可以在創建 Pod 時申請對應的資源了,比如申請一個 GPU:
apiVersion: v1
kind: Pod
metadata:name: gpu-pod
spec:containers:- name: gpu-containerimage: nvidia/cuda:11.0-base # 一個支持 GPU 的鏡像resources:limits:nvidia.com/gpu: 1 # 申請 1 個 GPUcommand: ["nvidia-smi"] # 示例命令,顯示 GPU 的信息restartPolicy: OnFailure
apply 該 yaml 之后,kube-scheduler 在調度該 Pod 時就會將其調度到一個擁有足夠 GPU 資源的 Node 上。
同時該 Pod 申請的部分資源也會標記為已使用,不會在分配給其他 Pod。
到這里,問題的答案就已經很明顯的。
- 1)device-plugin 感知到節點上的物理 GPU 數量,上報到 kube-apiserver
- 2)kube-scheduler 調度 Pod 時會根據 pod 中的 Request 消耗對應資源
即:Node 上的 GPU 資源被 Pod 申請之后,在 k8s 中就被標記為已消耗了,后續創建的 Pod 會因為資源不夠導致無法調度。
實際上:可能 GPU 性能比較好,可以支持多個 Pod 共同使用,但是因為 k8s 中的調度限制導致多個 Pod 無法正常共享。
因此,我們才需要 GPU 共享、切分等方案。
上一篇文章一文搞懂 GPU 共享方案: NVIDIA Time Slicing 中給大家分享了一個 GPU 共享方案。
可以實現多個 Pod 共享同一個 GPU,但是存在一個問題:Pod 之間并未做任何隔離,每個 Pod 能用到多少 GPU core、memory 都靠競爭,可能會導致部分 Pod 占用大部分資源導致其他 Pod 無法正常使用的情況。
今天給大家分享一個開源的 vGPU 方案 HAMi。
ps:NVIDIA 也有自己的 vGPU 方案,但是需要 license
2. 什么是 HAMi?
HAMi 全稱是:Heterogeneous AI Computing Virtualization Middleware,HAMi 給自己的定位或者希望是做一個異構算力虛擬化平臺。
原 第四范式 k8s-vgpu-scheduler, 這次改名 HAMi 同時也將核心的 vCUDA 庫 libvgpu.so 也開源了。
但是現在比較完善的是對 NVIDIA GPU 的 vGPU 方案,因此我們可以簡單認為他就是一個 vGPU 方案。
整體架構如下:
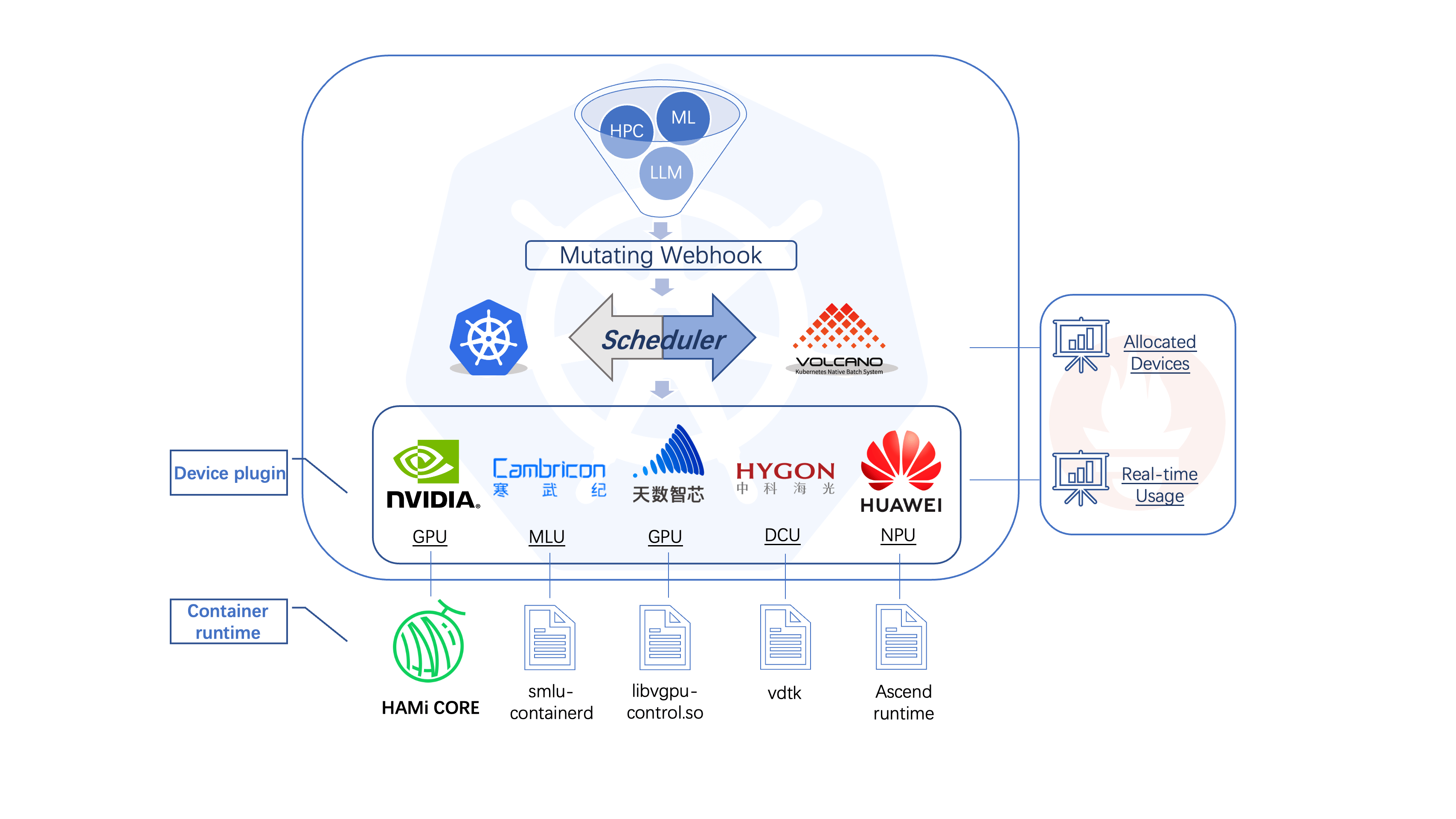
可以看到組件還是比較多的,設計到 Webhook、Scheduler、Device Plugin、HAMi-Core 等等。
這篇文章只講使用,因此架構、原理就一筆帶過,后續也會有相關文章,歡迎關注~。
Feature
使用 HAMi 最大的一個功能點就是可以實現 GPU 的細粒度的隔離,可以對 core 和 memory 使用 1% 級別的隔離。
具體如下:
apiVersion: v1
kind: Pod
metadata:name: gpu-pod
spec:containers:- name: ubuntu-containerimage: ubuntu:18.04command: ["bash", "-c", "sleep 86400"]resources:limits:nvidia.com/gpu: 1 # 請求1個vGPUsnvidia.com/gpumem: 3000 # 每個vGPU申請3000m顯存 (可選,整數類型)nvidia.com/gpucores: 30 # 每個vGPU的算力為30%實際顯卡的算力 (可選,整數類型)
- nvidia.com/gpu:請求一個 GPU
- nvidia.com/gpumem:只申請使用 3000M GPU Memory
- nvidia.com/gpucores:申請使用 30% 的 GPU core,也就是該 Pod 只能使用到 30% 的算力
相比于上文分享了 TimeSlicing 方案,HAMi 則是實現了 GPU core 和 memory 的隔離。
在開源方案里面已經算是比較優秀的了。
Design
HAMi 實現GPU core 和 memory 隔離、限制是使用的 vCUDA 方案,具體設計如下:
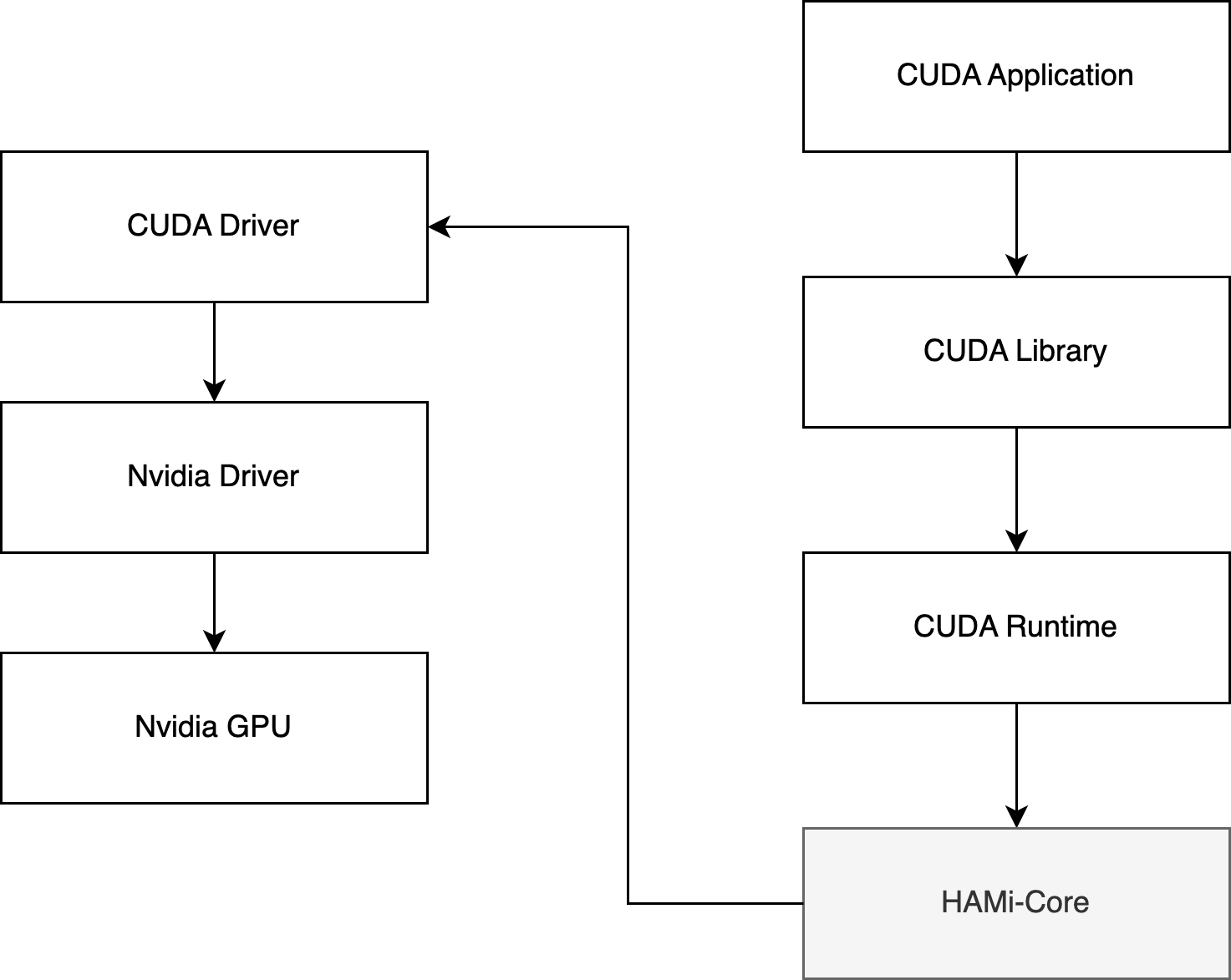
大部分使用 GPU 的應用都是用的 CUDA,HAMi 也是用的 vCUDA 方案,對 NVIDIA 原生的 CUDA 驅動進行重寫,然后掛載到 Pod 中進行替換,然后在自己的實現的 CUDA 驅動中對 API 進行攔截,使用資源隔離以及限制的效果。
例如:原生 CUDA 驅動進行內存分配,只有在 GPU 內存真的用完的時候才會提示 CUDA OOM,但是對于 HAMi CUDA 驅動來說,檢測到 Pod 中使用的內存超過了 Resource 中的申請量就直接返回 OOM,從而實現資源的一個限制。
然后在執行 nvidia-smi 命令查看 GPU 信息時,也只返回 Pod Resource 中申請的資源,這樣在查看時也進行隔離。
ps:需要對 CUDA 和 NVML 的部分 API 攔截。
3. HAMi 部署
HAMi 提供了 Helm Chart 安裝也是比較簡單的。
部署 GPU Operator
需要注意的是 HAMi 會依賴 NVIDIA 的那一套,因此推薦先部署 GPU-Operator。
參考這篇文章 --> GPU 環境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 環境搭建
部署好 GPU Operator 之后在部署 HAMi。
部署 HAMi
首先使用 helm 添加我們的 repo
helm repo add hami-charts https://project-hami.github.io/HAMi/
隨后,使用下列指令獲取集群服務端版本
這里使用的是 v1.27.4 版本
kubectl version
在安裝過程中須根據集群服務端版本(上一條指令的結果)指定調度器鏡像版本,例如集群服務端版本為 v1.27.4,則可以使用如下指令進行安裝
helm install hami hami-charts/hami --set scheduler.kubeScheduler.imageTag=v1.27.4 -n kube-system
通過kubectl get pods指令看到 vgpu-device-plugin 與 vgpu-scheduler 兩個pod 狀態為Running 即為安裝成功
root@iZj6c5dnq07p1ic04ei9vwZ:~# kubectl get pods -n kube-system|grep hami
hami-device-plugin-b6mvj 2/2 Running 0 42s
hami-scheduler-7f5c5ff968-26kjc 2/2 Running 0 42s
自定義配置
官方文檔:HAMi-config-cn.md
你可以在安裝過程中,通過-set來修改以下的客制化參數,例如:
helm install vgpu vgpu-charts/vgpu --set devicePlugin.deviceMemoryScaling=5 ...
devicePlugin.deviceSplitCount: 整數類型,預設值是 10。GPU 的分割數,每一張GPU 都不能分配超過其配置數目的任務。若其配置為N的話,每個 GPU 上最多可以同時存在 N 個任務。devicePlugin.deviceMemoryScaling:浮點數類型,預設值是1。NVIDIA 裝置顯存使用比例,可以大于1(啟用虛擬顯存,實驗功能)。對于有 M顯存大小的 NVIDIA GPU,如果我們配置devicePlugin.deviceMemoryScaling參數為 S ,在部署了我們裝置插件的Kubenetes 集群中,這張 GPU 分出的 vGPU 將總共包含S * M顯存。devicePlugin.migStrategy:字符串類型,目前支持"none“與“mixed“兩種工作方式,前者忽略 MIG 設備,后者使用專門的資源名稱指定 MIG 設備,使用詳情請參考mix_example.yaml,默認為"none"devicePlugin.disablecorelimit:字符串類型,"true"為關閉算力限制,“false"為啟動算力限制,默認為"false”scheduler.defaultMem:整數類型,預設值為 5000,表示不配置顯存時使用的默認顯存大小,單位為 MBscheduler.defaultCores:整數類型(0-100),默認為0,表示默認為每個任務預留的百分比算力。若設置為 0,則代表任務可能會被分配到任一滿足顯存需求的 GPU 中,若設置為100,代表該任務獨享整張顯卡scheduler.defaultGPUNum:整數類型,默認為1,如果配置為0,則配置不會生效。當用戶在 pod 資源中沒有設置 nvidia.com/gpu 這個 key 時,webhook 會檢查 nvidia.com/gpumem、resource-mem-percentage、nvidia.com/gpucores 這三個 key 中的任何一個 key 有值,webhook 都會添加 nvidia.com/gpu 鍵和此默認值到 resources limit中。resourceName:字符串類型, 申請vgpu個數的資源名, 默認: “nvidia.com/gpu”resourceMem:字符串類型, 申請vgpu顯存大小資源名, 默認: “nvidia.com/gpumem”resourceMemPercentage:字符串類型,申請vgpu顯存比例資源名,默認: “nvidia.com/gpumem-percentage”resourceCores:字符串類型, 申請vgpu算力資源名, 默認: “nvidia.com/cores”resourcePriority:字符串類型,表示申請任務的任務優先級,默認: “nvidia.com/priority”
除此之外,容器中也有對應配置
GPU_CORE_UTILIZATION_POLICY:字符串類型,“default”, “force”, “disable” 代表容器算力限制策略, "default"為默認,"force"為強制限制算力,一般用于測試算力限制的功能,"disable"為忽略算力限制ACTIVE_OOM_KILLER:字符串類型,“true”, “false” 代表容器是否會因為超用顯存而被終止執行,"true"為會,"false"為不會
我們只是簡單 Demo 就不做任何配置直接部署即可。
4. 驗證
查看 Node GPU 資源
類似于上一篇分享的 TimeSlicing 方案,在安裝之后,Node 上可見的 GPU 資源也是增加了。
環境中只有一個物理 GPU,但是 HAMi 默認會擴容 10 倍,理論上現在 Node 上能查看到 1*10 = 10 個 GPU。
默認參數就是切分為 10 個,可以設置。
$ kubectl get node xxx -oyaml|grep capacity -A 7capacity:cpu: "4"ephemeral-storage: 206043828Kihugepages-1Gi: "0"hugepages-2Mi: "0"memory: 15349120Kinvidia.com/gpu: "10"pods: "110"
驗證顯存和算力限制
使用以下 yaml 來創建 Pod,注意 resources.limit 除了原有的 nvidia.com/gpu 之外還新增了 nvidia.com/gpumem 和 nvidia.com/gpucores,用來指定顯存大小和算力大小。
- nvidia.com/gpu:請求的 vgpu 數量,例如 1
- nvidia.com/gpumem :請求的顯存數量,例如 3000M
- nvidia.com/gpumem-percentage:顯存百分百,例如 50 則是請求 50%顯存
- nvidia.com/priority: 優先級,0 為高,1 為底,默認為 1。
- 對于高優先級任務,如果它們與其他高優先級任務共享 GPU 節點,則其資源利用率不會受到
resourceCores的限制。換句話說,如果只有高優先級任務占用 GPU 節點,那么它們可以利用節點上所有可用的資源。 - 對于低優先級任務,如果它們是唯一占用 GPU 的任務,則其資源利用率也不會受到
resourceCores的限制。這意味著如果沒有其他任務與低優先級任務共享 GPU,那么它們可以利用節點上所有可用的資源。
- 對于高優先級任務,如果它們與其他高優先級任務共享 GPU 節點,則其資源利用率不會受到
完整 gpu-test.yaml 內容如下:
apiVersion: v1
kind: Pod
metadata:name: gpu-pod
spec:containers:- name: ubuntu-containerimage: ubuntu:18.04command: ["bash", "-c", "sleep 86400"]resources:limits:nvidia.com/gpu: 1 # 請求1個vGPUsnvidia.com/gpumem: 3000 # 每個vGPU申請3000m顯存 (可選,整數類型)nvidia.com/gpucores: 30 # 每個vGPU的算力為30%實際顯卡的算力 (可選,整數類型)
Pod 能夠正常啟動
root@iZj6c5dnq07p1ic04ei9vwZ:~# kubectl get po
NAME READY STATUS RESTARTS AGE
gpu-pod 1/1 Running 0 48s
進入 Pod執行 nvidia-smi 命令,查看 GPU 信息,可以看到展示的限制就是 Resource 中申請的 3000M。
root@iZj6c5dnq07p1ic04ei9vwZ:~# kubectl exec -it gpu-pod -- bash
root@gpu-pod:/# nvidia-smi
[HAMI-core Msg(16:139711087368000:libvgpu.c:836)]: Initializing.....
Mon Apr 29 06:22:16 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.14 Driver Version: 550.54.14 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 On | 00000000:00:07.0 Off | 0 |
| N/A 33C P8 15W / 70W | 0MiB / 3000MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------++-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
[HAMI-core Msg(16:139711087368000:multiprocess_memory_limit.c:434)]: Calling exit handler 16
根據最后的日志就是 HAMi 的 CUDA 驅動打印的。
[HAMI-core Msg(16:139711087368000:multiprocess_memory_limit.c:434)]: Calling exit handler 16
**【Kubernetes 系列】**持續更新中,搜索公眾號【探索云原生】訂閱,文章。

5. 小結
本文主要分享了開源 vGPU 方案 HAMi,并通過簡單 Demo 進行了驗證。
為什么需要 GPU 共享、切分?
在 k8s 中使用默認 device plugin 時,GPU 資源和物理 GPU 是一一對應的,導致一個物理 GPU 被一個 Pod 申請后,其他 Pod 就無法使用了。
為了提高資源利用率,因此我們需要 GPU 共享、切分等方案。
HAMi 大致實現原理
通過替換容器中的 libvgpu.so 庫,實現 CUDA API 攔截,最終實現對 GPU core 和 memory 的隔離和限制。
更加詳細的原理分析,可以期待后續文章~
最后在貼一下相關文章,推薦閱讀:
-
GPU 環境搭建指南:如何在裸機、Docker、K8s 等環境中使用 GPU
-
GPU 環境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 環境搭建
-
Kubernetes教程(二一)—自定義資源支持:K8s Device Plugin 從原理到實現
-
Kubernetes教程(二二)—在 K8S 中創建 Pod 是如何使用到 GPU 的:device plugin&nvidia-container-toolkit 源碼分析
-
一文搞懂 GPU 共享方案: NVIDIA Time Slicing

)











)

的k倍加到另一行(列),行列式的值不變)



