誤差與過擬合
?我們將學習器對樣本的實際預測結果與樣本的真實值之間的差異稱為:誤差(error)。
誤差定義:
①在訓練集上的誤差稱為訓練誤差(training error)或經驗誤差(empirical error)。
②在測試集上的誤差稱為測試誤差(test error)。
③學習器在所有新樣本上的誤差稱為泛化誤差(generalization error)
????????當學習器把訓練集學得“太好”的時候,即把一些訓練樣本的自身特點當做了普遍特征;同時也有學習能力不足的情況,即訓練集的基本特征都沒有學習出來。
①學習能力過強,以至于把訓練樣本所包含的不太一般的特性都學到了,稱為:過擬合(overfitting)。
②學習能太差,訓練樣本的一般性質尚未學好,稱為:欠擬合(underfitting)。
訓練集測試集劃分
1.留出法
????????將數據集D劃分為兩個互斥的集合,一個作為訓練集S,一個作為測試集T,滿足D=S∪T且S∩T=?,常見的劃分為:大約2/3-4/5的樣本用作訓練,剩下的用作測試。
2.交叉驗證法
????????將數據集D劃分為k個大小相同的互斥子集,滿足D=D1∪D2∪...∪Dk,Di∩Dj=?(i≠j),同樣地盡可能保持數據分布的一致性,即采用分層抽樣的方法獲得這些子集。
性能度量
1.均方誤差
?在回歸任務中,即預測連續值的問題,最常用的性能度量是“均方誤差”(mean squared error),很多的經典算法都是采用了MSE作為評價函數
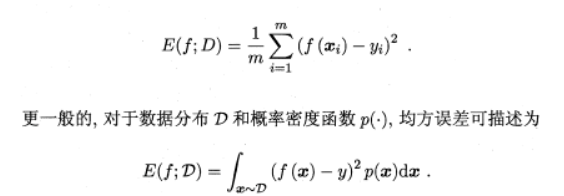
2.P/R/F1
對于二分類問題,分類結果混淆矩陣與查準/查全率定義如下:

????????除了混淆矩陣,一般還會畫“P-R曲線”
????????P-R曲線定義如下:根據學習器的預測結果(一般為一個實值或概率)對測試樣本進行排序,將最可能是“正例”的樣本排在前面,最不可能是“正例”的排在后面,按此順序逐個把樣本作為“正例”進行預測,每次計算出當前的P值和R值,如下圖所示:
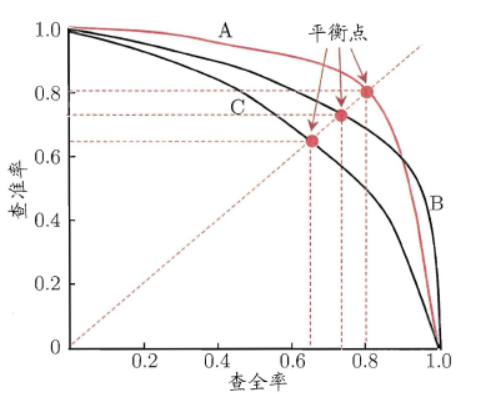
? ①若一個學習器A的P-R曲線被另一個學習器B的P-R曲線完全包住,則稱:B的性能優于A。
? ②若A和B的曲線發生了交叉,則誰的曲線下的面積大,誰的性能更優。
? ③但一般來說,曲線下的面積是很難進行估算的,所以衍生出了“平衡點”(Break-Event Point,簡稱BEP),即當P=R時的取值,平衡點的取值越高,性能更優。
????????P和R指標有時會出現矛盾的情況,這樣就需要綜合考慮他們,最常見的方法就是F-Measure,又稱F-Score。F-Measure是P和R的加權調和平均,即:
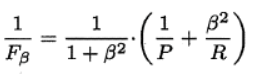
特別地,當β=1時,也就是常見的F1度量,是P和R的調和平均,當F1較高時,模型的性能越好。
3.ROC/AUC
????????學習器對測試樣本的評估結果一般為一個實值或概率,設定一個閾值,大于閾值為正例,小于閾值為負例,因此這個實值的好壞直接決定了學習器的泛化性能,若將這些實值排序,則排序的好壞決定了學習器的性能高低。
????????ROC曲線正是從這個角度出發來研究學習器的泛化性能,ROC曲線與P-R曲線十分類似,都是按照排序的順序逐一按照正例預測,不同的是ROC曲線以“真正例率”(True Positive Rate,簡稱TPR)為橫軸,縱軸為“假正例率”(False Positive Rate,簡稱FPR),ROC偏重研究基于測試樣本評估值的排序好壞。
????????進行模型的性能比較時
①若一個學習器A的ROC曲線被另一個學習器B的ROC曲線完全包住,則稱B的性能優于A。
②若A和B的曲線發生了交叉,則誰的曲線下的面積大,誰的性能更優。
????????ROC曲線下的面積定義為AUC(Area Uder ROC Curve),不同于P-R的是,這里的AUC是可估算的,即AOC曲線下每一個小矩形的面積之和。易知:AUC越大,證明排序的質量越好,AUC為1時,證明所有正例排在了負例的前面,AUC為0時,所有的負例排在了正例的前面。
比較檢驗
1 假設檢驗
????????“假設”指的是對樣本總體的分布或已知分布中某個參數值的一種猜想,例如:假設總體服從泊松分布,或假設正態總體的期望u=u0。
2.交叉驗證T檢驗
? ? ? ? 比較兩個學習率的性能。
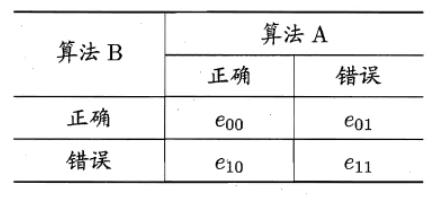
3.McNemar檢驗
????????MaNemar主要用于二分類問題,與成對t檢驗一樣也是用于比較兩個學習器的性能大小。主要思想是:若兩學習器的性能相同,則A預測正確B預測錯誤數應等于B預測錯誤A預測正確數,即e01=e10,且|e01-e10|服從N(1,e01+e10)分布。
偏差與方差
①偏差指的是預測的期望值與真實值的偏差
②方差則是每一次預測值與預測值得期望之間的差均方。
????????實際上,偏差體現了學習器預測的準確度,而方差體現了學習器預測的穩定性。通過對泛化誤差的進行分解,可以得到:
期望泛化誤差=方差+偏差
偏差刻畫學習器的擬合能力
方差體現學習器的穩定性
????????在欠擬合時,偏差主導泛化誤差,而訓練到一定程度后,偏差越來越小,方差主導了泛化誤差。因此訓練也不要貪杯,適度輒止。
參考: https://www.heywhale.com/mw/project/5e4f89fb0e2b66002c1f6468






)

的k倍加到另一行(列),行列式的值不變)









)
