在語音合成與語音編輯領域,一個長期存在的挑戰是如何在修改語音內容的同時,保持原始語音的自然性、連貫性和說話人特征。近日,一款名為 PlayDiffusion 的新型 AI 語音修復模型應運而生,成功實現了這一目標。
PlayDiffusion 是一個具備細粒度語音編輯能力 的語音修復模型,能夠在不破壞語音整體結構的前提下,實現對特定詞語或句子片段的精準修改。更重要的是,修改后的語音能夠無縫銜接原語音 ,聽感自然流暢,幾乎無法察覺修改痕跡。
核心功能亮點
1、精準語音修改
支持對語音中單個詞或短語進行修改,例如將一句話中的“小明”替換為“小紅”,而不影響其余部分的語音風格和語調。
2、上下文保留機制
在編輯過程中,系統會保留語音的上下文信息,確保修改區域與周圍語音之間實現平滑過渡。
3、說話人特征一致性
修改后的語音在音色、語速、語調等方面與原始語音高度一致,避免了傳統語音編輯中常見的“換聲”問題。
4、廣泛適用性
特別適用于需要頻繁修改語音內容的場景,如語音播報、有聲讀物制作、廣告配音、視頻解說 等領域。
工作原理詳解
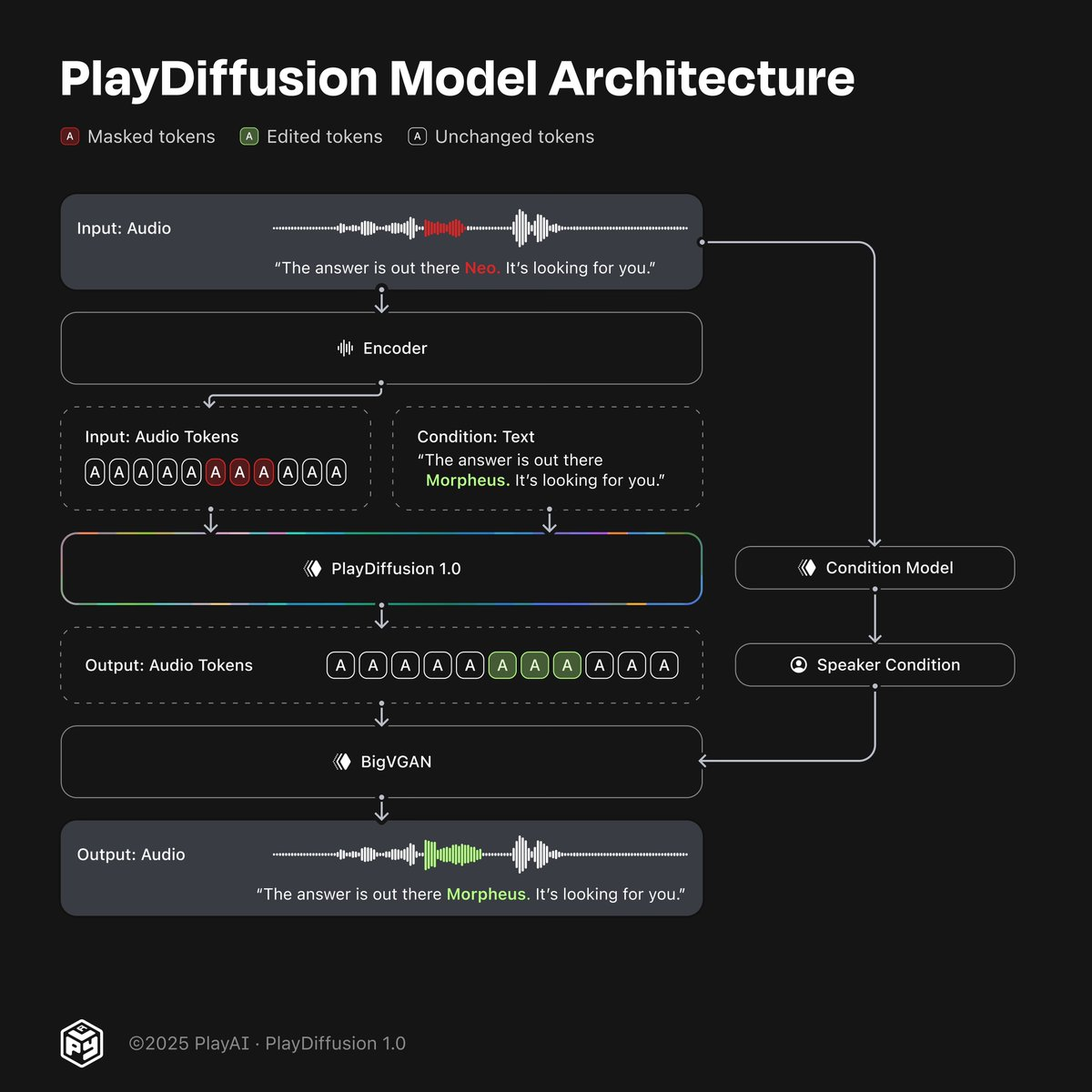
PlayDiffusion 的核心在于其基于擴散模型的非自回歸編輯架構 ,具體流程如下:
1、音頻編碼
首先,輸入的語音波形被編碼為一個離散空間中的 token 序列,形成一種更緊湊的表示形式。這一過程既適用于真實錄制的語音,也適用于由 Text-to-Speech(TTS)模型生成的語音。
2、局部遮罩處理
當用戶希望修改某段語音時,系統會自動遮蓋該區域的音頻 token,準備進行編輯。
3、條件擴散去噪
一個基于更新文本的條件擴散模型 被用于對遮罩區域進行去噪處理。在這個過程中,系統利用周圍的上下文信息來生成新的語音 token,從而保證語音的連貫性和說話人特征的一致性。
4、語音解碼輸出
編輯完成的 token 序列通過 BigVGAN 解碼器轉換回高質量的語音波形,最終輸出編輯后的語音。
借助非自回歸擴散模型 的強大建模能力,PlayDiffusion 能夠在語音編輯邊界處保持極佳的上下文一致性,顯著提升了語音編輯的質量和可控性。
PlayDiffusion 的推出標志著語音編輯技術邁入了一個新階段——從“只能重新錄音”到“精細編輯、無縫融合”。它不僅是語音處理領域的一項重大突破,更為 AI 驅動的內容創作開辟了全新的可能性。
github:https://github.com/playht/PlayDiffusion
)











)

的k倍加到另一行(列),行列式的值不變)




