一、傳統BI的決策滯后陷阱
標準化BI工具的核心短板在于被動響應:
- 數據延遲:T+1甚至T+7的數據聚合周期,無法捕捉實時市場波動
- 靜態規則:依賴人工設定庫存閾值/補貨公式,難以應對突發流量
- 經驗依賴:運營人員基于歷史報表推測趨勢,忽略隱性關聯因子
某服飾電商大促期間,因未及時感知某明星街拍帶貨效應,庫存預測偏差率達37%,直接損失超千萬
二、私有化AI決策引擎的定制化訓練路徑
我們為某美妝品牌構建的需求預測大腦,通過三階段實現決策升級:
? 階段1:數據融合層建設
python
# 構建時空特征引擎
feature_engine = Pipeline([
('temporal_features', TemporalTransformer()), # 提取節假日/促銷周期特征
('spatial_features', GeoDemographicEncoder()), # 融合區域經濟/氣候數據
('event_crawler', SocialMediaScraper()) # 實時爬取社交媒體聲量
])
打破ERP、CRM、輿情數據的孤島,融合15維動態特征因子
? 階段2:自適應模型訓練
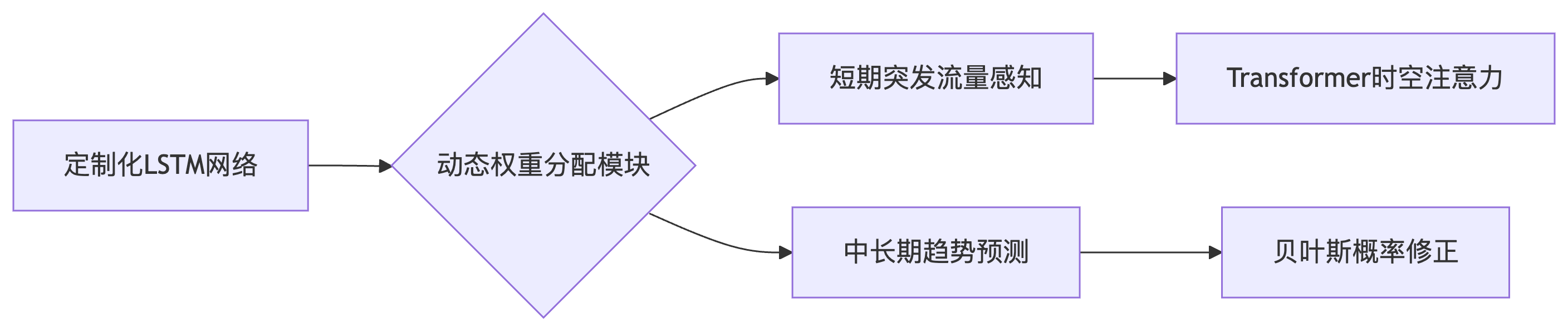
- 通過遷移學習復用行業基礎模型
- 注入企業特有經營規則約束(如:最小采購量/物流時效)
- 動態調整特征權重(促銷期價格敏感度提升300%)
? 階段3:閉環決策系統
text
實時數據流 → 需求預測引擎 → 自動生成采購單 → 銷售驗證 → 模型自優化
決策周期從7天壓縮至2小時,預測準確率提升至92%
三、決策層級對比:被動報表 vs 主動大腦
| 維度 | 標準化BI工具 | 私有化AI決策引擎 |
| 決策時效 | T+1~7天 | 近實時(<1小時) |
| 數據維度 | 結構化歷史數據 | 多源實時動態數據 |
| 響應機制 | 人工規則配置 | 自動策略生成 |
| 迭代能力 | 手動更新模型 | 在線自主學習 |
| 場景覆蓋 | 通用分析場景 | 企業定制化場景 |
四、決策鏈重構實戰:從預測到執行
某母嬰品牌接入決策引擎后:
- 需求預測層:通過輿情監控提前2周發現“待產包”新趨勢
- 智能決策層:自動生成分倉補貨方案+營銷活動建議
- 執行反饋層:根據首日銷售數據動態調整生產計劃
結果:庫存周轉率提升40%,促銷ROI增長25%,滯銷品占比降至3%以下
結語:讓決策權回歸業務前線
當AI決策大腦深度嵌入業務系統,運營人員不再是報表的被動接收者:
- 店長實時獲取分倉調貨建議
- 采購經理看到動態優化的供應商組合
- 營銷總監掌握品效聯動的資源分配方案
未來電商的競爭,本質是決策速度與精度的競爭。從滯后報表到先知大腦,重構的不僅是技術鏈條,更是企業核心決策基因。



)


-2 輸入一個數,統計這個數二進制中1的個數)




)




)


