基于pca的人臉識別
- 引言:pca
- 1.pca是什么
- 2.PCA算法的基本步驟
- 實例:人臉識別
- 1.實驗目的
- 2.實現步驟
- 3.代碼實現
- 4.實驗結果
- 5.實驗總結
引言:pca
1.pca是什么
pca是一種統計方法,它可以通過正交變換將一組可能相關的變量轉換成一組線性不相關的變量,這組新的變量被稱為主成分。PCA常用于高維數據的降維,通過保留最重要的幾個主成分來簡化數據集,同時盡可能保留原始數據的信息。
2.PCA算法的基本步驟
- 數據標準化:對原始數據進行預處理,使得每個特征的均值為0,標準差為1。這一步是為了消除不同量綱對數據分析的影響。
- 構建協方差矩陣:計算數據的協方差矩陣,協方差矩陣能夠反映不同特征之間的相關性。
- 計算協方差矩陣的特征值和特征向量:特征值和特征向量能夠揭示數據的內在結構。特征值越大,對應的特征向量在數據集中的重要性越高。
- 選擇主成分:根據特征值的大小,選擇前k個最大的特征值對應的特征向量作為主成分。通常會選擇累計貢獻率達到一定比例(如85%)的特征向量。
- 形成特征向量矩陣:將選定的特征向量組成一個矩陣,這個矩陣將用于將原始數據轉換到新的特征空間。
- 數據轉換:使用特征向量矩陣將原始數據轉換到新的特征空間,得到降維后的數據。
實例:人臉識別
1.實驗目的
- 理解PCA原理:通過實踐掌握主成分分析(PCA)算法的核心思想及其在降維中的應用
- 應用PCA處理圖像數據:學習如何將PCA應用于高維圖像數據,特別是人臉識別領域
- 探索特征提取:了解PCA如何提取圖像的主要特征(特征臉)及其在人臉表示中的作用
- 評估降維效果:通過圖像重建實驗,直觀理解不同數量主成分對圖像質量的影響
2.實現步驟
- 數據準備
? 加載ORL人臉數據集(包含40個人的400張人臉圖像)
? 將每張112×92像素的灰度圖像轉換為10304維的向量
? 構建數據矩陣(每行代表一張圖像) - 數據預處理
? 計算并減去平均臉(數據集中所有圖像的平均)
? 中心化數據(使數據均值為0) - PCA分析
? 使用sklearn的PCA進行主成分分析
? 提取前50個主成分
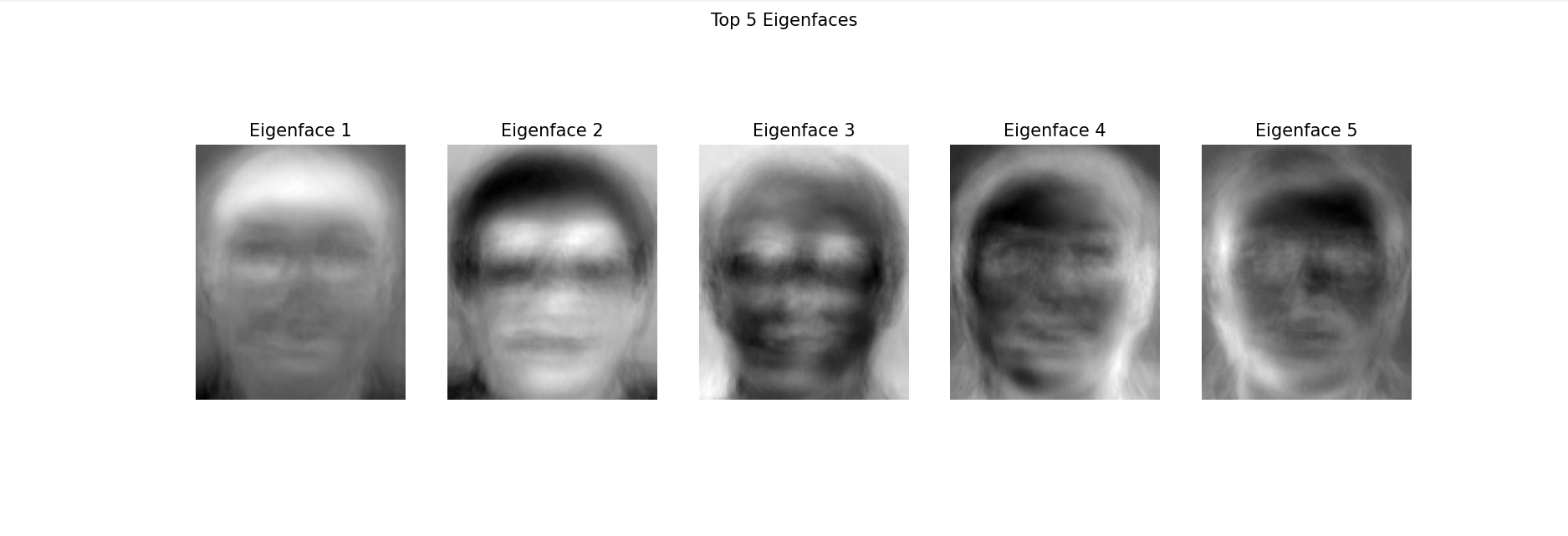
? 可視化前5個特征臉(主成分) - 方差分析
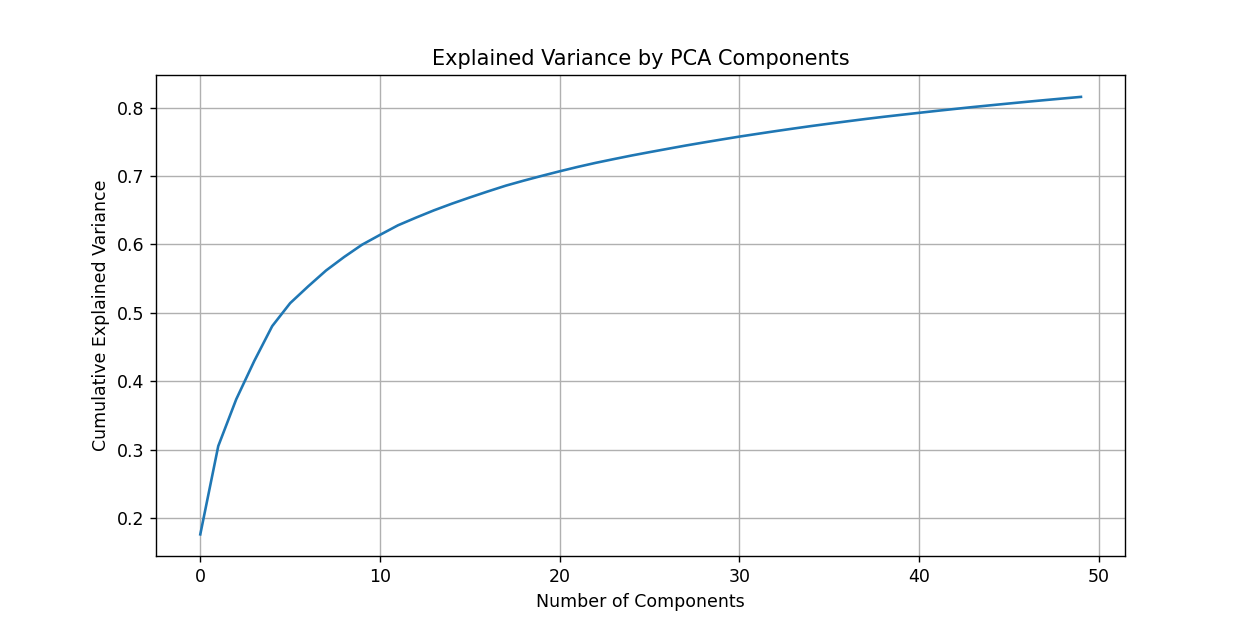
? 繪制累計解釋方差圖
? 觀察不同數量主成分對數據方差的解釋程度 - 圖像重建
? 選擇樣本圖像進行重建
? 分別使用10、30、50個主成分重建圖像
? 對比重建圖像與原始圖像的質量差異 - 結果分析
? 觀察特征臉的特點
? 分析主成分數量對重建質量的影響
? 評估PCA在圖像壓縮和特征提取中的效果
3.代碼實現
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA# 1. 加載ORL人臉數據集
def load_orl_faces(data_path, num_persons=40, num_images=10, img_size=(112, 92)):"""加載ORL人臉數據集參數:data_path: 數據集路徑num_persons: 人數(默認40)num_images: 每人圖像數(默認10)img_size: 圖像尺寸(默認112×92)返回:X: 圖像矩陣(每行一個圖像)image_shape: 圖像原始形狀"""total_images = num_persons * num_imagesX = np.zeros((total_images, img_size[0] * img_size[1]))image_count = 0for person in range(1, num_persons + 1):person_dir = os.path.join(data_path, f's{person}')for img_num in range(1, num_images + 1):img_path = os.path.join(person_dir, f'{img_num}.pgm')if os.path.exists(img_path):try:img = Image.open(img_path).convert('L')img_array = np.array(img).flatten()X[image_count] = img_arrayimage_count += 1except Exception as e:print(f"處理文件 {img_path} 時出錯: {str(e)}")else:print(f"警告: 未找到文件 {img_path}")# 只保留成功加載的圖像X = X[:image_count]return X, img_size# 2. PCA降維與可視化
def pca_analysis(X, image_shape, n_components=50):"""PCA分析與人臉重建參數:X: 圖像矩陣image_shape: 圖像原始形狀n_components: 保留的主成分數量"""# 數據標準化mean_face = np.mean(X, axis=0)X_centered = X - mean_face# 使用sklearn的PCApca = PCA(n_components=n_components)X_pca = pca.fit_transform(X_centered)# 可視化前幾個特征臉plt.figure(figsize=(15, 5))for i in range(5):eigenface = pca.components_[i].reshape(image_shape)plt.subplot(1, 5, i+1)plt.imshow(eigenface, cmap='gray')plt.title(f'Eigenface {i+1}')plt.axis('off')plt.suptitle('Top 5 Eigenfaces')plt.show()# 顯示方差解釋率plt.figure(figsize=(10, 5))plt.plot(np.cumsum(pca.explained_variance_ratio_))plt.xlabel('Number of Components')plt.ylabel('Cumulative Explained Variance')plt.title('Explained Variance by PCA Components')plt.grid()plt.show()return pca, mean_face, X_pca# 3. 圖像重建與對比
def reconstruct_and_compare(pca, mean_face, X_pca, image_shape, sample_indices=[0, 10, 20]):"""重建圖像并與原始圖像對比參數:pca: PCA模型mean_face: 平均臉X_pca: PCA降維后的數據image_shape: 圖像形狀sample_indices: 要顯示的樣本索引"""plt.figure(figsize=(15, 5 * len(sample_indices)))for i, idx in enumerate(sample_indices):# 原始圖像original_img = mean_face + X_pca[idx] @ pca.components_# 使用不同數量的主成分重建plt.subplot(len(sample_indices), 4, i*4 + 1)plt.imshow(original_img.reshape(image_shape), cmap='gray')plt.title(f'Original Image {idx}')plt.axis('off')for j, n in enumerate([10, 30, 50]):# 使用前n個主成分重建reconstructed = mean_face + X_pca[idx, :n] @ pca.components_[:n]plt.subplot(len(sample_indices), 4, i*4 + j + 2)plt.imshow(reconstructed.reshape(image_shape), cmap='gray')plt.title(f'{n} Components')plt.axis('off')plt.suptitle('Image Reconstruction with Different Numbers of PCA Components')plt.tight_layout()plt.show()# 主程序
def main():# 數據集路徑 - 替換為你的實際路徑dataset_path = r'C:\Users\62755\Downloads\ORL_Faces'# 1. 加載數據X, image_shape = load_orl_faces(dataset_path)print(f"成功加載 {X.shape[0]} 張人臉圖像,每張圖像維度 {X.shape[1]}")# 2. PCA分析pca, mean_face, X_pca = pca_analysis(X, image_shape, n_components=50)# 3. 重建與對比reconstruct_and_compare(pca, mean_face, X_pca, image_shape)if __name__ == "__main__":main()
4.實驗結果
圖像重建對比圖:

累計解釋方差圖:
5.實驗總結
通過本次基于PCA的人臉識別實驗,我深入理解了主成分分析的核心原理及其在實際問題中的應用價值。實驗過程中,我不僅掌握了如何將高維圖像數據轉化為適合PCA處理的矩陣形式,還學會了數據標準化和中心化的預處理方法。通過可視化特征臉,我直觀認識到PCA如何自動提取數據的主要變化模式,這些特征臉實際上構成了人臉圖像的基礎成分。






)

)

)






的記錄)

)