目錄
- 效果一覽
- 基本介紹
- 程序設計
- 參考資料
效果一覽

基本介紹
1.CPO-BP+NSGA,冠豪豬優化BP神經網絡+粒子群算法!(Matlab完整源碼和數據),冠豪豬算法優化BP神經網絡的權值和閾值,運行環境Matlab2020b及以上。
多目標優化是指在優化問題中同時考慮多個目標的優化過程。在多目標優化中,通常存在多個沖突的目標,即改善一個目標可能會導致另一個目標的惡化。因此,多目標優化的目標是找到一組解,這組解在多個目標下都是最優的,而不是僅僅優化單一目標。冠豪豬優化算法(Crested Porcupine Optimizer, CPO)是一種新型的元啟發式算法,由Abdel-Basset等人于2024年提出。該算法模擬了冠豪豬的防御行為,包括視覺、聲音、氣味和物理攻擊四種策略,用于解決復雜的優化問題。
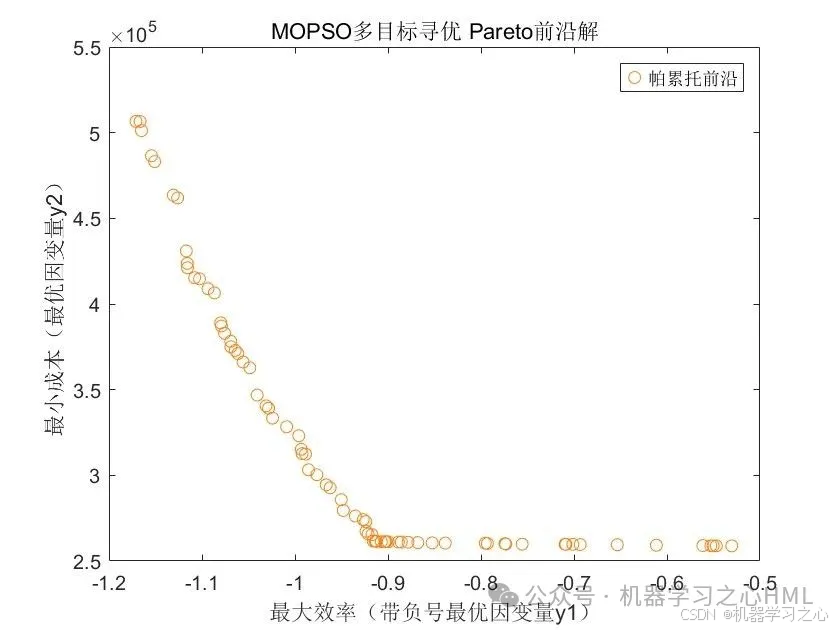
2.先通過CPO-BP封裝因變量(穩態下的效率、壓縮機經濟成本 )與自變量(轉速、余隙容積全關、用戶排氣量、冷卻水流量)代理模型,再通過MOPSO尋找極值(穩態下的效率極大;壓縮機經濟成本極小),并給出對應的轉速、余隙容積全關、用戶排氣量、冷卻水流量Pareto解集。
3.data為數據集,4個輸入特征,2個輸出變量,NSGA算法尋極值,求出極值時(max y1; min y2)的自變量x1,x2,x3,x4。
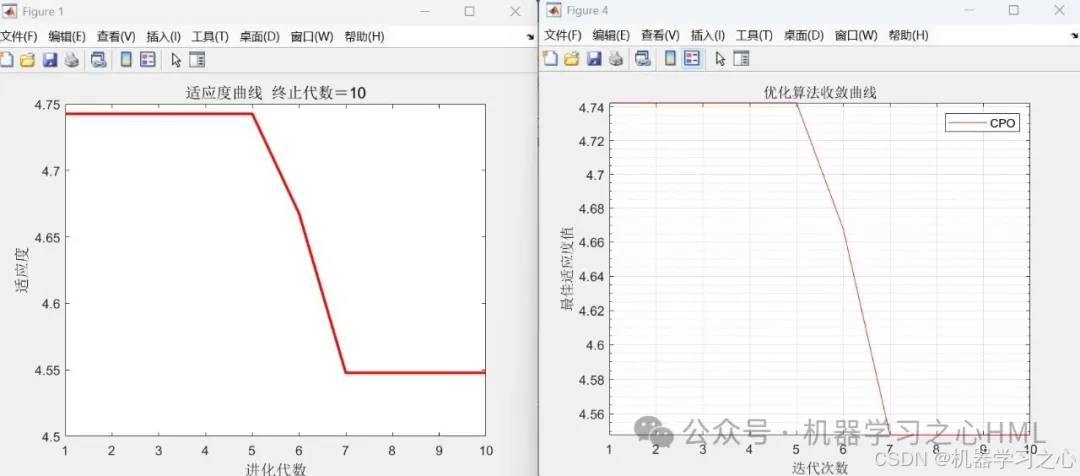
4.main1.m為CPO-BP神經網絡主程序文件、main2.m為MOPSO多目標優化算法主程序文件,依次運行即可,其余為函數文件,無需運行。
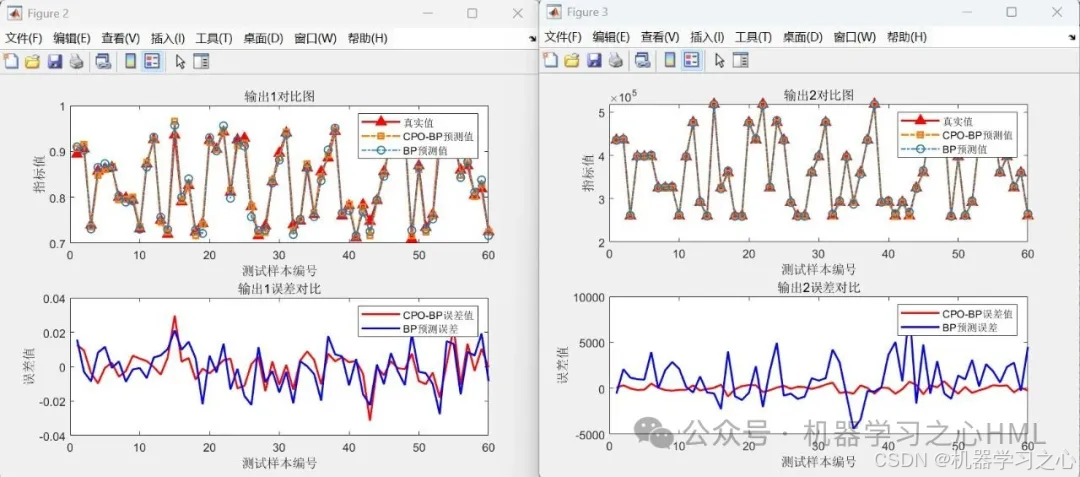
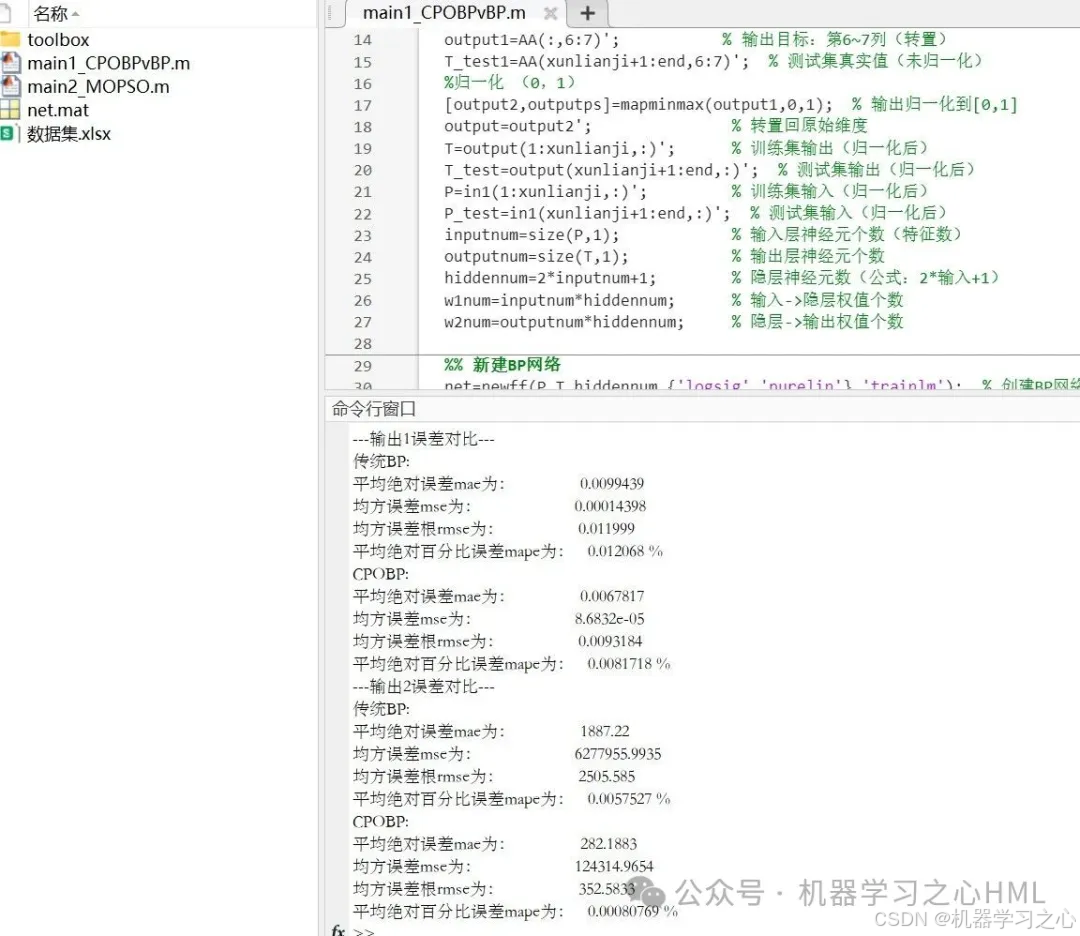
5.命令窗口輸出MAE、MAPE、MSE、RMSE等評價指標,輸出預測對比圖、誤差分析圖、多目標優化算法求解Pareto解集圖,可在下載區獲取數據和程序內容。
6.適合工藝參數優化、工程設計優化等最優特征組合領域。
代碼功能概述
main1_CPOBPvBP.m
核心功能
使用冠豪豬優化算法(CPO)優化BP神經網絡的初始權值和閾值。
訓練優化后的CPO-BP神經網絡,并與傳統BP網絡對比預測性能。
預測壓縮機性能指標(效率、成本)并可視化結果。
算法步驟
a. 數據預處理
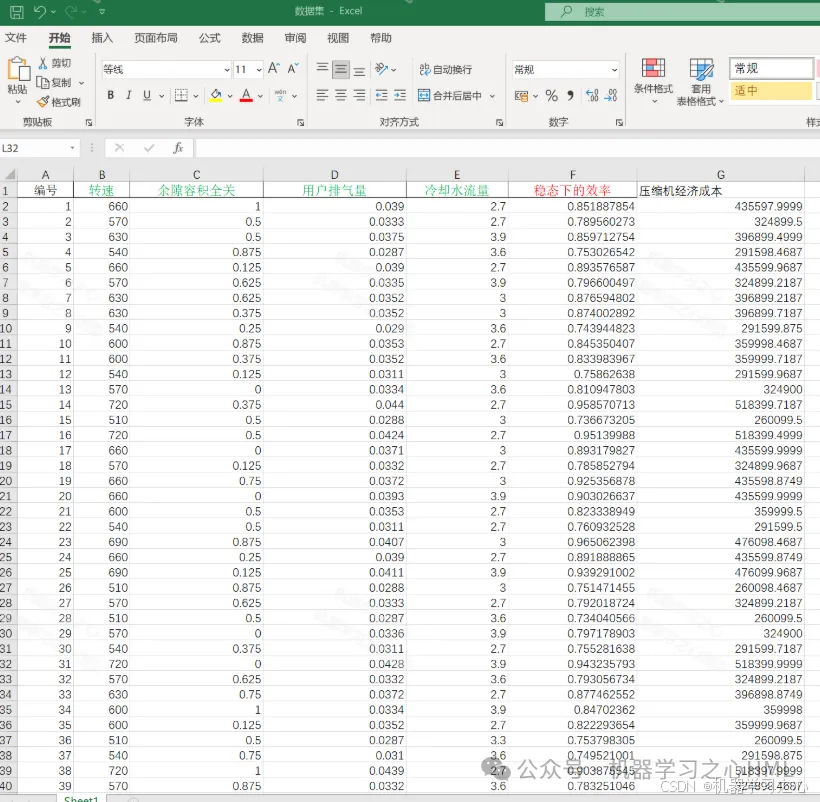
讀取數據集(數據集.xlsx),劃分訓練集(300樣本)和測試集。
輸入特征(4列)和輸出目標(2列)歸一化到[0,1]區間。
b. BP網絡構建
結構:輸入層(4節點)、隱層(2*4+1=9節點,logsig)、輸出層(2節點,purelin)。
訓練算法:Levenberg-Marquardt(trainlm)。
c. CPO優化BP參數
優化目標:最小化網絡預測誤差。
優化變量:所有權值+閾值(維度=65)。
d. 訓練與預測
用CPO優化后的參數初始化網絡,訓練100次。
預測測試集并反歸一化得到實際值。
e. 對比實驗
訓練傳統BP網絡(相同結構),對比預測誤差。
f. 結果分析
繪制真實值、預測值及誤差對比圖。
計算MAE、MSE、RMSE、MAPE等誤差指標。
關鍵參數
CPO:種群大小=10,迭代次數=10,變量范圍=[-3,3]。
BP:最大訓練次數=1000,學習率=0.1,目標誤差=0.00001。
模型原理
CPO算法:模擬冠豪豬防御行為(翻滾、逃離、跟隨)的啟發式算法,通過種群協作搜索全局最優解。
BP神經網絡:前饋網絡通過誤差反向傳播調整權值,CPO優化解決其易陷入局部最優的問題。
main2_MOPSO.m
核心功能
使用多目標粒子群算法(MOPSO)優化壓縮機設計參數。
尋找同時最大化效率和最小化成本的帕累托最優解集。
算法步驟
a. 目標函數定義
效率目標:XL = CPOBP_slover_XL(x1,x2,x3,x4)(最大化,取負)。
成本目標:CB = CPOBP_slover_CB(x1,x2,x3,x4)(最小化)。
b. MOPSO參數設置
變量:轉速、余隙容積、排氣量、水流量(4維)。
范圍:轉速∈[510,720],余隙容積∈[0.125,1]等。
c. MOPSO運行
初始化粒子群(10個粒子),迭代50次。
更新粒子位置/速度,維護外部存檔(100個帕累托解)。
d. 結果分析
繪制帕累托前沿(效率vs成本)。
計算Spacing指標評估解集分布均勻性。
輸出最優解參數(如轉速、余隙容積)。
關鍵參數
種群大小=10,存檔大小=100,迭代次數=50。
變量范圍:見步驟2b。
模型原理
粒子位置更新:v_i = wv_i + c1r1*(pbest_i - x_i) + c2r2(gbest - x_i)。
非支配排序篩選帕累托解,存檔機制保留最優解集。
MOPSO算法:擴展粒子群算法(PSO)至多目標優化:
目標函數模型:基于main1訓練的CPO-BP網絡預測壓縮機性能。
兩段代碼的聯系
依賴關系
main2中的目標函數CPOBP_slover_XL/CB調用main1訓練的CPO-BP模型預測壓縮機性能。
main1提供優化后的神經網絡,main2將其用于多目標優化。
整體流程
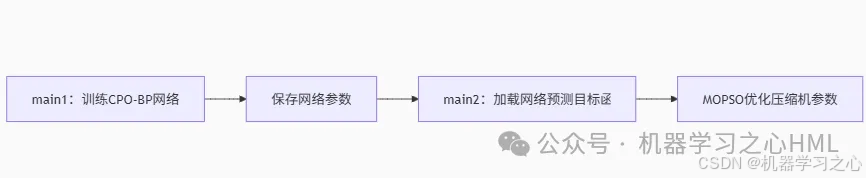
數據集
程序設計
- 完整程序和數據獲取方式:私信博主回復CPO-BP+MOPSO,冠豪豬優化BP神經網絡+多目標粒子群算法!(Matlab完整源碼和數據)。
.rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
nVar = 4; % 優化變量個數(4個設計變量)
VarMin = [510,0.125,0.0118,2.7]; % 變量下限:[轉速, 余隙容積, 用戶排氣量, 水流量]
VarMax = [720,1,0.044,3.9]; % 變量上限
name = 'MOPSO多目標尋優'; % 問題名稱(用于結果展示)
dynamic = 0; % 動態優化標志(0表示靜態優化)
numOfObj = 2; % 目標函數個數(2個目標:效率、成本)
%% 配置多目標問題結構體
MultiObj.nVar = nVar; % 變量維度
MultiObj.var_min = VarMin; % 變量下限
MultiObj.var_max = VarMax; % 變量上限
MultiObj.fun = CostFunction; % 目標函數句柄
MultiObj.dynamic = dynamic; % 動態優化標志
MultiObj.numOfObj = numOfObj; % 目標函數個數
MultiObj.name = name; % 問題名稱
MultiObjFnc = MultiObj.name; % 用于標題顯示的字符串
%% MOPSO算法參數設置
params.Np = 10; % 種群大小(粒子數量)
params.Nr = 100; % 外部存檔大小(存儲帕累托最優解的最大數量)
params.maxgen = 50; % 最大迭代次數(代數較少,實際應用需增加)
%% 運行MOPSO算法
[REP, POS_fit] = MOPSO(params, MultiObj); % 調用MOPSO函數,返回存檔解集和粒子適應度params.C1 = 2; % 個體學習因子:粒子向自身歷史最優位置移動的權重params.C2 = 2; % 社會學習因子:粒子向群體最優位置移動的權重params.ngrid = 20; % 網格劃分數量:用于存檔解集的空間劃分params.maxvel = 5; % 最大速度百分比:速度限制為變量范圍的5%params.u_mut = 0.5; % 均勻變異比例:種群中部分粒子進行隨機重置的比例%% 提取參數和問題定義Np = params.Np; % 種群大小(粒子數量)Nr = params.Nr; % 外部存檔最大容量(帕累托解數量)maxgen = params.maxgen; % 最大迭代次數W = params.W; % 慣性權重C1 = params.C1; % 個體學習因子C2 = params.C2; % 社會學習因子ngrid = params.ngrid; % 網格劃分數maxvel = params.maxvel; % 最大速度限制(百分比)u_mut = params.u_mut; % 均勻變異比例fun = MultiObj.fun; % 目標函數句柄(需最小化)nVar = MultiObj.nVar; % 變量維度(設計變量數量)var_min = MultiObj.var_min(:); % 變量下限(列向量)var_max = MultiObj.var_max(:); % 變量上限(列向量)%% --------------------- 種群初始化 ---------------------% 生成初始粒子位置:在變量范圍內隨機分布POS = repmat((var_max-var_min)', Np, 1) .* rand(Np, nVar) + repmat(var_min', Np, 1);VEL = zeros(Np, nVar); % 初始速度設為0% 計算初始種群的適應度(目標函數值)for i = 1:NpPOS_fit(i,:) = fun(POS(i,:)); % 每個粒子的目標函數值存儲為行向量end% 檢查目標函數返回值是否與粒子數量一致(避免函數編寫錯誤)if size(POS,1) ~= size(POS_fit,1)warning('目標函數返回的適應度數量與粒子數不匹配,請檢查函數實現');end%% --------------------- 存檔和個體歷史最優初始化 ---------------------PBEST = POS; % 個體歷史最優位置初始化為當前位置PBEST_fit = POS_fit; % 個體歷史最優適應度% 檢查支配關系:標記被其他粒子支配的個體(1表示被支配,0表示非支配)DOMINATED = checkDomination(POS_fit);REP.pos = POS(~DOMINATED,:); % 初始存檔:存儲所有非支配解REP.pos_fit = POS_fit(~DOMINATED,:); % 存檔對應的適應度REP = updateGrid(REP, ngrid); % 初始化網格劃分(用于存檔管理)% 計算實際最大速度:將百分比轉換為變量范圍的絕對數值maxvel = (var_max - var_min) .* maxvel ./ 100;gen = 1;%% --------------------- 可視化初始化 ---------------------h_fig = figure; % 創建圖形窗口h_par = plot(POS_fit(:,1), POS_fit(:,2), 'or'); % 紅色圓圈表示當前種群hold on;h_rep = plot(REP.pos_fit(:,1), REP.pos_fit(:,2), 'ok'); % 黑色圓圈表示存檔解xlabel('f1'); ylabel('f2'); % 坐標軸標簽(目標函數名稱)title('MOPSO迭代過程');display(['初始代數 #0 - 存檔大小: ' num2str(size(REP.pos,1))]);%% --------------------- 主循環 ---------------------stopCondition = false; % 終止條件標志while ~stopCondition%% 選擇領導者:基于網格的輪盤賭選擇h = selectLeader(REP); % 從存檔中選擇一個領導者索引%% 更新粒子速度和位置VEL = W .* VEL + ... % 慣性項C1 * rand(Np, nVar) .* (PBEST - POS) + ... % 個體歷史最優引導C2 * rand(Np, nVar) .* (repmat(REP.pos(h,:), Np, 1) - POS); % 群體最優引導POS = POS + VEL; % 更新位置%% 變異操作:增加多樣性POS = mutation(POS, gen, maxgen, Np, var_max, var_min, nVar, u_mut);%% 邊界檢查:確保位置和速度在允許范圍內[POS, VEL] = checkBoundaries(POS, VEL, maxvel, var_max, var_min);%% 計算新種群的適應度for i = 1:NpPOS_fit(i,:) = fun(POS(i,:));end%% 更新存檔REP = updateRepository(REP, POS, POS_fit, ngrid); % 合并新非支配解if size(REP.pos,1) > NrREP = deleteFromRepository(REP, size(REP.pos,1)-Nr, ngrid); % 刪除多余解end%% 更新個體歷史最優% 比較新位置與歷史最優的支配關系pos_best = dominates(POS_fit, PBEST_fit); % 新位置是否優于歷史最優best_pos = ~dominates(PBEST_fit, POS_fit); % 歷史最優是否不支配新位置best_pos(rand(Np,1) >= 0.5) = 0; % 隨機保留部分歷史最優(增加多樣性)% 更新被新位置支配的歷史最優if sum(pos_best) > 1PBEST_fit(pos_best,:) = POS_fit(pos_best,:);PBEST(pos_best,:) = POS(pos_best,:);end% 更新未被歷史最優支配的新位置if sum(best_pos) > 1PBEST_fit(best_pos,:) = POS_fit(best_pos,:);PBEST(best_pos,:) = POS(best_pos,:);end%% --------------------- 可視化更新 ---------------------% 2D目標空間繪圖if size(POS_fit,2) == 2figure(h_fig);delete(h_par); delete(h_rep); % 清除舊圖形h_par = plot(POS_fit(:,1), POS_fit(:,2), 'or'); % 紅色:當前種群hold on;h_rep = plot(REP.pos_fit(:,1), REP.pos_fit(:,2), 'ok'); % 黑色:存檔解try % 調整坐標軸以匹配網格劃分set(gca, 'xtick', REP.hypercube_limits(:,1)', 'ytick', REP.hypercube_limits(:,2)');axis([min(REP.hypercube_limits(:,1)), max(REP.hypercube_limits(:,1)), ...min(REP.hypercube_limits(:,2)), max(REP.hypercube_limits(:,2))]);endgrid on; drawnow; axis square;end% 3D目標空間繪圖(若目標數為3)if size(POS_fit,2) == 3figure(h_fig);delete(h_par); delete(h_rep);h_par = plot3(POS_fit(:,1), POS_fit(:,2), POS_fit(:,3), 'or');hold on;h_rep = plot3(REP.pos_fit(:,1), REP.pos_fit(:,2), REP.pos_fit(:,3), 'ok');% 調整3D坐標軸tryset(gca, 'xtick', REP.hypercube_limits(:,1)', 'ytick', REP.hypercube_limits(:,2)', ...'ztick', REP.hypercube_limits(:,3)');axis([min(REP.hypercube_limits(:,1)), max(REP.hypercube_limits(:,1)), ...min(REP.hypercube_limits(:,2)), max(REP.hypercube_limits(:,2)), ...min(REP.hypercube_limits(:,3)), max(REP.hypercube_limits(:,3))]);endgrid on; xlabel('f1'); ylabel('f2'); zlabel('f3');drawnow; axis square;end%% 顯示迭代信息display(['代數 #' num2str(gen) ' - 存檔大小: ' num2str(size(REP.pos,1))]);%% 終止條件檢查gen = gen + 1;if gen > maxgenstopCondition = true; % 達到最大迭代次數,終止循環endendhold off;
參考資料
GRU門控循環單元+NSGAII多目標優化算法,深度學習工藝參數優化+酷炫相關性氣泡圖!(Matlab完整源碼和數據)
LSTM+NSGAII多目標優化算法,酷炫相關性氣泡圖!(Matlab完整源碼和數據)
NRBO-CNN+NSGAII+熵權TOPSIS,附相關氣泡圖,Matlab代碼!
深度學習工藝參數優化+酷炫相關性氣泡圖!CNN卷積神經網絡+NSGAII多目標優化算法(Matlab完整源碼)
工藝參數優化、工程設計優化!GRNN神經網絡+NSGAII多目標優化算法(Matlab)
工藝參數優化、工程設計優化陪您跨年!RBF神經網絡+NSGAII多目標優化算法(Matlab)
工藝參數優化、工程設計優化來襲!BP神經網絡+NSGAII多目標優化算法(Matlab)
北大核心工藝參數優化!SAO-BP雪融算法優化BP神經網絡+NSGAII多目標優化算法(Matlab)
工藝參數優化、工程設計優化上新!Elman循環神經網絡+NSGAII多目標優化算法(Matlab)
強推未發表!3D圖!Transformer-LSTM+NSGAII工藝參數優化、工程設計優化!










 RadarDistill---NuScenes數據集Radar檢測第一名)
設計模式)







