本文介紹一篇Radar 3D目標檢測模型:RadarDistill。雷達數據固有的噪聲和稀疏性給3D目標檢測帶來了巨大挑戰。在本文中,作者提出了一種新的知識蒸餾(KD)方法RadarDistill,它可以通過利用激光雷達數據來提高雷達數據的表征。RadarDistill利用三個關鍵組件將激光雷達特征的特征轉移到雷達特征中: 模態對齊(CMA)、基于激活的特征蒸餾(AFD)和基于Proposal的特征蒸餾(PFD)。
- CMA通過多層膨脹操作增強了雷達特征的密度,有效地解決了從激光雷達到雷達的知識遷移效率不足的挑戰。
- AFD 旨在將知識從 LiDAR 特征的重要區域遷移,特別是那些激活強度超過預定閾值的區域。
- PFD引導雷達網絡在Proposal中模擬LiDAR網絡特征,以準確地檢測結果,同時調節誤檢測的Proposal的特征。
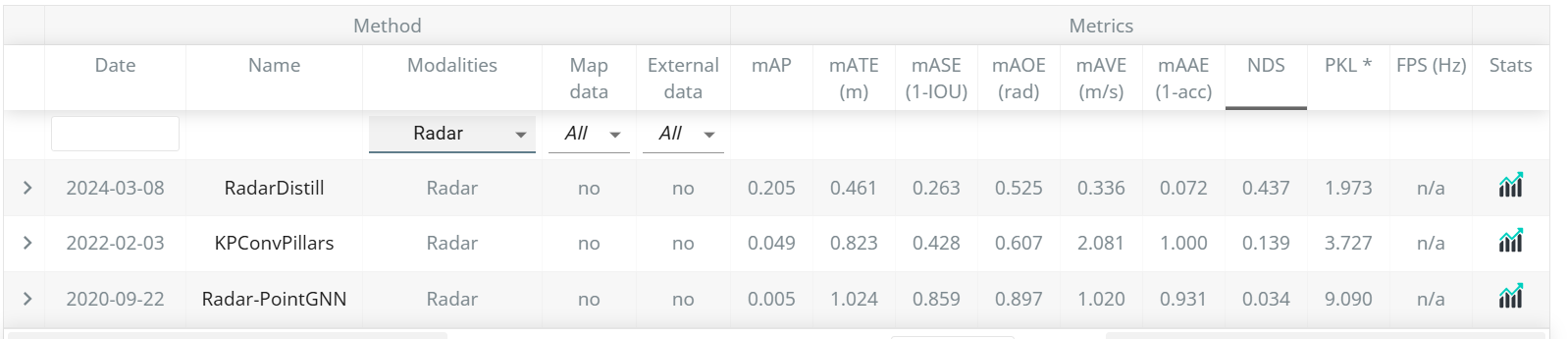
在nuScenes數據集上進行的實驗表明,RadarDistill在純雷達目標檢測任務中達到了最先進的性能(SOTA),mAP為20.5%,NDS為43.7%。此外,RadarDistill還提高了相機-雷達融合模型的性能。
項目地址:https://github.com/geonhobang/RadarDistill
文章目錄
- Introduction && Related Work
- Method
- Preliminary
- Cross-Modality Alignment
- Activation-based Feature Distillation
- Proposal-based Feature Distillation
- Experiments
Introduction && Related Work
本文引言和相關工作這里就簡單介紹下(本文的寫作可以學習下)。本文目標時利用深度神經網絡提高雷達的三維目標檢測的性能。考慮到雷達測量的稀疏和噪聲性質,雷達的有限性能主要是由于尋找有效表示的挑戰。受LiDAR 點云的深度模型的顯著成功的啟發,我們的目標是遷移從基于 LiDAR 的模型中提取的知識以增強基于雷達的模型。
最近,知識蒸餾 (KD) 技術在將知識從一種傳感器模態轉移到另一種傳感器模態方面取得了成功,從而優化目標模型的表示質量。基于所使用的學生模型的模態,跨模態知識蒸餾可以大致分為兩種方法。當使用相機作為學生模型時,深度和形狀信息都從教師模型轉移到學生模型。BEVDistill將 LiDAR 和相機特征轉換為 BEV 形式,從而能夠將空間知識從 LiDAR 特征轉移到相機特征。DistillBEV利用LiDAR或LiDAR-camera融合模型的預測結果來區分前景和背景,引導學生模型聚焦于重要區域的KD。S2M2-SSD根據學生模型的預測確定關鍵區域,并傳輸從關鍵區域的LiDAR-camera融合模型獲得的信息。除了這些方法之外,UniDistill采用了一個通用的跨模態框架,可以實現不同模態之間的知識轉移。該框架適用于不同的模態配對,包括相機到激光雷達、激光雷達到相機、(相機+激光雷達)到相機。
在本文中,我們提出了一種新的KD框架RadarDistill,該框架旨在增強雷達數據的表示。我們的研究表明,通過使用雷達編碼網絡作為學生網絡和LiDAR編碼網絡作為教師網絡,我們的KD框架有效地產生了類似于從LiDAR數據的密集和語義豐富的特征的特征,以更好地檢測目標。
本文主要貢獻有:
- 我們的研究是第一個證明在訓練過程中使用 LiDAR 數據可以顯著提高雷達目標檢測的工作。我們在圖1中的定性結果強調了通過 RadarDistill 獲得的雷達特征成功地模仿了 LiDAR 的特征,從而提高了目標檢測。
- 我們的研究結果表明,CMA 是 RadarDistill 中的一個關鍵模塊。在缺少CMA的情況下,我們觀察到性能提升顯著下降。根據我們的消融研究,CMA在解決雷達和LiDAR點云密度不同造成的低效知識轉移方面起著關鍵作用。
- 我們提出了兩種新的 KD 方法 AFD 和 PFD。這些方法彌合了雷達和激光雷達特征之間的差異,分別在在兩個獨立的特征層面工作,并專門為每個級別設計了KD損失。
- RadarDistill 在 nuScenes 基準測試中的 radar-only 目標檢測器類別中實現了最先進的性能。它還為 camera-radar 融合場景實現了顯著的性能提升。

Method
Preliminary

本文使用PillarNet作為激光雷達檢測器和雷達檢測器的baseline。激光雷達和雷達的稀疏2D pillar特征分別為 F l d r 2 D F^{2D}_{ldr} Fldr2D?、 F r d r 2 D F^{2D}_{rdr} Frdr2D?,通過2D稀疏卷積編碼器得到低級BEV特征為 F r d r l F^{l}_{rdr} Frdrl?、 F r d r l F^{l}_{rdr} Frdrl?為,然后使用2D密集卷積編碼器得到高級BEV特征 F r d r h F^{h}_{rdr} Frdrh?、 F r d r h F^{h}_{rdr} Frdrh?。最后高級BEV特征使用CenterHead進行處理,得到分類熱力圖,回歸熱力圖,IoU熱力圖:
H mod cls , H mod reg , H mod IoU = CenterHead ( F mod h ) H_{\text{mod}}^{\text{cls}}, H_{\text{mod}}^{\text{reg}}, H_{\text{mod}}^{\text{IoU}} = \text{CenterHead}(F_{\text{mod}}^h) Hmodcls?,Hmodreg?,HmodIoU?=CenterHead(Fmodh?)
Cross-Modality Alignment
我們的目標是通過CMA減少雷達和激光雷達之間的差異。PillarNet使用SPConv僅從非空pillar生成低級特征。在比較非空pillar的數量時,雷達的非空pillar僅占激光雷達非空pillar總數的11%。非空pillar數量的顯著差異需要兩種模式進行對齊,特別是由于激光雷達非空pillar的信息不能直接轉移到雷達數據中的相應空pillar中。CMA模塊如下圖所示,下采樣模塊應用可變形卷積在下采樣過程中提取必要特征,然后使用ConvNeXt V2塊聚合這些特征。在上采樣模塊中,使用2D轉置卷積應用膨脹以致密周圍區域的特征。包含連接和1×1卷積層的聚合模塊結合了不同的特征,操作類似于跳躍連接。

具體代碼如下:
def forward(self, data_dict):"""Args:data_dict:spatial_featuresReturns:"""spatial_features = data_dict['radar_multi_scale_2d_features']['x_conv4']ups = []ret_dict = {}en_16x = self.encoder_1(spatial_features) #(B, 256, 90, 90)de_8x = torch.cat((self.decoder_1(en_16x), spatial_features), dim=1)#(B,512,180,180)de_8x = self.agg_1(de_8x)#(B,256,180,180)en_32x = self.encoder_2(en_16x)#(B,256,45,45)de_16x = torch.cat((self.decoder_2(en_32x), self.encoder_3(de_8x)), dim=1)#(B,512,90,90)de_16x = self.agg_2(de_16x)#(B,256,90,90)x = torch.cat((self.decoder_3(de_16x), de_8x), dim=1)#(B, 512, 180, 180)x_conv4 = self.agg_3(x)data_dict['radar_multi_scale_2d_features']['radar_spatial_features_8x_2'] = x_conv4data_dict['radar_multi_scale_2d_features']['radar_spatial_features_8x_1'] = de_8xx_conv5 = data_dict['radar_multi_scale_2d_features']['x_conv5']ups = [x_conv4]x = self.blocks[1](x_conv5)ups.append(self.deblocks[0](x))data_dict['radar_spatial_features_2d_8x'] = ups[-1]x = torch.cat(ups, dim=1)x = self.blocks[0](x)data_dict['radar_spatial_features_2d'] = xreturn data_dict
Activation-based Feature Distillation
AFD 通過激活感知特征匹配策略對齊雷達和 LiDAR 的低級特征。這個過程將雷達特征的激活模式與激光雷達的激活模式相匹配,從而彌合了它們在活動特征分布上的差距。蒸餾區域被自適應地劃分為兩類:一類是雷達和激光雷達(LiDAR)都處于活躍狀態的活躍區域(AR),另一類是雷達處于活躍狀態而激光雷達處于非活躍狀態的非活躍區域(IR)。 由于雷達數據的稀疏性和噪聲特性,AR和IR之間存在不平衡。這種不平衡可能會通過專注于模仿占主導地位的IR來干擾訓練。因此,我們根據每個區域的像素數量應用相對自適應權重。具體代買如下:
def low_loss(self, lidar_bev, radar_bev):B, _, H, W = radar_bev.shapelidar_mask = (lidar_bev.sum(1).unsqueeze(1) > 0).float()radar_mask = (radar_bev.sum(1).unsqueeze(1))activate_map = (radar_mask > 0).float() + lidar_mask * 0.5mask_radar_lidar = torch.zeros_like(activate_map, dtype=torch.float)mask_radar_de_lidar = torch.zeros_like(activate_map, dtype=torch.float)mask_radar_lidar[activate_map==1.5] = 1mask_radar_de_lidar[activate_map==1.0] = 1mask_radar_de_lidar *= (mask_radar_lidar.sum() / mask_radar_de_lidar.sum())loss_radar_lidar = F.mse_loss(radar_bev, lidar_bev, reduction='none')loss_radar_lidar = torch.sum(loss_radar_lidar * mask_radar_lidar) / Bloss_radar_de_lidar = F.mse_loss(radar_bev, lidar_bev, reduction='none')loss_radar_de_lidar = torch.sum(loss_radar_de_lidar * mask_radar_de_lidar) / B# breakpoint()feature_loss = 3e-4 * loss_radar_lidar + 5e-5 * loss_radar_de_lidarloss = nn.L1Loss()mask_loss = loss(radar_mask.sigmoid(), lidar_mask)return feature_loss, mask_lossProposal-based Feature Distillation
PDF損失函數如下所示。
def high_loss(self, radar_bev,radar_bev2, lidar_bev,lidar_bev2, heatmaps, radar_preds):thres = 0.1gt_thres = 0.1gt_batch_hm = torch.cat(heatmaps, dim=1)gt_batch_hm_max = torch.max(gt_batch_hm, dim=1, keepdim=True)[0]#[1, 2, 2, 1, 2, 2]radar_batch_hm = [(clip_sigmoid(radar_pred_dict['hm'])) for radar_pred_dict in radar_preds]radar_batch_hm = torch.cat(radar_batch_hm, dim=1)radar_batch_hm_max = torch.max(radar_batch_hm, dim=1, keepdim=True)[0]radar_fp_mask = torch.logical_and(gt_batch_hm_max < gt_thres, radar_batch_hm_max > thres)radar_fn_mask = torch.logical_and(gt_batch_hm_max > gt_thres, radar_batch_hm_max < thres)radar_tp_mask = torch.logical_and(gt_batch_hm_max > gt_thres, radar_batch_hm_max > thres)# radar_tn_mask = torch.logical_and(gt_batch_hm_max < gt_thres, radar_batch_hm_max < thres)wegiht = torch.zeros_like(radar_batch_hm_max)wegiht[radar_tp_mask + radar_fn_mask] = 5 /(radar_tp_mask + radar_fn_mask).sum()wegiht[radar_fp_mask] = 1 / (radar_fp_mask).sum()scaled_radar_bev = radar_bev.softmax(1)scaled_lidar_bev = lidar_bev.softmax(1)scaled_radar_bev2 = radar_bev2.softmax(1)scaled_lidar_bev2 = lidar_bev2.softmax(1)high_loss = F.l1_loss(scaled_radar_bev, scaled_lidar_bev, reduction='none') * wegihthigh_loss = high_loss.sum()high_8x_loss = F.l1_loss(scaled_radar_bev2, scaled_lidar_bev2, reduction='none') * wegihthigh_8x_loss = high_8x_loss.sum()high_loss = 0.5 * (high_loss + high_8x_loss)return high_lossExperiments
下面介紹本文實驗部分。基線模型使用了PillarNet-18,即采用ResNet18作為骨干網絡的PillarNet [23]。我們使用了Adam優化器,學習率設置為0.001,并采用單周期學習率策略。我們將權重衰減設置為0.01,并將動量在0.85和0.95之間進行調整。我們在4塊NVIDIA RTX 3090 GPU上訓練了基線模型,共訓練了20個epoch,采用總批量大小為16的類別平衡分組與采樣(Class-Balanced Grouping and Sampling,簡稱CBGS)策略。
本文提出的模型訓練了40個epochs,其他所有訓練過程都與基線模型完全相同。我們采用教師模型的權重來初始化學生模型。
在NuScenes測試集上可以看到,在Radar-only模型中,我們的方法排到了第一名,并且比第二名KPConvPillars在mAP上提高了15.6個點,在NDS提高了29.8個點。
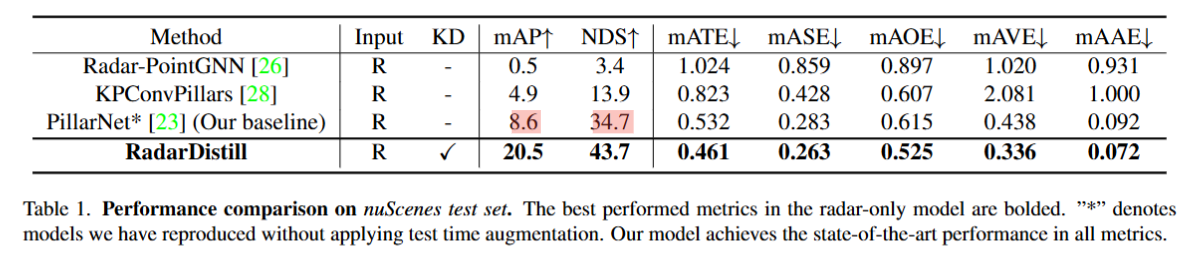
下面是具體每一類的目標AP對比,本文提出的方法比基線模型在所有類別上都有提高,特別是在Trailer、T.C和Barrier上都提高了20個點以上。在Car和Trailer類別上比純視覺模型和融合模型還要高。但是在Ped和Bicycle等小目標上沒有很大提高,因為它們的真值中有很少的雷達點。
下面是消融實驗,作者做消融實驗的時候使用了1/7的訓練集進行訓練,縮短開發時間。表3可以看到本文提出的三個模塊對模型性能的影響。當CMA和AFD或PFD一起使用的話,比baseline模型都提高了不少。而AFD和PFD一起使用的話,性能提升則十分有限。這表明CMA模塊扮演了十分重要的角色。

表4分析了AFD中選擇不同特征區域的影響。
(1)在整個區域上進行蒸餾時,汽車平均精度(Car AP)提高了4.2%,平均精度(mAP)提高了2.2%,以及NDS提高了2.9%。
(2)將蒸餾應用于真值框(GT boxes)為中心的高斯熱力圖區域,與在整個區域上進行蒸餾相比,汽車平均精度和平均精度均有所提高,但NDS有所下降。
(3)將蒸餾分為前景區域和背景區域進行,與在整個區域上進行蒸餾相比,汽車平均精度和平均精度均有所提高,但NDS略有下降(31.7vs32.2)。
(4)相反,按照我們提出的激活區域劃分特征蒸餾,與在整個區域上進行蒸餾相比,在所有指標上均取得了最佳性能,Car-AP提高了6.8%,mAP提高了2.3%,NDS提高了1.5%。

表5分析了PFD中選擇不同特征區域的影響。可以看到無論是整個區域,還是真值中心熱力圖、或是LiDAR預測都沒有太大的提升,而使用本文提出的Radar預測區域,相比baseline在NDS上提高了1個點。

最后作者在RC融合模型上驗證本文提出的知識蒸餾方法的效果,使用的baseline是MIT版本的BEVFusion代碼庫,可以看到使用本文提出的方法后,mAP和NDS均有提升。

設計模式)


















