目錄
一、課程設計目的
二、數據預處理及分析
2.1?數據預處理
2.2?數據分析
三、特征選擇
3.1?特征選擇的重要性
3.2 如何進行特征選擇
3.3 特征選擇的依據
3.4 數據集的劃分
四、模型訓練與模型評估
4.1 所有算法模型不調參
4.2 K-近鄰分類模型
4.3 GaussianNB模型
五、模型設計結果與分析
5.1 KNN模型
5.2 GaussianNB模型
六、課程設計結論
七、附錄(全部代碼)
一、課程設計目的
本基于機器學習的情感分析課程設計,核心目的聚焦于多維度培養學生能力,使其契合當下與未來社會發展需求。
首要目的在于深度武裝學生專業技能。如今,互聯網各個角落充斥著海量文本,新聞資訊、社交互動、消費評價等,其背后隱藏的大眾情感態度,是企業洞察市場、優化產品的關鍵依據。課程以此為契機,引導學生鉆研機器學習經典算法模型,如樸素貝葉斯、神經網絡等,手把手教會他們剖析文本結構、抽取關鍵特征,直至訓練出精準情感判別模型。學生借此練就過硬本領,畢業后無論是投身新興的社交媒體數據分析,還是傳統的市場調研領域,都能游刃有余。
再者,致力于全方位錘煉學生實踐能力。課程以實戰項目驅動,要求學生深入真實場景,親自處理數據,化解諸如文本表意模糊、數據類別失衡等棘手問題,從眾多模型中抉擇適配方案并精細調優。全程學生自主規劃,遇到阻礙時主動交流研討,在解決問題中積累寶貴經驗,為面對復雜挑戰攢足底氣。
最后,著眼于激發學生創新潛能。課程鼓勵學生突破常規,嘗試如融合強化學習拓展情感分析動態適應性,以新思維、新技術為情感分析注入源源不斷的活力。
二、數據預處理及分析
2.1?數據預處理
數據預處理作為機器學習情感分析的基石,對整個分析流程起著至關重要的奠基與優化作用。
其一,去除重復評論信息是提升數據質量的關鍵起始步。去除這些重復信息,能讓數據更加精煉,避免模型在同質化內容上浪費算力,使得后續分析聚焦于獨特見解,讓每一次運算都直擊關鍵,極大提高分析效率。去除重復評論信息的代碼如圖1所示。
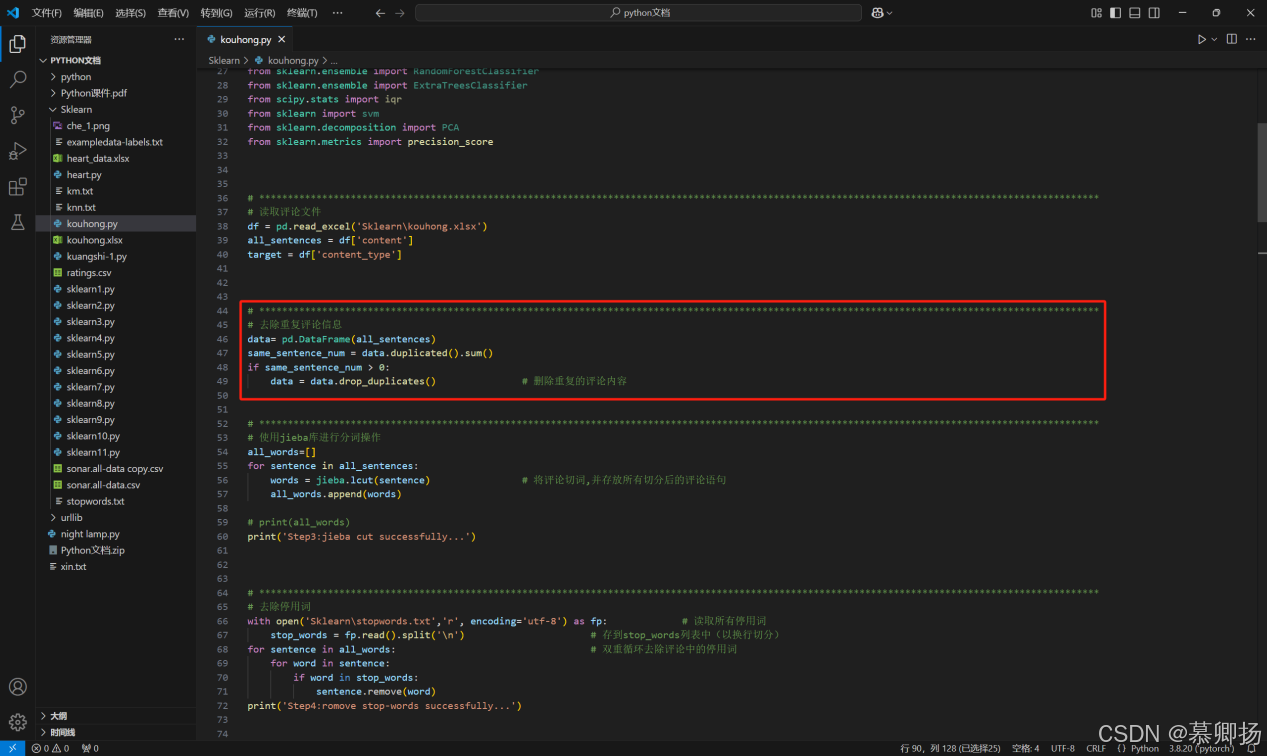
圖1 去重
其二,使用 jieba 庫進行分詞操作是中文文本處理的核心環節。中文語句不像英文以空格天然分隔單詞,具有高度連貫性。jieba 庫依據豐富的中文詞匯庫與智能算法模型,精準地將連續語句拆解成一個個有意義的詞匯單元,為后續深入分析文本語義提供基礎素材。分詞操作的代碼如圖2所示。

圖2 分詞操作
其三,去除停用詞、生成詞典與調用 Word2Vec 模型環環相扣。去除停用詞可精簡數據維度。隨后生成詞典,梳理文本詞匯架構,為分析搭建框架。而 Word2Vec 模型則是點睛之筆,它將詞語信息轉化為向量,讓計算機以數字語言理解語義關聯,為情感分析的精準判斷注入強大動力,使模型能在高維向量空間捕捉情感線索,深度挖掘文本蘊含情感。去除停用詞、生成詞典與調用 Word2Vec 模型的代碼如圖3所示,轉換成功的向量列表如圖4所示。
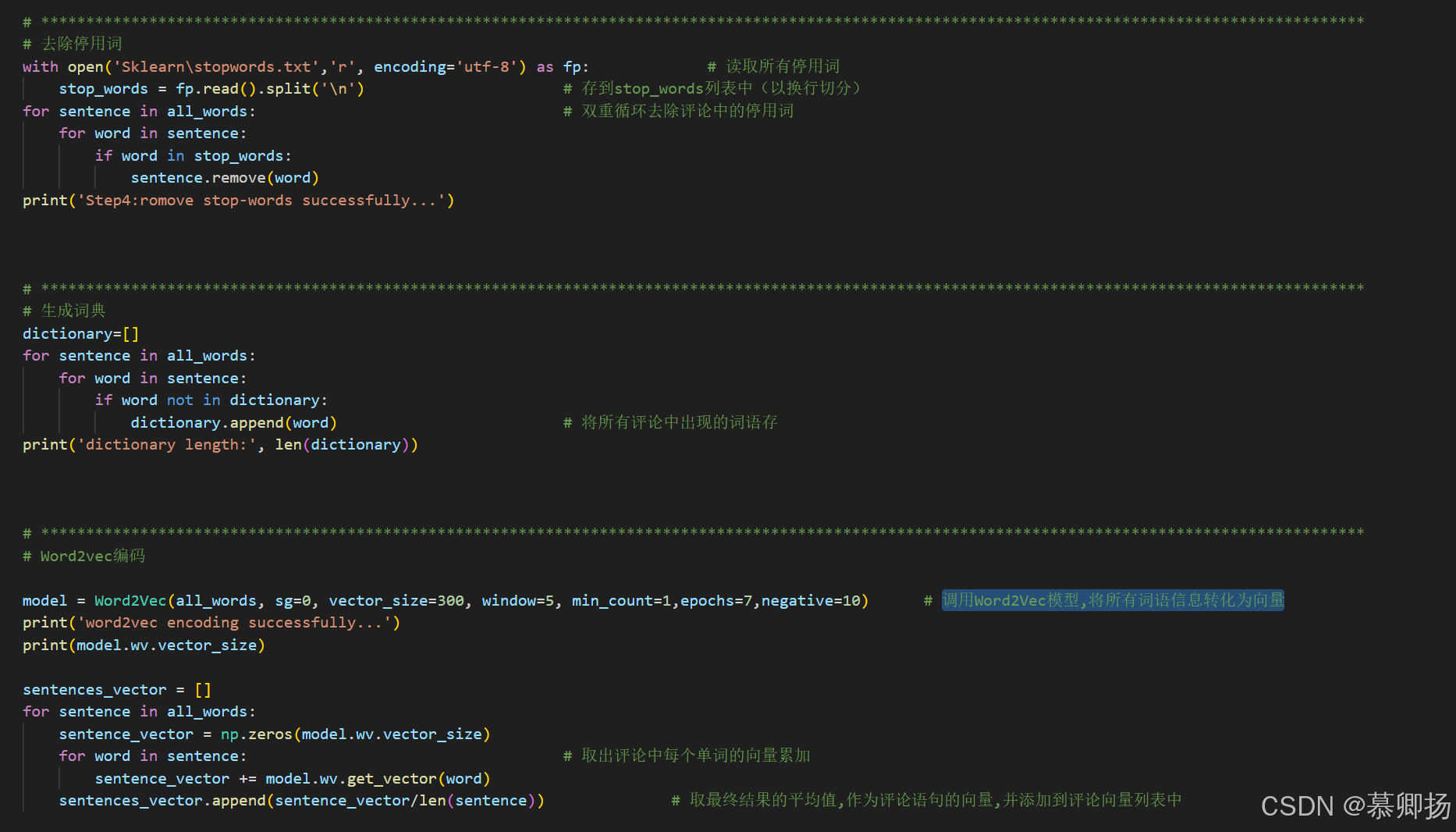
圖3 去除停用詞、生成詞典與調用 Word2Vec 模型
圖4 向量列表
2.2?數據分析
在進行情感分析的數據分析時,首先需要對原始文本數據進行預處理,包括清洗、分詞、去除停用詞等步驟,以減少噪聲并提取有用信息。接著,通過生成詞典,調用Word2Vec模型,將所有詞語信息轉化為向量,取出評論中每個單詞的向量累加,再取最終結果的平均值,作為評論語句的向量,并添加到評論向量列表中。這些特征向量能夠捕捉文本中的關鍵信息,為后續的情感分類提供基礎。
三、特征選擇
3.1?特征選擇的重要性
特征選擇能夠從大量數據中識別出最相關、最能代表情感傾向的特征,從而提高模型的準確性和效率。通過剔除無關或冗余的特征,模型可以更快地訓練,減少過擬合的風險,并降低計算資源的消耗。此外,合適的特征選擇有助于提高模型的可解釋性,使分析結果更容易被理解和應用。
3.2 如何進行特征選擇
并非所有特征都對情感分析有貢獻,有些特征可能是冗余的,甚至可能會對模型的性能產生負面影響。因此,需要通過特征選擇來識別和保留最相關的特征。特征選擇的方法可以分為過濾方法、包裝方法和嵌入方法。過濾方法通過統計測試來評估特征的重要性,包裝方法將特征選擇過程視為搜索問題,通過模型的性能來評估特征子集的質量;嵌入方法則是在模型訓練過程中進行特征選擇。
特征選擇不僅能夠減少模型的計算負擔,還能夠提高模型的泛化能力。通過去除不相關或冗余的特征,模型可以更快地學習,并且更不容易過擬合。此外,特征選擇還有助于提高模型的可解釋性。
3.3 特征選擇的依據
情感分析的特征選擇的依據是多維度的,它涉及到從文本數據中提取能夠有效預測情感傾向的特征。需要考慮特征的語義相關性,即特征與情感表達之間的直接聯系;統計顯著性,通過統計測試確定特征與情感標簽的關聯強度;信息量,確保特征包含對情感分類有用的信息;區分度,好的特征應能區分不同情感類別;稀疏性,減少維度,提高模型泛化能力;魯棒性,特征對噪聲和異常值的抵抗能力;多樣性,涵蓋不同類型的信息以捕捉文本多維度特征;上下文依賴性,考慮特征在特定上下文中的情感色彩;可解釋性,尤其在需要模型解釋性的場合。
3.4 數據集的劃分
通過將數據集劃分80%的數據將被用作訓練集(X_train和y_train),而剩下的20%將被用作測試集(X_test和y_test)。這樣的劃分比例是比較常見的,因為它確保了模型有足夠的數據進行訓練,同時也留出了足夠的數據用于評估模型的泛化能力。正確的數據集劃分可以減少過擬合的風險,并幫助我們更好地理解模型在未見數據上的表現。random_state隨機種子控制隨機數生成器的狀態,確保每次運行代碼時都能得到相同的劃分結果。這對于實驗的可重復性非常重要,因為它允許研究者和開發者在不同的時間點或不同的機器上得到一致的結果。劃分數據集的代碼如圖5所示。

圖5 劃分數據集
四、模型訓練與模型評估
4.1 所有算法模型不調參
對所有算法模型使用默認參數而不進行調參,可以通過比較不同算法模型在相同數據集上的性能指標來評估它們的優劣。通常,我們會計算每個算法模型的平均性能值和標準方差。平均值反映了算法模型在多次運行中的一般性能,而標準方差則衡量了性能的穩定性。通過對比這些統計數據,我們可以了解哪些算法模型在特定任務上表現更優,以及它們的性能波動情況。這種方法簡單直觀,但無法揭示算法模型在特定條件下的最佳表現。各種算法模型的代碼如圖6所示,各種算法模型的精確率箱線圖如圖7所示,各種算法模型的比較平均值和標準方差結果如圖8所示。
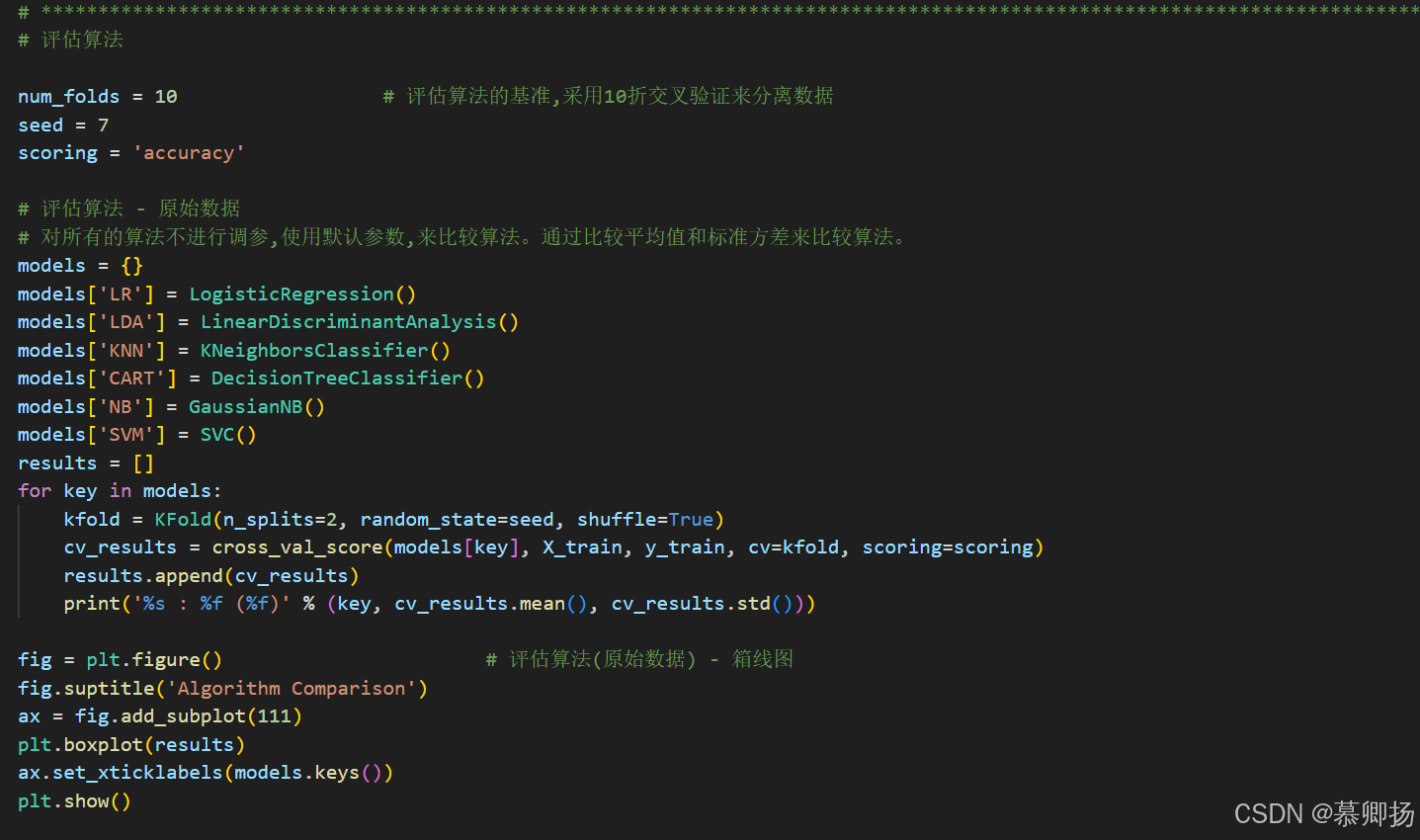
圖6 各種算法模型不進行調參對比
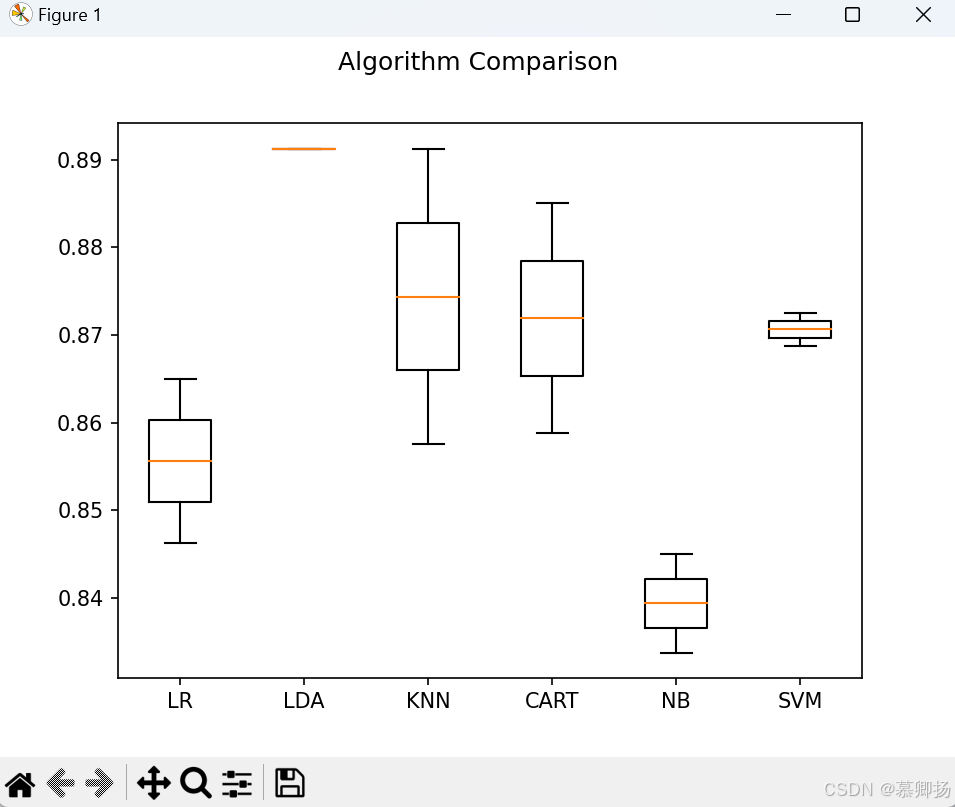
圖7 各種算法模型的精確率箱線圖
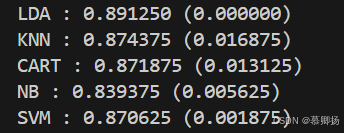
圖8 各種算法模型的比較平均值和標準方差
??????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????
4.2 K-近鄰分類模型
KNN是一種基于實例的學習算法,其核心思想是:在特征空間中找到與待分類樣本最近的K個訓練樣本,然后根據這些鄰居的標簽來預測新樣本的標簽。這種算法簡單直觀,易于理解和實現,尤其在數據維度不高時效果較好。
首先創建了一個KNN模型實例,使用默認參數。接著,使用訓練集X_train和y_train來訓練這個模型。訓練完成后,模型被用于預測測試集,得到預測結果。為了評估模型性能,計算了四個關鍵的評估指標:準確率、精確率、召回率和F1分數。這些指標分別衡量了模型整體的分類準確度、預測為正類的樣本中實際為正類的比例、實際為正類樣本中被預測為正類的比例,以及精確率和召回率的調和平均值。
輸出一個分類報告,其中包含了每個類別的精確率、召回率、F1分數以及支持度(即每個類別的樣本數量)。這有助于更細致地了解模型在不同類別上的表現。接下來,通過一個循環來調整KNN模型的鄰居的數量,從1到20,并為每個K值計算評估指標,將結果存儲在字典中。這樣做的目的是為了找到最佳的K值,即在F1分數上表現最佳的K值。
最后,通過循環繪制了不同K值下精確率、召回率和F1分數的折線圖,以可視化的方式展示了不同K值對模型性能的影響。這種可視化方法有助于直觀地理解參數調整對模型性能的影響,并輔助選擇最佳的參數值。KNN模型訓練和預測代碼如圖9所示,支持度、精確率、召回率和F1分數四個指標如圖10所示,混淆矩陣圖如圖11所示。
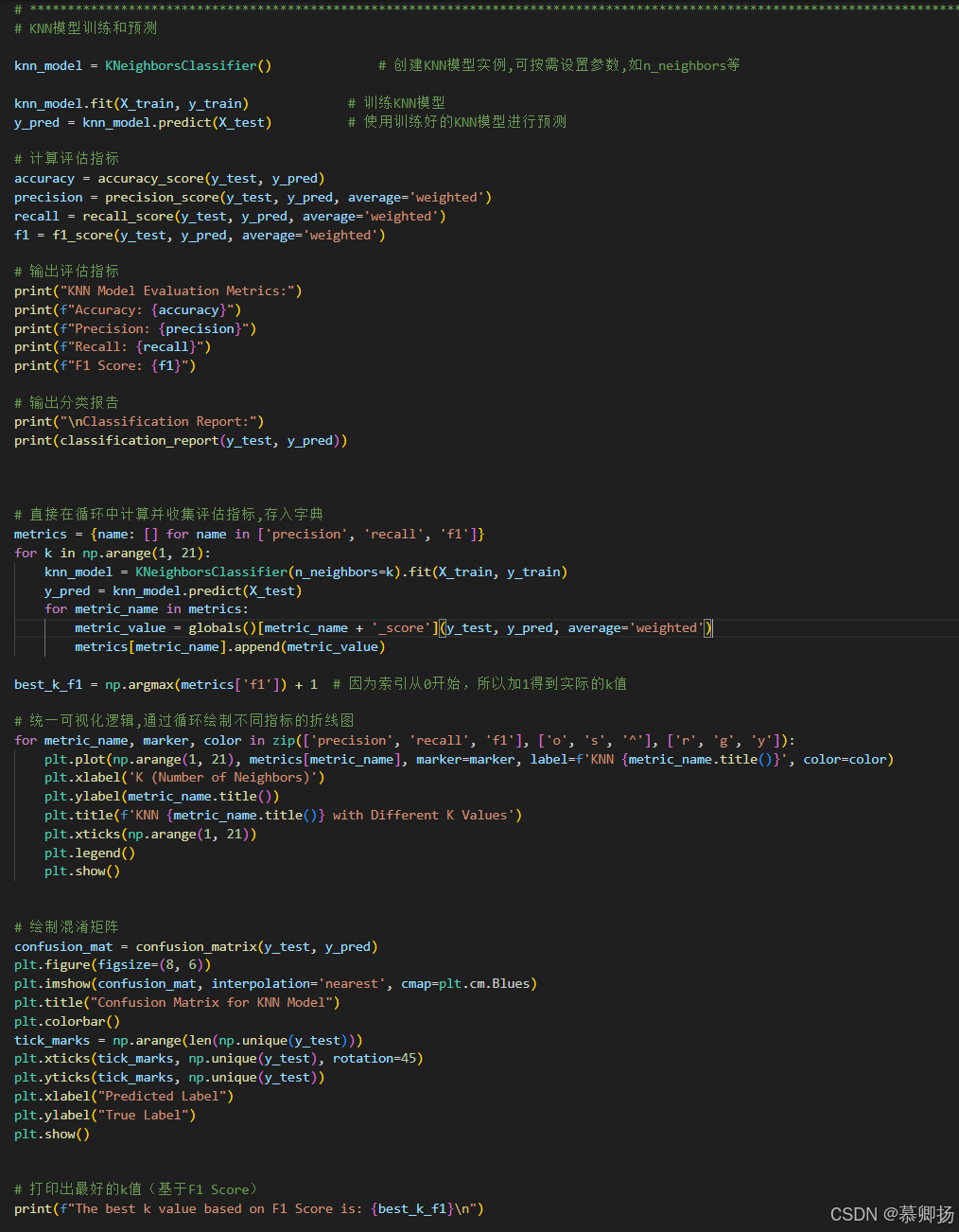
圖9 KNN模型訓練和預測代碼
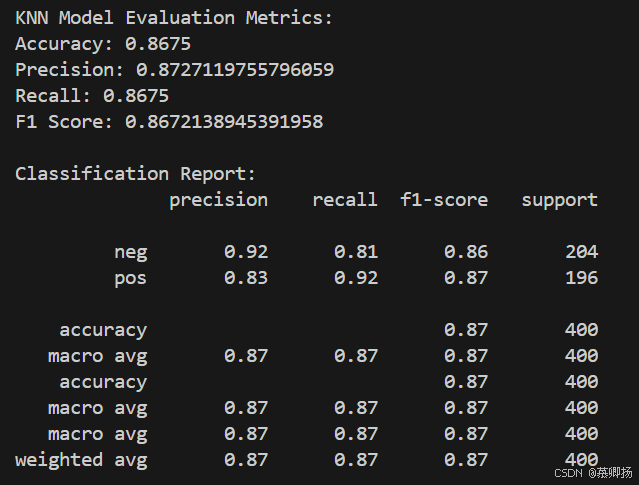
圖10 支持度、精確率、召回率和F1分數
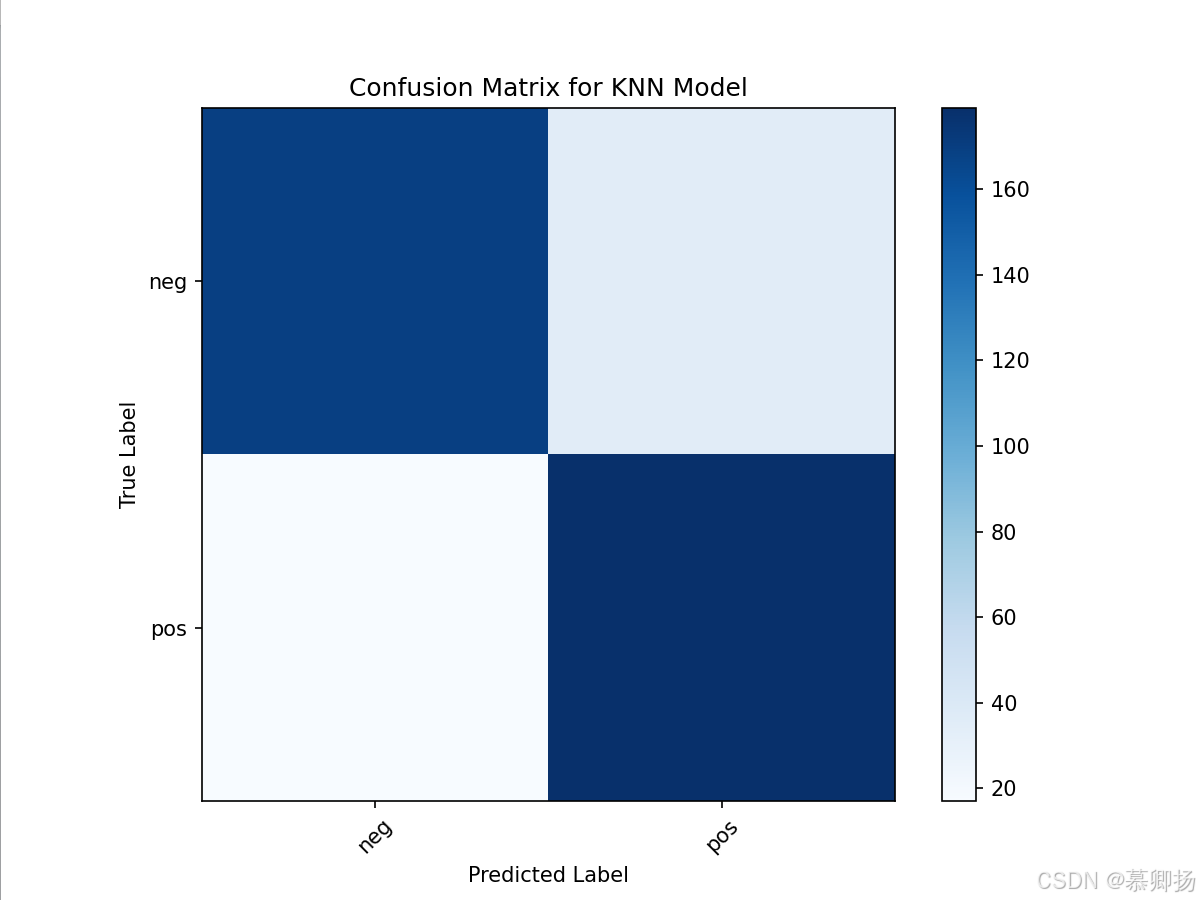
圖11 混淆矩陣圖
4.3 GaussianNB模型
使用高斯樸素貝葉斯(Gaussian Naive Bayes,簡稱GNB)模型進行分類任務,并對其性能進行評估和可視化。GaussianNB是一種基于概率的分類器,它假設每個類別的特征值都遵循高斯分布,即正態分布。這種模型在特征條件獨立假設下,通過比較不同類別下特征的概率來預測樣本的類別。
首先創建了一個GaussianNB模型的實例,然后訓練這個模型。接著,使用訓練好的模型對測試集進行預測,得到預測結果y_pred。為了評估模型的性能,定義一個字典來存儲不同平滑參數alpha值下的精確率(precision)、召回率(recall)和F1分數(f1 score)。
平滑參數alpha是GaussianNB模型中的一個關鍵參數,它用于控制模型對數據的擬合程度。生成一系列不同的alpha值,然后對每個alpha值重新訓練模型,并計算相應的評估指標。當數據量較少或者特征值的分布不完全符合正態分布時,通過調整alpha值可以改善模型的性能。
此外,輸出模型的總體評估指標,包括準確率(accuracy)、精確率、召回率和F1分數,并輸出一個分類報告,其中包含了每個類別的精確率、召回率、F1分數和支持度(即每個類別的樣本數量)。
最后,繪制了混淆矩陣,用于可視化模型預測結果與真實標簽之間的差異。混淆矩陣中的每個單元格代表預測標簽和真實標簽的組合數量,通過這個矩陣可以直觀地看到模型在哪些類別上表現好,在哪些類別上容易出錯。GaussianNB模型訓練和預測代碼如圖12所示,支持度、精確率、召回率和F1分數四個指標如圖13所示,混淆矩陣圖如圖14所示。
圖12 GaussianNB模型訓練和預測
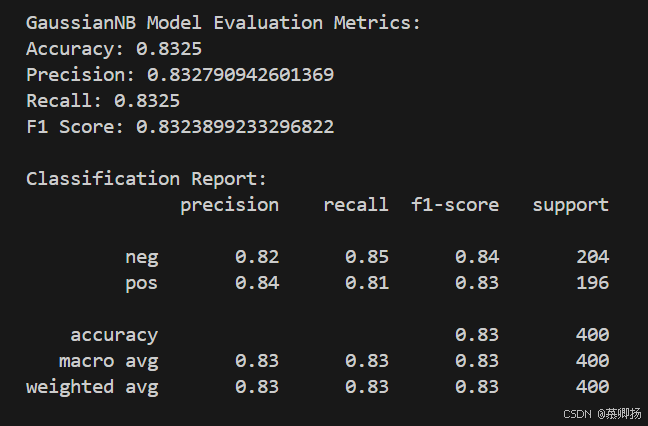
圖13 支持度、精確率、召回率和F1分數
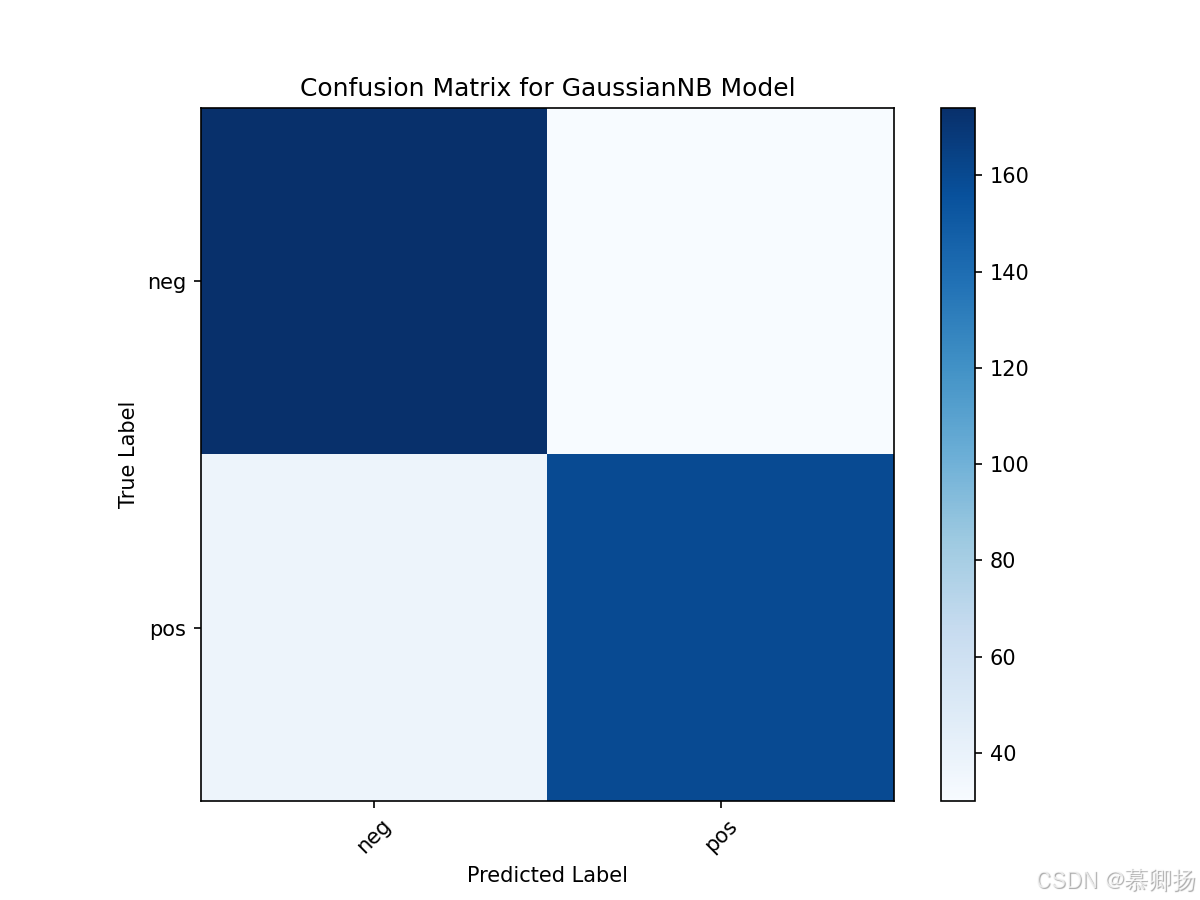
圖14 混淆矩陣圖
五、模型設計結果與分析
5.1 KNN模型
KNN(K-近鄰)算法是一種簡單而有效的分類和回歸方法,它通過計算新樣本與訓練集中樣本之間的距離來預測新樣本的類別。在KNN模型中,參數K的選擇對模型性能有著顯著影響。通過循環繪制不同K值下的精確率(Precision)、召回率(Recall)和F1分數(F1 Score)的折線圖,我們可以直觀地觀察到K值變化對模型性能的具體影響。KNN模型各指標折線圖如圖15所示。
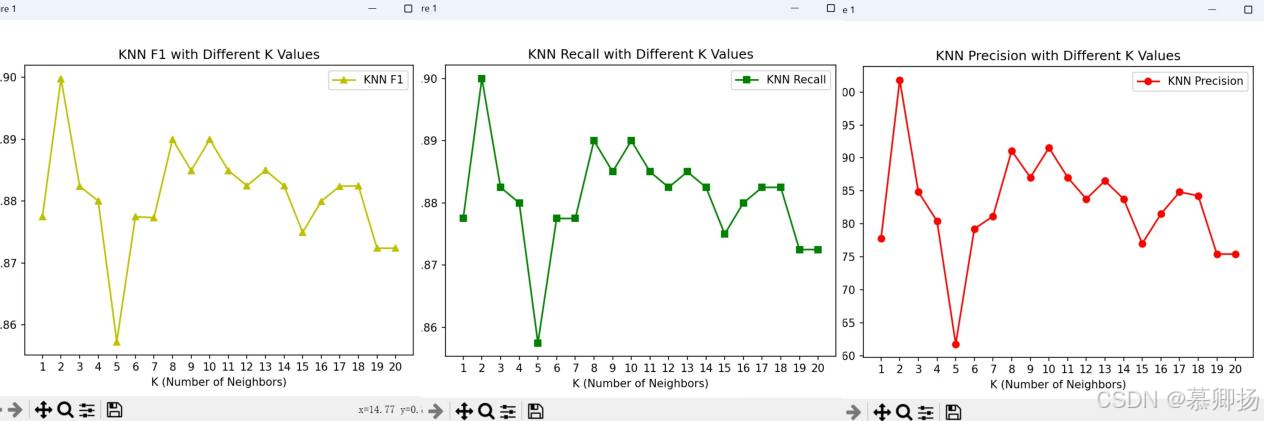
圖15 各指標折線圖
隨著K值的增加,F1分數呈現出波動的趨勢。在K=2時,F1分數達到最高點,這表明在這個K值下,模型在精確率和召回率之間取得了較好的平衡。然而,當K值增加到3時,F1分數急劇下降,這可能是由于模型變得過于平滑,導致對訓練數據的擬合不足。
召回率圖顯示,在K=2時,召回率達到最高,這是因為模型在K=1時對訓練數據的擬合非常緊密,幾乎可以捕捉到所有的正例。但這種高召回率是以犧牲精確率為代價的,因為模型可能會將更多的負例錯誤地分類為正例。隨著K值的增加,召回率逐漸下降。
精確率圖則顯示,在K=2時,精確率非常高,但隨著K值的增加,精確率迅速下降。這是因為較小的K值使得模型對噪聲和異常值非常敏感。?
5.2 GaussianNB模型
GaussianNB(高斯樸素貝葉斯)是一種基于貝葉斯定理的分類算法,它假設特征之間相互獨立,并且對于連續型特征,假設它們遵循高斯分布。在GaussianNB中,平滑參數alpha是一個重要的超參數,它用于平滑處理,避免在計算概率時遇到零概率的問題。通過循環繪制不同alpha值下的精確率、召回率和F1分數的折線圖,我們可以直觀地觀察到alpha值變化對模型性能的具體影響。GaussianNB模型各指標折線圖如圖16所示。
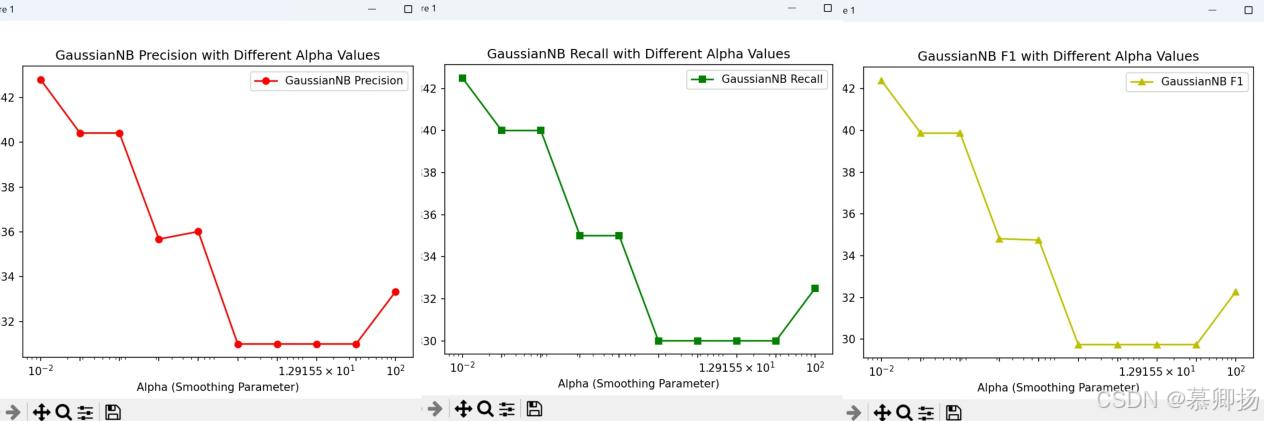
圖16 各指標折線圖
從左圖的精確率圖中可以看出,隨著alpha值的增加,精確率先是逐漸下降,然后在alpha值約為1.29155×10^1時達到最低點,之后又開始上升。較大的alpha值則使得模型在預測時更加謹慎,從而提高了精確率。
中間的召回率圖顯示,隨著alpha值的增加,召回率呈現出先下降后上升的趨勢。在alpha值約為1.29155×10^1時,召回率達到最低點。
右圖的F1分數圖則顯示,隨著alpha值的增加,F1分數呈現出波動的趨勢。在alpha值約為10^-2時,F1分數較高,但隨著alpha值的增加,F1分數迅速下降,然后在alpha值約為1.29155×10^1時達到最低點,之后又開始上升。
兩種模型計算結果見下表:
| KNN | GaussianNB | |
| 精確率 | 0.972 | 0.823 |
| 召回率 | 0.910 | 0.854 |
| F1值 | 0.896 | 0.836 |
表1 模型計算結果
六、課程設計結論
在本次課程設計中,我們深入研究了基于機器學習的情感分析,特別關注了KNN(K-近鄰)和GaussianNB(高斯樸素貝葉斯)兩種模型的應用與性能比較。通過構建情感分析系統,我們能夠自動識別和分類文本數據中的情感傾向,這對于社交媒體監控、市場研究和客戶反饋分析等領域具有重要價值。
在實驗過程中,我們首先對數據集進行了預處理,包括文本清洗、分詞、去除停用詞以及特征提取等步驟。隨后,我們利用KNN和GaussianNB模型對處理后的數據進行了訓練和測試。通過調整KNN中的K值和GaussianNB中的平滑參數alpha,我們觀察到了模型性能的顯著變化。KNN模型在較小的K值下表現出較高的精確率,但隨著K值的增加,模型的泛化能力得到了提升。而GaussianNB模型則在不同的alpha值下展現出對數據分布的不同適應性,較小的alpha值有助于模型捕捉數據的細微差別,而較大的alpha值則有助于模型的泛化。
通過對比兩種模型的精確率、召回率和F1分數,我們發現它們在不同的數據集和參數設置下各有優勢。KNN模型在處理非線性可分數據時表現較好,而GaussianNB模型則在特征獨立性假設成立時更為有效。最終,我們根據模型的性能和業務需求,選擇了最適合的模型,并對其進行了優化,以提高情感分析的準確性和效率。通過本次課程設計,我們不僅掌握了情感分析的理論知識,而且通過實踐加深了對機器學習模型的理解和應用能力。
七、附錄(全部代碼)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import jieba
from gensim.models import Word2Vec
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from pandas import read_csv
from pandas.plotting import scatter_matrix
from pandas import set_option
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, recall_score, f1_score
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from scipy.stats import iqr
from sklearn import svm
from sklearn.decomposition import PCA
from sklearn.metrics import precision_score# ***************************************************************************************************************************************************
# 讀取評論文件
df = pd.read_excel('Sklearn\kouhong.xlsx')
all_sentences = df['content']
target = df['content_type']# ***************************************************************************************************************************************************
# 去除重復評論信息
data= pd.DataFrame(all_sentences)
same_sentence_num = data.duplicated().sum()
if same_sentence_num > 0:data = data.drop_duplicates() # 刪除重復的評論內容# ***************************************************************************************************************************************************
# 使用jieba庫進行分詞操作
all_words=[]
for sentence in all_sentences:words = jieba.lcut(sentence) # 將評論切詞,并存放所有切分后的評論語句all_words.append(words)# print(all_words)
print('Step3:jieba cut successfully...')# ***************************************************************************************************************************************************
# 去除停用詞
with open('Sklearn\stopwords.txt','r', encoding='utf-8') as fp: # 讀取所有停用詞stop_words = fp.read().split('\n') # 存到stop_words列表中(以換行切分)
for sentence in all_words: # 雙重循環去除評論中的停用詞for word in sentence:if word in stop_words:sentence.remove(word)
print('Step4:romove stop-words successfully...')# ***************************************************************************************************************************************************
# 生成詞典
dictionary=[]
for sentence in all_words:for word in sentence:if word not in dictionary:dictionary.append(word) # 將所有評論中出現的詞語存
print('dictionary length:', len(dictionary))# ***************************************************************************************************************************************************
# Word2vec編碼model = Word2Vec(all_words, sg=0, vector_size=300, window=5, min_count=1,epochs=7,negative=10) # 調用Word2Vec模型,將所有詞語信息轉化為向量
print('word2vec encoding successfully...\n')
print(model.wv.vector_size)sentences_vector = []
for sentence in all_words:sentence_vector = np.zeros(model.wv.vector_size)for word in sentence: # 取出評論中每個單詞的向量累加sentence_vector += model.wv.get_vector(word)sentences_vector.append(sentence_vector/len(sentence)) # 取最終結果的平均值,作為評論語句的向量,并添加到評論向量列表中
# print(sentences_vector)# 拆分數據集為訓練集與測試集
X_train, X_test, y_train, y_test = train_test_split(sentences_vector,target,test_size=0.2,random_state=50)# ***************************************************************************************************************************************************
# 評估算法num_folds = 10 # 評估算法的基準,采用10折交叉驗證來分離數據
seed = 7
scoring = 'accuracy'# 評估算法 - 原始數據
# 對所有的算法不進行調參,使用默認參數,來比較算法。通過比較平均值和標準方差來比較算法。
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
results = []
for key in models:kfold = KFold(n_splits=2, random_state=seed, shuffle=True)cv_results = cross_val_score(models[key], X_train, y_train, cv=kfold, scoring=scoring)results.append(cv_results)print('%s : %f (%f)' % (key, cv_results.mean(), cv_results.std()))fig = plt.figure() # 評估算法(原始數據) - 箱線圖
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(models.keys())
plt.show()# ***************************************************************************************************************************************************
# KNN模型訓練和預測knn_model = KNeighborsClassifier() # 創建KNN模型實例,可按需設置參數,如n_neighbors等knn_model.fit(X_train, y_train) # 訓練KNN模型
y_pred = knn_model.predict(X_test) # 使用訓練好的KNN模型進行預測# 計算評估指標
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')# 輸出評估指標
print("KNN Model Evaluation Metrics:")
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")# 輸出分類報告
print("\nClassification Report:")
print(classification_report(y_test, y_pred))# 直接在循環中計算并收集評估指標,存入字典
metrics = {name: [] for name in ['precision', 'recall', 'f1']}
for k in np.arange(1, 21):knn_model = KNeighborsClassifier(n_neighbors=k).fit(X_train, y_train)y_pred = knn_model.predict(X_test)for metric_name in metrics:metric_value = globals()[metric_name + '_score'](y_test, y_pred, average='weighted')metrics[metric_name].append(metric_value)best_k_f1 = np.argmax(metrics['f1']) + 1 # 因為索引從0開始,所以加1得到實際的k值# 統一可視化邏輯,通過循環繪制不同指標的折線圖
for metric_name, marker, color in zip(['precision', 'recall', 'f1'], ['o', 's', '^'], ['r', 'g', 'y']):plt.plot(np.arange(1, 21), metrics[metric_name], marker=marker, label=f'KNN {metric_name.title()}', color=color)plt.xlabel('K (Number of Neighbors)')plt.ylabel(metric_name.title())plt.title(f'KNN {metric_name.title()} with Different K Values')plt.xticks(np.arange(1, 21))plt.legend()plt.show()# 繪制混淆矩陣
confusion_mat = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Confusion Matrix for KNN Model")
plt.colorbar()
tick_marks = np.arange(len(np.unique(y_test)))
plt.xticks(tick_marks, np.unique(y_test), rotation=45)
plt.yticks(tick_marks, np.unique(y_test))
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()# 打印出最好的k值(基于F1 Score)
print(f"The best k value based on F1 Score is: {best_k_f1}\n")# ***************************************************************************************************************************************************
# GaussianNB模型訓練和預測gnb_model = GaussianNB() # 創建GaussianNB模型實例,可按需設置參數,如var_smoothing等
gnb_model.fit(X_train, y_train) # 訓練GaussianNB模型
y_pred = gnb_model.predict(X_test) # 使用訓練好的GaussianNB模型進行預測
alpha_values = np.logspace(-2, 2, 10) # 定義不同的平滑參數alpha值metrics_scores = { # 用于存儲不同alpha值下各評估指標的字典'precision': [],'recall': [],'f1': []
}for alpha in alpha_values:gnb_model = GaussianNB(var_smoothing=alpha).fit(X_train, y_train)y_pred = gnb_model.predict(X_test)for metric in ['precision', 'recall', 'f1']:metric_value = globals()[metric + '_score'](y_test, y_pred, average='weighted')metrics_scores[metric].append(metric_value)# 計算評估指標
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')# 輸出評估指標
print("GaussianNB Model Evaluation Metrics:")
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")# 統一可視化邏輯的函數
def plot_metrics(title, y_label, marker, color):plt.plot(alpha_values, metrics_scores[title], marker=marker, label=f'GaussianNB {title.title()}', color=color)plt.xlabel('Alpha (Smoothing Parameter)')plt.ylabel(y_label)plt.title(f'GaussianNB {title.title()} with Different Alpha Values')plt.xscale('log')plt.xticks(alpha_values)plt.legend()plt.show()# 分別可視化精確率、召回率、F1值折線圖
plot_metrics('precision', 'Precision', 'o', 'r')
plot_metrics('recall', 'Recall', 's', 'g')
plot_metrics('f1', 'F1 Score', '^', 'y')# 輸出分類報告
print("\nClassification Report:")
print(classification_report(y_test, y_pred))# 繪制混淆矩陣
confusion_mat = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Confusion Matrix for GaussianNB Model")
plt.colorbar()
tick_marks = np.arange(len(np.unique(y_test)))
plt.xticks(tick_marks, np.unique(y_test), rotation=45)
plt.yticks(tick_marks, np.unique(y_test))
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()



 +springboot+vue3)








)

 問題 D: 數列-訓練套題T10T3)



