背景前搖&原視頻教程:
最近總是在小紅書上刷到多圖組成的養生小妙招、效率提升小tips、退休奶奶療愈語錄等等這樣的圖文筆記,而且人物圖像一眼就是AI畫的。
當時我以為這個排版和文字是人工的,就讓AI保持角色一致性畫了下圖,沒想到在B站刷到了實現教程,才知道Coze平臺已經支持很完善的一鍵出筆記的工作流了。
B站上優秀的視頻教程:
對比了我主動搜索+推薦算法推送的教程,最后跟著UP @在下李君陌 的教程學完了整個工作流,確實成功實現了出圖文筆記的效果。
原視頻鏈接:https://www.bilibili.com/video/BV1Xa5QzpEKM/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
傳送門
 而且這個UP特別好的是,把用到的演示文稿直接就放在了簡介里,直接飛書就可以打開,無需再三連私信求資料,最后被賣課的反復騷擾,簡直就是超級良心。
而且這個UP特別好的是,把用到的演示文稿直接就放在了簡介里,直接飛書就可以打開,無需再三連私信求資料,最后被賣課的反復騷擾,簡直就是超級良心。
因為原UP的視頻已經很詳細了,大家跟著學一定能順利實踐出真知,我就不再贅述UP的視頻里面已經介紹的如何搭建工作流的相關過程了。本文只分享一些我個人遇到的問題和心得。
跟完教程后生成的圖文筆記預期效果:
我這里選定的主題是“香港旅游”,想著順帶幫親戚做個旅游攻略。







封面圖+5張簡單的圖文筆記,效果還不錯~
學習準備:
1.9.9的氪金費用,因為這個工作流有很多圖像生成節點,可能Coze平臺默認的額度不夠用,必要時需要氪金開個個人進階版,或者增購資源包。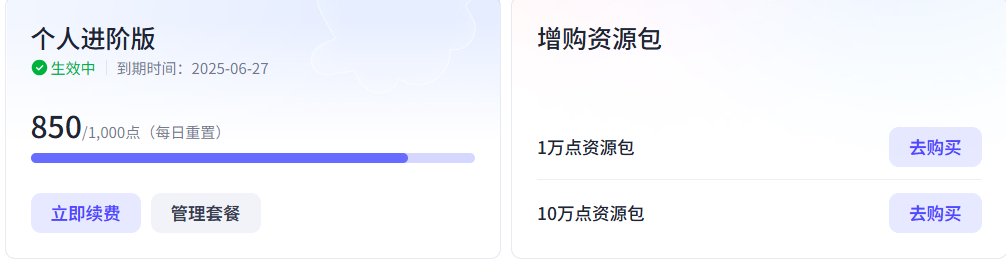
2.至少兩個小時的學習時間,原UP視頻長約一個半小時,加上大家自己摸索、連圖、調試的時間,如果是Coze新手,需要的時間會更長。
3.一些Coze平臺的基礎知識,至少知道如何搭建工作流和傳遞參數,讓一個工作流完整跑起來。如果對Coze完全一無所知,建議先看Coze官方視頻教程:傳送門
https://www.bilibili.com/video/BV1zC35eFEyN?spm_id_from=333.788.videopod.sections&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
4.其他原視頻UP在講解過程中要求準備的東西,比如飛書演示文檔(后面復制提示詞會用到,或者實在沒有的話,截圖OCR文字識別也可),放在桌面上的幾張組成模板用的底圖。
正文:
大家如果順利跟著UP的視頻走完了全流程以后,應該工作流會長下面這樣:是一個能生成5張圖文+一個主圖封面的工作流,并且每個頁面又有兩張組成圖片。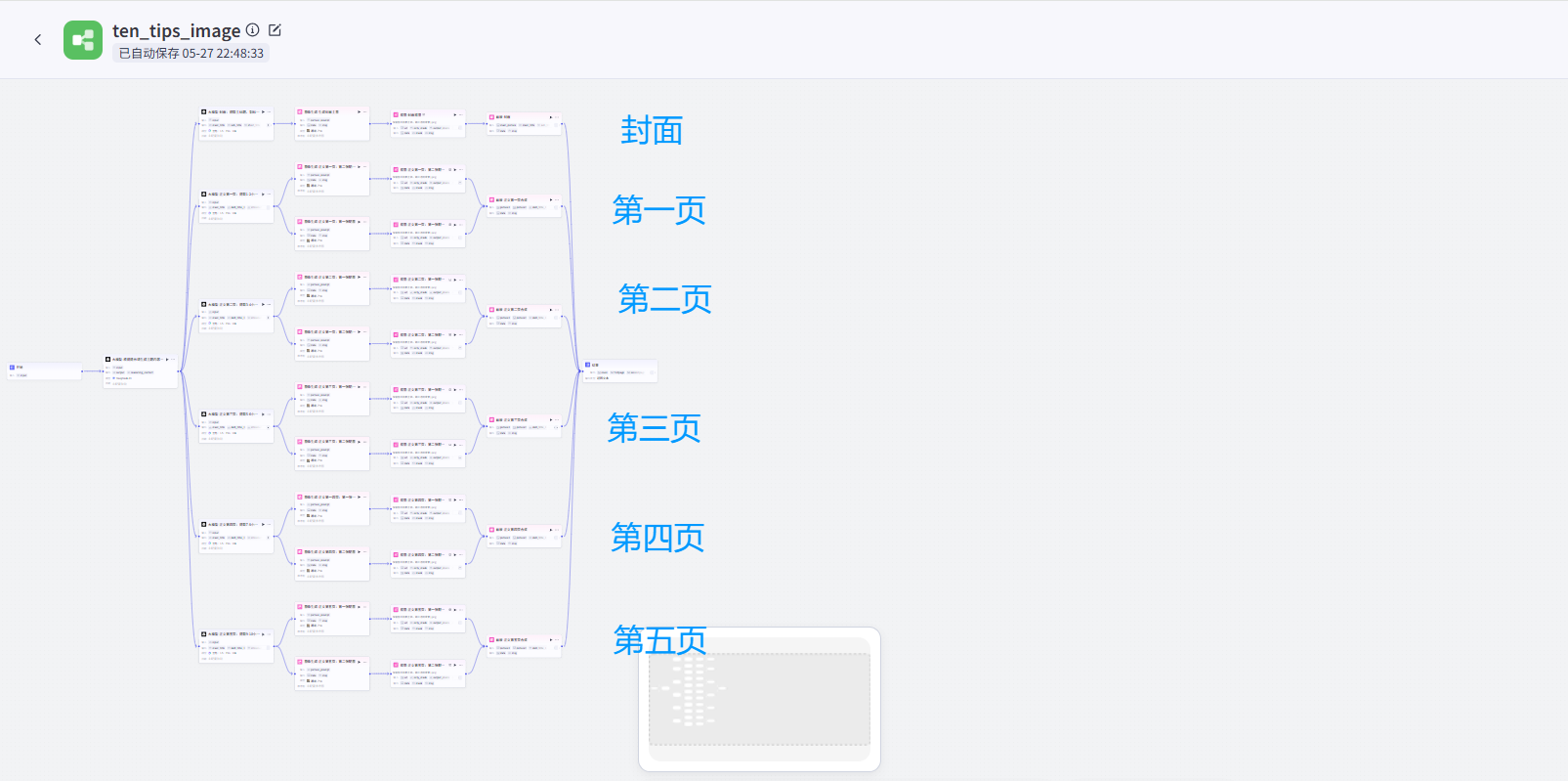
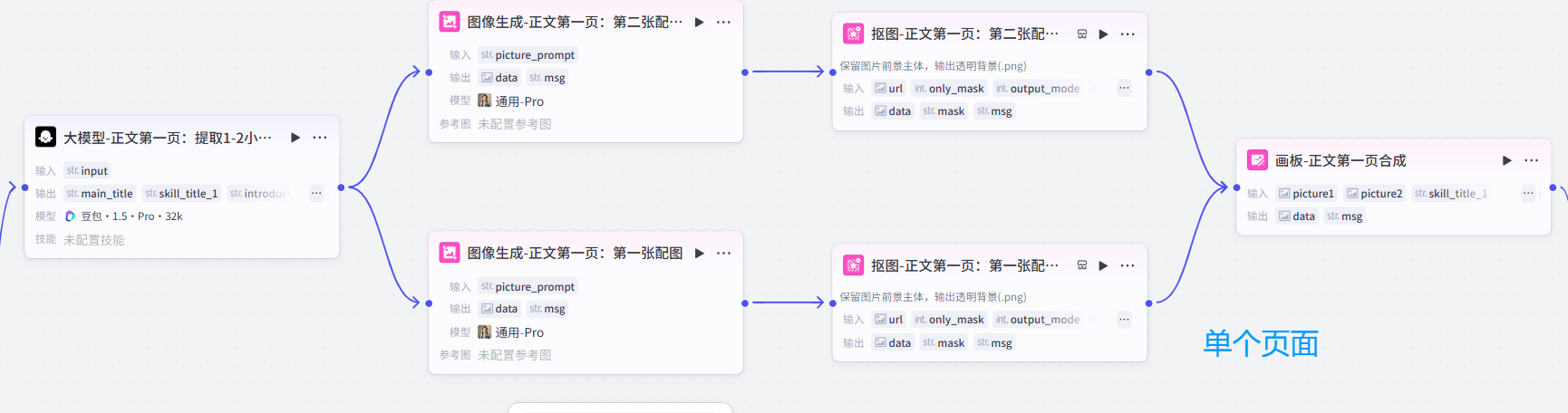

1.圖像調用節點受限問題:
如果按照上面這樣連接節點,邏輯是沒問題的,但是調用起來會發現工作流會被中途中斷,因為同時調用的圖像節點太多了。
中道崩殂不說,還白燒了不少token,簡直讓人心疼。

B站視頻評論區也有碼友遇到這個問題,給出的解決方法是拆成幾個工作流調用。
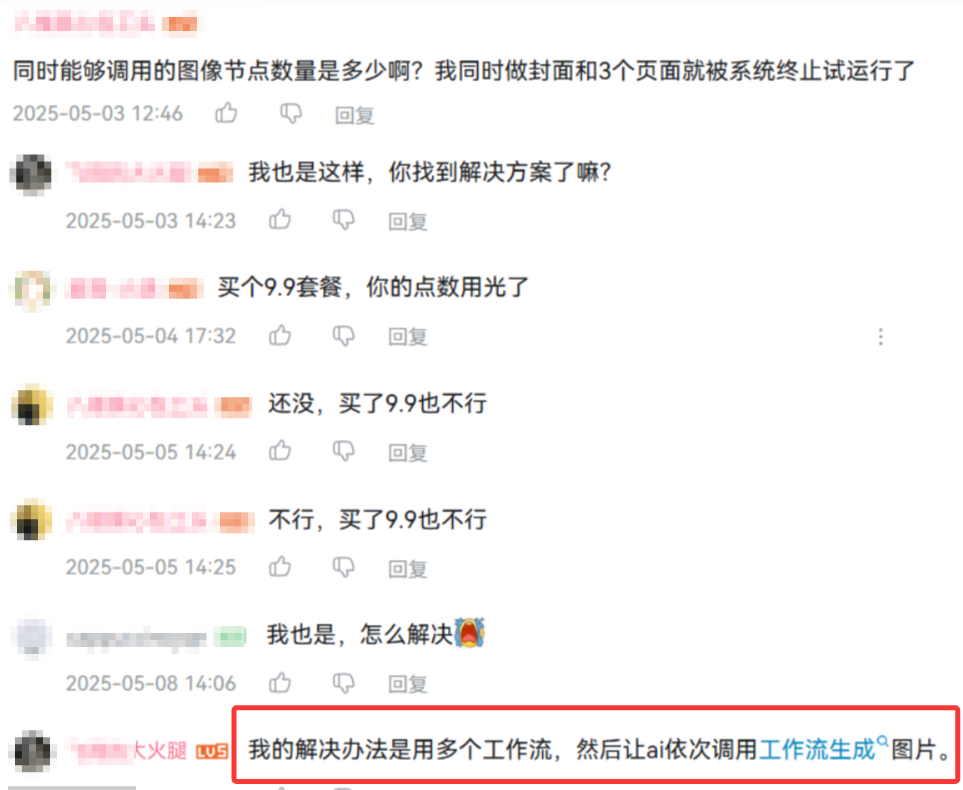
這樣應該也可行,我沒有自己嘗試過,不過我采用了另一種方法來規避這個問題。
那就是——把工作流連成一條長直線!
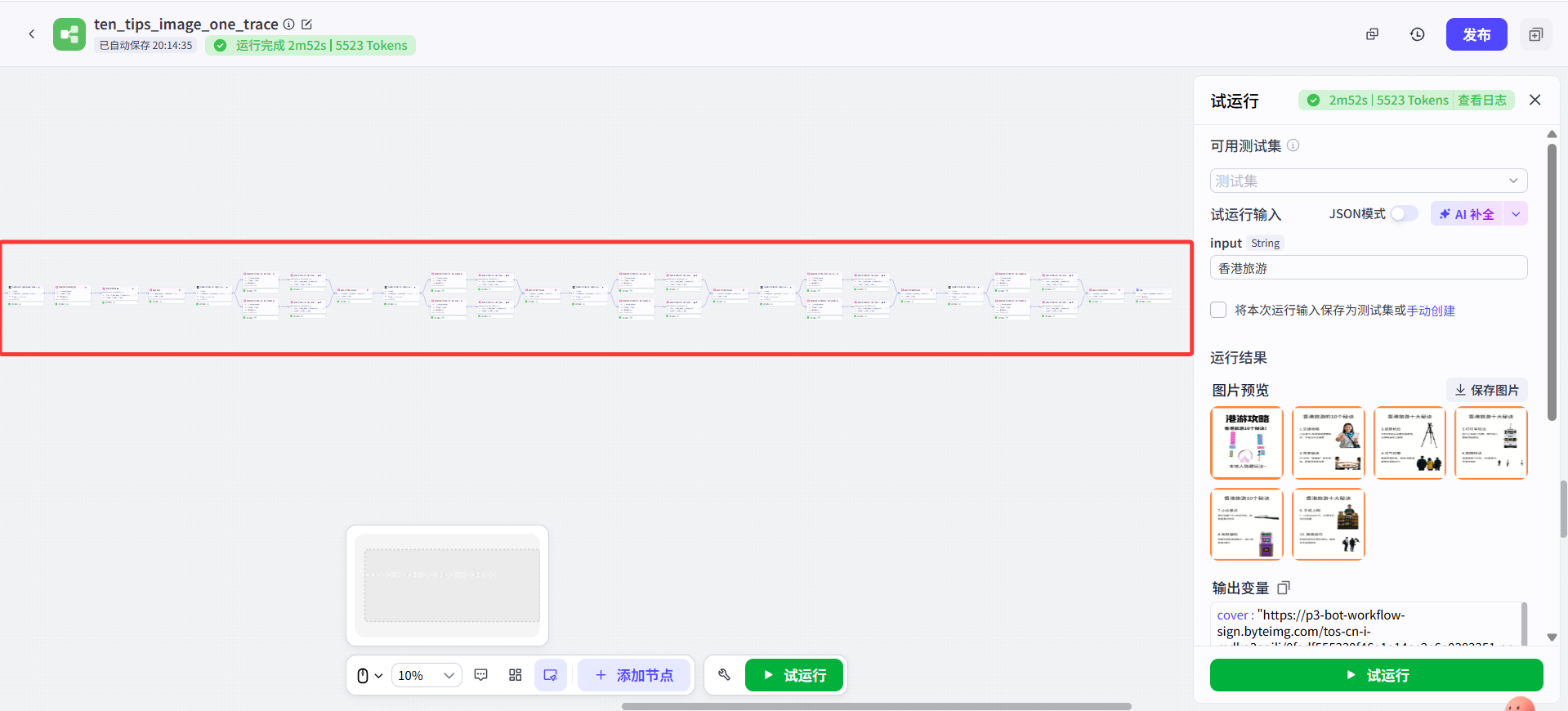
也就是說,把第一頁的大模型節點和封面的畫板節點連起來,再把第一頁的畫板節點和第二頁的大模型節點連接起來。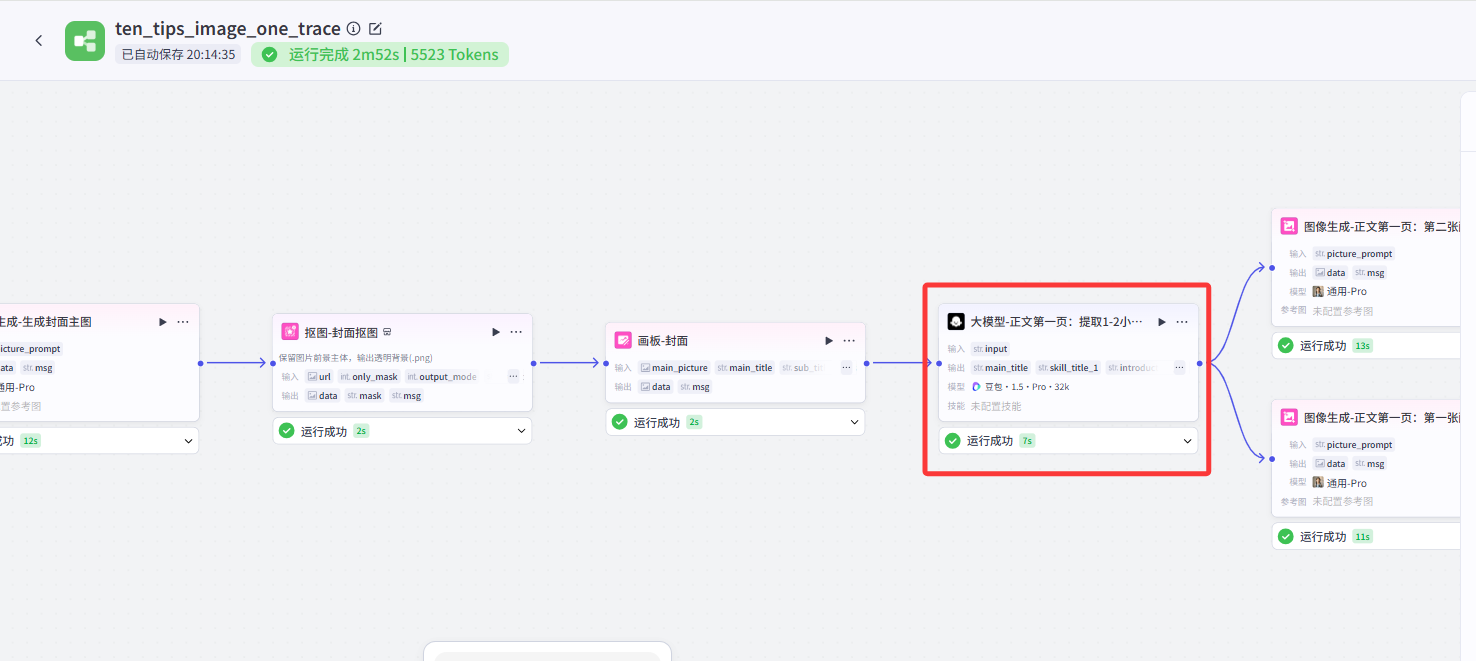
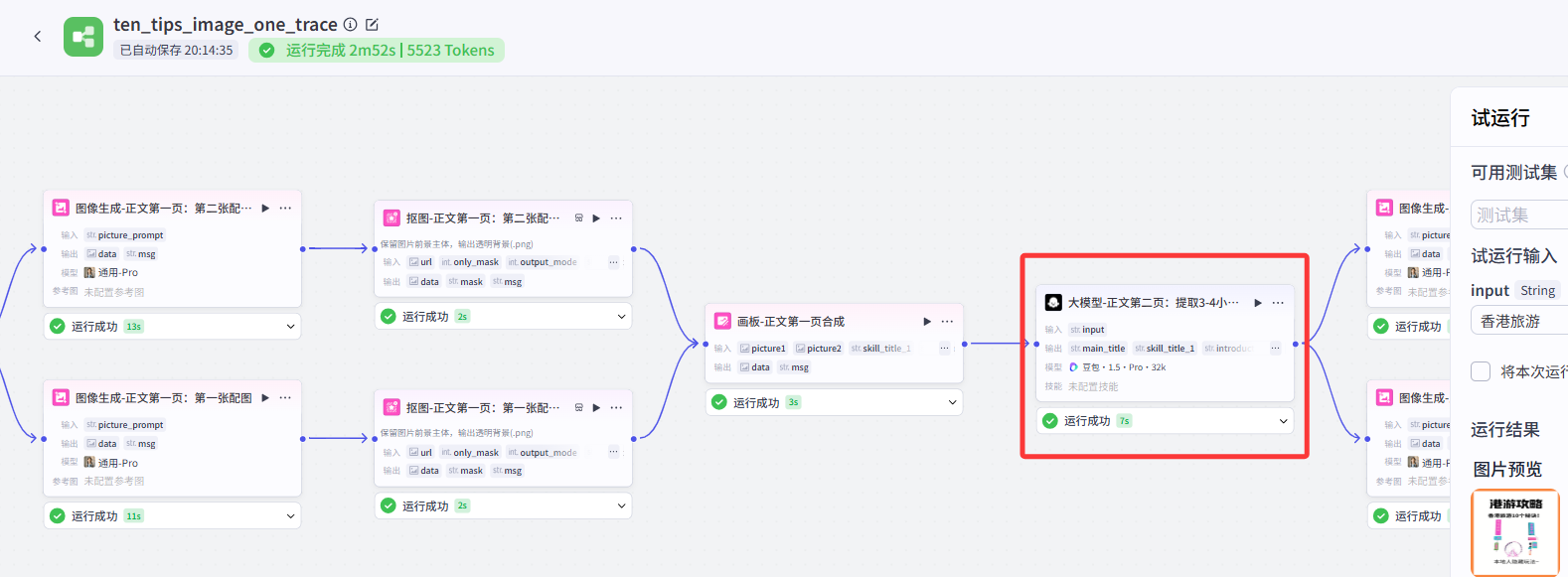 可以理解為,原作者那樣的結構,封面、不同頁之間是并聯關系。大模型節點生成提示詞以后,同時在生成封面和五頁內容的圖,這樣就導致圖像節點調用過多,超限制了。
可以理解為,原作者那樣的結構,封面、不同頁之間是并聯關系。大模型節點生成提示詞以后,同時在生成封面和五頁內容的圖,這樣就導致圖像節點調用過多,超限制了。
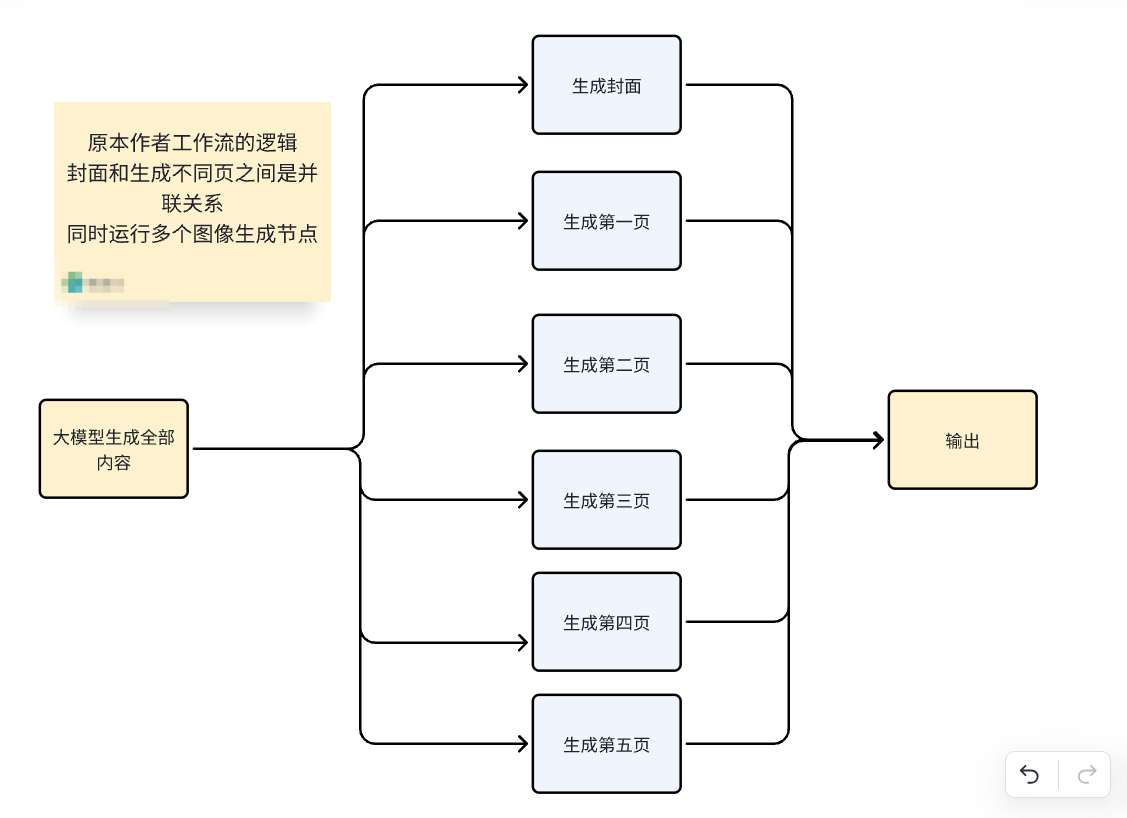
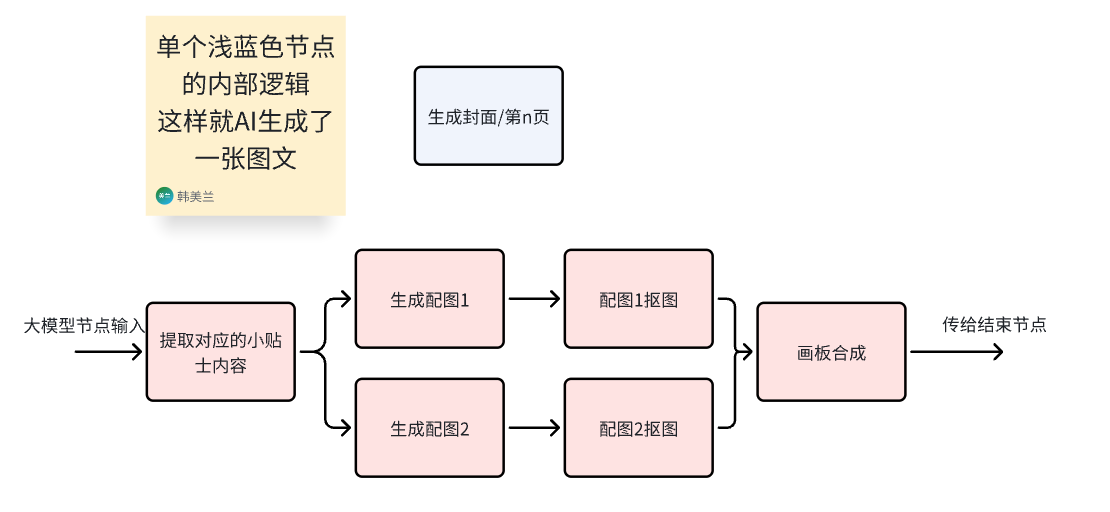
上圖中單個淺藍色的節點里面,構成了能組成一張單圖的基本邏輯: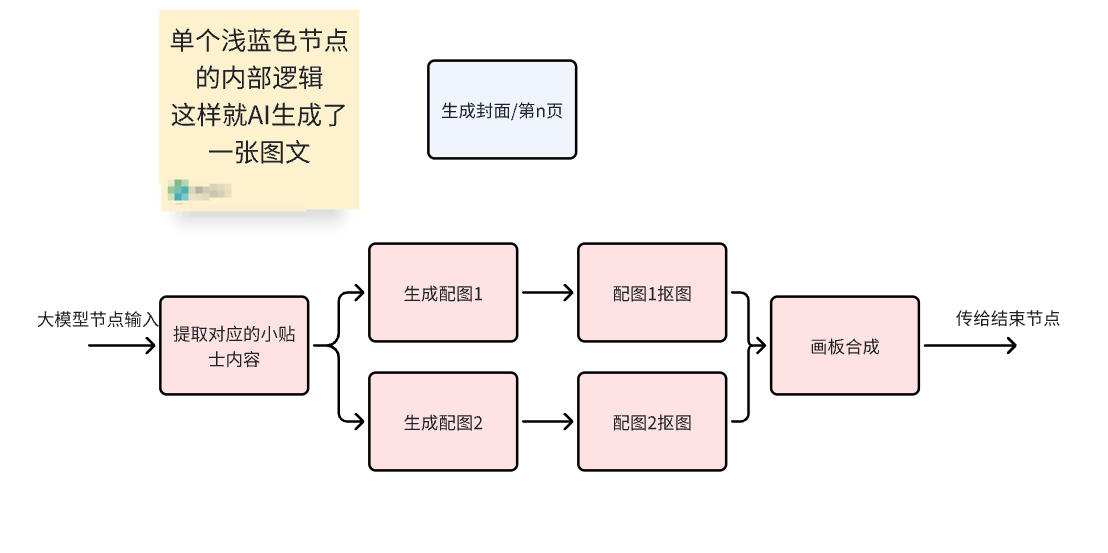
而我把封面和不同頁的生成順序變成了串聯關系,先生成封面,再生成第一頁,然后是第二頁,單張圖文筆記生成的邏輯并沒有改變,所以不影響出圖效果。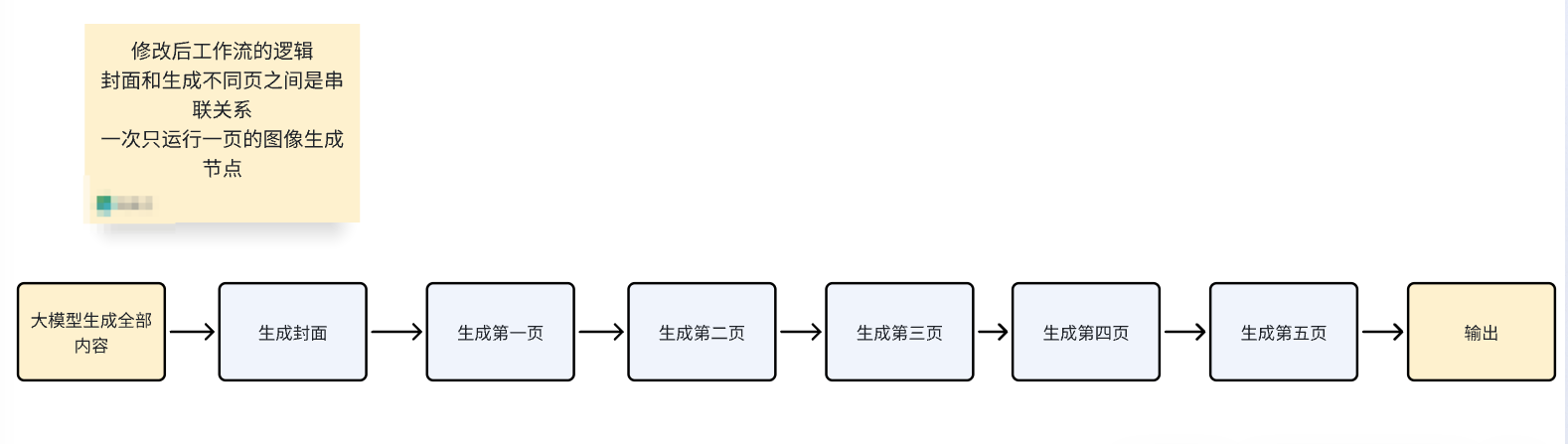
每個淺藍色節點生成圖片的邏輯依舊是這樣,沒有改變:
因為只要通路是連著的,后續的節點可得到前面任意節點的輸出,所以并不影響每一頁的大模型節點提取對應的小技巧,也不影響最后結束節點一次性輸出五張圖。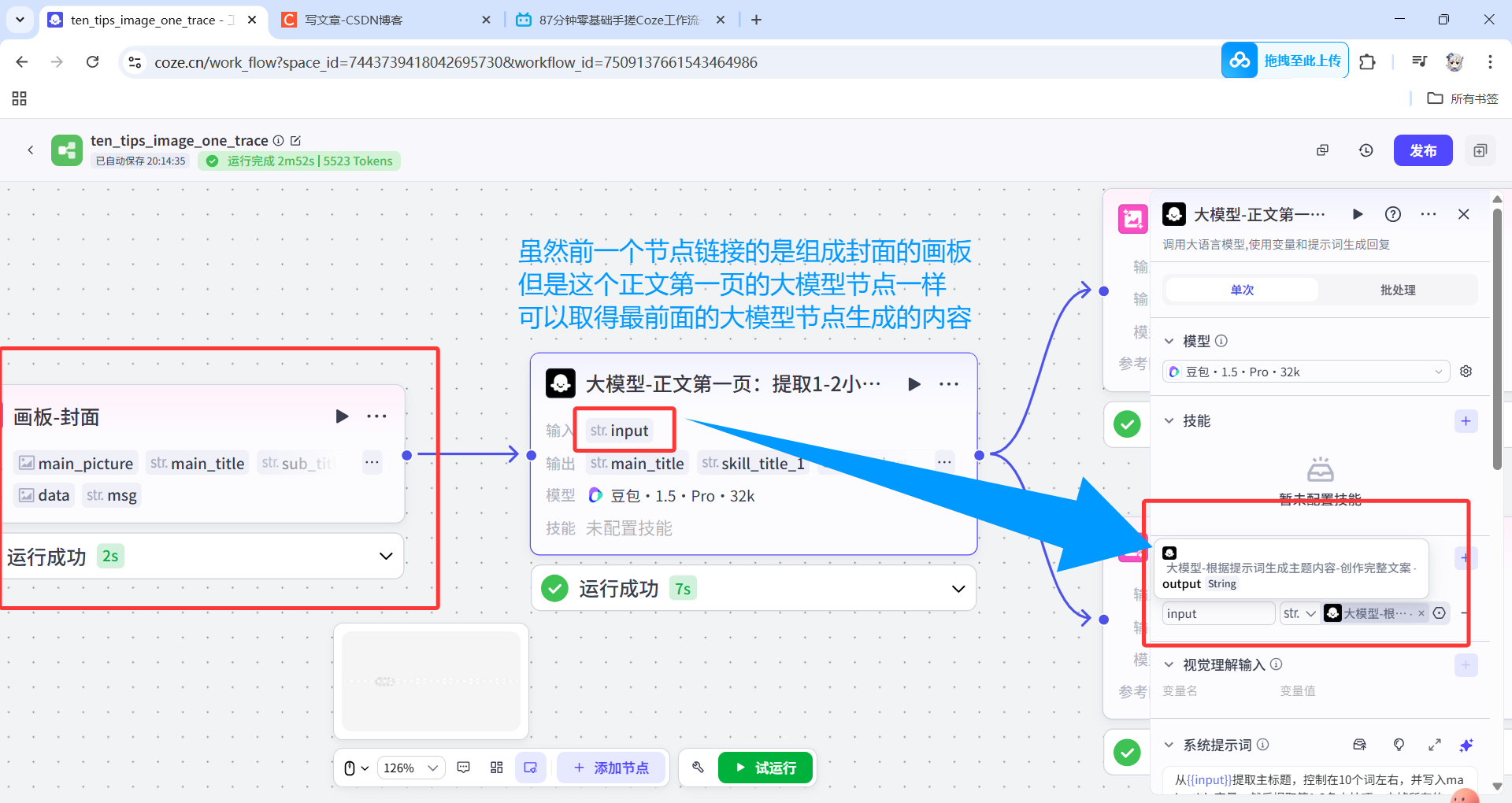
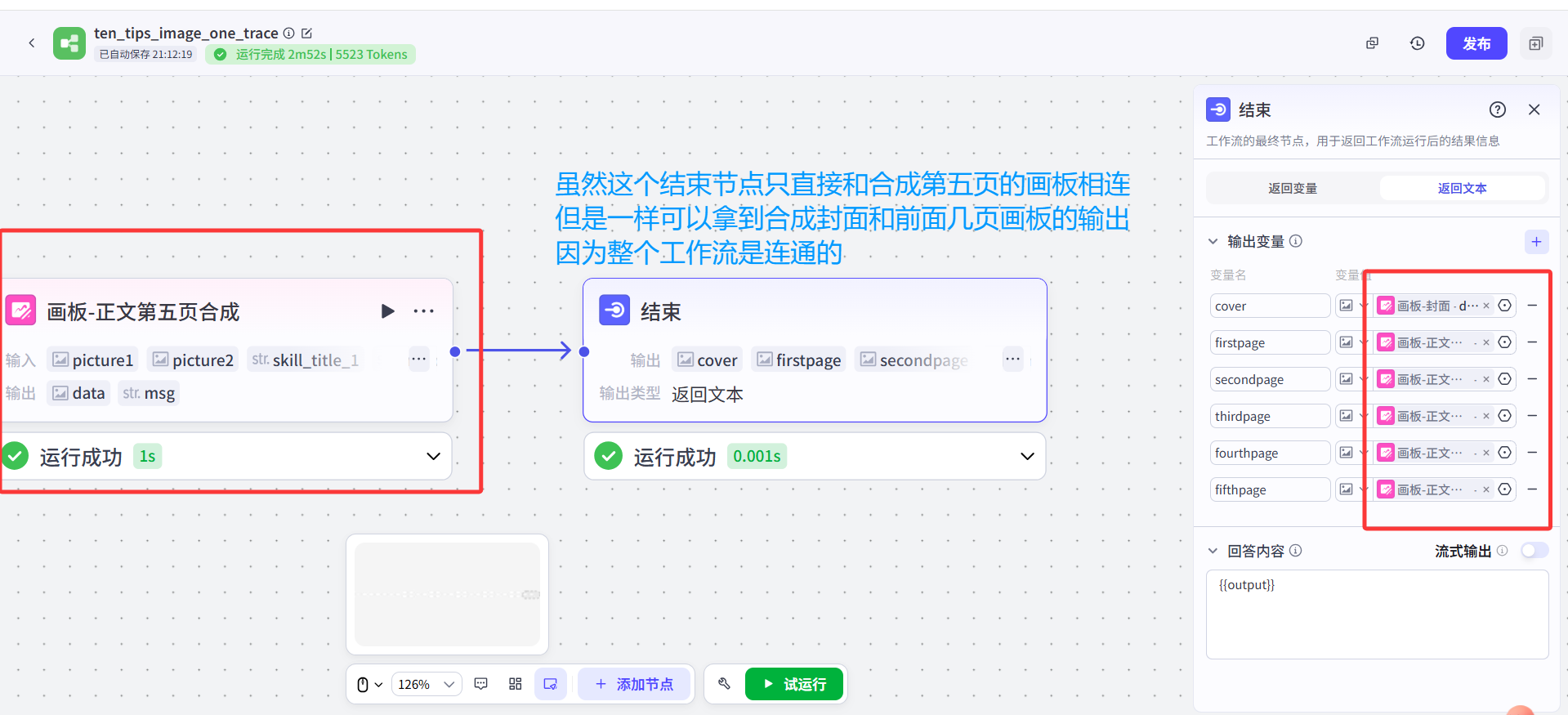
這樣雖然運行速度稍微慢一些,但是一個工作流內就可以實現生成全部圖文,并且不會報圖像節點受限的問題。
當然,如果覺得這樣擺成一長條不太美觀的話,也可把生成單張頁面的幾個節點按shift選中(或者鼠標左鍵長按拖拽框選),把他們作為一個組合(可以自行選擇是否封裝工作流,這里我為了清晰沒用封裝),拖拽成一排排的。
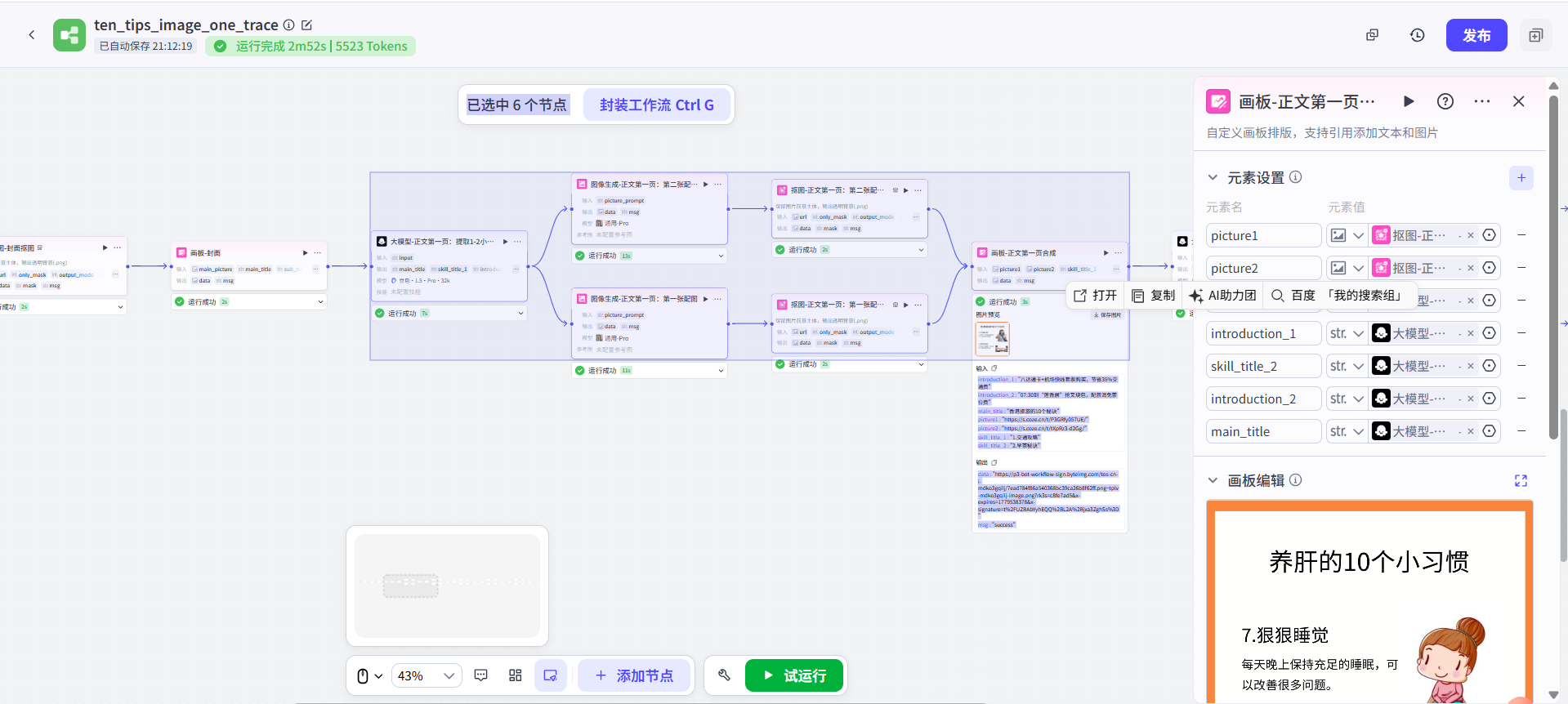
下面這樣是不是就跟原視頻UP的工作流比較像啦?其實在我按原UP的并聯工作流改為串聯邏輯以后,這就是這個串聯工作流最初的樣子。 其實我最開始演示的一條直線的工作流,就是現在這個工作流點擊了“優化布局”按鈕重排后,整個工作流被拉直后的結果。
其實我最開始演示的一條直線的工作流,就是現在這個工作流點擊了“優化布局”按鈕重排后,整個工作流被拉直后的結果。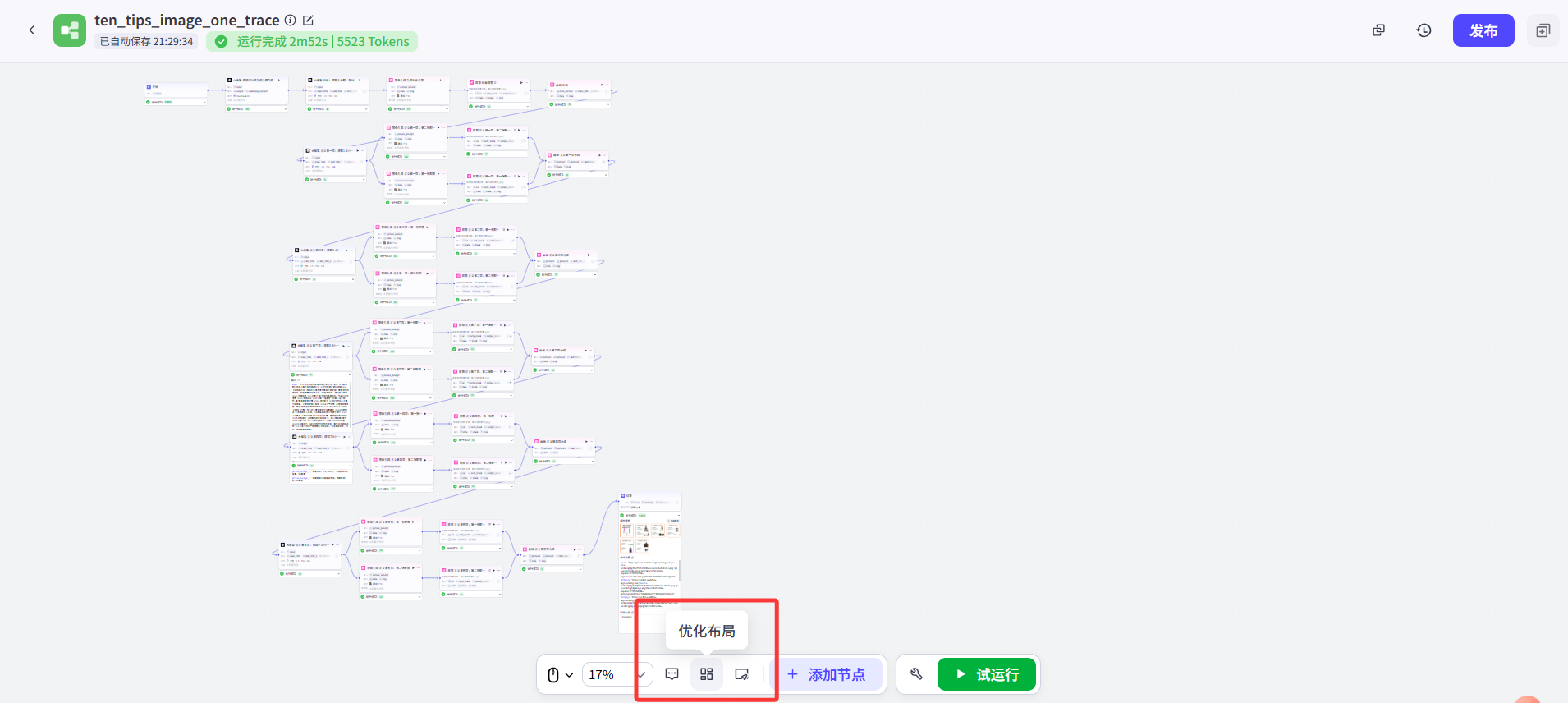
(串聯工作流偶爾也會遇到執行不成功的情況,但多試幾次就可以了!)
2.圖片生成內容更寬泛:
原作者跟著做的模板是人類養生相關的,圖片生成模型選的是“人像”,并且給了參考圖,但這就導致圖文筆記能生成的內容相對受限,很多圖片都會畫個人在中間。
但我希望做的主題是“香港旅游”,很多生成的貼士是跟旅游景點相關的,比如叮叮車、天星小輪,但是按照原來的設定,生成的很多配圖主體物都是人,摳圖完后基本上只剩下一個人的輪廓了,就跟我們的旅游場景不搭配。
我把所有節點選用的圖像生成模型全部都改成了**“通用Pro”**,這樣不但可以支持生成人像,也可以根據不同主題的提示詞生成其他景物、美食等圖片。通用模型畫什么其實更多取決于得到什么提示詞,如果前面生成提示詞的大模型判斷出來這個小貼士需要出現人物在畫面里,通用模型也可生成。
原作者給的參考圖我也去掉了,感覺有跟沒有差別并不大,很多時候參考圖并沒有發揮其該有的作用,很多時候不但人物崩壞,還很重復,出現人長得有些相似,但是一致性又不夠(就是倒像不像,很難說這倆是一個人,但又不是完全不像),畫風還不統一(有的寫實風,有的卡通風)、還有多手多腳、畫面結構混亂等問題。
綜合考慮感覺,不同小貼士之間人跟人長得一不一樣并不重要,就算是養生場景,展示的路人A在泡腳,路人B在做操也沒有關系。所以就讓模型更自由發揮了。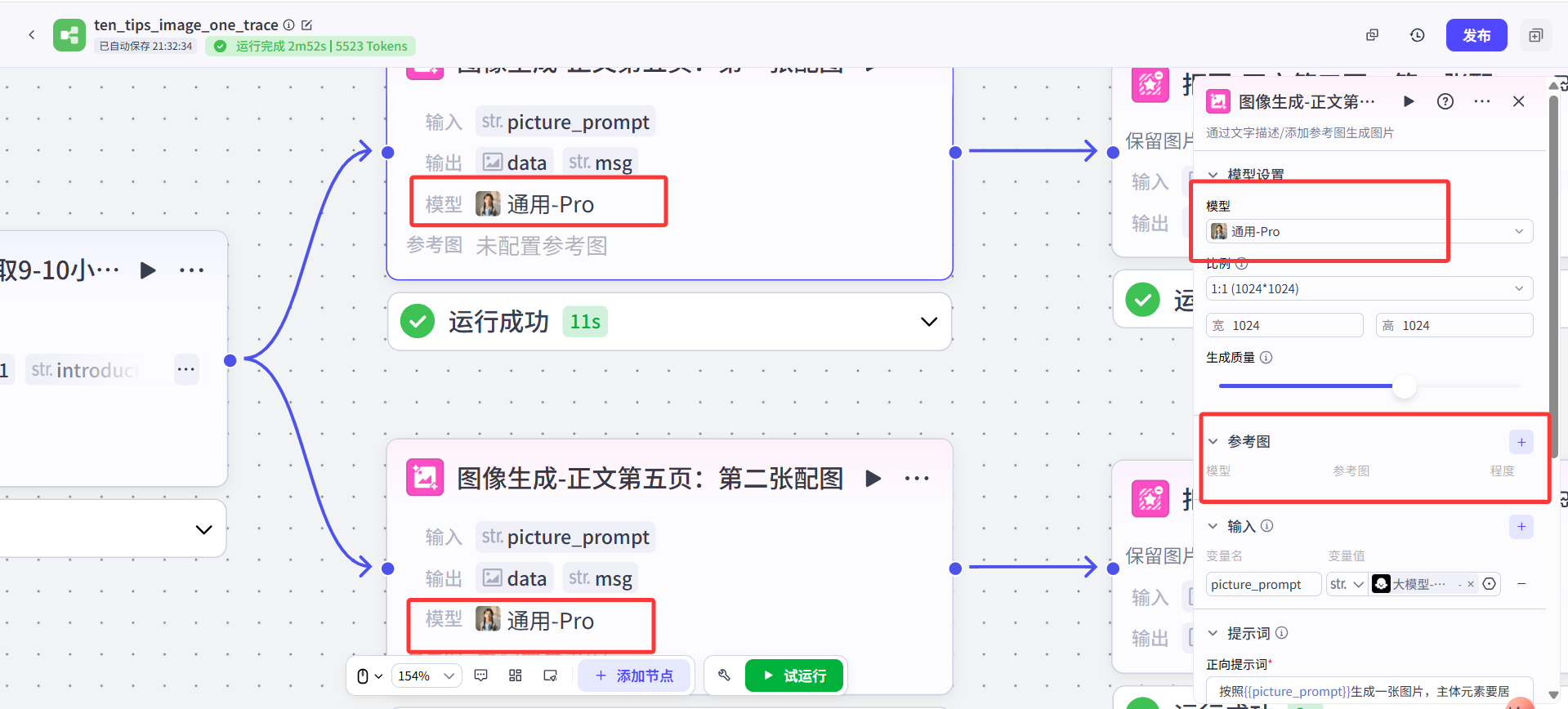
修改后,不但之前UP測試的養生、提效、告別拖延場景可適配,我想實現的旅游場景也能實現了。

3.實現圖文效果的提示詞:
這部分是我覺得很意外也很驚喜的點,我一直以為要生成這樣有封面+五張圖的內容,提示詞會很復雜,這些一段那寫一段,沒想到總共就三個部分。
這里原視頻作者寫得就很好,并且因為其文檔是公開分享的,我就直接截圖了。
首先是這個最重要的大模型節點,除了決定吸睛的首圖標題元素以外,還是后面幾頁內容的根基。
我一度以為要用很長的篇幅給大模型描述,我要做個什么樣的小紅書圖文排版,各種跟他解釋我整個排版要怎樣關聯,怎樣布局…
結果居然是這樣簡單,就告訴他,我要主標題副標題短標題,有什么字數要求,還要按照標題生成10個符合要求的實操技巧,就完事了。
至于排版的部分,是搭建好的畫板來解決,如果布局不好看,比如字數超了導致換行、沒對齊,再跟大模型進一步調整限制字數的要求。

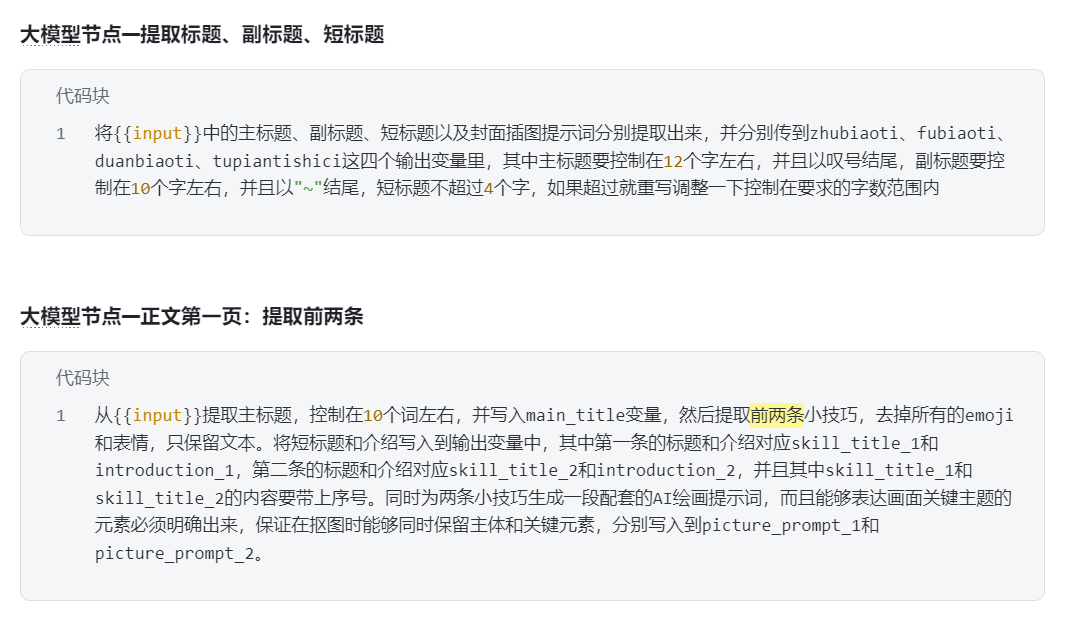
然后就是生成各頁面的大模型節點,負責來提取前面生成的、自己負責的這部分小貼士的主題,并且以此進一步生成畫圖的提示詞。
我以為提取內容這部分少說需要寫代碼,然后中間再把需求描述給GPT讓它代勞實現代碼邏輯,沒想到大模型直接就把提取內容整個活做了。
原視頻UP也說,簡單的內容提取可以交給大模型做,確認它完成得也很優秀,免得我把需求給另外的AI描述半天,然后測試代碼等折騰了。只需要針對不同頁的大模型,把提取哪幾條小技巧(下圖黃色高亮部分,比如第一頁提取1-2條小技巧,第二頁提取3-4條小技巧…)改一下即可。
這段提示詞同時還做了生成給后面的圖像生成節點構造提示詞的任務,甚至都沒有分段或者分點,行云流水一氣呵成,但是效果非常到位,看來模型對提示詞的理解能力非常好,沒用遺漏或者誤解這一段話的好幾個需求,可以說是《高端的食材只需要最簡單的烹飪方式》?
最后就是生成圖片的指令,這個就相對普通平常了,為了不至于摳完圖后主體物被切掉太多部分,所以讓周圍留出一些距離。 整個過程是調用了三層大模型,第一層總大模型負責圍繞用戶輸入的主題,生成標題和10個小貼士作為大的框架,第二層是每一頁的大模型,負責專注自己的那部分小貼士,補全細化文本內容,并且生成給圖像模型的提示詞,第三層每張圖的圖像生成模型負責按照輸入指令生成圖片。
整個過程是調用了三層大模型,第一層總大模型負責圍繞用戶輸入的主題,生成標題和10個小貼士作為大的框架,第二層是每一頁的大模型,負責專注自己的那部分小貼士,補全細化文本內容,并且生成給圖像模型的提示詞,第三層每張圖的圖像生成模型負責按照輸入指令生成圖片。
簡短總結:
整個工作流的結構,大模型、畫圖節點的調用方式,以及簡明干練的提示詞描述能力,很值得學習和借鑒,感謝原UP帶來這么棒的教程。





)

 問題 D: 數列-訓練套題T10T3)







》—— 零基礎實現基于離散優化的避障路徑規劃)



