論文標題:
Noise Modeling in One Hour: Minimizing Preparation Efforts for Self-supervised Low-Light RAW Image Denoising發表日期:
2025年5月作者:
Feiran Li, Haiyang Jiang*, Daisuke Iso發表單位:
Sony Research, Tokyo University原文鏈接:
https://arxiv.org/pdf/2505.00045開源代碼鏈接:
https://github.com/SonyResearch/raw_image_denoising
引言
在低光環境下拍攝RAW圖像時,噪聲問題總是令人頭疼。傳統降噪方法需要大量成對的干凈-噪聲圖像進行訓練,而索尼研究院的這項研究提出了一種自監督學習方法,僅需1小時的準備時間就能完成噪聲建模,性能還比現有方法提升了0.54dB。這項技術將大大降低低光攝影的門檻,讓更多人能拍出清晰的照片。
論文中的方法架構圖展示了這個創新的降噪流程:

實驗結果對比圖顯示,該方法在保持圖像細節的同時有效去除了噪聲:

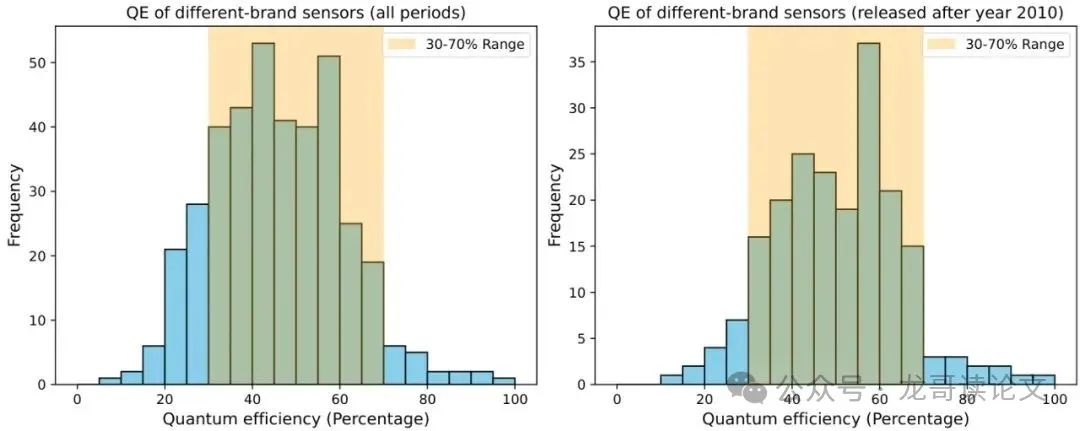
量子效率統計圖展示了該方法在傳感器特性分析方面的創新:
問題背景及相關工作
在低光環境下拍攝RAW圖像時,噪聲問題尤為突出。相比標準RGB圖像,RAW圖像保留了原始噪聲特性,具有更高的位深度,因此在降噪方面展現出巨大潛力。然而,基于學習的方法需要大量成對的干凈-噪聲圖像進行訓練,這在實踐中往往難以實現。
傳統噪聲合成方法通常需要傳感器特定的建模,包括信號依賴和信號無關的噪聲合成兩個步驟。這些步驟往往需要大量人工干預和復雜流程,如系統增益校準和噪聲分析,耗時可達數天。
現有的噪聲合成方法主要分為兩類:基于統計模型的方法和基于神經網絡的方法。前者如ELD方法識別了RAW傳感器數據中的四種關鍵噪聲元素;后者如NoiseFlow使用流模型進行噪聲建模。但這些方法都存在實現復雜或部署困難的問題。
方法概述
本論文提出了一種簡單實用的噪聲合成流程,通過詳細分析噪聲特性和廣泛驗證現有技術,大大減少了準備時間。該方法的核心在于:
假設量子效率:通過假設量子效率值來合成光子散粒噪聲,避免了繁瑣的系統增益校準過程
直接采樣信號無關噪聲:直接從傳感器采集暗幀作為信號無關噪聲的樣本,省去了復雜的噪聲分析步驟
暗影校正:通過暗影校正消除時間一致性噪聲的影響,提高訓練效果
術語解讀
RAW圖像:直接從相機傳感器輸出的未經處理的圖像數據,保留了更多的原始信息
系統增益K:由量子效率(QE)和模擬增益(AG)組成,K=QE×AG,是噪聲建模中的關鍵參數
暗幀:在完全黑暗條件下拍攝的圖像,僅包含傳感器自身產生的噪聲
光子散粒噪聲:由光的量子特性引起,服從泊松分布,是信號依賴噪聲的主要成分
核心設計
本方法的整體流程如圖2所示:

圖2:降噪流程概覽。在準備階段,本文為每個模擬增益收集多個暗幀并計算相應的暗影。為了合成一對訓練圖像,本文假設一個系統增益K來生成泊松散粒噪聲圖,并將其與采樣得到的暗影校正暗幀一起添加到干凈圖像中。在推理階段,給定一個噪聲圖像,本文從中減去暗影后輸入網絡。
該方法的核心創新點在于:
基于假設的散粒噪聲合成:通過假設量子效率值來估計系統增益K,避免了復雜的校準過程
直接采樣信號無關噪聲:使用直接從傳感器采集的暗幀作為信號無關噪聲的樣本
暗影校正:通過暗影校正消除時間一致性噪聲的影響
論文主體思路
本論文的主要研究思路可以總結如下:
應用場景:低光環境下RAW圖像去噪
問題建模:通過噪聲合成實現自監督學習,解決成對數據不足的問題
模型Backbone:采用U-Net作為去噪網絡,與現有工作保持一致
損失函數:使用L1損失函數
訓練數據集:使用合成的噪聲-干凈圖像對
測試數據集:SID、ELD和LRID數據集
訓練方法:使用Adam優化器訓練1000個epoch,其中400個epoch用于微調
方法優勢:準備時間從數天縮短至1小時,性能提升0.54dB
方法缺點:需要已知模擬增益(AG),對普通消費者相機用戶可能不友好
主要創新點
基于假設的散粒噪聲合成:通過假設量子效率值來估計系統增益K,避免了復雜的校準過程
直接采樣信號無關噪聲:使用直接從傳感器采集的暗幀作為信號無關噪聲的樣本
暗影校正:通過暗影校正消除時間一致性噪聲的影響
簡化流程:將準備時間從數天縮短至1小時,同時保持甚至提升去噪性能
核心原理推導
本方法基于以下圖像形成模型:
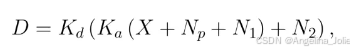
其中Kd是用于亮度調整的數字增益,Ka是應用于模擬信號的系統增益,X是與場景輻照度成正比的實際光子數,Np是信號依賴噪聲,N1和N2是兩種信號無關噪聲。
信號依賴噪聲主要來自光子散粒噪聲,服從泊松分布:
![]()
系統增益K由量子效率(QE)和模擬增益(AG)組成:?
![]()
基于量子效率的物理約束(通常在30%-70%之間),可以安全地假設K值而不需要精確校準。
數據準備及實驗設計
實驗使用了三個流行的低光RAW圖像去噪數據集:
SID:使用Sony-A7S2全畫幅單反相機拍攝
ELD:使用另一臺Sony-A7S2相機拍攝
LRID:使用Redmi K30智能手機的IMX686傳感器拍攝
實驗對比了多種方法,包括:
監督方法:使用真實噪聲-干凈圖像對訓練
自監督方法:基于干凈圖像合成噪聲
混合方法:使用合成數據進行預訓練,真實圖像對進行微調
實驗結果
在SID和ELD數據集上,本文方法以46.43dB的平均PSNR刷新了自監督降噪記錄,甚至超過部分監督學習方法。來看關鍵數據對比:

圖3:不同噪聲合成方法的定性對比。所有圖像都經過簡單的圖像信號處理流程轉換為sRGB格式以便更好可視化。ELD和SFRN在圖像邊界處表現出明顯的顏色偏差,而本文方法則沒有。
在智能手機傳感器測試集LRID上,本文方法展現出45.08dB的驚人表現,比現有最佳方法提升0.54dB。更令人驚喜的是,使用僅10個暗幀進行在線校準時的性能損失不超過0.1dB!

圖4:不同模型擬合信號無關噪聲的分位數-分位數圖。左:重采樣數據與用于模型擬合數據的對比(即建模精度)。右:重采樣數據與未見暗幀數據的對比(即泛化精度)



)

醫學圖像的配準全過程文檔及程序)
基礎使用)

中播放)
)








的路徑規劃(附ROS C++/Python仿真))
